基于三维网格划分的隐私保护轨迹数据发布方法与流程
本发明属于数据挖掘技术领域,提供了一种基于三维网格的隐私保护轨迹数据发布方法。
背景技术
随着移动智能终端、定位和存储技术的快速发展,研究人员可以收集和存储大量移动物体的位置和轨迹数据。这些轨迹数据包含丰富的时间和空间信息。收集、挖掘和分析轨迹数据可以支持与移动物体有关的各种应用。例如定位服务、交通监控、城市和道路规划、用户行为分析和旅行推荐等。
轨迹数据表示运动物体的移动路线。大量轨迹数据的发布势必会对用户的隐私和安全构成威胁。例如,结合其他相关背景信息,攻击者通过分析轨迹数据,可以很容易地获得用户的一些隐私信息,如:姓名、性别、单位、家庭住址、爱好、行为模式、社交习惯等,导致用户的切身利益受到伤害。对于一定时间内某个地点的隐私保护问题,目前已经取得了一些研究成果。但是,连续位置信息的轨迹隐私保护方法还有待进一步研究。随着人们对个人隐私信息保护问题的日益关注,隐私保护的轨迹数据发布问题逐渐成为数据挖掘领域的研究热点之一。发布轨迹数据时,数据发布者应确保匿名轨迹数据不会泄露个人隐私信息,同时保持高可用性以进行准确地分析。因此,如何在不破坏数据可用性的前提下有效保护运动物体的轨迹隐私已成为轨迹数据发布中需要迫切解决的问题,即本发明关注的研究问题。
轨迹隐私保护能力和轨迹数据的可用性是相互制约的。目前大多数轨迹数据隐私保护发布方法存在不足:一方面,根据访问频率抑制数据、根据时间干扰数据、使用假名交换用户标识符等方法,均未考虑包含在轨迹本身中的信息,所以在匿名过程中信息丢失非常大;另一方面,大多数方法都是基于整条轨迹的处理,忽略了子轨迹之间高度相似的可能性。因此,发布的匿名化轨迹数据集会降低轨迹数据挖掘的质量。
由于泛化方法能够在个人隐私保护和轨迹数据可用性之间取得良好的平衡,因此基于泛化方法的轨迹k-匿名模型得到了广泛的应用,大多数现有的匿名方法直接删除违反特定约束条件的轨迹或位置,很可能造成大量的信息丢失。
技术实现要素:
本发明实施例提供一种基于三维网格的隐私保护轨迹数据发布方法,旨在解决现有的匿名方法直接删除违反特定约束条件的轨迹或位置,造成大量的信息丢失问题。
本发明是这样实现的,一种基于三维网格的隐私保护轨迹数据发布方法,该方法包括如下步骤:
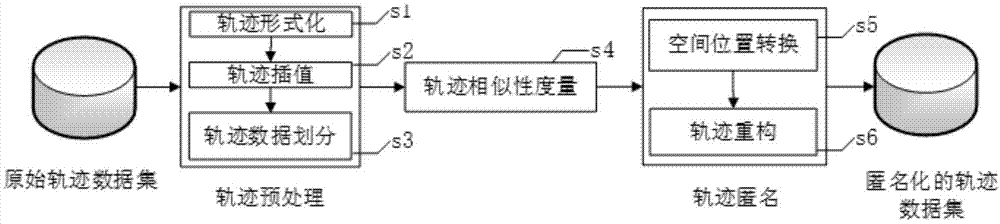
s1、对轨迹数据进行预处理,预处理是指提取轨迹数据的时间及空间位置属性;
s2、基于位置点采样时间对每条轨迹首尾位置点间的缺失位置进行插值;
s3、对轨迹区域进行网格划分,划分为若干个时空单元;
s4、基于各时空单元内子轨迹的时间、方向及空间位置来计算子轨迹间距离;
s5、在距离最近的两条子轨迹上寻找满足约束条件的位置点对,交换位置点对的时间及空间位置,获得匿名子轨迹;
s6、将分布在各时空单元内属于同一轨迹的匿名子轨迹进行重构,获得匿名轨迹数据集。
进一步的,所述时空单元为g×g×g三维单元,g为划分参数,其中,
进一步的,子轨迹ti与子轨迹tj间的距离计算方法包括如下步骤:
s41、识别子轨迹ti及子轨迹tj上的位置点数目;
s42、若子轨迹ti及子轨迹tj都只有一个位置点,则基于公式(2)进行计算:
其中,dist(ti,tj)为子轨迹ti及子轨迹tj间的距离,
若子轨迹ti上只有一个位置点,子轨迹tj上至少有两个位置点,则基于公式(3)进行计算:
其中,dist(ti,tj)为子轨迹ti及子轨迹tj间的距离,st和et分别为子轨迹tj的起始时间和结束时间,
若子轨迹ti及子轨迹tj上均至少有两个位置点,则基于公式(4)进行计算:
dist(ti,tj)=η*disto(ti,tj)+(1-η)*distl(ti,tj)(4)
其中,η为距离权值,设置为0.5,dist0(ti,tj)是轨迹方向距离,为两条子轨迹中重叠时间内所有轨迹段方向距离的平均值,distl(ti,tj)是轨迹位置距离,为轨迹中所有轨迹段位置距离的平均值,其中,dist0(ti,tj)的计算公式如(5)所示:
其中,
distl(ti,tj)的计算公式如(6)所示:
其中,当子轨迹ti和子轨迹tj之间存在共同周期,则令pt=100*min(ratio1,ratio2),ratio1是ti和tj重叠时长与ti时长的比值,ratio2是ti和tj重叠时长与tj时长的比值,若子轨迹ti和子轨迹tj不是同时段轨迹,则令pt=0,σr表示四个时空位置
进一步的,步骤s5中的约束条件为:时间差小于或等于时间阈值θt,且空间距离小于或等于距离阈值θd。
本发明提供的隐私轨迹数据发布方法如下三个功能:第一个是针对时空轨迹数据集进行三维网格划分,提出了一种新的有效的轨迹分割方法,该方法保留了轨迹数据的潜在特征,有利于轨迹相似性评估和轨迹匿名化;第二个是基于不同场景的轨迹相似性测量,分析了三种不同的轨迹分布情况,提出了一种综合轨迹距离计算方法,用于度量任意两条轨迹之间的相似度;第三个是对相似性高的位置点对进行时间交换及位置交换,获得匿名轨迹,实现轨迹匿名化,在保护用户隐私信息的同时,有效地提高了轨迹发布数据的可用性。
附图说明
图1为本发明实施例提供的基于三维网格划分的隐私保护轨迹数据发布方法的流程图;
图2为本发明实施例提供的时空单元内子轨迹间时空关系的三种场景示意图;
图3(a)为本发明实施例提供的tppg算法在两个数据集synds和realds上运行的avgll值随θd变化的结果示意图;
图3(b)为本发明实施例提供的tppg算法在两个数据集synds和realds上运行的avgll值随θt变化的结果示意图;
图4(a)为本发明实施例提供的tppg算法在两个数据集synds和realds上运行的
图4(b)为本发明实施例提供的tppg算法在两个数据集synds和realds上运行的
图5(a)为本发明实施例提供的tppg算法在两个数据集synds和realds上运行的tl值随θd变化结果示意图;
图5(b)为本发明实施例提供的tppg算法在两个数据集synds和realds上运行的tl值随θt变化结果示意图;
图6(a)为本发明实施例提供的tppg算法在两个数据集synds和realds上运行的til值随θd变化结果示意图;
图6(b)为本发明实施例提供的tppg算法在两个数据集synds和realds上运行的til值随θt变化结果示意图;
图7(a)为本发明实施例提供的tppg算法在两个数据集synds和realds上运行的araoi值随θd变化结果示意图;
图7(b)为本发明实施例提供的tppg算法在两个数据集synds和realds上运行的araoi值随θt变化结果示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
图1为本发明实施例提供的基于三维网格划分的隐私保护轨迹数据发布方法的流程图,该方法包括如下步骤:
s1、对轨迹数据进行预处理,预处理是指提取轨迹数据中的时间及空间位置属性;
对原始轨迹数据集进行形式化预处理,提取轨迹数据的时间及空间位置属性,生成如下形式的轨迹:
t={tid,(t1,x1,y1),(t2,x2,y2),…,(tn,xn,yn)}(1)
其中,tid表示轨迹的序号,(ti,xi,yi)(1≤i≤n)表示第i个位置点的时间和空间位置属性三元组(也称为位置点),n是轨迹中位置点的个数。
设ts是所有形如t的轨迹构成的集合,可表示为:ts={t1,t2,…,tp},|ts|指的是ts中轨迹的条数,即|ts|=p。
s2、基于位置点采样时间对每条轨迹首尾位置点间的缺失位置进行插值;
记录轨迹数据集的所有位置点采样时间,对每条轨迹首尾位置点之间的缺失位置点进行插值,使得每条轨迹首尾位置点之间的时刻具有连续性。
s3、对轨迹区域进行网格划分,划分为s个时空单元,其中s为正整数;
对轨迹区域进行网格划分,划分为s个时空单元,所有轨迹数据都分布在这些时空单元中,每个时空单元中可能有零条或多条子轨迹。时空单元为g×g×g三维单元,其中,g是划分参数,
