基于命名数据网络的Top-k查询方法及系统与流程
本发明涉及命名数据网络(ndn)来实现动态分布数据的查询方法,具体涉及一种基于命名数据网络的top-k查询方法及系统,包含数据在查询转发、响应处理和排序聚合及返回的各个模块阶段的实现过程。
背景技术:
命名数据网络(nameddatanetworking,ndn)是一种新兴的互联网体系架构,从现在的以主机为中心的ip网络体系结构会逐渐演变成以数据为中心的命名数据网络体系结构。ndn可以实现命名数据在分布式网络中基于名字的路由和转发,而不再依赖于类似ip网络中的地址来进行路由和转发数据,同时它采用分层结构化命名方法对内容名称进行命名,类似于ip地址前缀机制来迅速定位所需要的信息内容。ndn中有消费者(consumer)和生产者(producer)和两种类型的传输包:兴趣包(interestpacket)和数据包(datapacket),命名数据网络中的路由节点包含待定兴趣表(pit)、内容存储(cs)和转发信息库(fib)三个组件,其中,pit的作用是保存兴趣包发送的请求信息,以保证当接收到数据包时可以根据这些信息将其正确地返回给请求者,cs的作用类似于ip路由中的内容缓存存储,主要作用为缓存数据以备以后查找使用,fib是用来将兴趣包发送至潜在匹配的内容数据包所在的节点,与ip路由器相比,它可以实现同时向多个节点转发兴趣包。
ndn根据名字路由和转发包,从而消除了ip架构中地址造成的四个问题:地址空间耗尽、nat穿越、流动性和可扩展的地址管理。ndn没有地址枯竭的问题,因为命名空间是无限的;ndn同样不存在穿越问题,因为一台主机在传送内容时并不需要暴露其地址;流动性指的是主机ip地址发生变化,但是在ndn中不再需要中断通信,因为数据的名称保持不变;最后,在本地网络不再需要进行地址的分配和管理。传统的ip网络路由采用一个单一的最佳路径,而命名数据网络支持多路径路由。
top-k查询在处理海量的数据时显示出很好的查询效率,它的基本含义为:给定n个数据项,从中选出与用户兴趣最匹配和最相关的k(k≤n)个数据项,然后采用相关的一些技术或查询算法,将所得的数据结果返回给用户。
但是,如何基于命名数据网络(ndn)来实现动态分布数据的top-k查询,且确保该查询方式高效可靠、响应快速,能够解决命名数据网络查询中返回结果的爆炸式增长的问题,则仍然是一项亟待解决的关键技术问题。
技术实现要素:
本发明要解决的技术问题:针对现有技术的上述问题,提供一种基于命名数据网络的top-k查询方法及系统,本发明不仅能够在路由过程中处理大规模数据,而且提高了查询的效率、可扩展性和性能。
为了解决上述技术问题,本发明采用的技术方案为:
一种基于命名数据网络的top-k查询方法,实施步骤包括:
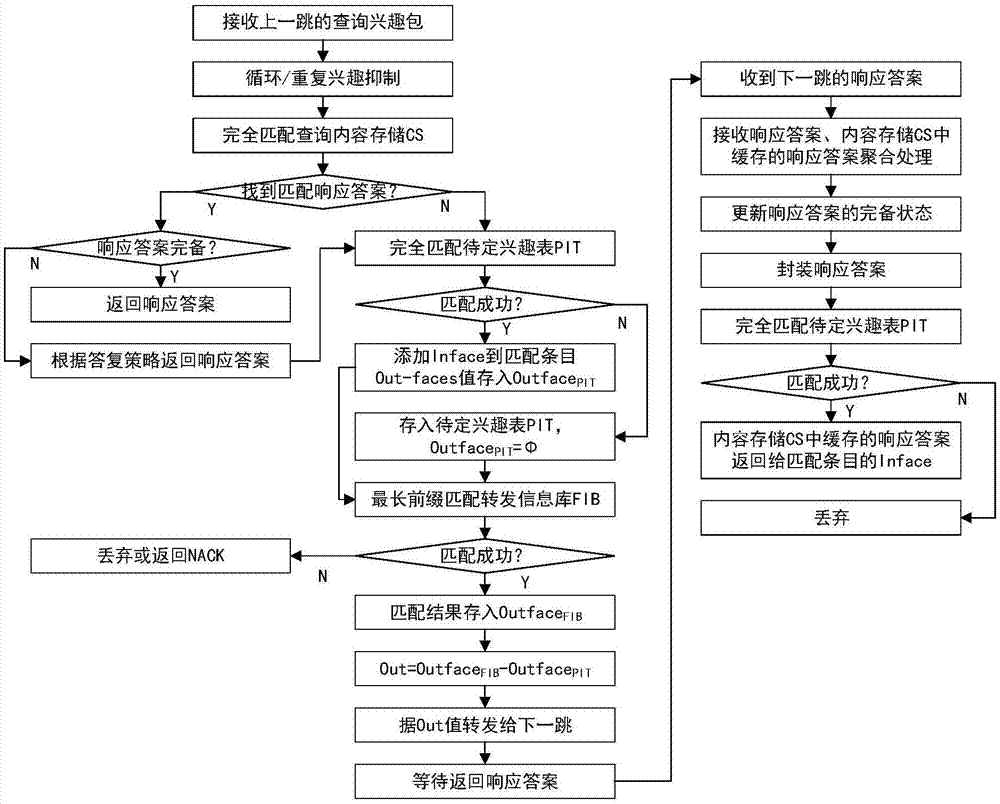
1)接收上一跳的查询兴趣包,对循环或重复的查询兴趣包对应的查询兴趣包进行抑制,如果接收的查询兴趣包被抑制,则跳转执行步骤1);否则,跳转执行步骤2);
2)判断完全匹配内容存储cs是否找到匹配的top-k查询结果,如果找到匹配的top-k查询结果则跳转执行步骤3);否则,跳转执行步骤4);
3)判断top-k查询结果是否完备,如果top-k查询结果完备,则向上一跳返回完备的top-k查询结果,结束并退出;否则如果top-k查询结果不完备,则跳转执行步骤4);
4)初始化转发信息库转出接口数组变量outfacefib和待定兴趣表转出接口数组变量outfacepit;判断完全匹配待定兴趣表pit是否找到匹配的条目,如果找到匹配的条目,则将查询兴趣包的接收接口inface添加到匹配的条目、待定兴趣表pit中匹配条目的outface的值添加到待定兴趣表转出接口数组变量outfacepit;否则,将查询兴趣包存入待定兴趣表pit,并设置存入条目的待定兴趣表转出接口数组变量outfacepit为空;
5)判断最长前缀匹配转发信息库fib是否匹配成功,如果匹配不成功,则丢弃查询兴趣包并退出;否则,跳转执行步骤6);
6)将匹配结果存入转发信息库转出接口数组变量outfacefib;
7)将转发信息库转出接口数组变量outfacefib减去待定兴趣表转出接口数组变量outfacepit得到下一跳接口集合out;
8)执行本地top-k查询,将本地top-k查询得到的k个答案作为top-k查询结果并缓存到内容存储cs,并根据下一跳接口集合out将查询兴趣包分别转发至各下一跳;
9)等待下一跳返回内容数据包,当收到内容数据包时解析获取内容数据包中的top-k查询结果,并跳转执行步骤10);
