一种人工智能深度学习的方法与流程
本发明涉及媒质六大成分值的检测的深度优化领域,特别一种人工智能深度学习的方法。
背景技术
传统方式靠人工采用化学燃烧方式测量煤炭六大成分从而确定煤炭价格,这种检测方法的实时性差、误差大、人为干扰强;近几年为了排除人为干扰,采用了激光测量法、伽马射线法,虽然激光测量法、伽马射线法,但是上述方法投入成本高、误差大、实时性差,同时伽马射线法辐射大,对操作者人身伤害大;2016年起国家要求逐步淘汰了伽马射线法测量技术。
技术实现要素:
为解决现有技术中存在的问题,本发明提供了一种人工智能深度学习的方法,解决了以往媒质实时精准检测设备没有“深度学习”人工智能方法的问题,解决了以往在处理数据时效率低、成本高、实时性差的问题。
本发明采用的技术方案如下:一种人工智能深度学习的方法,方法包括如下步骤:
步骤a1:媒质实时精准检测设备内的系统初始化,将接收到的六大成分数据输入到“煤种专家系统”进行数据处理;
步骤a2:将“煤种专家系统”的数据输出到“深度学习系统”进行数据处理;
步骤a3:将“深度学习系统”的数据输出到“监督学习算法系统”进行数据处理,最后将数据输出到大数据分析系统。
优选地,“煤种专家系统”的数据处理方法包括如下:
步骤b1:录入煤质的六大成分值,通过“深度学习系统”对比输入的煤的六大成分值与已有的煤种特性库的特性值,如果煤质的六大成分值基本相同则提取煤种特性库的特性值和当前值输入到“深度学习系统”中;
步骤b2:如果当前输入的煤的六大成分值与煤种特性库不同,其特性与已有的煤种特性库存在较大差异,且长时间存在,“深度学习系统”将当前数据传输到在煤种特性数据库处理平台,通过大数据处理系统自定义一个煤种特性值,定义后再输入到深度学习系统中。
优选地,“深度学习系统”的数据处理方法如下:
步骤c1:将输入的六大成分值按日期分类,分为过去一天、过去一周、过去一个月、过去三个月、过去半年、过去一年和过去三年,分别标注为cd1、cd2、cd3、cd4、cd5、cd6、cd7;
步骤c2:将七个时间档cd1、cd2、cd3、cd4、cd5、cd6、cd7的六大成分值在中央处理器内经过算法程序处理,将cd1、cd2、cd3、cd4、cd5、cd6、cd7转换为媒质的六大成分值,且存放在ai中间值数据库中;
步骤c3:cd1处理后的结果从ai中间值数据库输出,在中央处理器中进行“共性数据、差异数据、剩余数据”算法处理,将当前数据与cd1的共性、差异和剩余的数据进行对比,如果共性数据达到阈值,将停止学习,且将数据输出到“监督学习算法系统”;如果共性数据达不到阈值,将重复步骤b2;
步骤c4:将cd2、cd3、cd4、cd5、cd6、cd7进行步骤c3的数据处理。
优选地,“监督学习算法系统”的处理算法数据如下
监督学习算法包括“找差算法”和“微调算法”;
步骤e1:将数据进行“找差算法”处理,所述找差算法为:
利用“带记忆和裂变的修正k-means算法”数据挖掘技术找到当前三个质心点为c(c1、c2、c3)基准点;“深度学习”找到共性数据有n个,为ci(i=1、2、3…..n)
