一种基于微实数的异步排序方法及装置与流程
本发明涉及区块链技术领域,更具体的,涉及一种基于微实数的异步排序方法及装置。
背景技术:
对于异步系统而言,因为各节点存在信息接收的差异性,数据的产生时间并不能唯一决定数据最终的顺序。目前的区块链系统对多个数据进行排序的具体步骤是:由任意一个节点取若干数据打包成区块在节点间进行同步,通过一致性算法(也称共识)保证各节点均接收到并确认该数据有效,各节点将其记入本地的区块链副本中。完成本轮操作后,随机取下一组数据进行共识,直至将数据全部取出,完成排序。因为需要保证数据链的稳定有序,区块链系统的初始规则要求后一个区块在共识前需要包含前一个区块的摘要(如哈希值)。
由此可知,数据实际的顺序是按照各节点对其完成共识的时间进行确定的。每一个区块必须包含前一个区块的摘要,以保证区块链系统的链状数据结构稳定和唯一。对于任何已公开区块链系统,在前一个区块未产生时,后一个区块是无法处理并生成的,这就使整体系统在单位时间内只能处理一个区块。因此,上述方法无法应用于高并发的异步系统中。
技术实现要素:
有鉴于此,本发明提供了一种基于微实数的异步排序方法及装置,解决异步系统中大规模并发请求的处理,以及在此环境下数据的排序问题。
为了实现上述发明目的,本发明提供的具体技术方案如下:
一种基于微实数的异步排序方法,应用于区块链中任意一个节点,所述方法包括:
接收区块链中任一节点发送的目标待存储数据的基础数据,生成携带有所述目标待存储数据的第一轮建议值的所述目标待存储数据的第一轮投票数据,并将所述目标待存储数据的第一轮投票数据通讯至其他节点,所述目标待存储数据为区块链中任一待存储数据;
接收区块链中任一节点发送的所述目标待存储数据的第r轮投票数据,1<r≤r,r为预设最高投票轮数,当接收到的所述目标待存储数据第r轮投票数据的数量与区块链中全部节点数量的比值达到预设最低投票比值时,得到所述目标待存储数据第r轮投票数据集合;
根据所述目标待存储数据第r轮投票数据集合判断当前是否满足结束对所述目标待存储数据投票的条件;
若是,根据预设收敛函数和所述目标待存储数据第r轮投票数据集合计算所述目标待存储数据的共识终值,生成携带有所述目标待存储数据的共识终值和所述目标待存储数据第r轮投票数据集合的所述目标待存储数据的投票结果,并将所述目标待存储数据的投票结果通讯至其他节点;
若否,根据所述目标待存储数据第r轮投票数据集合和所述预设收敛函数,计算所述目标待存储数据的第(r+1)轮建议值,生成携带有所述目标待存储数据的第(r+1)轮建议值和所述目标待存储数据第r轮投票数据集合的所述目标待存储数据的第(r+1)轮投票数据,并将所述目标待存储数据的第(r+1)轮投票数据通讯至其他节点;
当得到批量多个待存储数据的投票结果时,根据当前批次每个所述待存储数据的投票终值对当前批次每个待存储数据进行排序,得到当前批次待存储数据的排序结果;
当区块链中所有节点对当前批次待存储数据的排序结果达成共识后,根据当前批次待存储数据的排序结果对当前批次待存储数据进行存储。
优选的,所述方法还包括:
根据自身私钥对所述目标待存储数据进行加密,得到对所述目标待存储数据的签名,并对所述目标待存储数据的签名、自身公钥和所述目标待存储数据进行封装,得到所述待存储数据的基础数据。
可选的,所述生成携带有所述目标待存储数据的第一轮建议值的所述目标待存储数据的第一轮投票数据,其中,生成所述目标待存储数据的第一轮建议值,包括:
将所述目标待存储数据的时间戳确定为所述目标待存储数据的第一轮建议值,所述目标待存储数据的时间戳为相应节点接收到所述目标待存储数据的时间。
可选的,所述生成携带有所述目标待存储数据的第一轮建议值的所述目标待存储数据的第一轮投票数据,其中,生成所述目标待存储数据的第一轮建议值,包括:
根据随机函数生成一个随机整数,将所述随机整数确定为所述目标待存储数据的第一轮建议值。
可选的,所述生成携带有所述目标待存储数据的第一轮建议值的所述目标待存储数据的第一轮投票数据,其中,生成所述目标待存储数据的第一轮建议值,包括:
对当前时间保存的数据总量与随机函数生成一个随机整数进行求和,得到扩展数据编号,将所述扩展数据编号确定为所述目标待存储数据的第一轮建议值。
优选的,所述生成携带有所述目标待存储数据的第一轮建议值的所述目标待存储数据的第一轮投票数据,包括:
对自身公钥、所述目标待存储数据的第一轮建议值、所述目标待存储数据的第一轮建议值的签名和所述目标待存储数据信息进行封装,得到封装包;
根据自身私钥对所述封装包进行加密,得到所述封装包的签名;
根据所述封装包和所述封装包的签名,生成所述目标待存储数据的第一轮投票数据。
可选的,根据所述目标待存储数据第r轮投票数据集合判断当前是否满足结束对所述目标待存储数据投票的条件:
提取所述目标待存储数据第r轮投票数据集合中各个建议值,组成所述目标待存储数据第r轮建议值集合;