10)将收到的top-k查询结果、内容存储cs中的top-k查询结果进行聚合处理,得到包含k个答案的新的top-k查询结果并替换更新内容存储cs中的缓存;
11)根据下一跳集合out中的下一跳是否全部返回top-k查询结果来更新内容存储cs中的top-k查询结果的完备状态,如果内容存储cs中的top-k查询结果尚未完备,则跳转执行步骤9);否则,跳转执行步骤12);
12)将内容存储cs中的top-k查询结果封装,判断完全匹配待定兴趣表pit是否找到匹配的条目,如果找到匹配的条目,则将封装后的top-k查询结果转发给匹配的条目对应的上一跳;否则,丢弃查询兴趣包并退出。
优选地,步骤1)的详细步骤包括:
1.1)接收上一跳的查询兴趣包;
1.2)判断完全匹配待定兴趣表pit是否找到匹配的条目,如果找到匹配的条目,则将查询兴趣包携带的随机数值nonce和匹配的条目的随机数值nonce是否相同,如果随机数值nonce相同,则跳转执行步骤1.3);否则,则将查询兴趣包的接收接口inface添加到匹配的条目、待定兴趣表pit中匹配条目的发送接口outface的值添加到待定兴趣表转出接口数组变量outfacepit,则跳转执行步骤2);如果没有找到匹配的条目,则将查询兴趣包存入待定兴趣表pit,并设置存入条目的待定兴趣表转出接口数组变量outfacepit为空,跳转执行步骤2);
1.3)通过接收查询兴趣包的接收接口inface向上一跳发送否定应答消息nack,收到否定应答消息nack的上一跳在待定兴趣表pit中删除该查询兴趣包对应的发送接口outface,如果该查询兴趣包对应的发送接口outface是该查询兴趣包的唯一的一个发送接口outface,则在待定兴趣表pit中删除该查询兴趣包对应的条目;跳转执行步骤1)。
优选地,步骤1)中接收的查询兴趣包包含响应策略信息字段restrategy,所述响应策略信息restrategy包含了向上一跳返回top-k查询结果的方式,返回top-k查询结果的方式分别包括三种:(1)聚合后立即响应策略ira:每一次聚合处理后立即返回top-k查询结果;(2)仅响应最终聚合策略mar-1:仅在top-k查询结果完备时返回top-k查询结果;(3)多次聚合后响应策略mar-2:多次聚合处理后立即返回top-k查询结果且在top-k查询结果完备时返回top-k查询结果;且步骤3)中如果top-k查询结果不完备时:如果响应策略信息restrategy为聚合后立即响应策略ira则立即向上一跳返回匹配的top-k查询结果,然后再跳转执行步骤4);如果响应策略信息restrategy为多次聚合后响应策略mar-2则根据聚合处理的次数对多次聚合后响应策略mar-2的聚合次数取模,根据取模结果是否为指定值来决定是否向上一跳返回匹配的top-k查询结果,然后再跳转执行步骤4);步骤11)中如果内容存储cs中的top-k查询结果尚未完备时:如果响应策略信息restrategy为聚合后立即响应策略ira则立即向上一跳返回内容存储cs中的top-k查询结果,然后再跳转执行步骤9);如果响应策略信息restrategy为多次聚合后响应策略mar-2则根据聚合处理的次数对多次聚合后响应策略mar-2的聚合次数取模,根据取模结果是否为指定值来决定是否向上一跳返回内容存储cs中的top-k查询结果,然后再跳转执行步骤9)。
优选地,步骤11)中更新内容存储cs中的top-k查询结果的完备状态的详细步骤包括:在待定兴趣表pit中将该查询兴趣包对应的返回top-k查询结果的发送接口outface删除,如果返回top-k查询结果的发送接口outface已经是最后一个发送接口outface或者该查询兴趣包在待定兴趣表pit中的条目的持续超过预设时间阈值interestlifetime,则删除该查询兴趣包在待定兴趣表pit中的条目,并更新内容存储cs中的top-k查询结果的完备状态为完备。
优选地,步骤10)将收到的top-k查询结果、内容存储cs中的top-k查询结果进行聚合处理的详细步骤包括:首先,根据内容存储cs中的top-k查询结果、收到的top-k查询结果两者的内容判断进行聚合处理的聚合类型,所述聚合类型包括缓存包含聚合、新到包含聚合、重叠聚合和不相交聚合四种,其中缓存包含聚合是指内容存储cs中的top-k查询结果包含收到的top-k查询结果,新到包含聚合是指收到的top-k查询结果包含内容存储cs中的top-k查询结果,重叠聚合是指内容存储cs中的top-k查询结果和收到的top-k查询结果两者部分重叠,不相交聚合是指内容存储cs中的top-k查询结果和收到的top-k查询结果两者不重叠;然后,基于不同的聚合类型进行不同的聚合处理:针对缓存包含聚合,直接将内容存储cs中的top-k查询结果作为聚合处理结果输出;针对新到包含聚合,直接将收到的top-k查询结果替换内容存储cs中的top-k查询结果并作为聚合处理结果输出;针对重叠聚合和不相交聚合,则将内容存储cs中的top-k查询结果、收到的top-k查询结果根据预设的评分函数进行评分,根据评分将内容存储cs中的top-k查询结果、收到的top-k查询结果两者进行快速排序,并针对快速排序的所有响应答案选择得分最高的k个响应答案作为聚合处理结果输出。