式中的asse就是找差算法的最终值;
步骤e2:将数据进行“微调算法”处理,所述“微调算法”为:
假设三个质心点数值的最大值为cmax=max(c1、c2、c3);中间值为cmid=mid(c1、c2、c3);最小值为cmin=min(c1、c2、c3);cmin<=cmid<=cmax,
当前输入的值为cc,其最终值为cf,则微调算法包括如下步骤:
步骤f1:如果cc<cmin,cf=cc+asse;
步骤f2:如果cc>cmax,cf=cc-asse;
步骤f3:如果cmin<=cc<=cmid,cf=cc+asse/2;
步骤f4:如果cmid<=cc<=cmax,cf=cc-asse/2;
cf为整个监督学习算法的输出值。
式中,c对应为发热量(q)、水分(m)、灰分(a)、挥发分(v)、固定碳(fc)和含硫量(s)六种成分的某一成分值便可。
本发明一种人工智能深度学习的方法的有益效果如下:
1.该系统是人工智能相关技术在煤炭成分测量领域的独创、首次运用,为将来的更好发展抛砖引玉;
2.“深度学习系统”技术为其它固体、液体和气体成分值的分析独创性的提供了一种有用的参考;
3.本系统ai的“深度学习系统”具有强大的延展性和优化空间。
附图说明
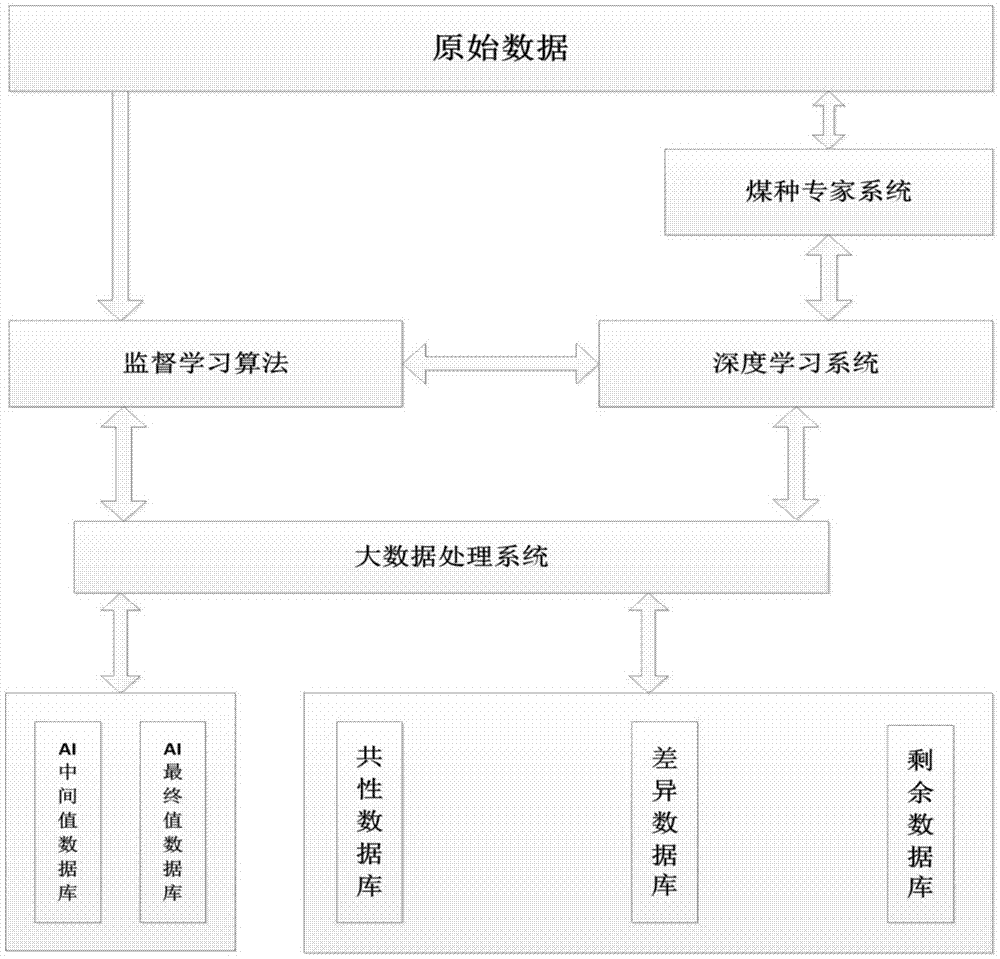
图1为本发明一种人工智能深度学习的方法的系统总框图。
图2为本发明一种人工智能深度学习的方法的“煤种专家系统”框图。
图3为本发明一种人工智能深度学习的方法的“深度学习系统”框图。
图4为本发明一种人工智能深度学习的方法的“监督学习算法系统”框图。
具体实施方式
下面结合附图对本发明的实施例进行详细说明。
下面对本发明的具体实施方式进行描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
如图1所示,一种人工智能深度学习的方法包括如下步骤:
步骤a1:媒质实时精准检测设备内的系统初始化,将接收到的六大成分数据输入到“煤种专家系统”进行数据处理;
步骤a2:将“煤种专家系统”的数据输出到“深度学习系统”进行数据处理;
步骤a3:将“深度学习系统”的数据输出到““监督学习算法系统”的处理算法数据如下”进行数据处理,最后将数据输出到大数据分析系统。
本实施方案在实施时,本部分利用大数据处理系统中提供的有用数据,分析数据的共性和差异,通过ai的“深度学习”、神经网络等技术处理,系统可以自我不断的学习,对“转换模型处理”中得到的煤炭六大成分的数值进行有价值的修正或局部微调,以进一步提升煤炭六大成分的测量精确度,从而逐步降低测量误差,并适应复杂的煤种及混烧掺烧煤种,一般而言,通过ai处理后,煤炭六大成分的测量值误差不会超过0.1%。