s4、采用轨迹相似性度量方法计算每个时空单元内子轨迹间的距离,即基于各时空单元内子轨迹的时间、方向及空间位置来计算子轨迹间距离;
在每个时空单元内部,基于子轨迹的时间、方向及空间位置特征来评估时空单元内两子轨迹间的相似度,通过两子轨迹间的距离来表征两子轨迹间的相似度,距离越近的两子轨迹相似度越高,如图2所示,子轨迹ti及子轨迹tj为时空单元内部的两子轨迹,子轨迹ti和子轨迹tj的时空关系有三种情况,两条子轨迹ti、tj间距离计算取决于其所处的具体情况:
第一种情况:子轨迹ti、tj都只有一个位置点;
距离是根据欧几里得距离计算的,对应于图2(a)及图2(b),计算公式如下:
其中,
第二种情况:子轨迹ti只有一个位置点,子轨迹tj至少有两个位置点。
计算由子轨迹ti位置点与子轨迹tj中每对相邻两位置点组成三角形的面积,根据三角形的面积计算距离,不失一般性,我们假设子轨迹ti只包含一个位置点
st和et分别为子轨迹tj的起始时间和结束时间,σtr为三个位置点
第三种情况:子轨迹ti及子轨迹tj均至少有两个位置点。
如图2(e)-(f)所示,在子轨迹ti及子轨迹tj中至少有两个位置,若子轨迹ti和子轨迹tj之间存在共同周期,令pt>0,pt=100*min(ratio1,ratio2),ratio1是ti和tj重叠时长与ti时长的比值,ratio2是ti和tj重叠时长与tj时长的比值,如图2(e)所示,子轨迹ti和子轨迹tj中存在共同周期t2~t3,若子轨迹ti和子轨迹tj不是同时段轨迹,即子轨迹ti和子轨迹tj之间不存在共同周期,令pt=0,如图2(f)所示,距离计算公式如(4)所示:
dist(ti,tj)=η*disto(ti,tj)+(1-η)*distl(ti,tj)(4)
其中,η为距离权值,设置为0.5,dist0(ti,tj)是轨迹方向距离,为两条子轨迹中重叠时间内所有轨迹段方向距离的平均值,distl(ti,tj)是轨迹位置距离,为轨迹中所有轨迹段位置距离的平均值,其中,dist0(ti,tj)的计算公式如(5)所示:
其中,
distl(ti,tj)的计算公式如(6)所示:
其中,σr表示四个时空位置
s5、在距离最近的两条子轨迹上寻找满足约束条件的位置点对,交换位置点对的时间及位置,获得匿名子轨迹;
对于两条距离最近的子轨迹,寻找时间差小于或等于θt,且空间距离小于或等于θd的位置点对,然后对满足时间阈值θt和距离阈值θd约束条件的位置点对进行时间交换及位置交换。
s6、将分布在不同时空单元内属于同一轨迹的子轨迹进行重构,获得匿名的轨迹数据集,该匿名轨迹数据集是基于实际数据形成的。
本发明提供的隐私轨迹数据发布方法如下三个功能:第一个是针对时空轨迹数据集进行三维网格划分,提出了一种新的有效的轨迹分割方法,该方法保留了轨迹数据的潜在特征,有利于轨迹相似性评估和轨迹匿名化;第二个是基于不同场景的轨迹相似性测量,分析了三种不同的轨迹分布情况,提出了一种综合轨迹距离计算方法,用于度量任意两条轨迹之间的相似度;第三个是对相似性高的位置点对进行时间交换及位置交换,获得匿名轨迹,实现轨迹匿名化,在保护用户隐私信息的同时,有效地提高了轨迹发布数据的可用性。
该方法适用于具有时间属性和空间位置属性的时空轨迹数据集,理论分析与实验结果均表明,本发明是能够有效地保护轨迹数据的隐私性,并提高匿名轨迹数据集的准确性和可用性。
为了说明效果,本发明的具体实施例,列举了在2个数据集上评价提出方法的有效性。数据来源1是用brinkhoff生成器生成的基于德国奥登堡市的合成轨迹数据集synds,具体包括1005条合成轨迹、45727个时空位置;数据来源2是取自美国三藩市真实出租车移动轨迹数据集realds,具体包括2008年5月25日12:04到5月26日12:04之间的500辆出租车的运行轨迹,包括480条真实轨迹,平均每条轨迹含有244个时空位置。本发明的实验中抽取轨迹位置点的时间、纬度、经度三个属性。