计算所述目标待存储数据第r轮建议值集合中最大建议值与最小建议值的差值,得到第一差值;
提取所述目标待存储数据各轮投票数据集合中各个建议值,组成所述目标待存储数据各轮建议值集合;
计算得到的所述目标待存储数据各轮建议值集合中最大建议值与最小建议值的差值,得到第二差值;
计算所述第一差值与所述第二差值的比值;
判断所述第一差值与所述第二差值的比值是否大于预设收敛值;
若是,判定当前不满足结束对所述目标待存储数据投票的条件;
若否,判定当前满足结束对所述目标待存储数据投票的条件。
可选的,根据所述目标待存储数据第r轮投票数据集合判断当前是否满足结束对所述目标待存储数据投票的条件:
提取所述目标待存储数据第r轮投票数据集合中各个建议值,组成所述目标待存储数据第r轮建议值集合;
根据预设收敛函数计算得到所述目标待存储数据第r轮建议值集合的1-α置信区间,并计算1-α置信区间上限和1-α置信区间下限的差值,得到第三差值;
提取所述目标待存储数据各轮投票数据集合中各个建议值,组成所述目标待存储数据各轮建议值集合;
根据预设收敛函数计算得到的所述目标待存储数据各轮建议值集合的1-α置信区间,并计算各轮建议值集合的1-α置信区间上限和下限的差值,得到第四差值;
计算所述第三差值与所述第四差值的比值;
判断所述第三差值与所述第四差值的比值是否大于预设收敛值;
若是,判定当前不满足结束对所述目标待存储数据投票的条件;
若否,判定当前满足结束对所述目标待存储数据投票的条件。
一种基于微实数的异步排序装置,包括:
第一轮投票数据生成单元,用于接收区块链中任一节点发送的目标待存储数据的基础数据,生成携带有所述目标待存储数据的第一轮建议值的所述目标待存储数据的第一轮投票数据,并将所述目标待存储数据的第一轮投票数据通讯至其他节点,所述目标待存储数据为区块链中任一待存储数据;
第r轮投票数据生成单元,用于接收区块链中任一节点发送的所述目标待存储数据的第r轮投票数据,1<r≤r,r为预设最高投票轮数,当接收到的所述目标待存储数据第r轮投票数据的数量与区块链中全部节点数量的比值达到预设最低投票比值时,得到所述目标待存储数据第r轮投票数据集合;
判断单元,用于根据所述目标待存储数据第r轮投票数据集合判断当前是否满足结束对所述目标待存储数据投票的条件;若是,触发投票结果计算单元,若否,触发第(r+1)轮投票数据生成单元;
所述投票结果计算单元,用于根据预设收敛函数和所述目标待存储数据第r轮投票数据集合计算所述目标待存储数据的共识终值,生成携带有所述目标待存储数据的共识终值和所述目标待存储数据第r轮投票数据集合的所述目标待存储数据的投票结果,并将所述目标待存储数据的投票结果通讯至其他节点;
所述第(r+1)轮投票数据生成单元,用于根据所述目标待存储数据第r轮投票数据集合和所述预设收敛函数,计算所述目标待存储数据的第(r+1)轮建议值,生成携带有所述目标待存储数据的第(r+1)轮建议值和所述目标待存储数据第r轮投票数据集合的所述目标待存储数据的第(r+1)轮投票数据,并将所述目标待存储数据的第(r+1)轮投票数据通讯至其他节点;
排序单元,用于当得到批量多个待存储数据的投票结果时,根据当前批次每个所述待存储数据的投票终值对当前批次每个待存储数据进行排序,得到当前批次待存储数据的排序结果;
存储单元,用于当区块链中所有节点对当前批次待存储数据的排序结果达成共识后,根据当前批次待存储数据的排序结果对当前批次待存储数据进行存储。
可选的,所述装置还包括:
基础数据生成单元,用于根据自身私钥对所述目标待存储数据进行加密,得到对所述目标待存储数据的签名,并对所述目标待存储数据的签名、自身公钥和所述目标待存储数据进行封装,得到所述待存储数据的基础数据。
可选的,所述第一轮投票数据生成单元包括:
第一建议值生成子单元,用于将所述目标待存储数据的时间戳确定为所述目标待存储数据的第一轮建议值,所述目标待存储数据的时间戳为相应节点接收到所述目标待存储数据的时间。
可选的,所述第一轮投票数据生成单元包括:
第二建议值生成子单元,用于根据随机函数生成一个随机整数,将所述随机整数确定为所述目标待存储数据的第一轮建议值。
可选的,所述第一轮投票数据生成单元包括:
第三建议值生成子单元,用于对当前时间保存的数据总量与随机函数生成一个随机整数进行求和,得到扩展数据编号,将所述扩展数据编号确定为所述目标待存储数据的第一轮建议值。
优选的,所述第一轮投票数据生成单元包括:
封装子单元,用于对自身公钥、所述目标待存储数据的第一轮建议值、所述目标待存储数据的第一轮建议值的签名和所述目标待存储数据信息进行封装,得到封装包;
加密子单元,用于根据自身私钥对所述封装包进行加密,得到所述封装包的签名;
投票数据生成子单元,用于根据所述封装包和所述封装包的签名,生成所述目标待存储数据的第一轮投票数据。
可选的,所述判断单元包括:
第一提取子单元,用于提取所述目标待存储数据第r轮投票数据集合中各个建议值,组成所述目标待存储数据第r轮建议值集合;
第一计算子单元,用于计算所述目标待存储数据第r轮建议值集合中最大建议值与最小建议值的差值,得到第一差值;
第二提取子单元,用于提取所述目标待存储数据各轮投票数据集合中各个建议值,组成所述目标待存储数据各轮建议值集合;
第二计算子单元,用于计算得到的所述目标待存储数据各轮建议值集合中最大建议值与最小建议值的差值,得到第二差值;
第三计算子单元,用于计算所述第一差值与所述第二差值的比值;
第一判断子单元,用于判断所述第一差值与所述第二差值的比值是否大于预设收敛值;若是,触发第一判定子单元,若否,触发第二判定子单元;
所述第一判定子单元,用于判定当前不满足结束对所述目标待存储数据投票的条件;
所述第二判定子单元,用于判定当前满足结束对所述目标待存储数据投票的条件。
可选的,所述判断单元包括:
第一提取子单元,用于提取所述目标待存储数据第r轮投票数据集合中各个建议值,组成所述目标待存储数据第r轮建议值集合;
第四计算子单元,用于根据预设收敛函数计算得到所述目标待存储数据第r轮建议值集合的1-α置信区间,并计算1-α置信区间上限和1-α置信区间下限的差值,得到第三差值;
第二提取子单元,用于提取所述目标待存储数据各轮投票数据集合中各个建议值,组成所述目标待存储数据各轮建议值集合;
第五计算子单元,用于根据预设收敛函数计算得到的所述目标待存储数据各轮建议值集合的1-α置信区间,并计算各轮建议值集合的1-α置信区间上限和下限的差值,得到第四差值;
第六计算子单元,用于计算所述第三差值与所述第四差值的比值;
第二判断子单元,用于判断所述第三差值与所述第四差值的比值是否大于预设收敛值;若是,触发第一判定子单元,若否,触发第二判定子单元;
所述第一判定子单元,用于判定当前不满足结束对所述目标待存储数据投票的条件;
所述第二判定子单元,用于判定当前满足结束对所述目标待存储数据投票的条件。
相对于现有技术,本发明的有益效果如下:
本发明提供的一种基于微实数的异步排序方法及装置,区块链中每个节点对连续进入系统的待存储数据中每个待存储数据的顺序进行独立共识,使用预设收敛函数保证每个节点在排序共识的投票过程中达到一致。对于不同待存储数据的共识产生不同的结果,当得到批量多个待存储数据的投票结果时,根据当前批次每个所述待存储数据的投票结果对当前批次每个待存储数据进行排序,得到当前批次待存储数据的排序结果;当区块链中所有节点对当前批次待存储数据的排序结果达成共识后,根据当前批次待存储数据的排序结果对当前批次待存储数据进行存储,进而在多轮并发的共识过程中,同步对各轮同步进行排序,实现了高并发的异步系统中对待存储数据进行存储。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
图1为本发明实施例公开的一种基于微实数的异步排序方法流程图;
图2为本发明实施例公开的一种判断当前是否满足结束对所述目标待存储数据投票的条件的方法流程图;
图3为本发明实施例公开的另一种判断当前是否满足结束对所述目标待存储数据投票的条件的方法流程图;
图4为本发明场景实施例中{vj(r+1)}与{ci(r)}之间的关系示意图;
图5为本发明场景实施例中共识流程示意图;
图6为本发明场景实施例中集群中各个节点对同一批次待存储数据的排序结果示意图;
图7为本发明a场景中最低投票比值s对共识次数的影响(故障节点占比10%)示意图;
图8为本发明b场景中最低投票比值s对共识次数的影响(故障节点占比33%)示意图;
图9为本发明c场景中最低投票比值s对共识次数的影响(故障节点占比40%)示意图;
图10为本发明d场景中最低投票比值s对共识次数的影响(故障节点占比49%)示意图;
图11为本发明e场景2笔交易并行排序原始数据分布示意图;
图12为本发明e场景2笔交易并行排序第一轮投票后数据分布示意图;
图13为本发明e场景2笔交易并行排序完成共识后数据分布示意图;
图14为本发明实施例公开的一种基于微实数的异步排序装置结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
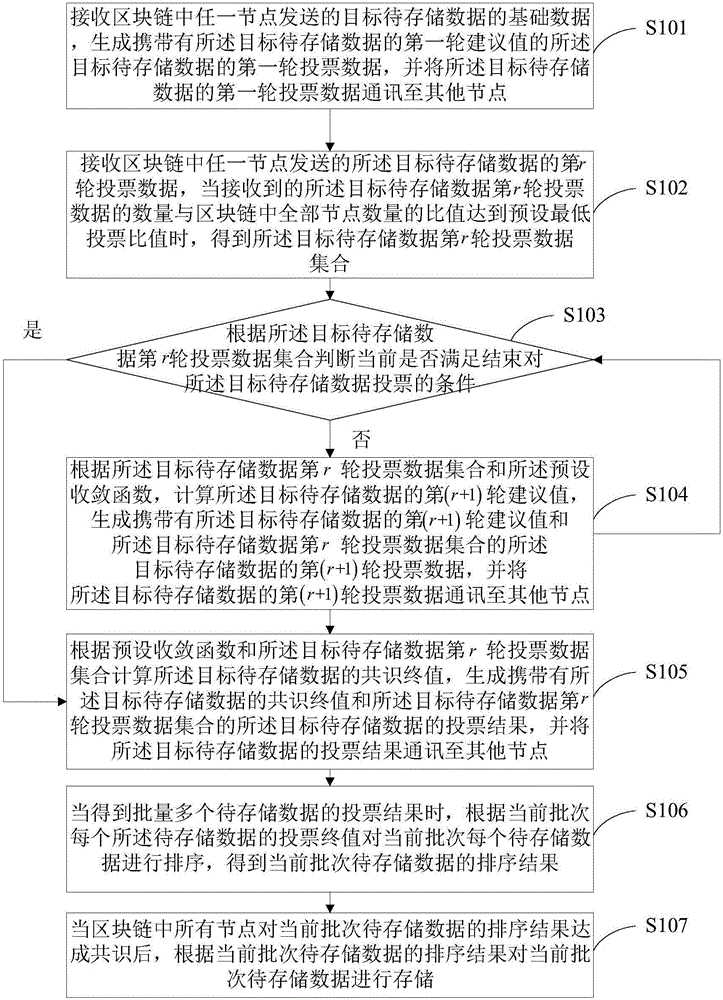
请参阅图1,本实施例公开了一种基于微实数的异步排序方法,应用于区块链中任意一个节点,所述方法具体包括以下步骤:
s101:接收区块链中任一节点发送的目标待存储数据的基础数据,生成携带有所述目标待存储数据的第一轮建议值的所述目标待存储数据的第一轮投票数据,并将所述目标待存储数据的第一轮投票数据通讯至其他节点;
所述目标待存储数据为区块链中任一待存储数据;
通讯可以为多种通讯方式,如单播(1个节点对1个节点)、多播(1个节点对多个节点)和广播(1个节点对全部节点)。