本系统包含三部分,分别为:煤种专家系统、深度学习系统和监督学习算法系统。煤种专家系统对所有的常规煤种提供一种定性的参考和基准点;深度学习系统负责对当前及历史的煤质数据分析、学习并做出共性和差异性,以供监督学习算法系统优化煤质六大成分测量值;“监督学习算法系统”的处理算法数据如下主要负责推演出煤质六大成分优化值。
本系统包含三部分,分别为:煤种专家系统、深度学习系统和遗传进化系统。煤种专家系统对所有的常规煤种提供一种定性的参考和基准点;深度学习系统负责对当前及历史的煤质数据分析、学习并做出共性和差异性,以供遗传进化系统优化煤质六大成分测量值;“监督学习算法系统”的处理算法数据如下主要负责推演出煤质六大成分优化值。
如图2所示,“煤种专家系统”的数据处理方法包括如下:
步骤b1:录入煤质的六大成分值,通过“深度学习系统”对比输入的煤的六大成分值与已有的煤种特性库的特性值,如果煤质的六大成分值基本相同则提取煤种特性库的特性值和当前值输入到“深度学习系统”中;
步骤b2:如果当前输入的煤的六大成分值与煤种特性库不同,其特性与已有的煤种特性库存在较大差异,且长时间存在,“深度学习系统”将当前数据传输到在煤种特性数据库处理平台,通过大数据处理系统自定义一个煤种特性值,定义后再输入到深度学习系统中。
本实施方案在实施时,我们国家的煤可以分为无烟煤、烟煤、褐煤3大类,17个小类别,它们分别是无烟煤、贫烟、贫瘦煤、瘦煤、焦煤、肥煤、1/3焦煤、气肥煤、气煤、1/2中粘煤、弱粘煤、不粘煤、长焰煤、褐煤。每一种煤种都有相对固定的特性,如:无烟煤固定碳含量高,挥发分产率低,密度大,硬度大,燃点高,燃烧时不冒烟;而褐煤的含水量大,燃烧值低。根据这些煤种的特性,本系统将它们分类,赋予其对应的煤质六大成分特性。同时为了适应国内煤炭的混烧和掺烧,本系统可以自定义煤种,并赋予其对应的六大成分特性。
如图3所示,“深度学习系统”的数据处理方法如下:
步骤c1:将输入的六大成分值按日期分类,分为过去一天、过去一周、过去一个月、过去三个月、过去半年、过去一年和过去三年,分别标注为cd1、cd2、cd3、cd4、cd5、cd6、cd7;
步骤c2:将七个时间档cd1、cd2、cd3、cd4、cd5、cd6、cd7的六大成分值在中央处理器内经过算法程序处理,将cd1、cd2、cd3、cd4、cd5、cd6、cd7转换为媒质的六大成分值,且存放在ai中间值数据库中;
步骤c3:cd1处理后的结果从ai中间值数据库中输出,在中央处理器中进行“共性数据、差异数据、剩余数据”算法处理,将当前数据与cd1的共性、差异和剩余的数据进行对比,如果共性数据达到阈值,将停止学习,且将数据输出到“遗传进化系统”;如果共性数据达不到阈值,将重复步骤b2;
步骤c4:将cd2、cd3、cd4、cd5、cd6、cd7进行步骤c3的数据处理。
本实施方案在实施时,深度学习系统将历史数据库的煤质6大成分值(对应为“ai最终值数据库”里的数据),按日期分类,分别按过去一天、过去一周、过去一个月、过去三个月、过去半年、过去一年和过去三年的数据分为7个时间档,分别标注为cd1、cd2、cd3、cd4、cd5、cd6、cd7,按照特定的算法得到7个时间档的煤质六大成分值,这7组值随时间推移相对变化,但变化相对较小,这7组值将作为深度学习7次循环学习的重要原始数据。
