一种基于Avatar表情移植的虚拟社交方法与流程
本发明涉及计算机视觉、计算机图形学、人脸动画、网络通信技术领域,具体是一种基于avatar表情移植的虚拟社交方法,能实时捕捉用户面部表情并在avatar上进行表情重演,并搭建网络通信技术的虚拟社交。
背景技术:
目前市场上的虚拟社交类系统如雨后春笋般涌现,其中商业思路也各有不同,主要分为工具性、ugc型和全体验型三种。工具型中以移动虚拟社交网络平台vtime最具代表性,通过vr头盔接入,头部运动来实现人机界面的交互控制以及虚拟世界的导航,语音进行沟通,但其提供的虚拟角色形象较为固定,支持的场景也相对简单;ugc型虚拟社交系统,提供高度开放的虚拟共享世界,并支持用户与朋友进行实时的交互式创建,其中基于3d摄影机的highfidelity,能捕捉人的表情和头部动作,如眨眼和嘴唇等动作,并同步到虚拟角色身上,提供更灵活的场景编辑和更丰富的交互体验,但这类应用依赖于辅助外设,如3d摄影机等;全方位体验型,主要以altspace和facebookspace为代表,其中altspacevr能让你在虚拟空间中和朋友会面、并在线聊天的社交应用,用户的头部运动和眨眼等动作也会被同步到虚拟角色身上,而facebookspace中,用户能上传自拍或者合拍的照片来打造适合自己的虚拟形象以及后续发型、五官编辑等工作,并根据语音识别普配出大概的发音嘴型,同时用户可借助手柄来实现简单动作的交互控制。
现有虚拟社交系统中,大部分只捕捉用户眨眼、口型以及头部运动等参数,缺乏对面部表情的捕捉,而面对面视频聊天中的非语言线索在沟通情绪、调节转折,实现和维持谈话关系方面发挥着至关重要的作用,其中面部表情是表达天生情感线索的最普遍标志,可以帮助我们更好地了解我们的对话者。由于表情捕捉、网络传输等技术限制,构建带有表情捕捉功能的虚拟社交系统带来很大挑战。基于此,本专利构建了一个基于avatar表情移植的虚拟社交系统。
技术实现要素:
本发明的目的在于:克服背景技术的不足,提供一种基于avatar表情移植的虚拟社交方法,能实时捕捉用户面部表情并在avatar上进行表情重演,并搭建网络通信技术的虚拟社交。为达到以上目的,本发明采用的构思为:利用sdm从实时输入的视频流中提取人脸特征点;2d面部语义特征作为cpr训练的dde模型的输入,输出的表情系数和头部运动参数移植给avatar;对dde模型输入的表情系数进行表情编码分组与情感分类;通过网络传输策略实现表情动画音频数据同步。
根据上述发明构思,本发明采用下述技术步骤:
一种基于avatar表情移植的虚拟社交方法,其特征在于具体操作步骤如下:
步骤一、利用sdm从实时输入的视频流中提取人脸特征点;
利用最小化非线性最小二乘函数的监督下降法sdm来实时提取人脸特征点,即在训练期间学习不同采样点的nls函数的平均值最小化的下降方向。在测试阶段,通过opencv人脸检测选择出人脸感兴趣区域并初始化平均2d形状模型,因此人脸对齐问题的求解就变成寻找梯度方向步长,于是使用学习下降的方向将nls最小化,从而实现实时的2d人脸特征点提取。
步骤二、面部语义特征作为cpr训练的dde模型的输入,输出的表情系数和头部运动参数移植给avatar
基于dde模型的cpr回归算法中,通过为3d形状模型的投影添加2d位移向量来弥补动态表情模型dem未校准匹配特定用户带来的精度误差,实现直接从视频流中回归头部姿势和表情的面部运动参数。首先利用facs建立包含中性面以及其他n个表情融合网格模型,即b={b0,b1,…,bn},然后由融合表情模型的线性组合来表示dem。并组织了50位不同年龄段的用户,通过kinect构造用户3d表情库来重建标准blendshape网格模型,其中单个用户的表情混合模型由b=c×ut参数化重建,u为用户身份向量,c为三级核心张量。而2d形状模型{sk}的特征点可通过3d网格模型相应顶点
