基于深度相机的三维场景实时重建方法与流程
本发明涉及三维重建技术领域,特别是涉及一种基于深度相机的三维场景实时重建方法。
背景技术
三维重建技术是指捕捉真实物体的形状和外观,建立相应的数学模型,并在计算机中对其进行处理、操作和分析。在计算机图形学和计算机视觉领域中,三维重建技术是解决三维建模问题常用的手段,对于3d真实感建模和大规模复杂场景建模有着非常重要的现实意义。随着计算机硬件和深度数据采集设备的不断更新和发展,三维重建技术在电影、游戏、辅助医疗、城市规划等领域中得到了广泛而深入的应用。
根据数据的获取方式,三维建模技术可分为接触式和非接触式两大类。
接触式:接触式是利用专业设备直接测量目标对象的三维数据。虽然该方法获得的三维数据比较准确,但由于在测量过程中需要接触被测物体,可能对被测物体造成损伤,所以应用范围受到限制。
非接触式:非接触式是在测量时不需要接触被测量的物体,而是通过光、声音、磁场等物理媒介来间接获取目标对象的三维数据。根据是否主动发射能量用于传感,非接触式扫描又分为被动式与主动式两类方法。其中,被动式扫描方法在传感的过程中一般不主动发射能量,相机根据环境自然光的反射,获取目标对象的图像,然后计算得到目标物体的三维空间信息。被动式建模方法设备成本低,在扫描的过程中无需特殊硬件的支持,可用于较大规模场景的三维重建。然而被动式扫描方法存在着明显的缺陷,对物体表面光照纹理条件有严格要求。主动式扫描方法将光源或能量源发射至目标物体表面,根据主动能量投射过程时间和空间的转换规律来计算出三维信息。常见的主动能量有激光、声波、电磁波等。主动式建模方法设备成本比较昂贵,而且操作复杂。
微软发布了一款深度相机kinect,引起了研究者们的广泛关注。同传统的三维扫描设备相比,kinect具有结构小巧、易于操作、价格低廉的优势,而且能实时地同步采集物体表面的深度与彩色信息。由于kinect具有主动发射近红外光的功能,所以在采集数据的过程中不易受被测物体表面光照和纹理变化的影响。kinect的问世引发了计算机图形学、计算机视觉等领域的技术变革,为可视化研究提供了一种全新的手段,目前在人机交互、虚拟现实等领域得到了广泛而深入的应用。
kinectfusion算法中通过邻近的两点交叉相乘估计顶点的向量,这样的方法存在不精确性。结合点云分布的特性,通过分析样本顶点和相邻的四个采样点组成的点集的协方差,估计顶点的向量以提高向量估计的精确性;点云的配准过程中,每组对应点在求解变换参数过程中具有不同的贡献度,kinectfusion算法在求解过程中对这些贡献度不同的点采取相同的处理,可能造成次优的结果。通过对符合条件的匹配点对赋予不同的确信度,以提高相机姿态追踪的稳定性;在kinectfusion中当前时刻和前一时刻的体素中存储的权重系数是相同的,因为当前时刻的数据需要尽快被集成到前一时刻模型,这样可以更快速、更准确地响应场景中的动态变化。但是当相机在相同的位置停留的时间过长时,上述的tsdf值更新方法就显得不稳定了。通过对当前时刻的tsdf值赋予权重1,这样可以确保,只有接收到重要的深度数据时,体素中存储的值才会被更新,而不会收到噪声的影响,因此经过点云融合之后的立方体体素中存储的数据才会更加平滑和准确。kinectfusion中存在的不足,是本发明所要解决的问题。
技术实现要素:
本发明所要解决的技术问题是提供一种基于深度相机的三维场景实时重建方法,能够产生高质量、可视化强的三维模型。
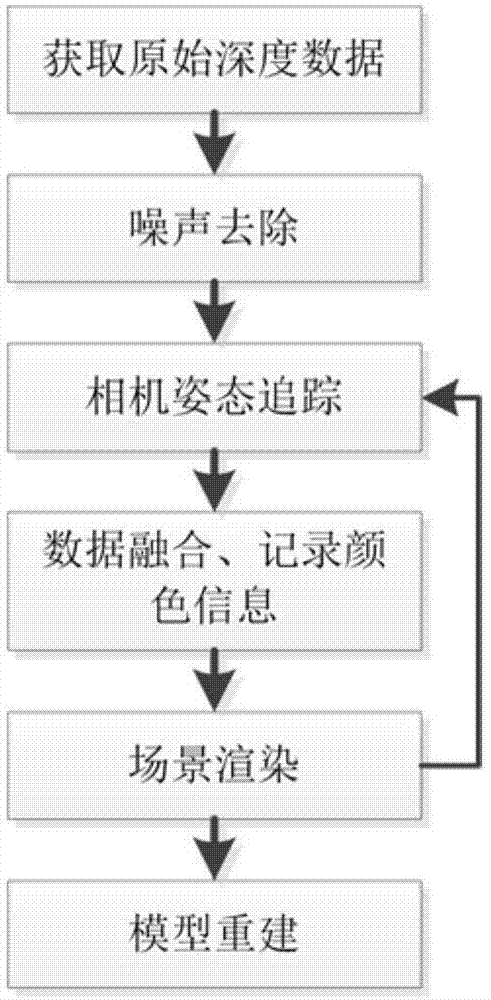
为解决上述技术问题,本发明采用的一个技术方案是:提供一种基于深度相机的三维场景实时重建方法,包括以下步骤:
s1、根据实验的需求,编译与深度相机相兼容的函数库,设置实验系统环境变量;
s2、移动深度相机,从不同的视角对同一场景进行测量,获取多帧连续的深度数据,并对深度数据进行去噪处理;