需要说明的是,在s101之前所述方法还包括:
根据自身私钥对所述目标待存储数据进行加密,得到对所述目标待存储数据的签名,并对所述目标待存储数据的签名、自身公钥和所述目标待存储数据进行封装,得到所述待存储数据的基础数据。
每个节点都包括相应的公钥和私钥,每个节点的公钥不同,每个节点的私钥也不同。
生成所述目标待存储数据的第一轮建议值的方法可以有多种,本实施例提供了以下三种方法:
方式一
将所述目标待存储数据的时间戳确定为所述目标待存储数据的第一轮建议值,所述目标待存储数据的时间戳为相应节点接收到所述目标待存储数据的时间。
方式二
根据随机函数生成一个随机整数,将所述随机整数确定为所述目标待存储数据的第一轮建议值。
方式三
对当前时间保存的数据总量与随机函数生成一个随机整数进行求和,得到扩展数据编号,将所述扩展数据编号确定为所述目标待存储数据的第一轮建议值。
当前时间保存的数据总量可以为所述节点保存的最大数据区块的编号等,本发明并不以此为限。
所述生成携带有所述目标待存储数据的第一轮建议值的所述目标待存储数据的第一轮投票数据,包括:
对自身公钥、所述目标待存储数据的第一轮建议值、所述目标待存储数据的第一轮建议值的签名和所述目标待存储数据信息进行封装,得到封装包;
根据自身私钥对所述封装包进行加密,得到所述封装包的签名;
根据所述封装包和所述封装包的签名,生成所述目标待存储数据的第一轮投票数据。
需要说明的是,目标待存储数据信息可以为完整的目标待存储数据,为了降低多节点投票对网络带宽的消耗,目标待存储数据信息也可以为目标待存储数据的摘要,即计算目标待存储数据的哈希值,得到目标待存储数据的摘要,达到压缩数据的目的。
s102:接收区块链中任一节点发送的所述目标待存储数据的第r轮投票数据,当接收到的所述目标待存储数据第r轮投票数据的数量与区块链中全部节点数量的比值达到预设最低投票比值时,得到所述目标待存储数据第r轮投票数据集合;
1<r≤r,r为预设最高投票轮数。
系统启动时,需要预设最低投票比值,例如,预设最低投票比值可以为40%。在系统运行过程中,可根据实际效率要求,经过50%以上节点共识后,调整所述最低投票比值。
s103:根据所述目标待存储数据第r轮投票数据集合判断当前是否满足结束对所述目标待存储数据投票的条件;若是,执行s104,若否,执行s105;
其中,请参阅图2,s103的一种优选实施方式包括以下步骤:
s201:提取所述目标待存储数据第r轮投票数据集合中各个建议值,组成所述目标待存储数据第r轮建议值集合;
s202:计算所述目标待存储数据第r轮建议值集合中最大建议值与最小建议值的差值,得到第一差值;
s203:提取所述目标待存储数据各轮投票数据集合中各个建议值,组成所述目标待存储数据各轮建议值集合;
s204:计算得到的所述目标待存储数据各轮建议值集合中最大建议值与最小建议值的差值,得到第二差值;
s205:计算所述第一差值与所述第二差值的比值;
s206:判断所述第一差值与所述第二差值的比值是否大于预设收敛值;
若是,执行s207,s207:判定当前不满足结束对所述目标待存储数据投票的条件;
若否,执行s208,s208:判定当前满足结束对所述目标待存储数据投票的条件。
其中,请参阅图3,s103的一种优选实施方式包括以下步骤:
s301:提取所述目标待存储数据第r轮投票数据集合中各个建议值,组成所述目标待存储数据第r轮建议值集合;
s302:根据预设收敛函数计算得到所述目标待存储数据第r轮建议值集合的1-α置信区间,并计算1-α置信区间上限和1-α置信区间下限的差值,得到第三差值;
s303:提取所述目标待存储数据各轮投票数据集合中各个建议值,组成所述目标待存储数据各轮建议值集合;
s304:根据预设收敛函数计算得到的所述目标待存储数据各轮建议值集合的1-α置信区间,并计算各轮建议值集合的1-α置信区间上限和下限的差值,得到第四差值;
s305计算所述第三差值与所述第四差值的比值;
s306:判断所述第三差值与所述第四差值的比值是否大于预设收敛值;
若是,执行s307,s307:判定当前不满足结束对所述目标待存储数据投票的条件;
若否,执行s308,s308:判定当前满足结束对所述目标待存储数据投票的条件。
其中,1-α根据实际应用确定,一般1-α取值为95%或99.7%;
其中,1-α置信区间的上限和下限根据预设收敛函数的特定置信区间计算公式得到,如无法确定上限和下限,可采用bootstrap等方法进行估算。
每一个节点会在每一轮进行一次采样,即得到一部分节点前一轮的投票值。定义r-1轮全部节点的投票值为总体,某一个节点在第r轮采样得到投票值为样本。则样本中的全部投票值为总体的一部分,即总体完全包含样本,在此基础上根据预设收敛函数计算得到的所述目标待存储数据各轮建议值集合的置信区间。
还需要说明的是,当投票轮数已达到预设最高投票轮数r时,则认为当前满足结束对所述目标待存储数据投票的条件。