优选地,步骤1)中接收的查询兴趣包包含评分阈值maxscore,所述根据评分将内容存储cs中的top-k查询结果、收到的top-k查询结果两者进行快速排序之前,还包括将收到的top-k查询结果中包含的k个响应答案中评分大于评分阈值maxscore的响应答案删除。
本发明还提供一种基于命名数据网络的top-k查询系统,包括计算机系统,所述计算机系统被编程以执行本发明所述基于命名数据网络的top-k查询方法的步骤。
本发明与现有技术相比,具有以下优点和有益效果:
1、通过在命名数据网络中的top-k查询能够有效地满足内容消费者向数据生产者所发出的各种自身请求的内容数据,并且具有很好的查询效率,查询方式高效可靠、响应快速,能够解决命名数据网络查询中返回结果的爆炸式增长的问题。
2、本发明的top-k查询方法为单个路由节点的方法,基于该单个路由节点的方法进行多点组合实质上形成了分布式处理结构,不仅能够处理大规模数据、提高查询效率和性能,还能够增强top-k查询框架的伸缩性和可扩展性,各功能能够保持很好的独立性。
附图说明
图1为本发明实施例方法的基本流程示意图。
图2为本发明实施例中查询兴趣包的结构示意图。
图3为本发明实施例中内容数据包的结构示意图。
图4为本发明实施例中完备状态的判断原理示意图。
图5为本发明实施例中循环或重复的查询兴趣包的原理示意图。
图6为本发明实施例中聚合后立即响应策略ira的原理示意图。
图7为本发明实施例中仅响应最终聚合策略mar-1的原理示意图。
图8为本发明实施例中多次聚合后响应策略mar-2的原理示意图。
图9为本发明实施例中two_k_aggregation算法的原理示意图。
图10为本发明实施例方法中四种聚合处理的原理示意图。
具体实施方式
如图1所示,本实施例基于命名数据网络的top-k查询方法的实施步骤包括:
1)接收上一跳的查询兴趣包,对循环或重复的查询兴趣包对应的查询兴趣包进行抑制,如果接收的查询兴趣包被抑制,则跳转执行步骤1);否则,跳转执行步骤2);
2)判断完全匹配内容存储cs是否找到匹配的top-k查询结果,如果找到匹配的top-k查询结果则跳转执行步骤3);否则,跳转执行步骤4);
3)判断top-k查询结果是否完备,如果top-k查询结果完备,则向上一跳返回完备的top-k查询结果,结束并退出;否则如果top-k查询结果不完备,则跳转执行步骤4);
4)初始化转发信息库转出接口数组变量outfacefib和待定兴趣表转出接口数组变量outfacepit;判断完全匹配待定兴趣表pit是否找到匹配的条目,如果找到匹配的条目,则将查询兴趣包的接收接口inface添加到匹配的条目、待定兴趣表pit中匹配条目的outface的值添加到待定兴趣表转出接口数组变量outfacepit;否则,将查询兴趣包存入待定兴趣表pit,并设置存入条目的待定兴趣表转出接口数组变量outfacepit为空;
5)判断最长前缀匹配转发信息库fib是否匹配成功,如果匹配不成功,则丢弃查询兴趣包并退出;否则,跳转执行步骤6);
6)将匹配结果存入转发信息库转出接口数组变量outfacefib;
7)将转发信息库转出接口数组变量outfacefib减去待定兴趣表转出接口数组变量outfacepit得到下一跳接口集合out;
8)执行本地top-k查询,将本地top-k查询得到的k个答案作为top-k查询结果并缓存到内容存储cs,并根据下一跳接口集合out将查询兴趣包分别转发至各下一跳;
9)等待下一跳返回内容数据包,当收到内容数据包时解析获取内容数据包中的top-k查询结果,并跳转执行步骤10);
10)将收到的top-k查询结果、内容存储cs中的top-k查询结果进行聚合处理,得到包含k个答案的新的top-k查询结果并替换更新内容存储cs中的缓存;
11)根据下一跳集合out中的下一跳是否全部返回top-k查询结果来更新内容存储cs中的top-k查询结果的完备状态,如果内容存储cs中的top-k查询结果尚未完备,则跳转执行步骤9);否则,跳转执行步骤12);
12)将内容存储cs中的top-k查询结果封装,判断完全匹配待定兴趣表pit是否找到匹配的条目,如果找到匹配的条目,则将封装后的top-k查询结果转发给匹配的条目对应的上一跳;否则,丢弃查询兴趣包并退出。
