基于深度残差长短时记忆网络的视频事件识别方法与流程
本发明涉及视频事件识别技术,尤其是一种基于深度残差长短时记忆网络的视频事件识别方法。
背景技术
视频事件识别是指从视频中识别出事件的时空视觉模式。随着视频监控在现实生活中的广泛应用,监控视频事件识别受到了广泛关注,并取得了一系列的研究成果,然而监控视频的事件识别仍然面临着巨大的挑战和困难,比如自然场景下监控视频背景复杂、事件区域对象遮挡严重、摄像头视角变化等因素,导致事件类间距离小、类内距离大。
现有技术中,为了解决监控视频事件识别困难的问题,传统的解决方案是采用基于视觉词袋模型的方法和基于运动轨迹的方法进行监控视频的事件识别,但是这种手工特征识别方法难以进一步提高识别精度;随着时代的发展,深度学习成为人工智能领域研究的热点,并开始应用于监控视频的事件检测、行为识别等领域,例如,用于行为识别的双流cnn网络,其中,时间cnn网络利用视频的静态帧信息,空间cnn网络利用视频的光流信息,但是以双流cnn网络为代表的方法仅仅利用了视频的短时动态特征,并无有效利用视频的长时动态特征,在监控视频的事件识别方面仍然存在一定缺陷,于是通过采用长时递归卷积网络(lrcn)的方法来弥补上述缺陷,lrcn利用cnn网络提取特征,然后送入lstm网络获得识别结果,其中,lstm又称长短期记忆网络,可以从输入序列中递归学习长时动态特征,因此能够处理具有典型时间序列的任务,例如语音识别、行为识别,由此,通过深层架构能够提高cnn和lstm网络的识别能力,但是,无论是cnn还是lstm,随着网络深度的增加,都会遇到梯度消失问题,很难训练具有更加有深度的网络。
技术实现要素:
本发明解决的技术问题是提供一种基于深度残差长短时记忆网络的视频事件识别方法。
本发明的技术方案是:一种基于深度残差长短时记忆网络的视频事件识别方法,包括:1)时空特征数据联接单元设计:时空特征数据经lstm同步解析后形成时空特征数据联接单元dlstm;2)du-dlstm双单向结构设计:每个dlstm单元包含了来自时间cnn网络(convolutionalneuralnetwork)和空间cnn网络的输入,两个单向传递的dlstm联接后构成du-dlstm单元;3)rdu-dlstm残差模块设计:多个du-dlstm层再加一个恒等映射形成残差模块;4)2c-softmax目标函数设计:双中心loss分别维护空间特征中心和时间特征中心,空间特征中心和时间特征中心按一定权重系数融合形成质心,给softmax的loss加入双中心loss以及dlstm单元的正则项,构成2c-softmax目标函数。
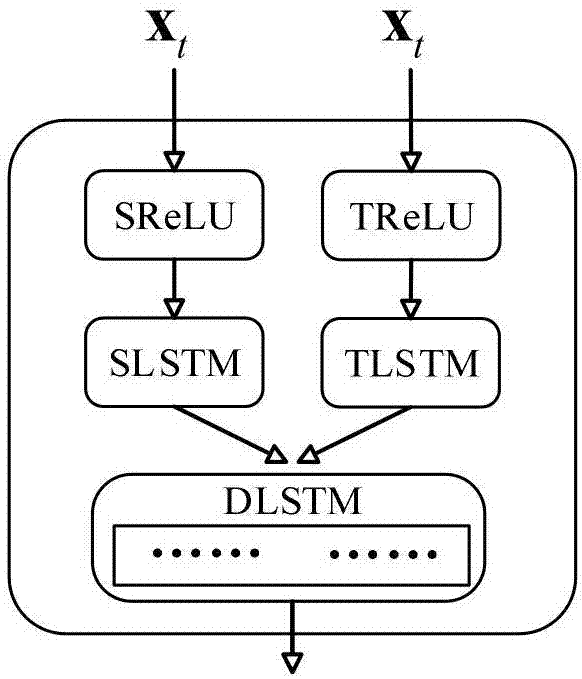
进一步,本发明中所述步骤1)时空特征数据联接单元设计包括:(1)接收数据:slstm(spatiallstm)接收来自空间cnn网络的特征hsl,tlstm(temporallstm)接收来自时间cnn网络的特征htl;(2)激活函数转换:slstm和tlstm经relu激活函数d转换,分别得到:d(wshsl+bs)和d(wthtl+bt),其中ws和wt表示权重,bs和bt表示偏置项;(3)特征联接:激活函数转换后的slstm和tlstm再经联接操作c形成一个新的单元dlstm,描述为:hdl=c(d(wshsl+bs),d(wthtl+bt)),突出了时空信息的一致性。
进一步,本发明中所述步骤2)du-dlstm双单向结构设计包括:(1)特征同向传递:每个dlstm单元包含了来自时间cnn网络和空间cnn网络的输入,hdl1和hdl2表示两个相同传递方向dlstm单元的输入;(2)特征联接:两个单向传递的dlstm联接后构成du-dlstm单元,hdu为du-dlstm的输出,描述为:hdu=c(d(w1hdl1+b1),d(w2hdl2+b2)),由此拓宽了网络的宽度,增加了特征选择范围。