s104:根据预设收敛函数和所述目标待存储数据第r轮投票数据集合计算所述目标待存储数据的共识终值,生成携带有所述目标待存储数据的共识终值和所述目标待存储数据第r轮投票数据集合的所述目标待存储数据的投票结果,并将所述目标待存储数据的投票结果通讯至其他节点;
预设收敛函数具有收敛性,可以为中位数函数、平均数函数、n次开方函数等。
具体为以所述目标待存储数据第r轮投票数据集合为预设收敛函数的输入数据,输出所述目标待存储数据的共识终值。
s105:根据所述目标待存储数据第r轮投票数据集合和所述预设收敛函数,计算所述目标待存储数据的第(r+1)轮建议值,生成携带有所述目标待存储数据的第(r+1)轮建议值和所述目标待存储数据第r轮投票数据集合的所述目标待存储数据的第(r+1)轮投票数据,并将所述目标待存储数据的第(r+1)轮投票数据通讯至其他节点;
具体为以所述目标待存储数据第r轮建议值集合为预设收敛函数的输入数据,输出所述目标待存储数据的第(r+1)轮建议值。
所述生成携带有所述目标待存储数据的第(r+1)轮建议值和所述目标待存储数据第r轮投票数据集合的所述目标待存储数据的第(r+1)轮投票数据,包
对自身公钥、所述目标待存储数据的第(r+1)轮建议值、所述目标待存储数据第r轮投票数据集合、所述目标待存储数据的第(r+1)轮建议值的签名和所述目标待存储数据信息进行封装,得到封装包;
根据自身私钥对所述封装包进行加密,得到所述封装包的签名;
根据所述封装包和所述封装包的签名,生成所述目标待存储数据的第(r+1)轮投票数据。
s106:当得到批量多个待存储数据的投票结果时,根据当前批次每个所述待存储数据的投票终值对当前批次每个待存储数据进行排序,得到当前批次待存储数据的排序结果;
s107:当区块链中所有节点对当前批次待存储数据的排序结果达成共识后,根据当前批次待存储数据的排序结果对当前批次待存储数据进行存储。
本实施例公开的一种基于微实数的异步排序方法,区块链中每个节点对连续进入系统的待存储数据中每个待存储数据的顺序进行独立共识,使用预设收敛函数保证每个节点在排序共识的投票过程中达到一致。对于不同待存储数据的共识产生不同的结果,当得到批量多个待存储数据的投票结果时,根据当前批次每个所述待存储数据的投票结果对当前批次每个待存储数据进行排序,得到当前批次待存储数据的排序结果;当区块链中所有节点对当前批次待存储数据的排序结果达成共识后,根据当前批次待存储数据的排序结果对当前批次待存储数据进行存储,进而在多轮并发的共识过程中,同步对各轮同步进行排序,实现了高并发的异步系统中对待存储数据进行存储。
通过本发明,可以在非正常节点(含恶意节点及故障节点)数量占总体数量不超过50%的系统中,完成正常节点的有效共识。同时,因为其与前置节点无直接关联,可以实现并行处理,进而达到提高区块链系统吞吐量的目的。
为了进一步阐述本实施例公开的一种基于微实数的异步排序方法,以下通过一个具体的场景实施例进行说明。
场景实施例
1.准备阶段
本阶段主要用于将交易数据tx转变为用于后续投票阶段的基础数据。具体实现方法如下:
当区块链中任一节点na发起交易或接收到客户端提交的交易后,应将交易数据tx、节点na的公钥pba、以及节点na对交易的加密签名sa=s(tx,pva)交易打包,形成基础数据ra=[pba,sa,tx],并将ra通讯至其他节点,其中,pva为节点na的私钥。
2.初始投票阶段
本阶段产生用于投票的原始数据。为了降低多节点投票对网络带宽的消耗,这里目标待存储数据信息为h(tx),即,目标待存储数据tx的摘要,达到压缩数据的目的。初始投票具体实现方法如下:
当区块链中的任一节点ni(公钥pbi,私钥pvi)接收到通讯数据ra,并验证ra是节点na发出的有效数据后,应投出自己的第一轮建议值vi(1)。vi(1)可由所述第一轮建议值生成方法中的一种确定,此方法应在系统搭建前选定,若中途变更,需要经过全部节点共识认可后进行。本实例以方式二为例。vi(1)是由随机函数生成一个随机整数,随后将vi(1)、自身公钥pbi进行打包并签名,形成第一轮投票数据ti(1)=[pbi,si(1),vi(1),h(tx)]其中,si(1)=(vi(1),pbi),随后将ti(1),以及对ti(1)的签名通讯至其他节点。
3.循环验票阶段
区块链中各节点将对区块的排序进行投票,以确定该区块的序号。本阶段为多次循环,直至满足条件后结束。具体实现方法如下:
对于系统中的任意节点nj,假定其接收到其他节点的第r轮投票数据为{ti(r)},(i=1,2,...,n;n≤nmax)其中,nmax为区块链中最大节点数量。则对应的建议值数组为{vi(r)},(i=1,2,...,n;n≤nmax)。当收到投票节点数量在全部节点数量占比达到s(如s=40%则
