一种基于储存受限数据库的私人信息检索方法与流程
本发明涉及信息检索领域,尤其是涉及了一种基于储存受限数据库的私人信息检索方法。
背景技术:
信息检索是指信息按一定的方式组织起来,并根据信息用户的需要找出有关的信息的过程和技术,而私人信息检索是一个重要的安全多方计算协议,它是指用户向数据库提交数据查询请求时,在保证用户的查询信息不被数据库知道的情况下完成查询。私人信息检索在信息安全领域有着广阔的应用前景,如在多个情报部门的合作查询中,若某部门需要查询其他部门的数据库,但查询条件包含敏感信息而不能泄露给被查询部门时,就需要私人信息检索来完成该任务。如今,社会经济发展迅速,竞争也越来越激烈,商业竞争中企业信息检索也成为继互联网、数据库、数据挖掘之后企业关注的下一个技术热点,因此利用私人信息检索方法可以在保证企业隐私的情况下查询竞争者的信息;同样地,私人信息检索也可以在军事合作中应用,在保证合作双方机密信息不外泄的情况下,相互查询合作过程中的所需信息。但目前私人信息检索方法仍然存在实用性不强、数据库被过度复制且计算复杂度过高等问题。
本发明提出了一种基于储存受限数据库的私人信息检索方法,考虑到存储受限数据库中的私人信息检索问题,首先标记每个数据库的储存容量,其中包括信息的数量、每个信息的大小以及规范化的储存,允许用户决定内容所需的储存数据库,假定用户使用的储存策略是完全公开的,然后规一化储存参数,令跨数据集存储的内容满足规定的存储限制,最后在存储受限的数据库中,利用私人信息检索方法建立一个可用的储存方案。本发明为数据库中存储的信息提供一个通用的私人信息检索方案,解决了数据库被过度复制的问题,进一步简化了计算方法。
技术实现要素:
针对实用性不强、数据库被过度复制且计算复杂度过高的问题,本发明提出了一种基于储存受限数据库的私人信息检索方法,考虑到存储受限数据库中的私人信息检索问题,首先标记每个数据库的储存容量,其中包括信息的数量、每个信息的大小以及规范化的储存,允许用户决定内容所需的储存数据库,假定用户使用的储存策略是完全公开的,然后规一化储存参数,令跨数据集存储的内容满足规定的存储限制,最后在存储受限的数据库中,利用私人信息检索方法建立一个可用的储存方案。
为解决上述问题,本发明提出一种基于储存受限数据库的私人信息检索方法,其主要内容包括:
(一)跨数据集储存内容;
(二)储存限制信息;
(三)储存方案。
其中,所述的跨数据集储存内容,每个数据库的储存容量为μKL位,其中K是信息的数量,L是每个信息的大小,并且μ∈[1/N,1]是规范化的储存,N为数据集数量。
进一步地,所述的数据库,从储存受限的数据库中,为储存的任何信息提供一个通用的私人信息检索(PIR)方案,对于任意(N,K),归一化储存μ=t/N,其中参数t可以取整数值,令t∈{1,2,…,N},当t=N时,对应复制数据库的设置可以完整储存。
其中,所述的储存限制信息,考虑到一个PIR有N个非串通数据库和K个独立信息,其中每个信息大小为L位,由以下等式给定:
H(W1)=H(W2)=…=H(Wk)=L (1)
假设每个数据库都有μKL位的储存容量,用Z1,Z2,…,ZN表示跨数据库储存的内容,对于每个数据库都有以下储存限制:
H(Z1)=H(Z2)=…=H(ZN)=μKL (2)
允许用户决定内容所需的储存数据库,假定用户使用的储存策略是完全公开的,归一化储存参数μ,μ的取值范围为1/N≤μ≤1,μ=1时复制数据库的设置,其中,μ≥1/N是解码的必要条件。
进一步地,所述的信息,为了查询信息,用户在1和K之间选择数字θ用来对应所需要的信息,然后用户生成H个查询将其发送到N个数据库,角标θ表示期望得到的信息,可以替代K中的任意一个,在用户决定访问信息的时候必须保证隐私,因此,查询必须独立于信息之外:
通过向第n个数据库发送查询请求来查询信息,然后生成并向用户返回结果,用于查询的函数储存在第n个数据库中,通过以下等式给定:
从每个数据库的所有结果中,用户必须以较小的错误概率正确地解码需要的信息Wk,正确性约束如下:
其中,o(L)表示L的函数,使得当L接近无穷大时,o(L)/L接近0。
进一步地,所述的储存参数,对于储存参数μ,如果储存限制PIR方案具有储存、查询和解码功能,则满足(D,L)的储存、正确性要求和隐私约束条件,PIR方案的性能由每个下载位中期望信息L的位数来表征,如果D是下载位的总数,并且L是所需信息的大小,则标准化的下载成本是D/L,即PIR率是D/L,将最优的标准化下载成本描述为数据集储存参数μ的函数:
D*(μ)=min{D/L:(D,L)是可行的} (7)
PIR的储存限制容量是归一化下载成本的倒数:
C*(μ)=max{D/L:(D,L)是可行的} (8)
以上函数表明最优下载成本D*(μ)是归一化储存μ的凸函数
进一步地,所述的凸函数,对于任何(μ1,μ2)和α∈[0,1],最佳下载成本满足以下条件:
D*(αμ1+(1-α)μ1)≤αD*(μ1)+(1-α)D*(μ2) (9)
分别使用两个储存限制PIR方案,计算两个储存参数μ1和μ2,获得最优下载成本D*(μ1)和D*(μ2),再计算一个新的储存点μ=αμ1+(1-α)μ2,构造一个PIR方案如下:把每个信息Wi分成两个独立的部分的大小为L1=αL位,的大小为L2=(1-α)L位,每条信息的总大小为L。
进一步地,所述的储存限制,对于具有N个数据库,K个信息和每个数据库储存限制为μKL位的储存限制PIR问题,在(μ,D(μ))中可以实现较低的凸包:
其中,t=1,2,…,N。
其中,所述的储存方案,在μ=t/N的储存方案中,对于固定参数t∈[1,…,N],把每条信息Wi细分成个子信息,每个子信息由大小为t的数据库的子集索引,例如:如果t=1,N=2,那么每个信息Wi将被细分为个子信息,Wi=(Wi(1,2),Wi(2,3),Wi(1,3)),假设每个子信息的大小为tK位,因此每个信息的总大小L给定为通过这种信息分解法,提出的储存方案如下:对于每个信息,每个数据库储存所有包含其索引的子信息,对于t=2,N=3的数据库和K=2的信息,储存策略如下:
●DB1储存A12,A13,A12,A13
●DB2储存A12,A23,A12,A23
●DB3储存A13,A23,A13,A23
其中,每个信息分别被拆分为A=(A12,A23,A13)和B=(B12,B23,B13)。
进一步地,所述的子信息,对于每条信息,每个数据库储存子信息,因此,任何数据库所需的总储存量为:
这表明该方案满足每个数据库的储存限制。
附图说明
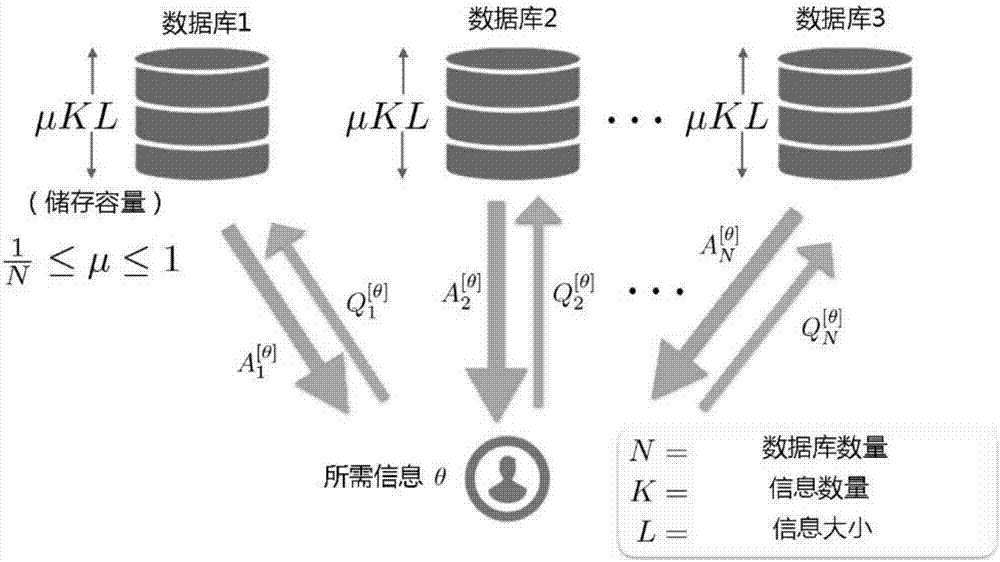
图1是本发明一种基于储存受限数据库的私人信息检索方法的系统框架图。
图2是本发明一种基于储存受限数据库的私人信息检索方法的储存限制信息图。
图3是本发明一种基于储存受限数据库的私人信息检索方法的储存限制的结果图。
具体实施方式
需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互结合,下面结合附图和具体实施例对本发明作进一步详细说明。
图1是本发明一种基于储存受限数据库的私人信息检索方法的系统框架图。主要包括跨数据集储存内容、储存限制信息、储存方案。
其中,所述的跨数据集储存内容,每个数据库的储存容量为μKL位,其中K是信息的数量,L是每个信息的大小,并且μ∈[1/N,1]是规范化的储存,N为数据集数量。
进一步地,所述的数据库,从储存受限的数据库中,为储存的任何信息提供一个通用的私人信息检索(PIR)方案,对于任意(N,K),归一化储存μ=t/N,其中参数t可以取整数值,令t∈{1,2,…,N},当t=N时,对应复制数据库的设置可以完整储存。
图2是本发明一种基于储存受限数据库的私人信息检索方法的储存限制信息图。考虑到一个PIR有N个非串通数据库和K个独立信息,其中每个信息大小为L位,由以下等式给定:
H(W1)=H(W2)=…=H(Wk)=L (1)