本实施例中,步骤9)中下一跳返回内容数据包以及封装后的top-k查询结果得到的内容数据包由三个字段构成:(pid,sa,tl),其中pid为查询兴趣包的源id,用于识别来自不同源的响应答案;sa为score数组,用来表示top-k查询结果中各个答案的得分;tl为top-k查询结果的k个答案的数据或元组列表。对于命名数据网络而言,命名数据网络的消费节点consumer中发送top-k查询兴趣包,执行本实施例基于命名数据网络的top-k查询方法的节点同时作为数据生产节点producer中进行本地化数据top-k查询、并作为路由节点中对来自不同节点的top-k数据或元组进行排序、聚合处理选择出最符合的top-k数据或元组、并最终作为消费节点返回全局top-k数据或元组,在实现动态分布数据的top-k查询过程中,使用基于命名数据网络的分布式查询处理,有效地提高了top-k查询的效率。
本实施例中,步骤2)中判断完全匹配内容存储cs是否找到匹配的top-k查询结果,完全匹配内容存储cs使用完全匹配算法匹配结果数据,步骤5)判断最长前缀匹配转发信息库fib是否匹配成功时,,使用最长前缀匹配(lpm)算法匹配fib转发信息表中的表项来查找下一跳(下游节点),且对于属性范围对,可以使用逻辑和算术运算(例如“<,>,=”)和通配符(例如“*,?”)。
在查询兴趣包转发经过的路由节点中,对于循环或重复兴趣进行抑制。当兴趣经过路由节点或到达相关数据源,会对路由缓存或数据源进行本地查询,响应答案的总和可能远大于k个,所以使用过滤函数f(score,hop,k)来获取本地top-k个数据或元组。当本地查询结果不完备时,兴趣包会继续转发到下游节点。在数据聚合与返回阶段,首先数据返回是原路返回,主要通过匹配相关路由节点中兴趣暂存表pit中的兴趣名字查找到返回的上一跳(上游节点)。在返回过程中,每个经过的路由节点可能接收多组top-k数据或元组。因此,引入了聚合处理算法来聚合来自不同源的本地top-k答案。聚合函数agg(top-k1,top-k2,...)指经过聚合处理后输出一组top-k数据或元组。接下来对输出数据的返回状态进行设置,当从该路由节点转发出去的兴趣包都收到响应结果后,则设置为完备返回,并从兴趣暂存表pit中删除有关该兴趣的记录,否则只删除有关该兴趣的发送接口outface,以便接收其它接口的返回结果。对于返回到上一跳的top-k数据或元组将重新封装返回。至于何时返回,则根据查询兴趣包中设置的响应要求按对应响应策略返回。假设命名数据网络中各数据源分布存储了dmoz网站分类数据,每个本地数据库存储的每个网站信息所包括的字段为website,title,description,topic。其中website为网站名称,title为网站内容的标题,description为描述网站内容的一段介绍文本,topic为网站的层次分类目录名字,如:
/arts/architecture/history/academicdepartments。
因此,转发阶段,假设用户的兴趣实例i为:
/arts/architecture/history/academicdepartments:description='%computermodel%':k=10:maxscore=1.0:restrategy=mar-2。
在命名数据网络的路由节点中将根据兴趣的层次名字/arts/architecture/history/academicdepartments将用户兴趣组播到相应数据源中,在数据源中将会根据整个兴趣的约束条件查询本地数据库,并根据评分函数对各数据项计算匹配度,然后选择top-k个数据项,不足k个数据项,则返回所有数据项及它们的匹配度。在数据聚合阶段,返回路径中经过的路由节点利用完全匹配在pit中找到对应的条目,以沿原始转发路径的相反方向返回答案。此外,该方案允许消费者改变查询范围、匹配度和响应策略,以更好地满足他们的要求。
如图2所示,本实施例中查询兴趣包的兴趣名称包含名字的前缀prefix和属性范围对;selector是可选择项,包括优先顺序orderpreference、发布者过滤器publisherfilter、选择范围scope等;签名字段k包括兴趣包的签名信息等;随机数值nonce是一个包含随机数字段,根据它可以很容易地判断重复的兴趣包,以便及时地丢弃。上述字段均为命名数据网络的查询兴趣包标准字段,此外,本实施例中查询兴趣包还包含可选项评分阈值maxscore、响应策略信息restrategy两个新增字段,可选项评分阈值maxscore用于筛选答案、响应策略信息restrategy用于选择返回top-k查询结果的方式,其具体实现将在下文进行说明。