之后根据相同的方法产生第二轮投票数据集{ti(r+1)},(i=1,2,...,n;n≤nmax),并通讯至其他节点,如此循环。
对于任意一个节点,如在第r轮最大值max{vi(r)}和最小值min{vi(r)}的差值range(r)与该节点接收到本次全部轮次交易投票最大值max{vi(k)},(k=1,2,...,r)与最小值min{vi(k)},(k=1,2,...,r)的差值range(all)的比值小于设定值ε,即
3.集群共识阶段
对于一个交易(待存储数据),每个节点会对这个交易产生一个投票结果,假定这个投票结果的目标值是n。
集群中的节点在经过微实数排序共识后,各节点最后得到的投票结果未必等于n,但均会落在[(1-e/2)*n,(1+e/2)*n]这个区间之内。
将这个区间视为一个点,那么对于多次交易,每个不重叠的点就会产生顺序。这个顺序在各节点之间是一致的。
请参阅图6,图6为集群中各个节点对同一批次待存储数据的排序结果示意图。其中,中间的数字就是每个节点的投票终值。结果未必完全一致,但通过控制误差e,可以使集群中的结果收敛到一定的范围之内。这样tx1tx2tx3tx4的顺序实际上在各节点之间就已经达成一致了。tx2tx1tx3tx4这样的排序结果是每一个节点都认可的。
基于上述场景实施例,本实施例公开的基于微实数的异步排序方法具有以下优点:
向上扩展性:比如预设收敛函数采用平均数average函数,则参加运算的节点越多,数据收敛性越好。节点数越多,则分布式系统的扩展性越强,解决大规模网络的共识的难题。
强容错性:比如预设收敛函数采用中位数median函数,则参加运算的数值大、小两端边缘值不会影响最终结果,使得少数节点的恶性投票很容易的被共识机制排除在外
由传统的离散型投票转变为连续型:在传统的共识算法投票中,每个节点对数据的投票为“同意”或“拒绝”,即非0即1的离散型数据。这种方法在特定的环境下,会产生“同意”票和“拒绝”票相等的对立情况,造成节点无法确定结果,投票流程被阻塞。在微实数排序共识算法中,我们创新性地将投票变更为连续型实数投票,使在传统算法中被阻塞的情况得到了有效的解决。
性能可调节:微实数排序共识协议提供了预设收敛值ε、最低投票比值s、最高投票轮数r等参数用于对协议的效率进行控制。针对不同的应用环境,可使用不同的参数配置,且该参数在共识协议运行过程中可结合系统运行状况适时调整。如,在节点规模小、并发程度低的环境下,设置收敛范围ε=1、s=100%、r=2时,根据算法原理,微实数排序共识协议即退化为传统pbft,性能与pbft一致,容错率不超过33%。在节点规模较大、并发程度高的环境下,如果采用pbft算法,网络传输数据量将成指数级上升,最终造成性能下降甚至网络堵塞。而采用微实数排序共识协议则可以设置参数ε=0.1%、s=60%、r=20,微实数排序共识协议可稳定运行在故障节点不超过50%的环境中,即提供最大不超过50%的容错率,同时更加节省网络带宽消耗。共识的性能可以灵活的被调节,达到同时满足(或者折中)节点数、安全和性能要求。
节能降耗:对节点性能要求极低,可进一步降低社会经济成本。低传输开销,降低节点对系统网络结构的依赖。
以pbft为参照,假定系统中节点数量为2000个。在四种不同场景下,对pbft和微实数排序共识两种方案的排序效果进行对比:
a场景故障节点数量占总体比例为10%,即故障节点为200个;
b场景故障节点数量占总体比例为33%,即故障节点为660个;
c场景故障节点数量占总体比例为40%,即故障节点数量为800个。
d场景故障节点数量占总体比例为49%,即故障节点数量为980个。
e场景故障节点数量占总体比例为10%,即故障节点为200个,以可视化方式展现并行排序能力;
根据pbft原理,当故障节点(含恶意节点和失效节点)总体超过33%时,系统将无法运行。即在c场景和d场景中,pbft方案是无法运行的。微实数排序共识方案可通过使用不同的最低投票比值s(每次上升10%,每一个s值实验500次)验证方案的效果。
对比依据:
对于传递次数,在使用pbft进行共识系统中,需要进行2次全节点的投票和1次原始消息的发送。pbft投票数量与节点数量n有关,具体计算公式为2*n*(n-1)。在使用微实数排序共识的系统中,需要进行若干次部分节点投票和1次原始消息的发送,微实数排序共识投票数量由最低投票比值s(即上述预设最低投票比值)、完成共识所需轮次数r,以及节点数量n有关,具体计算公式为r*s*n2。当2*n*(n-1)<r*s*n2时,认为微实数排序共识更为优秀。该式可以转化为