初始阶段如果没有时间更长的数据,譬如一年和三年的数据,系统自动初始化为零,且循环学习自动变为5次,依次类推。
原始的煤质成分值进入深度自学习系统,第一次学习以当前时间为基准退后一天的煤质最终成分值为学习的基准数据,简称cd1,通过特定的学习算法,找出当前数据与cd1的共性、差异和剩余数据,如果共性数据多,差异和剩余数据少,且达到阈值,将停止学习,如果共性数据少,差异和剩余数据多,达不到阈值,将进行第二次学习,依次类推,不同的是每次学习的基准数据分别为cd2、cd3、cd4、cd5、cd6、cd7和每一层学习的算法会不同,原则上来讲;
1.时间上越靠近当前时间的数据越重要,权重越高;
2.历史上煤种特性越接近当前煤种特性的数据越重要,权重越高。如果通过7层学习任然找不到满足条件的共性数据,系统将自动挑选预设的7层学习,自动从某一层开始学习,这时候,系统的学习方法将做适当调整,直到共性数据达到阈值,为了防止过度学习和死循环,系统在学习次数达到预设值后,将停止学习,当然这个预设值可人为设定,譬如:预设值是15次,那么学习15次后,无论如何,系统将停止学习。从其工作原理可见,系统的煤种专家系统越丰富、历史数据越多,系统的学习能力越强,效果越好。
如图4所示,“监督学习算法系统”的处理算法数据如下
监督学习算法包括“找差算法”和“微调算法”;
步骤e1:将数据进行“找差算法”处理,找差算法为:
利用“带记忆和裂变的修正k-means算法”数据挖掘技术找到当前三个质心点为c(c1、c2、c3)基准点;“深度学习”找到共性数据有n个,为ci(i=1、2、3…..n)
式中的asse就是找差算法的最终值;
步骤e2:将数据进行“微调算法”处理,“微调算法”为:
假设三个质心点数值的最大值为cmax=max(c1、c2、c3);中间值为cmid=mid(c1、c2、c3);最小值为cmin=min(c1、c2、c3);cmin<=cmid<=cmax,
当前输入的值为cc,其最终值为cf,则微调算法包括如下步骤:
步骤f1:如果cc<cmin,cf=cc+asse;
步骤f2:如果cc>cmax,cf=cc-asse;
步骤f3:如果cmin<=cc<=cmid,cf=cc+asse/2;
步骤f4:如果cmid<=cc<=cmax,cf=cc-asse/2;
cf为整个监督学习算法的输出值。
式中,c对应为发热量(q)、水分(m)、灰分(a)、挥发分(v)、固定碳(fc)和含硫量(s)六种成分的某一成分值便可。
本系统采用“监督类”的深度学习,图示中的“监督学习算法”是基于“共性数据”的相似性分布会趋于统一原理,监督学习算法依次包含两部分:
1用共性数据和参照数据比对,找出共性数据的趋势差异值,该算法简称:找差算法;
2用差异值调整现有数值,该算法简称:微调算法。
- 还没有人留言评论。精彩留言会获得点赞!