一种针对职业教育动态的分析方法与流程
本发明属于文本可视化领域,涉及一种对文本数据集进行统计分析的方法。给定一个文档集合,通过数据挖掘的技术,将文档量化,然后挖掘出有利于用户的信息,然后通过可视化的技术,将通过人眼很难去浏览的足量的数据可视的展示出来,从而发现在结果中潜藏的某种规律。
背景技术
职业教育在我们的教育体系中占有很大的比重,自“十一五”规划纲要实施以来,在中央和各地的关注推动下,我国对职业教育越来越重视,职业教育体系不断完善,办学模式不断创新,招生规模和毕业生就业率再上新台阶。随着职业教育受重视的程度越来越高,国家发放的关于职业教育的相关文件也越来越多,对于很多关注职业教育的人,尤其是从事职业教育相关的商业活动的人来说,得知国家下发的这些文件的具体内容就具有很大的意义,然而全部阅读这些文件意味着耗费大量的时间和精力,这时候就需要一个方法,能够帮助他们提取这些文件的主要内容,辅助他们的决策,而这属于数据挖掘技术。
现在,随着互联网的发展,数据挖掘技术日趋成熟,而其中,针对文本的数据挖掘技术占有很大的比重。文本在我们能获得的数据中占有很大的比例,在图片和视频还没有足够好的处理方法之前,文本便是我们唯一的数据源。而文本处理有很大的难度,我们使用的大多数文本都是人所创造的,而人所使用的自然语言的处理本身就是一个很大的难题,因为人在创造文本的时候,自然不会考虑到机器是否能识别这段文本。现在通用的做法便是将文本转化为向量,通过向量的计算得到一些我们想要的结果。
大量的文本,我们根本没有时间和精力去人工进行处理,或者,需要付出比较大的代价才能做到,所以我们需要在其中提取出隐藏的内容。但是,即使我们提取出文本的主干内容,其实也有很大的文字量,因此,最佳的方式便是与可视化技术相结合。文本可视化便是完成这一目的的绝佳途径。
技术实现要素:
为了能够更好的帮助用户理解职业教育相关文件的内容,并从中找出足够影响决策的规律,本发明针对职业教育相关文件,将其向量化,并提供了一种可视化的方法,来分析这些年的文件,帮助用户更快更方便的理解职业教育相关的内容。本发明的技术方案如下:
一种针对职业教育动态的分析方法,包括下列步骤:
(1)爬虫得到国家发放的有关于职业教育相关文件的原始文件
(2)文本向量化
采用tf-idf算法将原始文件的文本转化为向量;
(3)文本聚类
使用无监督学习中的分类方法,将向量化的文本进行聚类,将其聚为三类:一类是举办的活动,一类是政府的正式通知,一类算工作报告以及未来计划;
(4)可视化
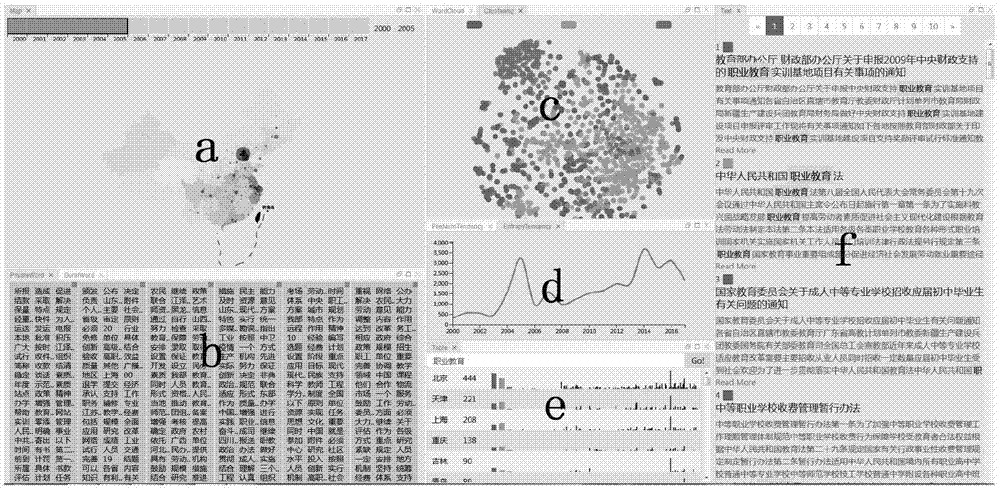
可视化一共包括a,b,c,d,e,f6个部分,其中b,c,d三个部分都有两个视图,整体一共由9个视图构成:
a部分显示的是各个省市中,相关文件的数量随着年份的变化趋势,绘制地图,然后统计每一年各个地区的文件数量,文件数量的多少则用一个黑色半透明圆表示,根据上面滑动框覆盖的年份范围,将滑动框包含的年份的文件数量相加,分布在地图上,可以让用户直接根据地理位置来定位;
b部分是一个词列表,显示的是不同年份中重要性比较靠前的词,a,b部分是彼此关联的,a部分中有一滑动框,代表着年份;b部分则是多个词列表,一个列表代表一年,a部分的滑动框所在的年份和b部分的词列表是一一对应的,滑动框范围的扩大和缩小,都会在b部分同步反应;b部分中另外一个部分,画出了一个根据时间轴显示突现的视图,用户可以针对时间轴缩放,具体到某一个月甚至星期;
c部分针对内容,利用之前文本聚类的结果,不同的类别赋予不同的颜色,结合散点图的分布来研究分类的结果,另外一个视图使用的是词云,对词的重要性进行排序,重要性的数值和词云中词的大小是成正比的;