如图3所示,本实施例中每一跳返回的内容数据包包括兴趣名字(查询兴趣包的兴趣名称,为消费者一开始向生产者所请求的名称数据)、元信息metainfo、签名方法signnature(包括摘录算法、证明等)和签名信息signedinfo(包括发布者id、密钥定位、失效时间等)以及k个响应答案(top-k元组),每一个响应答案的结构为(scorei,tuplei),scorei为响应答案的得分,tuplei为响应答案的元组,其中i<=k,k即为top-k中指定的数值k,用户可以根据需要在查询兴趣包中指定。上述字段均为命名数据网络的查询兴趣包标准字段,本实施例中仅仅是在元信息metainfo中额外增加了一个completestate,用来标识内容数据包对应的查询兴趣包是否完备,如果查询兴趣包完备,则将其对应的内容数据包的completestate设置为真,通过completestate的值可以估计答案是否为完备的答案。如图4所示,其中|response|表示返回答案response的数量,|outfaces|表示发送接口outface的数量,对于每一个查询兴趣包而言,都存在一个接收接口inface和至少一个发送接口outface,|response|<|outfaces|则表示内容存储cs中的top-k查询结果不完备,如图4(a)和图4(b)所示,否则|response|=|outfaces|则表示内容存储cs中的top-k查询结果完备,如图4(c)所示。本实施例中,步骤11)中更新内容存储cs中的top-k查询结果的完备状态的详细步骤包括:在待定兴趣表pit中将该查询兴趣包对应的返回top-k查询结果的发送接口outface删除,如果返回top-k查询结果的发送接口outface已经是最后一个发送接口outface或者该查询兴趣包在待定兴趣表pit中的条目的持续超过预设时间阈值interestlifetime,则删除该查询兴趣包在待定兴趣表pit中的条目,并更新内容存储cs中的top-k查询结果的完备状态为完备。
对循环或重复的查询兴趣包对应的查询兴趣包进行抑制是解决命名数据网络查询中返回结果的爆炸式增长的问题的一个关键技术问题。参见图5,对于路由节点1而言,其发出的查询兴趣包i1经过某路径达到路由节点d,如果其通过另一路径达到路由节点d,则路由节点d收到了重复的查询兴趣包(简称重复兴趣),同时如果路由节点d将查询兴趣包i1又通过任意路径转发给路由节点1,则路由节点1收到了循环的查询兴趣包(简称循环兴趣)。本实施例中,当一个路由节点从上游节点接收到多个名字相同的查询兴趣包时,该路由节点只将第一个查询兴趣包向下游的生产者转发。当两个查询兴趣包的名字和随机数值nonce的值相同,即认为接收到了相同兴趣。进一步当该兴趣的inface等于该查询兴趣包在待定兴趣表pit记录中的某个发送接口outface,即认为接收到了循环兴趣,否则即认为是重复兴趣。在路由节点转发兴趣时,可能会收到来自不同路径的循环兴趣或重复兴趣。因为在复杂的命名数据网络中,查询兴趣包可能会随机沿着网络路径转发,这样就可能会产生循环兴趣;如果相同的兴趣包沿着不同路径在路由节点之间转发,就可能会产生重复兴趣。本实施例中,步骤1)的详细步骤包括:
1.1)接收上一跳的查询兴趣包;
1.2)判断完全匹配待定兴趣表pit是否找到匹配的条目,如果找到匹配的条目,则将查询兴趣包携带的随机数值nonce和匹配的条目的随机数值nonce是否相同,如果随机数值nonce相同,则跳转执行步骤1.3);否则,则将查询兴趣包的接收接口inface添加到匹配的条目、待定兴趣表pit中匹配条目的发送接口outface的值添加到待定兴趣表转出接口数组变量outfacepit,则跳转执行步骤2);如果没有找到匹配的条目,则将查询兴趣包存入待定兴趣表pit,并设置存入条目的待定兴趣表转出接口数组变量outfacepit为空,跳转执行步骤2);
1.3)通过接收查询兴趣包的接收接口inface向上一跳发送否定应答消息nack,收到否定应答消息nack的上一跳在待定兴趣表pit中删除该查询兴趣包对应的发送接口outface,如果该查询兴趣包对应的发送接口outface是该查询兴趣包的唯一的一个发送接口outface,则在待定兴趣表pit中删除该查询兴趣包对应的条目;跳转执行步骤1)。
本实施例中,步骤1)中接收的查询兴趣包包含响应策略信息字段restrategy(如图2所示),所述响应策略信息restrategy包含了向上一跳返回top-k查询结果的方式,返回top-k查询结果的方式分别包括三种:
(1)聚合后立即响应策略ira:每一次聚合处理后立即返回top-k查询结果;如图6所示,aggi表示第i次聚合操作,因为在路由节点中每收到一个响应就会触发一次聚合操作;responsei表示对于某个兴趣该路由节点对于下游节点的第i次响应,任意第i次聚合处理后得到答案responsei,且立即返回答案responsei。
(2)仅响应最终聚合策略mar-1:仅在top-k查询结果完备时返回top-k查询结果;如图7所示,任意第i次聚合处理后得到答案responsei,最终聚合处理得到完毕的答案response,仅在top-k查询结果完备时返回答案response。
(3)多次聚合后响应策略mar-2:多次聚合处理后立即返回top-k查询结果且在top-k查询结果完备时返回top-k查询结果;如图8所示,任意第i次聚合处理后得到答案responsei,以两次为例,每2次聚合处理后得到答案responsei+1并返回答案responsei+1。
且步骤3)中如果top-k查询结果不完备时:如果响应策略信息restrategy为聚合后立即响应策略ira则立即向上一跳返回匹配的top-k查询结果,然后再跳转执行步骤4);如果响应策略信息restrategy为多次聚合后响应策略mar-2则根据聚合处理的次数对多次聚合后响应策略mar-2的聚合次数取模,根据取模结果是否为指定值来决定是否向上一跳返回匹配的top-k查询结果,然后再跳转执行步骤4);步骤11)中如果内容存储cs中的top-k查询结果尚未完备时:如果响应策略信息restrategy为聚合后立即响应策略ira则立即向上一跳返回内容存储cs中的top-k查询结果,然后再跳转执行步骤9);如果响应策略信息restrategy为多次聚合后响应策略mar-2则根据聚合处理的次数对多次聚合后响应策略mar-2的聚合次数取模,根据取模结果是否为指定值来决定是否向上一跳返回内容存储cs中的top-k查询结果,然后再跳转执行步骤9)。
对于聚合后立即响应策略ira而言,在收到每个非第一个top-k数据或元组之后,该top-k数据或元组在路由节点中与缓存的top-k数据或元组聚合后立即响应,所以ira策略表示每次聚合操作后立即将答案发送至上一跳,每聚合一次就会响应一次。在路由节点中,在对与兴趣相关的最后top-k数据或元组进行最终聚合操作之后的top-k数据或元组称为区域top-k元组。在聚合后立即响应策略ira中,不能保证答案responsei(i<n)的一些元组一定属于区域top-k数据或元组,但是答案responsen一定属于区域top-k元组并且总有minscore(responsei+1)>=minscore(responsei)。minscore(responsei)表示第i次响应结果中匹配度最小的元组的匹配度,minscore(responsei+1)表示第i+1次响应结果中匹配度最小的元组的匹配度。假设在一个兴趣响应处理期间存在n次聚合操作,并且整个响应时间小于缓存的最小时间,则对其消费者的响应数据sira的最大量是:
sira=|k1+[top-k(k1∪k2)-k1]+[top-k(k1∪k2∪k3)-k1-k2]+···|
=|k1+(k2-k1∩k2)+(k3-k2∩k3-k1∩k3)+···|<|n*k|
上式中,ki表示第i次接收到的收到的top-k查询结果的大小,top-k表示对收到的top-k查询结果与内容存储cs中的top-k查询结果的聚合操作后得到新的top-k数据的大小,∪表示多个数据集合并后的大小,“-”表示去除掉内容相同的数据项,n为接收top-k查询结果的次数,k为top-k中的k即指定的查询结果中的答案数量。如果在不同的源和下游路由器中存在更多相同的top-k数据或元组,那么响应数据sira的大小就会更小。在响应答案中,第一个响应时间tfr≈tr-ndn≈tlf*2+tlq,其中tr-ndn是传统ndn兴趣的响应时间,tlf是到查询兴趣最近源的转发时间,tlq是在某个路由节点中的本地查询时间。令tc是ndn上top-k查询的完成时间,所以tc=tf+tr+ta+tlq,这里,tf是转发到最后一个数据源的时间,tr是最后一个响应的传输时间,ta是最后一个数据的聚合总时间(通常是最长的聚合链),tlq是最后一个数据来源的本地查询时间。通常ta比其他因素更大,变化更大。最长的聚合链意味着对一个兴趣来说数据从源或缓存转发器返回的路径中发生的聚合总量最大。如果聚合节点数量在最长聚合链中为n,则ta=tai*n,其中tai为每个聚合节点中的平均聚合时间。
