一种基于种子词的半监督LDA模型的制作方法
本发明涉及一种互联网通信
技术领域:
,特别涉及一种基于种子词的半监督lda模型。
背景技术:
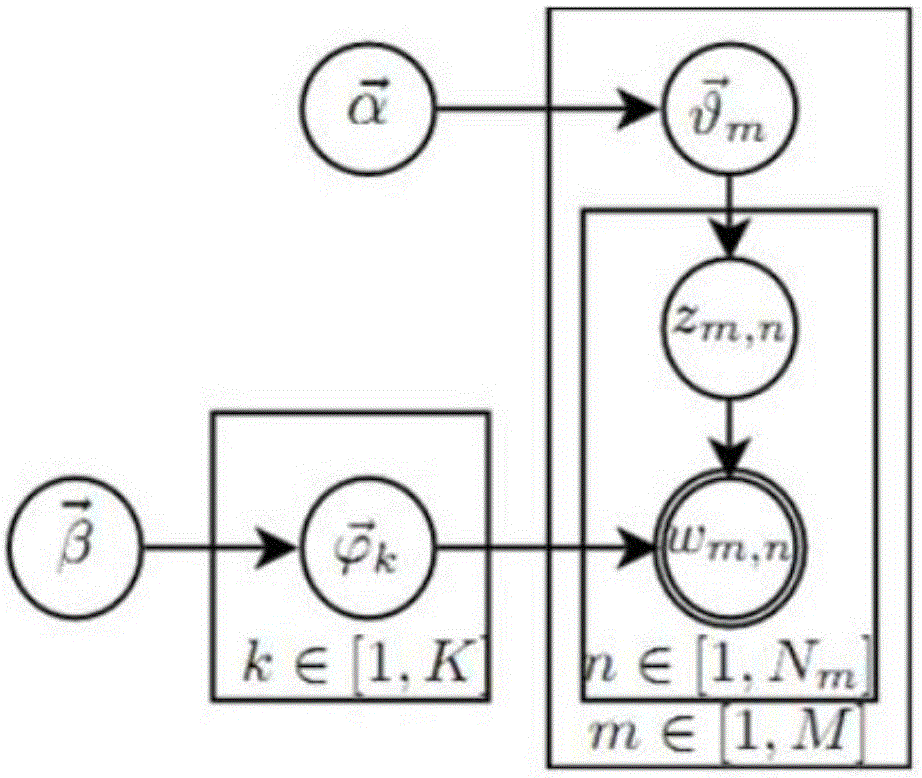
:文本分类的难点在于,如何将非数字的文本转化为易于量化的数量和向量。lda模型与其他的文本分类算法相比,有以下的优点:一,lda模型是一种主题模型,可以将文档集中每篇文档的主题按照概率给出;二,lda模型是一种无监督学习算法,在训练是不需要手工标注的训练集,需要的仅仅是文档集合,以及指定主题的数量k;三,对于lda生成的每个主题,都可以用一系列的词语来描述这个主题,使主题具有语义上的意义。然而,lda的也有一些未解决的问题:一,基于词袋法,对于词语在文档中的先后次序数据被忽略了,可能产生影响;二,无监督算法的通病,聚类效果不好,主题粒度大,并且没能利用到一部分已标记的数据,造成浪费。技术实现要素:通过引入部分已被标注主题的词来加强算法的聚类效果。常见关键词在多篇文档中的重复出现可能性比较大,相比于为每篇文档进行人工标注,对常见关键词进行人工标注的工作量要大大减少。将这些被人工标注了的常见关键词的集合称为先验知识。在构建主题向量的过程中,当文档中出现先验知识中的词时,在使用gibbs采样前,对其概率进行权重调整,从而使得这些词必然从属于它的人工标注的主题。如此,特定的词被主动的归入特定的主题,从而与这些词类似的词,也有更大概率属于同一个主题。本发明本发明技术方案带来的有益效果:本发明加入先验知识,提升聚类准确度;实质上减少了需要gibbs采样的词的数量,加快收敛速度;通过对先验知识的增删查改,实质上有了人工调整模型聚类结果的能力,使模型更有解释能力。附图说明为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它的附图。图1是本发明中lda的概率图模型;具体实施方式下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。实施流程:一、数据预处理建立先验知识表,形如(词,主题),可以创建下列表prior_dic。词主题java编程语言七数字出租屋房产adaboost算法二、模型假设以及原理1.模型假设人类在写一篇文章时,往往先确定要写几个主题,譬如:20%计算机,40%算法,30%编程,10%其他。谈起计算机这个主题,一时间容易想到内存、cpu、磁盘等词。之所以有如此联想,是因为这些词在对应主题下出现可能性很高。hoffman在1999年首次正式对该想法进行数学化。hoffman认为,一篇文档(document)可以由多个主题(topic)混合组成,而每个topic都是词汇的概率分布,文章中每个词都是由一个固定的主题生成的。这就是plsa模型中的假设。对于plsa模型,贝叶斯学派提出另一种看法。doc-topic的概率分布以及topic-word的概率分布都是模型中的参数,都是随机变量。既然是随机变量,那么可以引入一个先验分布,来决定这个随机变量。从而,过程变为:随机选取一个doc-topic的概率分布并生成一个topic,再寻找topic对应的topic-word的概率分布从而产生一个词。这便是lda模型。2.模型原理结合图1可以将概率图分解成两个过程:1)表示在生成第m篇文档时,先抽取doc-topic的概率分布然后根据生成了第n个词的主题编号zm,n2)表示选择编号为k的概率分布来产生词wm,n这两个过程都有一个共同点,即,前部分对应于dirichlet分布,后部分对应于multinomial分布,所以是整体上,都是dirichlet-multinomial共轭结构。从生成语料w的概率出发。因为doc-topic的概率分布是个随机变量,所以,用积分的方法算出p(w):因为是个多项分布,所以,选取先验分布为多项分布的共轭分布——dirichlet分布。其中,是归一化因子。对于dirichlet分布,有着:dirichlet先验分布+多项分布的数据→为dirichlet分布的后验分布取平均值作为的估计值。从而,产生语料w的概率为:从而,对应lda模型中的两个过程,有:将两个过程整合起来,有:然后对此进行gibbs采样。由于词是能观测到的数据,实际需要采样的是主题编号由贝叶斯法则,得:在去掉第i=(m,n)个词后,并不改变dirichlet-multinomial共轭结构,只是在计数上减去第i个词。所以,和的后验分布为:结合起来,就有:加上本模型提出的示性函数:其中,prior表示先验知识,w是词,(w,z)表示w属于主题编号z最终,gibbs采样公式形如:三、程序流程1)对文档集中的每个词,随机赋予topic编号z;2)重新扫描全部词,对每个词w进行gibbs采样,更新它的topic编号;3)重复2)中的采样过程,直至gibbs采样收敛;4)收敛后的topic-word同现矩阵,就是所求模型。以上对本发明实施例所提供的一种基于种子词的半监督lad模型进行了详细介绍。本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1