d部分是两个曲线图,横轴都是年份,纵轴一个是很简单的数量统计,另外一个则是熵值,每一年中,针对每个文本计算熵值,然后取熵值的平均值,熵值越高,文本混乱程度越大,换句话说,文本内容越复杂;
e部分提供搜索功能,用户可以在文本框自行输入感兴趣的内容,根据搜索的内容会在下面显示不同省份包含的文件中和包含搜索话题的文件数量,每一行中,左边是根据聚类的结果的三种类型,用条形图展示的数量分布,右边显示的对应不同时间的数量分布;
f部分展示的是文本的具体内容,e,f部分也是彼此相连的,在e中的搜索,除了本视图会发生变化外,f部分同样会刷新。
附图说明
图1为总的视图;
图2为a部分示例图;
图3(a)为b部分视图1;
图3(b)为b部分视图2;
图4(a)为c部分视图1;
图4(b)为c部分视图2;
图5(a)为d部分视图1;
图5(b)为d部分视图2;
图6为e部分示例图;
图7为f部分示例图;
图8为a,b部分联动示意图;
图9为e,f部分联动示意图;
具体实施方式
本发明针对自2000年起的职业教育相关文件,将其向量化,并提供了一种可视化的方法,来分析这些年的文件,帮助用户更快更方便的理解职业教育相关的内容。本发明是一种基于维度聚类的维度相关性计算方法,可以直接用数值来表示维度间的相关性,然后利用维度间的相关性将维度重新排序,使得相邻之间的维度具有较强的相关性,有利于我们分析高维数据。本发明的技术方案概况如下:
(1)爬虫得到国家发放的有关于职业教育相关文件的原始文件
(2)文本向量化
上述文件皆是原始文本,计算机是无法直接处理自然语言的,需要将其转化为向量,才方便进行处理。我们所采用的是tf-idf算法,tf-idf是一个用以评估一个词对于一个文件集或一个语料库中的其中一份文件的重要程度的方法。词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。其中tf为词频,意味这个词在文档中出现的频率,通过该词个数除以总词数得到。idf称为逆文档频率,用的是总文档数目除以包含这个文档的数目再取对数。文档集合包含的所有词可以构成一个词列表,而每个文档中计算出的tf-idf值和词一一对应,文档中不存在的词自然为0,从而得到向量。
(5)文本聚类
我们想要对得到的文件区分一下类别,但是我们手中并没有一个集合来为我们提供训练,所以我们使用了无监督学习中的分类方法kmeans,将其进行聚类。我们使用的是python的scikit-learn工具中实现的kmeans方法,该方法需要提供一个样本数*特征数的矩阵,之前的文本向量化,便是为此步骤做铺垫。我们通过人眼观测,发现这些文件大致分为了三类,一类是举办的活动,一类是政府的正式通知,一类属于工作报告以及未来计划,因此,我们在聚类的时候,将其聚为三类。
(6)可视化
将得到的内容可视的展示出来,是我们所做的主要工作。我们的可视化工作中一共包括a,b,c,d,e,f6个部分,其中b,c,d三个部分都有两个视图,整体一共由9个视图构成。
a部分显示的是各个省市中,相关文件的数量随着年份的变化趋势。我们使用d3.js绘制了一个地图,然后统计每一年各个地区的文件数量。文件数量的多少则用一个黑色半透明圆表示,根据上面滑动框覆盖的年份范围,将滑动框包含的年份的文件数量相加,分布在地图上。这样可以让用户直接根据地理位置来定位。圆的大小比较很直观,黑色可以确保不会和地图的颜色模糊在一起。