对于仅响应最终聚合策略mar-1而言,一个兴趣只有一个数据包(只有最后一个全局top-k数据或元组)返回,如图10所示。在mar-1中,当接收到top-k数据或元组时将进行聚合操作,然后聚合答案将替代缓存答案。如果每个outface都得到一个完备的或为null的答案,最后的聚合答案将被返回,并且其completestate将被设置为真。假设所有响应时间小于最小缓存时间,smar-1=|top-k元组|。仅响应最终聚合策略mar-1具有下述特点:a)区分来自不同来源的新的top-k数据或元组:如果top-k数据或元组来自不同的来源,则向每个数据包添加或更新pid。根据它们的来源删除重复的top-k数据或元组。此外,我们可以使用摘要信息作为标识符来区分答案。b)如果它们有不同的来源,为一个兴趣聚合新传入的top-k数据或元组以及缓存的top-k数据或元组。c)为一个兴趣计算剩余有效的发送接口outface:当收到nack的兴趣时,从待定兴趣表pit中删除nack(否定应答应答)的兴趣(例如重复的,循环的兴趣)的发送接口outface或接收接口inface。并且在收到它们的响应时删除正常的兴趣的发送接口outface。d)如果兴趣没有发送接口outface或interestlifetime超时,则响应聚合结果并清除待定兴趣表pit中对应兴趣的条目。对于仅响应最终聚合策略mar-1的top-k查询,最后的响应时间(或完成时间)等于第一个响应时间,即:tc=tf+tr+ta*n+tlq,等于聚合后立即响应策略ira的top-k查询的响应时间。
对于多次聚合后响应策略mar-2而言,如果延迟响应直到多次聚合之后,相比于mar-1可以缩短响应时间(第一组top-k数据或元组的响应时间)。例如,仅仅在每两次聚合之后响应,其消费者响应数据的最大大小smar-2为:smar-2=|[top-k(k1∪k2)]+[top-k(k1∪k2∪k3∪k4)-k1-k2]+···|<|(n/2)*k|,这里的n是响应的次数。上式中,ki表示第i次接收到的收到的top-k查询结果的大小,top-k表示对收到的top-k查询结果与内容存储cs中的top-k查询结果的聚合操作后得到新的top-k数据的大小,∪表示多个数据集合并后的大小,“-”表示去除掉内容相同的数据项,n为接收top-k查询结果的次数,k为top-k中的k即指定的查询结果中的答案数量。对于多次聚合后响应策略mar-2,第一个响应时间tfr≈tr-ndn≈tlf*2+tlq,等于聚合后立即响应策略ira的top-k查询,其中tr-ndn是传统ndn兴趣的响应时间,tlf是到查询兴趣最近源的转发时间,tlq是在某个路由节点中的本地查询时间。对于这三种响应策略,响应数据的最大大小的关系为:smar-1<smar-2<sira,即聚合后立即响应策略ira最大,多次聚合后响应策略mar-2居中,仅响应最终聚合策略mar-1最小。
本实施例中,步骤10)将收到的top-k查询结果、内容存储cs中的top-k查询结果进行聚合处理是针对每次只对两组top-k元组根据每个元组的score进行快速排序、选择,本实施例中称为two_k_aggregation算法,该算法的聚合操作只涉及新来的top-k数据或元组以及缓存的top-k数据或元组集合,主要组成部分为快速排序算法,所以其计算复杂度为o(2k*log22k)+o(k),two_k_aggregation算法的计算复杂度与响应的数量无关。如图9所示,每通过发送接口outface收到一个top-k查询结果,则采用two_k_aggregation算法(简称agg)将收到的top-k查询结果、内容存储cs中的top-k查询结果进行一次聚合处理,并将聚合处理得到的top-k查询结果缓存在内容存储cs中以备下次聚合处理或者作为完备的top-k查询结果发送给上一跳。
本实施例中,步骤10)将收到的top-k查询结果、内容存储cs中的top-k查询结果进行聚合处理的详细步骤包括:首先,根据内容存储cs中的top-k查询结果、收到的top-k查询结果两者的内容判断进行聚合处理的聚合类型,所述聚合类型包括缓存包含聚合、新到包含聚合、重叠聚合和不相交聚合四种,其中:缓存包含聚合是指内容存储cs中的top-k查询结果(top-ki,j)包含收到的top-k查询结果(top-ki),新到包含聚合是指收到的top-k查询结果(top-ki,j)包含内容存储cs中的top-k查询结果(top-ki),重叠聚合是指内容存储cs中的top-k查询结果(top-ki,j)和收到的top-k查询结果(top-ki,m)两者部分重叠,不相交聚合是指内容存储cs中的top-k查询结果(top-ki,j)和收到的top-k查询结果(top-kl,m)两者不重叠;然后,基于不同的聚合类型进行不同的聚合处理:针对缓存包含聚合,直接将内容存储cs中的top-k查询结果(top-ki,j)作为聚合处理结果输出,如图10(a)所示;针对新到包含聚合,直接将收到的top-k查询结果(top-ki,j)替换内容存储cs中的top-k查询结果(top-ki)并作为聚合处理结果输出,如图10(b)所示;针对重叠聚合和不相交聚合,则将内容存储cs中的top-k查询结果、收到的top-k查询结果根据预设的评分函数进行评分,根据评分将内容存储cs中的top-k查询结果、收到的top-k查询结果两者进行快速排序,并针对快速排序的所有响应答案选择得分最高的k个响应答案作为聚合处理结果输出,如图10(c)和图10(d)所示。