在运行阶段,通过facewarehouse的平均身份向量来初始化u值,坐标系下降和二分查找的方法求解矩阵q。对于形状向量p,当新用户进入时,第一帧图像通过2d的cpr方法提取73个特征点,生成2d形状向量sk,与训练的3d形状向量
步骤三、对dde模型输出的表情系数进行表情编码分组与情感分类
在传输分组尺寸一定时,传输占用信道的时间与节点的传输速度成反比,因此网络传输速度降低时,通过实时自适应调整传输数据分组的尺寸,能极大地减少数据包占用信道的时间,显著提高网络性能。系统中通过调整表情系数的数量来设计三种不同尺寸的数据分组,但表情系数数量的降低,表情动画的移植也相应的会受到影响。为了测试不同表情系数对融合动画影响的程度,我们分别组织了50位动画专业的大学生参与系统测试和用户体验反馈。并根据1971年ekman和friesen研究6种基本表情(高兴、悲伤、惊讶、恐惧和厌恶)所建立的人脸表情图像库,建立自己的面部表情动作单元与表情间的映射关系。
步骤四、通过网络传输策略实现表情动画音频数据同步
同步是多媒体通信的主要特征,是多媒体系统服务质量(qos)研究中的重要内容,媒体间同步即要保持表情动画和音频之间的时间关系,但由于发送端在数据采集编码和数据解码等处理算法不同引起时间差,以及网络传输延迟等引起的失步。因此本发明中在发送端别对每次捕捉的表情系数和采样的语音数据打上相对时间戳,包括绝对时间和局部时间标志。在接收端,考虑到人对声音更为敏感,系统中选择音频作为主流,表情动画作为从流,主流连续播放,从流的播放由主流的播放状态决定,进而实现同步。
针对多点网络传输中的同步问题,由于不同客户端的时间戳可能按不同的速率推进,直接比较各自的时间戳很难实现多客户端间的同步,因此系统中将客户端的时间戳和服务端的参考时钟关联,组成时间戳对,所有组播网内的客户端共享参考时钟。
针对复杂网络环境下网速的降低,导致网络传输延迟和数据分组丢失严重的问题,本文中利用qos反馈机制来实时检测网络服务质量的变化,
当网络状况较好时,通过减少循环队列的长度,提高表情动画的实时性;
当网络状况较差时,通过增加循环队列的长度,用延迟换取表情动画和音频的流畅性;
该方法有效地降低网络抖动对表情动画和音频播放质量的影响,从而在实时性和流畅性之间保持平衡。
本发明与现有技术相比较,具有如下显而易见的突出实质性特点和显著优点,可实时捕捉用户面部表情,并移植到虚拟角色身上的网络社交平台。包括输入模块、表情重现模块、及时网络通信模块、可视化模块,所述输入模块,通过网络摄像头和麦克风实时捕捉用户脸部轮廓模型和语音信息,并借助鼠标键盘实现与虚拟场景和虚拟角色的交互控制;所述表情重现模块,通过sdm从视频流中实时提取人脸轮廓特征,并计算和cpr训练的3d形状模型投影的2d特征的均方根距离,找到10组最接近的形状模型后求取平均值,实现人脸表情形状模型的捕捉;利用facs对用户表情融合模型进行分解和编码,通过编码后表情捕捉的系数对用户情感进行分类,实现高兴、悲伤、惊讶三种情感的识别;表情捕捉完成后,移植给有相应形状融合变形动画的虚拟角色脸上,实现平顺、高精度的表情动画融合效果。所述即时网络通信模块,通过tcp协议搭建客户端和服务端面向连接的高可靠性网络传输,以及udp多播讨论组建立等操作,并利用网络通信策略,降低网络抖动对表情动画和音频播放质量的影响,实现表情-语音同步;所述可视化模块,对虚拟场景、表情系数驱动的人脸融合变形动画以及鼠标键盘交互控制的肢体动画等实时三维信息可视化,并通过人机交互界面实现用户好友列表管理以及场景、角色模型的编辑和切换等工作。本发明同时提供了一种基于sdm人脸特征点提取和cpr训练dde模型的人脸表情捕捉方法,该方法有效地解决了面部表情捕捉中需要校准特定用户和容错性低等问题。
附图说明
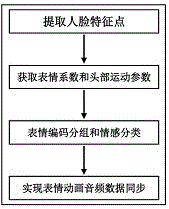
图1为本发明的程序框图。
图2为基于avatar表情移植的虚拟社交系统的系统架构图。
图3为表情捕捉系统在运行阶段形状向量p的求解过程。
图4为表情系数对面部表情动画融合影响程度的评估结果。
图5为建立的面部表情动作单元与表情间的映射关系。