b部分则是一个词列表。显示的是不同年份中重要性比较靠前的词。a,b部分是彼此关联的,a部分中有一滑动框,代表着年份。b部分则是多个词列表,一个列表代表一年,a部分的滑动框所在的年份和b部分的词列表是一一对应的,滑动框范围的扩大和缩小,都会在b部分同步反应,如图8,将滑动框缩小至3年,b部分的词列表也会变为3个。每一年的词都是取的这一年所有文档tf-idf平均值最高的前几十位。b部分中另外一个部分,我们使用d3.js画出了一个根据时间轴显示突现的视图,我们使用python中的burst_detection工具,得到十七年的突现分布。我们利用实现了zoom功能,用户可以针对时间轴缩放,具体到某一个月甚至星期。
c部分针对的则是文件的内容。我们设计用一个散点图来展示所有的文件。利用的是之前文本聚类的结果,不同的类别赋予不同的颜色,所以我们可以结合散点图的分布来研究分类的结果。另外一个视图使用的是词云,实现方法和b部分每一年的词列表类似,也是根据每个词的tf-idf值的平均值,对词的重要性进行排序。不过这次针对的是所有文本。重要性的数值和词云中词的大小是成正比的。
d部分是两个曲线图。横轴都是年份,纵轴一个是很简单的数量统计,另外一个则是熵值。每一年中,针对每个文本计算熵值,然后取熵值的平均值,熵值越高,文本混乱程度越大,换句话说,文本内容越复杂。我们可以和b图中的突显相对照,熵值突然增加的年份,突显也大致符合突然增多增强的规律。
e部分提供了一个搜索功能,用户可以在文本框自行输入感兴趣的内容。根据搜索的内容会在下面显示不同省份包含的文件中和包含搜索话题的文件数量。每一行中,左边是根据聚类的结果的三种类型,用条形图展示的数量分布,右边显示的对应不同时间的数量分布。我们使用了bootstrap来使我们的按钮文本框等更加美观。
f部分展示的是文本的具体内容,e,f部分也是彼此相连的,在e中的搜索,除了本视图会发生变化外,f部分同样会刷新,如图9,我们搜索某关键词,f部分显示具体的文件。为了节省空间,我们使用js将每个文件内容折叠,用户可以自行展开折叠。
图1为总的流程图,具体包括以下步骤:
1.爬虫爬取相关内容
通过python中request和beautifulsoup4工具包,构建爬虫程序,爬取了国家教育部网站http://www.moe.edu.cn/was5/web/search?channelid=255182
中的2000到2017年的所有和职业教育相关的国家发放的文件,作为本发明的统计分析的数据源。
2.向量化
通用的文本处理方法就是将文本转化为方便处理的向量,我所采用的方法是tf-idf,tf-idf英文全称是termfrequency–inversedocumentfrequency,是一种用于资讯检索与资讯探勘的常用加权技术。严格来说,tf-idf是一种统计方法,用以评估一个词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。因此需要tf和idf相乘。tf-idf加权的各种形式常被搜寻引擎应用,作为文件与用户查询之间相关程度的度量或评级。具体计算步骤如下:
(1)先将文本切分为单个的词语
不管是中文还是英文,亦或是其他的语种,想要将其向量化,最初始的步骤都是要分词,将句子拆分为词语,英文的分词相对来说还比较简单,因为英文每个单词就是一个词,但是中文分词就比较复杂了,因为中文是多个字组成一个词。比较好的中文分词工具有jieba,中科院分词系统,smallseg等,我们所用的是python的jieba工具包,将其切分成单个的词语,而不再是句子。
(2)计算这些文档的tf矩阵
分词之后,每个文档相当于由一个词语的列表所构成,要将每个文档转化为词频矩阵。词频(termfrequency,tf)指的是某一个给定的词语在该文件中出现的频率。这个数字是对词数(termcount)的归一化,防止出现同一个词语在长文件里可能会比短文件有更高的词数,而不管该词语重要与否的情况。对于在某一特定文件里的词语ti来说,它的重要性可表示为