对于共识结果,在使用pbft进行共识系统中,在故障节点数量占总体比例不超过33%时,能够使所有正常节点得到一致的信息。在故障节点数量占总体比例超过33%时,pbft无法保证所有正常节点信息一致,可以认为此条件下pbft的共识是失败的。在使用微实数排序共识的系统中,每个节点会在共识结束后得到一个共识终值,当系统中正常节点得到的终值集合中最大值与最小值的差值为零(误差为零),即正常节点的共识终值一致,认为达到绝对共识;当系统中正常节点得到的终值集合中最大值与最小值的差值小于规定数值(本数字由系统的并行度决定,如最多并行100个共识,则差值为1/100=1%),本实例中以1%为例,即误差小于1%,认为达到相对共识,结果同样为有效。据此,微实数排序共识的系统中分析结果中,误差小于1%,即可认为微实数排序共识效果相对pbft不存在劣势。
对于共识耗时,无论绝对共识或相对共识,微实数排序共识均能使用该终值对并行数据进行排序。而pbft无法进行排序,必须补充后续步骤。如对于100个数据进行排序,采用微实数排序共识所需要的时间约为pbft所需时间的1%,即节省99%的时间成本,认定采用微实数排序共识始终优于pbft。
a场景
设定误差控制参数e=0.01,在最低投票比值s逐渐升高的过程中,需要的最大投票轮次逐步下降,如图7。由图7可知,最多需要5次投票即可以完成共识,确定排序。在此情况下,对于传递次数,r*s=5*10%=0.5<2,采用微实数排序共识效果更好,r*s=3*70%=2.1>2,采用pbft效果更好;对于所有最终结果,误差远小于1%。据此,在最低投票比值s小于70%的设定下,采用微实数排序共识优于pbft;而最低投票比值s大于70%的设定下,微实数排序共识相对于pbft,节省了99%的时间成本。
b场景
设定误差控制参数e=0.01,在最低投票比值s逐渐升高的过程中,需要的最大投票轮次逐步下降,如图8,由图8可知,最多需要4次投票即可以完成共识,确定排序。结论于a场景的结论相同。
c场景
设定误差控制参数e=0.01,在最低投票比值s逐渐升高的过程中,需要的最大投票轮次逐步下降,如图8,由图9可知,最多需要4次投票即可以完成共识,确定排序。而对于pbft,因为故障节点数量高于基本要求,在本环境中,pbft无法完成共识。
d场景
因为本场景中故障节点数量巨大,为保证共识排序效果,设定误差控制参数e=0.00001,在最低投票比值s逐渐升高的过程中,需要的最大投票轮次逐步下降,如图10,由图10可知,当最低投票比值s不低于40%时,最多需要6次投票,即可以完成共识,误差小于0.5%,确定排序。而对于pbft,因为故障节点数量高于基本要求,在本环境中,pbft无法完成共识。
e场景
设定误差控制参数e=0.01,由2000个节点同时对2笔交易进行并行投票,第一笔交易各节点投票的数值用符号“.”进行标记,第二笔交易各节点投票数值用符号“x”进行标记。因为含有10%的故障节点,实际有效的节点数量为1800个。各节点在进行微实数排序共识之前的数据如图11,节点第一轮投票后数据分布如图12,节点在第三轮完成投票后数据分布如图13。从图中可以看出,微实数排序共识的并行共识能力使各节点对两笔不同的交易顺序完成了同步的排序,最终的结果为第二笔交易先于第一笔交易进行记录,两笔交易均为有效。
通过调整最低投票比值s和误差控制参数e,对于故障节点占比不超过50%的系统,均能够实现整体系统的收敛。且s值约高,收敛所需要的次数越少,效果越好。
基于上述实施例公开的一种基于微实数的异步排序方法,请参阅图14,本实施例对应公开了一种基于微实数的异步排序装置,包括:
第一轮投票数据生成单元401,用于接收区块链中任一节点发送的目标待存储数据的基础数据,生成携带有所述目标待存储数据的第一轮建议值的所述目标待存储数据的第一轮投票数据,并将所述目标待存储数据的第一轮投票数据通讯至其他节点,所述目标待存储数据为区块链中任一待存储数据;
第r轮投票数据生成单元402,用于接收区块链中任一节点发送的所述目标待存储数据的第r轮投票数据,1<r≤r,r为预设最高投票轮数,当接收到的所述目标待存储数据第r轮投票数据的数量与区块链中全部节点数量的比值达到预设最低投票比值时,得到所述目标待存储数据第r轮投票数据集合;
判断单元403,用于根据所述目标待存储数据第r轮投票数据集合判断当前是否满足结束对所述目标待存储数据投票的条件;若是,触发投票结果计算单元405,若否,触发第(r+1)轮投票数据生成单元404;
所述投票结果计算单元405,用于根据预设收敛函数和所述目标待存储数据第r轮投票数据集合计算所述目标待存储数据的共识终值,生成携带有所述目标待存储数据的共识终值和所述目标待存储数据第r轮投票数据集合的所述目标待存储数据的投票结果,并将所述目标待存储数据的投票结果通讯至其他节点;
所述第(r+1)轮投票数据生成单元404,用于根据所述目标待存储数据第r轮投票数据集合和所述预设收敛函数,计算所述目标待存储数据的第(r+1)轮建议值,生成携带有所述目标待存储数据的第(r+1)轮建议值和所述目标待存储数据第r轮投票数据集合的所述目标待存储数据的第(r+1)轮投票数据,并将所述目标待存储数据的第(r+1)轮投票数据通讯至其他节点;