s3、将不同坐标系中的经过去噪处理的深度图像转换到统一的世界坐标中,获得三维点云模型;
s4、通过计算六个方向自由度的刚体变换矩阵,将当前点云数据与已有的参考点云模型对齐,输出连续两帧之间的相对变换参数,并初始化为下一帧对齐时相机姿态;
s5、经过配准之后,对重叠区域的重复点云数据进行融合处理,简化点云,并融合颜色信息;
s6、实时进行场景渲染,指导用户规划深度相机的运动轨迹;
s7、利用mc算法对点云模型进行三角网格化处理,生成可视化的三维模型。
在本发明一个较佳实施例中,所述步骤s1具体实现步骤包括:
s11、首先安装深度相机设备驱动程序,在此基础上搭建基于深度相机与openni的数据采集模块;
s12、利用cmake对vtk、opencv开源代码进行编译,获得第三方独立函数库,并配置相应的系统环境变量;
s13、安装eigen库和cuda,并配置相应的系统环境变量。
在本发明一个较佳实施例中,所述步骤s2具体实现步骤包括:
s21、通过usb接口将深度相机连接到计算机上;
s22、手持深度相机,保持距物体预定距离,匀速缓慢移动深度相机来扫描场景,
获取数据流;
s23、利用双边滤波算法对数据进行平滑去噪处理。
进一步的,所述预定距离为0.4—3.5m。
在本发明一个较佳实施例中,所述步骤s3具体实现步骤包括:
s31、将经过去噪处理的二维图像中的每个像素点u透视投影到相机空间中,得到对应的顶点v(u);
s32、将每一帧的深度图像复制到gpu中,利用gpu计算得到相应的全局空间顶点映射vg,i(x,y)。
s33、得到新的深度图的世界坐标系后,系统在gpu上并行地计算每个顶点的法向量。
进一步的,所述步骤s33中法向量具体计算过程包括:
s331、根据kinect点云数据的结构特征,选取点vi(x,y)的4个近邻点,分别为:vi(x+1,y),vi(x-1,y),vi(x,y+1),vi(x,y-1);
s332、计算vi(x,y)的邻域的质心
s333、通过分析点vi及其近邻点,得出三阶协方差矩阵c:
s334、对协方差矩阵c进行特征分解:
s335、特征值λ1对应的特征向量v1即为点vi处切平面的法向量。
在本发明一个较佳实施例中,所述步骤s4具体实现步骤包括:
s41、经过步骤s3坐标变换,将连续帧的点云统一到世界坐标系中,搜寻连续两帧点云之间的重叠区域,选取深度差和法向量夹角满足阈值条件的点对,确定为匹配点对;
s42、根据对应点对,利用基于点面距离的icp算法最小化目标函数,求解最优变换参数topt;
s43、通过topt和参考点云的当前帧相机姿态估计ti,即可求出当前相机对应的位置和朝向信息;
进一步的,所述深度差和法向量阈值分别为0.25和20°。
进一步的,所述步骤s42求解最优变换参数topt的具体过程包括:
s421、为每对匹配点赋予一个相应的确信度wi:
其中,φd(x)是核函数,定义为:
s422、重新定义目标函数:
s423、采用线性最小二乘法求解目标函数。
在本发明一个较佳实施例中,所述步骤s5具体实现步骤包括:
s51、在gpu内存空间中开辟两个分辨率为5123的体空间,分别用于存储点云的空间几何信息和颜色信息;
s52、通过投影方程π求出体素v的中心点在深度图像上对应的像素点u;
s53、利用坐标转换求出深度图像上像素点u在三维空间中的对应点的世界坐标pg;
s54、计算点云体空间的体素v与三维空间中的对应点pg之间的有向距离sdfi;
s55、截断有向距离sdfi到一个规定的取值范围内;
s56、寻找sdfi=0的零交叉点,确定模型表面的位置,同时在颜色体空间的对应位置上记录颜色信息;
s57、更新tsdf值fi(v)avg和权重系数wi(v)。
wi=min(max_weight,wi-1+1)
本发明的有益效果是:
(1)本发明利用单个深度相机扫描场景,获得场景的深度数据流,在计算机上完成对数据的实时处理,并生成相应的三维模型,该方法可以提供低成本、易操作、高质量、具有实时性的三维重建系统,产生高质量、可视化强的三维模型;
(2)本发明优化了顶点向量的计算,为后续计算提供了更精确的向量;
(3)本发明在点云配准过程中,为每对匹配点赋予不同的确信度,对不同的匹配点进行不同的处理以提高相机姿态追踪的稳定性;
(4)本发明优化tsdf权重,对当前时刻的tsdf值赋予权重1,确保只有接收到重要的深度数据时,体素中存储的值才会更新,保证点云融合后更加平滑和准确。
附图说明
图1是本发明基于深度相机的三维场景实时重建方法一较佳实施例的流程图;
图2是深度图像转换过程示意图;
图3为投影数据关联原理图。
具体实施方式
下面结合附图对本发明的较佳实施例进行详细阐述,以使本发明的优点和特征能更易于被本领域技术人员理解,从而对本发明的保护范围做出更为清楚明确的界定。
请参阅图1,本发明实施例包括:
一种基于深度相机的三维场景实时重建方法,包括以下步骤:
s1、根据实验的需求,编译与硬件系统相兼容的函数库,设置系统环境变量;以安装kinect深度相机为例,具体步骤如下:
s11、首先安装kinect设备驱动程序,在此基础上搭建基于kinect+openni的数据采集模块;
s12、用cmake对vtk、opencv开源代码进行编译,获得与实验系统相兼容的第三方独立函数库,并配置相应的系统环境变量:
1、利用cmake分别编译生成vtk.sln和opencv.sln解决方案文件;
2、在vs2010中分别打开vtk.sln和opencv.sln工程文件,在debug和release环境下编译生成解决方案;
3、在系统环境变量中设置函数库的路径;
s13、安装eigen库和cuda,并配置相应的系统环境变量;
s2、移动kinect深度相机,从不同的视角对同一场景进行测量,获取多帧连续的深度数据,并对深度数据进行去噪处理;具体步骤如下:
s21、通过usb接口将kinect深度相机连接到计算机上;
s22、用户手持kinect深度相机,保持距物体0.4米~3.5米的距离,匀速缓慢的移动kinect扫描场景,获取数据流;
s23、利用双边滤波算法对数据进行平滑去噪处理:
1、搜索像素点(i,j)的近邻点;
2、计算图像灰度域权值wr和空间域权值ws:
其中,σs表示高斯滤波器的权系数,σr表示图像灰度差权系数,这两个系数共同决定了双边滤波器的性能。
3、计算滤波后的深度像素值:
其中,i为原始噪声图像,i′为经过平滑去噪处理后的图像,ω表示以像素(i,j)为中心的矩形区域,w(i,j)为滤波器在像素(i,j)处的权值,wp为归一化参数。
s3、将不同坐标系中的经过去噪处理的深度图像转换到统一的世界坐标中,获得三维点云模型;如图2所示,具体步骤如下:
s31、将经过去噪处理的二维图像中的每个像素点u透视投影到相机空间中,得到深度图像对应的顶点v(u):
v(u)=d(u)·k-1[u,1]
其中,k是投影矩阵,(cx,cy)表示图像的中心坐标,fx和fy表示深度相机的焦距。
s32、将每一帧的深度图像复制到gpu(graphicsprocessingunit,图形处理器)中,利用gpu的并行计算能力快速地得到相应的三维空间顶点映射vg,i(x,y):
其中,ti为时刻i的刚体变换矩阵,由上一帧的相机位姿ti-1初始化得到,因为kinect运动过程中前后两帧的运动幅度不大,所以可认为当前帧的相机姿态是由上一帧相机姿态进行微小变动后得到的。刚体变换矩阵描述了世界坐标系中6dof(六个方向自由度)的相机姿态,ti的定义为:
其中,ri是一个3×3的旋转矩阵,ti是一个平移向量。
s33、得到新的深度图的世界坐标系后,系统在gpu上并行地计算每个顶点的法向量,具体步骤如下:
1、根据kinect点云数据的结构特征,搜寻点vi(x,y)的k=4个近邻点vi(x+1,y),vi(x-1,y),vi(x,y+1),vi(x,y-1);计算vi(x,y)的邻域的质心v:
2、通过分析点vi及其近邻点,得出三阶协方差矩阵c:
3、对协方差矩阵c进行特征分解:
4、特征值λ1对应的特征向量v1即为点vi处切平面的法向量。
s4、通过计算六个方向自由度的刚体变换矩阵,将新的点云数据与现有的渲染模型对齐,输出连续两帧之间的相对变换参数,并初始化为下一帧对齐时相机姿态;具体步骤如下:
s41、经过步骤s3坐标变换,将连续帧的点云统一到世界坐标系中,搜寻连续两帧点云之间的重叠区域,确定匹配点对,具体过程如下:
1、采用投影数据关联法将位于世界坐标系下的源点云si和目标点云di投影到相机成像平面上,如图3所示;
2、计算候选匹配点对之间的深度差δd和法向量夹角δθ;
δd=||si-di||
3、选取投影在同一位置且深度差和法向量夹角均满足一定阈值条件的点对作为正确的匹配点对,具体判定条件为:
||si-di||<ε
其中,ε=0.25,θ=20°。当对应点对si和di之间的欧式距离和法向量夹角越大,则该点对是错误匹配点对的概率越大,所以当大于阈值时则认为该匹配点对是错误的匹配点对。
s42、根据对应点对,利用基于点面距离的icp算法最小化目标函数,求解最优变换参数topt,具体步骤如下所示:
1、为每对匹配点赋予一个相应的确信度wi:
其中,φd(x)是核函数,定义为:
2、采用点面距离方差作为目标函数的判断依据,重新定义目标函数:
3、采用线性最小二乘法求解目标函数。
s43、通过topt和参考点云的初始相机姿态ti即可求出当前相机对应的位置和朝向信息。
s5、经过配准之后,对重叠区域的重复点云数据进行融合处理,简化点云,并融合颜色信息,具体步骤如下所示:
s51、在gpu内存空间中开辟两个分辨率为5123的体空间,分别用于存储点云的空间几何信息和颜色信息:
1、在点云体空间中的每个体素存储空间几何信息,用复合变量φ(v)=(f(v),w(v))表示,其中f(v)表示截断距离函数(tsdf)计算出的体素到场景实际表面的相对距离值。tsdf值为正时,表示该体素位于模型表面的外部;tsdf为负时,表示该体素位于模型表面的内部;零交叉处为模型表面真正所在处,即f(v)=0处对应着模型表面的一个点。w(v)为体素v中f(v)值的权重系数;
2、在颜色体空间中,存储着颜色数据cn(p),其中p∈n3是体素在体空间中的三维坐标,cn(p)表示融合了1到n帧的颜色数据集。
s52、在点云体空间中,通过投影方程π求出体素v的中心点在深度图像上对应的像素点u:
s53、利用坐标转换求出深度图像上像素点u在三维空间中的对应点的世界坐标pg;
s54、计算点云体空间的体素v与三维空间中的对应点pg之间的有向距离sdfi:
sdfi=‖v-ti||-‖pg-ti‖
s55、截断有向距离sdfi到一个规定的取值范围内,得到其对应的tsdf值δf:
其中,thr表示预设的截断最大值,thr=0.03。
s56、寻找δf=0的零交叉点,确定模型表面的位置,同时在颜色体空间的对应位置上记录颜色信息;
s57、深度相机在移动过程中会不断的产生新的点云数据,而所有处于深度相机当前视角下的空间体素的tsdf值fi(v)avg和权重系数wi(v)都需要被更新:
wi=min(max_weight,wi-1+1)
s6、实时进行场景渲染,指导用户规划深度相机的运动轨迹;
由于受到物体表面材质和深度相机性能的影响,从不同视角对场景同一区域空间进行深度数据采集时,所得的深度信息会存在不同的误差,在点云融合过程中对深度数据进行加权处理可以有效的消除误差的影响,经过点云融合处理之后三维体素模型中存储的tsdf值会变得更加平滑和准确。
s7、利用mc算法对点云模型进行三角网格化处理,生成可视化的三维模型。
以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!