图3(a)给出了本发明所描述方法基于数据集synds和realds的avgll值随θd变化的结果示意图,图3(b)给出了本发明所描述方法基于数据集synds和realds的avgll值随θt变化的结果示意图,avgll是匿名轨迹数据集的平均位置损失结果,每条轨迹的位置损失是指匿名轨迹和原始轨迹在同一时间不同位置的数量与原始轨迹中原始位置数量的比率,如3(a)所示,随着θd的变化,对于synds数据集来说,avgll值范围从10%到38%,对于realds数据集来说,avgll值范围从8%到11%。在图3(b)中,随着θt的变化,对于synds数据集来说,avgll值大约保持在21.8%,对于realds数据集来说,avgll值范围从13%到14%。总的趋势是,θd的值越大,平均位置损失就越高。因为θd是距离阈值,所以当它越来越大时,满足交换条件的子轨迹的数量将会更大,然后平均位置损失会更大。这与avgll和时间阈值θt(单位:秒)的关系是相同的。另外,在两个数据集上运行的结果之间的巨大差异取决于数据集的长度,synds的长度大约是realds长度的两倍。与其他两个算法gc_dm和mdav的结果(约99.8%)相比,本发明所描述方法的平均位置损失率要小得多。
图4(a)给出了本发明所描述方法基于数据集synds和realds的
图5(a)给出了本发明所描述方法基于数据集synds和realds的tl值随θd变化的结果示意图,图5(b)给出了本发明所描述方法基于数据集synds和realds的tl值随θt变化的结果示意图,tl值是指删除的轨迹条数与原始轨迹条数的比值。如图5(a)所示,随着θd的变化,对于synds数据集来说,tl值范围从1.9%到2.2%,对于realds数据集来说,tl值大约保持在0.2%。在图5(b)中,随着时间阈值θt(单位:秒)的变化,对于synds数据集来说,tl值大约保持在2%,对于realds数据集来说,tl值大约保持在0.2%。与其他两个算法gc_dm和mdav的结果(55%到100%)相比,本发明所描述方法的轨迹损失率要低得多。
图6(a)给出了本发明所描述方法基于数据集synds和realds的til值随θd变化的结果示意图,图6(b)给出了本发明所描述方法基于数据集synds和realds的til值随θt变化的结果示意图,til值是指将匿名轨迹与原始轨迹进行比较而导致的一些错误。通过比较原始轨迹数据集ts与匿名数据集ts*,计算时空信息损失以获得信息失真度。如图6(a)所示,随着时间阈值θd(单位:秒)的变化,对于synds数据集来说,til值范围从0.5×106到6.5×106,对于realds数据集来说,til值范围从0.5×106到1×106。在图6(b)中,随着θt的变化,对于synds数据集来说,til值大约保持在2.4×106,对于realds数据集来说,til值大约保持在0.4×106。与其他两个算法gc_dm和mdav的结果(0.1×107到2.8×107)相比,本发明所描述方法的位置错误值要小得多。
图7(a)给出了本发明所描述方法基于数据集synds和realds的araoi值随θd变化结果示意图,图7(b)给出了本发明所描述方法基于数据集synds和realds的araoi值随θt变化结果示意图,araoi是指aoi查询度量的准确率,是基于相同的检索机制估计在匿名数据集中正确检索的aoi数量的比率,其中aoi指的是点密度高于指定阈值的区域。aoi是一项统计结果,可用于许多应用,包括个性化推荐和路径规划。为了测量araoi,将匿名轨迹数据集上的检索结果与原始数据集上的检索结果进行比较。如图7(a)所示,随着θd的变化,对于synds数据集来说,araoi值保持在100%,对于realds数据集来说,araoi值保持90%。在图7(b)中,随着时间阈值θt(单位:秒)的变化,araoi取值情况与图7(a)相同。与其他两个算法gc_dm和mdav的结果(不超过50%)相比,本发明所描述方法的aoi查询度量准确率要高得多。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!