图10显示了四种不同的top-k数据或元组的聚合类型,分别为缓存包含聚合、新到包含聚合、重叠聚合和不相交聚合。其中只有两种类型(重叠聚合、不相交聚合)的操作将排序较新的top-k数据或元组以及缓存的top-k数据或元组,只要有一组具有scores的top-k数据或元组到达,它将根据pid(pid为数据源节点的id,网络中出现的某个top-k元组与数据源的关系是一对一或一对多的关系)并使用其中一种聚合类型快速聚合。所以这种聚合方式将单块聚合在其响应路径中分解成更小的和异步的聚合。该聚合运算符不需要缓存所有的响应答案,并能延迟聚合,直到所有top-k答案到达相应的地方。
本实施例中,步骤1)中接收的查询兴趣包包含评分阈值maxscore(如图2所示),所述根据评分将内容存储cs中的top-k查询结果、收到的top-k查询结果两者进行快速排序之前,还包括将收到的top-k查询结果中包含的k个响应答案中评分大于评分阈值maxscore的响应答案删除,好处是如第一次返回最优的k个答案,下次用户可以设定上次k个答案中最小的分值为maxscore,则可以返回次优的k个答案。为了调整用户接收数据或元组所属得分区域,可以在兴趣中设置maxscores的值,从而在路由节点调整只接收低于maxscore的数据或元组,只要内容数据包的得分>=maxscore则拒收,从而允许用户端通过设置maxscore值,获取满足某个匹配度范围的查询结果。本实施例中,具体使用过滤函数f(score,hop,k)来将收到的top-k查询结果中包含的k个响应答案中评分大于评分阈值maxscore的响应答案删除,以获取本地top-k个数据或元组。
本实施例基于命名数据网络的top-k查询方法支持用户根据自身的喜好去定制一些关键的查询参数,如兴趣包的转发范围、top-k查询中k的大小或一些查询喜好、响应策略等。在ira和mar-2响应策略中,如果top-k查询允许消费者设置转发范围,它会缩短时间间隔,减少数据包的聚合次数。对于k的大小,如果k元组的数目大于数据包可携带的数目,则响应答案将需要多个数据包携带,因此,如果一个消费者想要获得top-k元组并且k元组的数目大于或等于数据包可携带的数目,消费者可以设定返回数据或元组的score上限值为top-k查询发出多个兴趣。另外用户还可以定制一些查询喜好,如响应字段、新鲜度、受欢迎程度等。
综上所述,本实施例基于命名数据网络的top-k查询方法在命名数据网络中实现top-k查询是汇聚所有相关数据源上的本地top-k个最匹配用户兴趣的数据项,并在返回路径中的汇聚路由节点中聚合各个来自不同路径或数据源的本地或区域的top-k个数据项,并通过排序、选择得到区域或更大区域的top-k个数据项,然后缓存并返回到上游路由节点,最终在用户节点得到全局的top-k个最匹配用户兴趣的数据项。命名数据网络和top-k查询两者结合则可以允许根据动态分布数据的流行度、语义匹配度、新鲜度、跳数等数据属性值的综合值返回top-k个最匹配的数据项,防止命名数据网络查询中返回结果的爆炸式增长,并能根据数据包最大允许大小、网络带宽等网络性能参数调节返回的结果大小。但要在命名数据网络中实现top-k查询的主要技术问题是用户top-k查询兴趣的定义、网络中重复兴趣和循环兴趣的抑制并对返回结果完备性判断的影响、路由节点中利用有限存储空间的top-k聚合算法、适用不同响应速度的结果响应策略。
本发明基于命名数据网络的top-k查询方法是基于ndn的基础工具nfd和ndn-cxx开发的,并连接包含查询结果数据项或元组的数据库。通过从消费者发送携带top-k元组的兴趣包,经过一些匹配计算转发至生产者,再对数据包进行相关处理选择出最符合的top-k结果,进而完成整个top-k查询过程。此外,本实施例还提供一种基于命名数据网络的top-k查询系统,包括计算机系统,该计算机系统被编程以执行本实施例基于命名数据网络的top-k查询方法的步骤。
以上所述仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!