排序单元406,用于当得到批量多个待存储数据的投票结果时,根据当前批次每个所述待存储数据的投票终值对当前批次每个待存储数据进行排序,得到当前批次待存储数据的排序结果;
存储单元407,用于当区块链中所有节点对当前批次待存储数据的排序结果达成共识后,根据当前批次待存储数据的排序结果对当前批次待存储数据进行存储。
优选的,所述装置还包括:
基础数据生成单元,用于根据自身私钥对所述目标待存储数据进行加密,得到对所述目标待存储数据的签名,并对所述目标待存储数据的签名、自身公钥和所述目标待存储数据进行封装,得到所述待存储数据的基础数据。
优选的,所述第一轮投票数据生成单元401包括:
第一建议值生成子单元,用于将所述目标待存储数据的时间戳确定为所述目标待存储数据的第一轮建议值,所述目标待存储数据的时间戳为相应节点接收到所述目标待存储数据的时间。
优选的,所述第一轮投票数据生成单元401包括:
第二建议值生成子单元,用于根据随机函数生成一个随机整数,将所述随机整数确定为所述目标待存储数据的第一轮建议值。
优选的,所述第一轮投票数据生成单元401包括:
第三建议值生成子单元,用于对当前时间保存的数据总量与随机函数生成一个随机整数进行求和,得到扩展数据编号,将所述扩展数据编号确定为所述目标待存储数据的第一轮建议值。
优选的,所述第一轮投票数据生成单元401包括:
封装子单元,用于对自身公钥、所述目标待存储数据的第一轮建议值、所述目标待存储数据的第一轮建议值的签名和所述目标待存储数据信息进行封装,得到封装包;
加密子单元,用于根据自身私钥对所述封装包进行加密,得到所述封装包的签名;
投票数据生成子单元,用于根据所述封装包和所述封装包的签名,生成所述目标待存储数据的第一轮投票数据。
可选的,所述判断单元403包括:
第一提取子单元,用于提取所述目标待存储数据第r轮投票数据集合中各个建议值,组成所述目标待存储数据第r轮建议值集合;
第一计算子单元,用于计算所述目标待存储数据第r轮建议值集合中最大建议值与最小建议值的差值,得到第一差值;
第二提取子单元,用于提取所述目标待存储数据各轮投票数据集合中各个建议值,组成所述目标待存储数据各轮建议值集合;
第二计算子单元,用于计算得到的所述目标待存储数据各轮建议值集合中最大建议值与最小建议值的差值,得到第二差值;
第三计算子单元,用于计算所述第一差值与所述第二差值的比值;
第一判断子单元,用于判断所述第一差值与所述第二差值的比值是否大于预设收敛值;若是,触发第一判定子单元,若否,触发第二判定子单元;
所述第一判定子单元,用于判定当前不满足结束对所述目标待存储数据投票的条件;
所述第二判定子单元,用于判定当前满足结束对所述目标待存储数据投票的条件。
可选的,所述判断单元403包括:
第一提取子单元,用于提取所述目标待存储数据第r轮投票数据集合中各个建议值,组成所述目标待存储数据第r轮建议值集合;
第四计算子单元,用于根据预设收敛函数计算得到所述目标待存储数据第r轮建议值集合的1-α置信区间,并计算1-α置信区间上限和1-α置信区间下限的差值,得到第三差值;
第二提取子单元,用于提取所述目标待存储数据各轮投票数据集合中各个建议值,组成所述目标待存储数据各轮建议值集合;
第五计算子单元,用于根据预设收敛函数计算得到的所述目标待存储数据各轮建议值集合的1-α置信区间,并计算各轮建议值集合的1-α置信区间上限和下限的差值,得到第四差值;
第六计算子单元,用于计算所述第三差值与所述第四差值的比值;
第二判断子单元,用于判断所述第三差值与所述第四差值的比值是否大于预设收敛值;若是,触发第一判定子单元,若否,触发第二判定子单元;
所述第一判定子单元,用于判定当前不满足结束对所述目标待存储数据投票的条件;
所述第二判定子单元,用于判定当前满足结束对所述目标待存储数据投票的条件。
本实施例公开的一种基于微实数的异步排序装置,区块链中每个节点对连续进入系统待存储数据中每个待存储数据的顺序进行独立共识,使用预设收敛函数保证每个节点在排序共识的投票过程中达到一致。对于不同待存储数据的共识产生不同的结果,当得到批量多个待存储数据的投票结果时,根据当前批次每个所述待存储数据的投票结果对当前批次每个待存储数据进行排序,得到当前批次待存储数据的排序结果;当区块链中所有节点对当前批次待存储数据的排序结果达成共识后,根据当前批次待存储数据的排序结果对当前批次待存储数据进行存储,进而在多轮并发的共识过程中,同步对各轮同步进行排序,实现了高并发的异步系统中对待存储数据进行存储。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其他实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 还没有人留言评论。精彩留言会获得点赞!