假设每个数据库都有μKL位的储存容量,用Z1,Z2,…,ZN表示跨数据库储存的内容,对于每个数据库都有以下储存限制:
H(Z1)=H(Z2)=…=H(ZN)=μKL (2)
允许用户决定内容所需的储存数据库,假定用户使用的储存策略是完全公开的,归一化储存参数μ,μ的取值范围为1/N≤μ≤1,μ=1时复制数据库的设置,其中,μ≥1/N是解码的必要条件。
进一步地,所述的信息,为了查询信息,用户在1和K之间选择数字θ用来对应所需要的信息,然后用户生成N个查询将其发送到N个数据库,角标θ表示期望得到的信息,可以替代K中的任意一个,在用户决定访问信息的时候必须保证隐私,因此,查询必须独立于信息之外:
通过向第n个数据库发送查询请求来查询信息,然后生成并向用户返回结果,用于查询的函数储存在第n个数据库中,通过以下等式给定:
从每个数据库的所有结果中,用户必须以较小的错误概率正确地解码需要的信息Wk,正确性约束如下:
其中,o(L)表示L的函数,使得当L接近无穷大时,o(L)/L接近0。
进一步地,所述的储存参数,对于储存参数μ,如果储存限制PIR方案具有储存、查询和解码功能,则满足(D,L)的储存、正确性要求和隐私约束条件,PIR方案的性能由每个下载位中期望信息L的位数来表征,如果D是下载位的总数,并且L是所需信息的大小,则标准化的下载成本是D/L,即PIR率是D/L,将最优的标准化下载成本描述为数据集储存参数μ的函数:
D*(μ)=min{D/L:(D,L)是可行的} (7)
PIR的储存限制容量是归一化下载成本的倒数:
C*(μ)=max{D/L:(D,L)是可行的} (8)
以上函数表明最优下载成本D*(μ)是归一化储存μ的凸函数
其中,所述的凸函数,其特征在于,对于任何(μ1,μ2)和α∈[0,1],最佳下载成本满足以下条件:
D*(αμ1+(1-α)μ1)≤αD*(μ1)+(1-α)D*(μ2) (9)
分别使用两个储存限制PIR方案,计算两个储存参数μ1和μ2,获得最优下载成本D*(μ1)和D*(μ2),再计算一个新的储存点μ=αμ1+(1-α)μ2,的大小为L1=αL位,的大小为L2=(1-α)L位,每条信息的总大小为L。
图3是本发明一种基于储存受限数据库的私人信息检索方法的储存限制的结果图。当μ=1/N最小值的对应参数t=1时,其下载成本最大,且下载成本为K,储存的另一个极值μ=1时,t=N。
对于具有N个数据库,K个信息和每个数据库储存限制为μKL位的储存限制PIR问题,在(μ,D(μ))中可以实现较低的凸包:
其中,t=1,2,…,N。
其中,所述的储存方案,在μ=t/N的储存方案中,对于固定参数t∈[1,…,N],把每条信息Wi细分成个子信息,每个子信息由大小为t的数据库的子集索引,例如:如果t=1,N=2,那么每个信息Wi将被细分为个子信息,Wi=(Wi(1,2),Wi(2,3),Wi(1,3)),假设每个子信息的大小为tK位,因此每个信息的总大小L给定为通过这种信息分解法,提出的储存方案如下:对于每个信息,每个数据库储存所有包含其索引的子信息,对于t=2,N=3的数据库和K=2的信息,储存策略如下:
●DB1储存A12,A13,A12,A13
●DB2储存A12,A23,A12,A23
●DB3储存A13,A23,A13,A23
其中,每个信息分别被拆分为A=(A12,A23,A13)和B=(B12,B23,B13)。
进一步地,所述的子信息,对于每条信息,每个数据库储存子信息,因此,任何数据库所需的总储存量为:
这表明该方案满足每个数据库的储存限制。
对于本领域技术人员,本发明不限制于上述实施例的细节,在不背离本发明的精神和范围的情况下,能够以其他具体形式实现本发明。此外,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围,这些改进和变型也应视为本发明的保护范围。因此,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
- 还没有人留言评论。精彩留言会获得点赞!