进一步,本发明中所述步骤3)rdu-dlstm残差模块设计包括:(1)网络输出:将du-dlstm结构作为一个网络层,第一个du-dlstm结构的输出hdu作为x;(2)残差连接:快捷连接对hdu做一个线性变换wi,rdu-dlstm残差模块的输出为:h=f(hdu,{wi})+hdu,解决了更深层次的网络梯度消失问题。
进一步,本发明中所述步骤4)2c-softmax目标函数设计包括:(1)为了防止过拟合,给softmax的loss项lj加上dlstm单元权重的二范数作为正则项,表示为:
目标函数l加入双中心loss形成新的目标函数l¢,并称之为2c-softmax,cs和ct按一定权重系数b融合形成质心,2c-softmax描述为:
本发明与现有技术相比具有以下优点:
1)本发明中,设计的残差模块使得训练深达数百甚至超过千层的网络成为可能,同时能够较好地解决深度堆叠的lstm梯度消失的问题,弥补了现有监控视频事件识别方法的不足。
2)本发明中,2c-softmax目标函数中设计的中心loss结构能够对每一个类别学习一个中心,并根据样本特征与类中心的距离进行惩罚,大大缩短了类内距离,使学习到的特征具有更好的泛化能力和辨别能力,由此,模型的辨识能力大大提高,为现有技术中事件类间距离小、类内距离大的难点提出了新的解决方案。
3)本发明中,通过双流cnn网络(即时间cnn网络和空间cnn网络)获得深度特征输入,从输入序列中递归学习长时动态特征,实现深度残差网络架构的构建,并最终能够解决复杂场景下监控视频事件识别问题,具有更高的推广价值。
附图说明
下面结合附图及实施例对本发明作进一步描述:
图1为本发明中时空特征数据联接单元的结构图;
图2为本发明中du-dlstm双单向结构设计结构图;
图3为本发明中rdu-dlstm残差模块设计结构图;
图4为本发明中双中心loss特征划分图;
图5为本发明中drdu-dlstm的网络模型图;
图6为本发明方法的系统总体框架图。
具体实施方式
实施例:
结合附图所示为本发明一种基于深度残差长短时记忆网络的视频事件识别方法的具体实施方式,包括如下步骤:
步骤1)时空特征数据联接单元设计:时空特征数据经lstm同步解析后形成时空特征数据联接单元dlstm;
如图1所示,其具体步骤包括:
(1)接收数据:首先采用两个lstm单元,分别记为slstm和tlstm,slstm接收来自空间cnn网络的特征hsl,tlstm接收来自时间cnn网络的特征htl;
(2)激活函数转换:lstm单元在接收输入前,需采用非线性激活函数对输入数据处理,采用relu激活函数,slstm和tlstm经relu激活函数d转换,分别得到:d(wshsl+bs)和d(wthtl+bt),其中ws和wt表示权重,bs和bt表示偏置项,d表示relu激活函数;
(3)特征联接:激活函数转换后的slstm和tlstm再经联接操作c形成一个新的单元dlstm,公式为:
hdl=c(d(wshsl+bs),d(wthtl+bt))(1)
其中ws和wt表示权重,bs和bt表示偏置项,c表示联接操作。
步骤2)du-dlstm双单向结构设计:每个dlstm单元包含了来自时间cnn网络(convolutionalneuralnetwork)和空间cnn网络的输入,两个单向传递的dlstm联接后构成du-dlstm单元;
如图2所示,其具体步骤包括:
(1)特征同向传递
每个dlstm单元包含了来自时间cnn网络和空间cnn网络的输入,hdl1和hdl2表示两个相同传递方向dlstm单元的输入;
(2)特征联接
两个单向传递的dlstm联接后构成du-dlstm单元,hdu为du-dlstm的输出,公式为:
hdu=c(d(w1hdl1+b1),d(w2hdl2+b2))(2)
其中w和b分别表示权重和偏置项。
步骤3)rdu-dlstm残差模块设计:多个du-dlstm层再加一个恒等映射形成残差模块;
如图3所示,其具体步骤包括:
(1)网络输出
将du-dlstm结构作为一个网络层,第一个du-dlstm结构的输出hdu作为x;
(2)残差连接
残差学习结构可以通过前向神经网络加快捷连接实现,快捷连接块定义为:
y=f(x,{wi})+x(3)
其中x和y分别表示网络层的输入和输出,函数f(x,{wi})表示待学习的残差映射,利用快捷连接对hdu做一个线性变换wi,rdu-dlstm残差模块的输出为:
h=f(hdu,{wi})+hdu(4)
步骤4)2c-softmax目标函数设计:双中心loss分别维护空间特征中心和时间特征中心,空间特征中心和时间特征中心按一定权重系数融合形成质心,给softmax的loss加入双中心loss以及dlstm单元的正则项,构成2c-softmax目标函数。
如图4所示,其具体步骤包括:
(1)网络反向传播通过计算损失函数实现,通常情况下可以用softmax的loss:
其中xi表示第i个特征向量,yi表示类别标签,n为类别数,m表示小批量(mini-batch)的大小,w为权重,b是偏置项;
为了防止过拟合,可以给softmax的loss项lj加上正则项,dlstm单元对网络具有重要的影响,因此可以加入dlstm单元权重的二范数作为正则项:
其中m表示小批量的大小,
(2)中心loss函数对每个类别在特征空间都维护一个类中心c,其计算公式为:
其中xi表示第i个样本的特征向量,
在事件识别算法中,drdu-dlstm网络的输入来自于时间cnn网络和空间cnn网络的两类特征,因此设计一个双中心loss,双中心loss分别维护空间特征中心cs和时间特征中心ct,其中
(3)cs和ct按一定权重系数b融合形成质心,加入双中心loss形成新的目标函数
为了防止目标函数过拟合,加入dlstm单元的正则项,公式为:
将公式(5)、(6)、(8)代入(10)得目标函数,称之为2c-softmax:
本实施例具体工作时,
首先采用两种不同的数据集,包括virat1.0数据集和virat2.0数据集,其中:
virat1.0数据集包含了约3小时的监控视频,180多个事件案例。视频由安装在校园停车场的固定高清摄像机拍摄,分辨率为1280×720像素或1920×1080像素。virat1.0数据集的事件类型包括6类人车交互事件:(1)装载货物(loading),(2)卸载货物(unloading),(3)打开车门(opening),(4)关闭车门(closing),(5)进入车辆(intovehicle),(6)走出车辆(outvehicle)。
virat2.0数据集包含了8.5小时的监控视频,11类事件,1500多个事件案例。视频由安装在校园停车场、商场入口、建筑工地等场所的固定高清摄像机拍摄,分辨率为1280×720像素或1920×1080像素。virat2.0数据集扩展自virat1.0数据集,事件类别由6类扩展为11类,原有的6类事件增加了部分事件案例,新增的事件类别涉及人与建筑物、人与物以及人体行为等,新增的事件类型有:(1)进入商场(enteringfacility),(2)走出商场(exitingfacility),(3)打手势(gesturing),(4)搬运物体(carrying),(5)跑步(running)。
实验参数设置如下:
视频事件片段通过事件邻域(eventneighborhood)的方式从原始视频中获得,其邻域参数l设置为0.35。cnn网络采用caffe工具箱实现。实验在gpu服务器上完成,操作系统为centos7,使用了2个k20加速卡。virat1.0数据集中的180多个事件案例视频、virat2.0数据集中的1500多个事件案例视频分别提取了空间cnn网络的全连接层fc6的特征和时间cnn网络的全连接层fc7特征,生成视频特征数据文件。视频特征数据文件按文件名随机置乱后,选取其中的70%为drdu-dlstm网络的训练数据,剩余的30%数据作为测试数据,并作为drdu-dlstm网络时空特征数据联接层的输入。
接下来对每个方法进行实验验证:
1、输入方式对网络的影响验证
实验首先比较了数据输入模态对drdu-lstm网络的影响,以验证时空特征数据联接单元的有效性,如表1所示。drdu-lstm网络的结构为1个残差单元、5个堆叠层。从表1可以看出,无论是时、空数据流分别作为独立输入,还是取双流独立输入后融合的结果,并不能提高识别准确率。我们分析发现,在时间数据流检测正确而空间数据流检测错误的案例中,由于时间数据流仅有微弱的概率优势,并没有做到和空间数据流互补。而我们设计的双流联接输入模式,准确率可以提高2%左右,其原因主要在于深层的残差dlstm结构在传递过程中,时空双流连接输入单元dlstm加深了时空信息的融合,时空信息做到了最大程度上的互补。
表1输入方式对网络的影响
2、dlstm的传递方向对网络的影响验证
表2给出了网络不同的传递方向对网络的影响。实验采用了双流联接输入方式。从表2可以看出,在语音识别等领域获得成功的双向传递方式识别准确率不高,甚至低于单向传递方式,说明在事件识别中,后续帧对前帧的正向影响不大,时序的先后关系更重要;而本文设计的双单向传递方式获得了最好的结果,表明双单向传递的dlstm单元拓宽网络的宽度,增加了特征选择的范围,增强了特征的耦合能力。
表2dlstm的传递方向对网络的影响
3、残差单元和堆叠层数对网络的影响验证
为了说明网络层次结构对识别结果的影响,表3对比了残差单元数量和堆叠深度对网络的影响。实验采用双流联接输入方式。表3给出了网络在1至2个残差单元、堆叠深度为2至6层时的准确率和f1值。实验结果表明,不同的层次结构对网络有一定的影响,残差单元和堆叠深度取值应适中,更多的残差单元或更深的堆叠深度并不能提高准确率和f1值。
表3残差单元和堆叠层数对网络的影响
4、loss对网络的影响验证
另外,为了说明优化后的loss在网络的作用,表4对比了不同的loss设计方案对网络的影响。实验表明,仅用双中心loss并不能有效提高识别结果,双中心loss与dlstm单元正则项结合可以取得更好的效果。
表4loss对网络的影响
5、最终模型与其他方法的对比验证
我们和更多的算法作了进一步的对比,如表5所示。bow虽然在视频检索、行为识别等视频处理任务上取得了广泛的应用和不错的业绩,但其在更具有挑战性的监控视频事件识别任务上效果一般。spn在bow的基础上更好地结合了视频的全局特征和局部特征,取得了比bow更好的效果。structuralmodel、hierarchical-crf和bn均利用了视频的上下文信息和时空特征,虽然也取得了很好的结果,但手工特征的选择禁锢了算法识别的上限。相比于深度受限玻尔兹曼机,采用卷积网络能够从视频中获得更加鲁棒的自动特征,结合残差结构的lstm递归网络,我们的算法能够最大程度上利用视频的空间信息、短时信息、长时信息和时空融合信息,识别准确率也得到了较大幅度的提高。
表5virat1.0和virat2.0上的对比实验
当然上述实施例只为说明本发明的技术构思及特点,其目的在于让熟悉此项技术的人能够了解本发明的内容并据以实施,并不能以此限制本发明的保护范围。凡根据本发明主要技术方案的精神实质所做的修饰,都应涵盖在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!