以上式子中ni,j是该词ti在文件dj中的出现次数,而分母则是在文件dj中所有字词的出现次数之和。
(3)计算tf-idf矩阵
tf-idf是由tf*idf得到的,所以,我们需要先得到idf
逆向文件频率(inversedocumentfrequency,idf)是一个词语普遍重要性的度量。为了防止某一个词在所有文档中都有很高频率,以及为了凸显出某些在很少的文档中出现,但是很重要的词,我们使用了idf这个计算方式。某一特定词语的idf,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到:
其中,|d|是语料库中的文件总数,分母是包含该词语的文件数目,
得到idf的值之后,计算tf-idf
tfidfi,j=tfi,j×idfi
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的tf-idf。因此,tf-idf倾向于过滤掉常见的词语,保留重要的词语。
3.聚类
由于没有训练样本集,我们采用的是无监督学习的分类算法中的kmeans,使用的是之前得到的tf-idf矩阵,kmeans算法是一种应用很广泛的算法,算法的思想很简单,原理如下
1,选取k个质心
2,计算每一个样本与质心之间的相似度,将样本点归到最相似的类中
3,重新计算每个类的质心
4,重复这样的过程,直到质心不再改变
我们使用的是python中的scikit-learn工具包来进行计算,其中相似度计算方法需要人工选取,我们选用的是余弦相似度
4.可视化
我们一共拥有9个视图,每个视图都有其对应的功能,视图之间彼此相互响应,组合成一套完善的方法来帮助用户分析。
(1)a部分显示的是中国不同地区职业教育受重视程度
主体部分是一个地图,我们使用d3.js显示的是整个中国不同地区职业教育的受重视程度,根据文件涉及到的地区,将其归为省或者市,然后将统计的结果对应到地图上。图中圆的大小,代表相关文件的多少。上面是个滑动框,可以选择想要观察的年份,初始范围是选取了其中的5年,用户可以自行扩大或缩小年份的范围,最小可到一年。
(2)b部分分为两个视图,具体如下
第一个视图是词语列表,和a部分的年份范围相对应,初始范围是5年,便有5个词语列表。每一个词语列表,都是截取的其对应的那一年的所有文件中tf-idf平均值排名最高的那些词;当鼠标选中其中某个词时,该词会添加一个白色的背景色,同时其他年份的词列表中若存在这些词,也会添加白色的背景色。每个列表左上方是全部选择的按钮,会选择该列表全部的词。其他年份存在相同的词时,白色背景色的效果同样会添加。
第二个视图展示了词的突发,我们使用了突发检测(burstdetection)的算法,展示词的突变。突发检测是为了检测一个变量的值在短期内是否有很大的变化。由于针对的是一个时间段,所以同一个词的突现可能并不止一次,算法本身是会为突现区分层级的,该词出现的层级越高,证明其突现的程度越高,视图中横轴代表时间,纵轴代表的便是层级。我们使用d3.js.,使得横轴的时间轴可以伸缩,可以通过将时间轴拉伸,来缩小粒度,初始时刻的粒度是年,可以将其缩小到月,甚至日。每个突现对应的是一个矩形,矩形的宽都是相同的,但是长度不同,对照着下面的时间轴,代表着突现的时间范围。从图中可以明显的看出,05年,07年,17年,这三个年份,突变的数量急剧增加,意味着,国家很可能分别在这三年中,对职业教育给与了足够多的关注,职业教育体系发生了比较多的变革,需要给与重视。
(3)c部分同样由两个视图构成,具体如下:
第一个视图是个词云(wordcloud),对于每个词,根据之前得到的tf-idf矩阵,计算tf-idf的平均值。tf-idf的平均值越高,我们便认为这个词在整个文件集合中,所占的比重越大。tf-idf对应图中词的大小,tf-idf值越大,词的字体越大。