图6为表情动画音频数据同步的算法流程图。
具体实施方式
下面结合附图以及具体实施方式进一步说明本发明。:
实施例一:
参见图1~图4,基于avatar表情移植的虚拟社交方法,其特征在于,具体步骤如下:
步骤一、利用sdm从实时输入的视频流中提取人脸特征点:
利用最小化非线性最小二乘函数的监督下降法sdm来实时提取人脸特征点,即在训练期间学习不同采样点的nls函数的平均值最小化的下降方向;在测试阶段,通过opencv人脸检测选择出人脸感兴趣区域并初始化平均2d形状模型,因此人脸对齐问题的求解就变成寻找梯度方向步长,于是使用学习下降的方向将nls最小化,从而实现实时的2d人脸特征点提取;
步骤二、面部语义特征作为cpr训练的dde模型的输入,输出的表情系数和头部运动参数移植给avatar:
基于dde模型的cpr回归算法中,通过为3d形状模型的投影添加2d位移向量来弥补动态表情模型dem未校准匹配特定用户带来的精度误差,实现直接从视频流中回归头部姿势和表情的面部运动参数;首先利用facs建立包含中性面以及其他n个表情融合网格模型,即b={b0,b1,…,bn},然后由融合表情模型的线性组合来表示dem。并组织了50位不同年龄段的用户,通过kinect构造用户3d表情库来重建标准blendshape网格模型,其中单个用户的表情混合模型由b=c×ut参数化重建,u为用户身份向量,c为三级核心张量;而2d形状模型{sk}的特征点可通过3d网格模型相应顶点
在运行阶段,通过facewarehouse的平均身份向量来初始化u值,坐标系下降和二分查找的方法求解矩阵q;而形状向量p的求解过程如图2所示,当新用户进入时,第一帧图像通过2d的cpr方法提取73个特征点,生成2d形状向量sk,与训练的3d形状向量
步骤三、对dde模型输出的表情系数进行表情编码分组与情感分类:
在传输分组尺寸一定时,传输占用信道的时间与节点的传输速度成反比,因此网络传输速度降低时,通过实时自适应调整传输数据分组的尺寸,能极大地减少数据包占用信道的时间,显著提高网络性能;系统中通过调整表情系数的数量来设计三种不同尺寸的数据分组,但表情系数数量的降低,表情动画的移植也相应的会受到影响。为了测试不同表情系数对融合动画影响的程度,我们分别组织了50位动画专业的大学生参与系统测试和用户体验反馈。并根据1971年ekman和friesen研究6种基本表情(高兴、悲伤、惊讶、恐惧和厌恶)所建立的人脸表情图像库,建立面部表情动作单元与表情间的映射关系;
步骤四、通过网络传输策略实现表情动画音频数据同步:
同步是多媒体通信的主要特征,是多媒体系统服务质量qos研究中的重要内容,媒体间同步即要保持表情动画和音频之间的时间关系,但由于发送端在数据采集编码和数据解码等处理算法不同引起时间差,以及网络传输延迟引起的失步;因此在发送端分别对每次捕捉的表情系数和采样的语音数据打上相对时间戳,包括绝对时间和局部时间标志。在接收端,考虑到人对声音更为敏感,系统中选择音频作为主流,表情动画作为从流,主流连续播放,从流的播放由主流的播放状态决定,进而实现同步;
针对多点网络传输中的同步问题,由于不同客户端的时间戳可能按不同的速率推进,直接比较各自的时间戳很难实现多客户端间的同步,因此系统中将客户端的时间戳和服务端的参考时钟关联,组成时间戳对,所有组播网内的客户端共享参考时钟;
针对复杂网络环境下网速的降低,导致网络传输延迟和数据分组丢失严重的问题,利用qos反馈机制来实时检测网络服务质量的变化,
1)当网络状况较好时,通过减少循环队列的长度,提高表情动画的实时性;
2)当网络状况较差时,通过增加循环队列的长度,用延迟换取表情动画和音频的流畅性;
该方法有效地降低网络抖动对表情动画和音频播放质量的影响,从而在实时性和流畅性之间保持平衡。
实施例二:
本实施例与实施例一基本相同,特别之处在于:
1.所述步骤一利用sdm从实时输入的视频流中提取人脸特征点的方法,从公共图像集中学习得到一系列下降的方向和该方向上的尺度,使得目标函数以非常快的速度收敛到最小值,从而回避了求解jacobian矩阵和hessian矩阵的问题。
2.根据权利要求1所述基于avatar表情移植的虚拟社交方法,其特征在于:所述步骤二中利用cpr训练的dde模型,获取表情系数和头部运动参数的方法:blendshape表情模型通过基础姿势的线性组合来实现表情动画的重演,不同人的给定面部表情对应于相似的一组基本权重,可以很方便地将表演者的面部表情传递给avatar。
3.根据权利要求1所述基于avatar表情移植的虚拟社交方法,其特征在于:所述步骤三中对表情系数进行表情编码分组与情感分类的方法:通过测试不同表情基础权重对avatar表情融合动画的影响程度,对表情系数进行分组,通过控制网络传输的分组长度,来提高系统对复杂网络条件的适应能力。通过建立面部表情动作单元与表情间的映射关系,实现高兴、悲伤、惊讶三种表情的识别,为虚拟社交提供智能化的提示功能。
4.根据权利要求1所述基于avatar表情移植的虚拟社交方法,其特征在于:所述步骤四中利用网络传输策略实现表情动画音频数据同步的方法:利用时间戳对和qos反馈机制的多点网络通信技术,降低网络抖动对表情动画和音频播放质量的影响,实现表情-语音同步。
实施例三:
基于avatar表情移植的虚拟社交方法,参见图1,主要步骤有:利用sdm从实时输入的视频流中提取人脸特征点;2d面部语义特征作为cpr训练的dde模型的输入,输出的表情系数和头部运动参数移植给avatar;对dde模型输出的表情系数进行表情编码分组与情感分类;通过网络传输策略实现表情动画音频数据同步,如图2所示。
1、利用sdm从实时输入的视频流中提取人脸特征点:
利用最小化非线性最小二乘函数的监督下降法sdm来实时提取人脸特征点,即在训练期间学习不同采样点的nls函数的平均值最小化的下降方向,在测试阶段通过先初始化平均2d形状模型,然后使用学习下降的方向将nls最小化,从而实现实时的2d人脸特征点提取。
对于给定测试图像d∈rm×1(即把图像从左向右、从上至下展开成m个像素的一维向量),d(x)∈rp×1表示图像中第p个标记点的索引,h(d(x))∈r(128*p)×1表示非线性特征提取函数,如sift特征,其中128表示每个特征点有128维度。在测试阶段,通过opencv人脸检测选择出人脸感兴趣区域,并初始化一组平均人脸标记点,因此人脸对齐问题的求解就变成寻找梯度方向步长δx,使得目标函数(1)误差最小:
其中
其中,h和j分别表示hessian矩阵jacobian矩阵,但矩阵h和j的计算开销太大,因此可以直接计算他们的乘积,即上述公式可转变为:
其中
其中di表示第i张训练图片,
2、面部语义特征作为cpr训练的dde模型的输入,输出表情系数和头部运动参数移植给avatar:
基于dde模型的cpr回归算法中,通过为3d形状模型的投影添加2d位移向量来弥补动态表情模型dem未校准匹配特定用户带来的精度误差,实现直接从视频流中回归头部姿势和表情的面部运动参数。首先利用facs建立包含中性面以及其他n个表情融合网格模型,即b={b0,b1,…,bn},然后由融合表情模型的线性组合来表示dem,如公式(1)所示,其中e为表情系数,r为头部旋转四元数,t位移向量。
f=r(bet)+t=r(c×utet)+t(5)
并组织了50位不同年龄段的用户,通过kinect构造用户3d表情库来重建标准blendshape网格模型,其中单个用户的表情混合模型由b=c×ut参数化重建,u为用户身份向量,c为三级核心张量。而2d形状模型{sk}的特征点可通过3d网格模型相应顶点
然后利用cpr回归算法完成dde模型的未知量(q,u;e,r,t,d)到2d形状模型{sk}的函数映射,即cpr(i,q,u;pin)=pout,其中形状向量p=(e,r,t,d)。
在运行阶段,通过facewarehouse的平均身份向量来初始化u值,坐标系下降和二分查找的方法求解矩阵q。而形状向量p的求解过程如图2所示,当新用户进入时,第一帧图像通过2d的cpr方法提取73个特征点,生成2d形状向量sk,与训练的3d形状向量