第二个视图是一个散点图,我们在文档向量化的时候,得到了一个tf-idf矩阵,将每个文件转化为了一个多维向量。为了将向量映射到二维平面上,需要使用降维算法,我们选取的是pca,pca全称是主成分分析,实质就是在尽可能代表原来特征的情况下,将原特征进行线性变换,映射至低纬度空间中。
通过降维算法可以将tf-idf矩阵的列全部转化为二维,得到的二维的向量可以作为(x,y)坐标,构造散点图,每个点代表一个文件。我们之前的聚类过程中,将所有的文件分为了三个大类,分别用蓝色,橙色,绿色三种颜色进行区分,根据图中点的分布结果可以看出,绿色的类别和另外两种类别区分明显,蓝色和橙色的类别有些混杂,但是也可以区分开。
当用户在将鼠标悬停在一个点上时,我们设置了响应,可以显示出这个点对应文件的标题。我们可以大致看出,绿色的点所代表的文件,都是一些活动,大致内容是活动的介绍;蓝色的点则是政府官方性质的正式通知,向我们展示了国家对于职业教育的态度;橙色是一些对过去工作的总结以及对未来工作的展望,而且,这些文件大多都可以具体到某个省某个市甚至某个县,或者具体到某位领导。从内容上我们可以看出,活动类和其他两个类别确实区分明显,而通知和工作总结以及未来展望在内容上则有部分重叠的,结果与现实的真实情况是大致相符的。
图中我们在将文本向量化之后,分别计算了不同文件之间的相似度,在散点图中,用户可以点击一个点,我们会从计算结果中选出与其相似度最高的8个文件,为这8个文件所对应的点添加一个黑色的边框,同时改变其他点的透明度,将其虚化。我们通过实际操作可以看出,彼此相似的文件,在图中的距离也极为接近。
(4)d部分同样由两个视图组成,具体如下:
第一个视图是个统计结果,我们统计了每年的文件数目,然后用一个曲线图将其展示出来,可以看出05年和16年有两个激增。对应到之前的a部分和b部分,可以发现,a部分中的黑色圆数量,大小都有明显的变多变大;b部分中05年的突现也是激增,但是16年的突现并不多,到17年才开始出现大量的突现,说明16年是在重复之前的工作,17年才开始出现新的思想。
第二个视图则不同于之前的视图,是个计算结果,我们计算了每一年的熵值,用曲线图展示出来。熵这个概念是从热力学中借鉴过来的一个概念。定义为:
描述的是混乱程度,反映的是内容的随机性。我们利用的是之前得到的词频矩阵。因为词频矩阵中每一行都代表一个文件,所有词的词频相加之和等于1。和熵的概率p相符合。我们将所有词的列表作为整体集合x,每个词作为集合中的元素x,词的词频可以作为p(x),从而计算一个文件的熵。然后再将每年所有文件的熵求平均值,作为这一年的文件的熵值
(5)e部分和f部分是相连的,是一个搜过功能,在搜索框中输入想要搜索的内容,e部分和f部分会同时相应,我们使用bootstrap框架来完成这个功能。
e部分会展示一个城市的列表:每一行最前面是城市名称;后面的数字则是包含搜索内容的文件数目;再后面是蓝,橙,绿三种颜色的矩形,这是对应于之前的聚类结果的,显示的是这一行对应的城市相关的文件中,三种类别的分布。再之后则是一个矩形图,显示的是不同的时间,文件的数量。
f部分也是响应e部分的搜索,显示的是包含搜索内容的所有文件。每个文件中搜索的内容会添加一个橙色的背景,同时,标号前面的小正方形则是根据聚类结果显示的蓝,橙,绿中的一个,代表这个文件所属的类别。每一页显示50个文件,超过50个,则显示分页。为了节省空间,每个文件初始时刻只显示7到8行,用户可以通过点击readmore来显示全部的文件。再通过close来重新折叠。
- 还没有人留言评论。精彩留言会获得点赞!