3、对dde模型输出的表情系数进行表情编码分组与情感分类:
在传输分组尺寸一定时,传输占用信道的时间与节点的传输速度成反比,因此网络传输速度降低时,通过实时自适应调整传输数据分组的尺寸,能极大地减少数据包占用信道的时间,显著提高网络性能。系统中通过调整表情系数的数量来设计三种不同尺寸的数据分组,但表情系数数量的降低,表情动画的移植也相应的会受到影响。为了测试不同表情系数对融合动画影响的程度,我们分别组织了50位动画专业的大学生参与系统测试和用户体验反馈。用户先体验51位系数表情重演的动画效果后,关闭其中某个系数(若系数有左右之分则都关闭),并要求用户演练该系数控制的相应脸部动作,再评价该系数对体验的影响,并统计每个表情系数评估的平均分数,结果如图4所示,快中慢三种网速模式下分别传输7、26、51位系数,由红绿蓝三角形标识(其中,1:非常大,2:大,3:适中,4:不太大,5小)。
并根据1971年ekman和friesen研究6种基本表情(高兴、悲伤、惊讶、恐惧和厌恶)所建立的人脸表情图像库,建立自己的面部表情动作单元与表情间的映射关系,如图5所示,然后通过阈值判断对用户情感进行分类后驱动同种类不同动画的播放,为虚拟社交系统实现更为丰富多样的视频化效果。
4、通过网络传输策略实现表情动画音频数据同步:
同步是多媒体通信的主要特征,是多媒体系统服务质量(qos)研究中的重要内容,媒体间同步即要保持表情动画和音频之间的时间关系,但由于发送端在数据采集编码和数据解码等处理算法不同引起时间差,以及网络传输延迟等引起的失步。
如图6所示,发送端分别对每次捕捉的表情系数和采样的语音数据打上相对时间戳,包括绝对时间和局部时间标志。根据表情捕捉的帧率和音频采样的速率来动态地控制时间戳的递增速率,同一时间采集的数据打上同样的时间戳,并在同一线程中交替发送数据包;
在接收端,当数据分组到达时,先利用litjson进行反序列化,针对音频数据还需zlib进行解码,然后分别存入各自的动态循环队列中。考虑到人对声音更为敏感,系统中选择音频作为主流,表情动画作为从流,主流连续播放,从流的播放由主流的播放状态决定,进而实现同步。当循环队列都填充满后,定时从动态循环队列中提取音频数据分组,在实例化的虚拟化身嘴部播放,并记录当前播放数据的时间戳。在表情动画播放方面,采用事件驱动的方式来对avatar应用表情系数。当接收到新的表情数据分组时,存入表情动态循环队列,并提取数据分组的时间戳和记录的音频时间戳比较:
1)若处于同步区域中间,则播放当前表情动画数据;
2)若滞后于同步区域,则丢弃数据;
3)若超前该同步区域,则等待下次;
针对多点网络传输中的同步问题,由于不同客户端的时间戳可能按不同的速率推进,直接比较各自的时间戳很难实现多客户端间的同步,因此系统中将客户端的时间戳和服务端的参考时钟关联,组成时间戳对,所有组播网内的客户端共享参考时钟。
针对复杂网络环境下网速的降低,导致网络传输延迟和数据分组丢失严重的问题,本文中利用qos反馈机制来实时检测网络服务质量的变化,其中反馈信息包括了估算分组丢失和分组延迟抖动等信息。数据分组中的序列号除了用于对数据包排序外,还用于统计分组丢失的情况,而抖动延迟则通过时间戳进行计算。
当丢包率和抖动达到阈值时反馈给发送端,调整网络传输中分组的长度,在音频方面,调整音频采样时间来控制数据分组在mtu(最大传输单元)内,从而无需采用分片封包模式,在表情系数方面,自适应调整表情模式,减少需要传输的表情系数,为音频传输减少带宽负担。同时接收端会调整动态循环队列的长度:
1)当网络状况较好时,通过减少循环队列的长度,提高表情动画的实时性;
2)当网络状况较差时,通过增加循环队列的长度,用延迟换取表情动画和音频的流畅性;
该方法有效地降低网络抖动对表情动画和音频播放质量的影响,从而在实时性和流畅性之间保持平衡。
- 还没有人留言评论。精彩留言会获得点赞!