一种基于bootstrapping的文本相似度计算方法与流程
本发明涉及一种词权重的计算方法,尤其是一种基于bootstrapping的文本相似度计算方法。
背景技术:
在当今的信息互联网时代,大量的文本信息需要经过加工处理才能有效利用。因此,自然语言处理领域不断发展起来。在自然语言处理中将文本分词并用词权重来表示,生成向量空间模型是常见处理方式。目前在词权重的计算方法上已经提出了很多有效的方法,其中使用tfidf作为词权重是最常使用的方法之一。
bootstarpping算法是在统计学的基础上,利用有限的样本进行重复采样的过程。每迭代一次就会产生新的样本,来抽取与初始样本相似的新样本。
词向量是指通过对语料中的分词进行统计,将每个词映射到一个多维的富含上文信息的向量空间中。词向量的维度可以根据具体的任务来设置,便于将文本信息转化为可计算的数值信息,对自然语言处理有着重要的作用。
技术实现要素:
为解决传统的idf仅是从词频上判别分词的权重,而忽视了词汇之间关联的不足,本发明提供一种基于bootstrapping的文本相似度计算方法,用来优化idf词权重以提高文本相似度。
为实现上述目的,本发明采用下述技术方案:
一种基于bootstrapping的文本相似度计算方法,它包括以下步骤:
步骤一,计算词的逆向文档频率作为词权重的初始值;
步骤二,依据逆向文档频率选择初始核心词表;
步骤三,计算文本中词的共现矩阵;
步骤四,根据bootstrapping算法,计算候选词和初始核心词的相关度作为更新权重的系数;
步骤五,根据词向量v、词权重w和词性权值f来计算句向量。
进一步地,步骤一中词权重是用代表文本中的词以一个数值来表示,生成文本的实数值向量。词在文本中越能代表主题,权重越低。
进一步地,步骤四中相关度的计算公式如下:
其中,si是指初始核心词表s中第i个词,rj是指候选词表r中第j个词,f(si,rj)是指初始核心词si和候选词rj的共现频次,f(rj)是指包含候选词rj在文档出现的频次。
进一步地,步骤四中更新权重的系数的计算公式如下:
其中,maxit(si,rj)是指最大的相关度,|s|是指核心词表s中词的个数。
进一步地,步骤四中每迭代一次,更新一次系数,其更新计算公式如下:
其中,j是指第j次迭代,n是指总共迭代的次数,kj(ci)是指第j次迭代中词ci的更新系数。
进一步地,步骤五中句向量的计算公式如下:
其中,dij是指文本di中的第j个词,|di|是指文本di中的词个数,α参数从0到1反复迭代查找最优值。
有益效果:
1.本发明将bootstarpping算法中的相关度用于词权重的更新。
2.本发明将一个候选词w与多个初始核心词s分别计算相关度,将最大值*(最大值-平均值)得到判断是否将该候选词放入新初始核心词表的依据。
3.根据词向量v、词权重w和词性权值f计算句向量。
4.采用本发明的技术方案,可以显著提高短文本的相似度计算。
附图说明
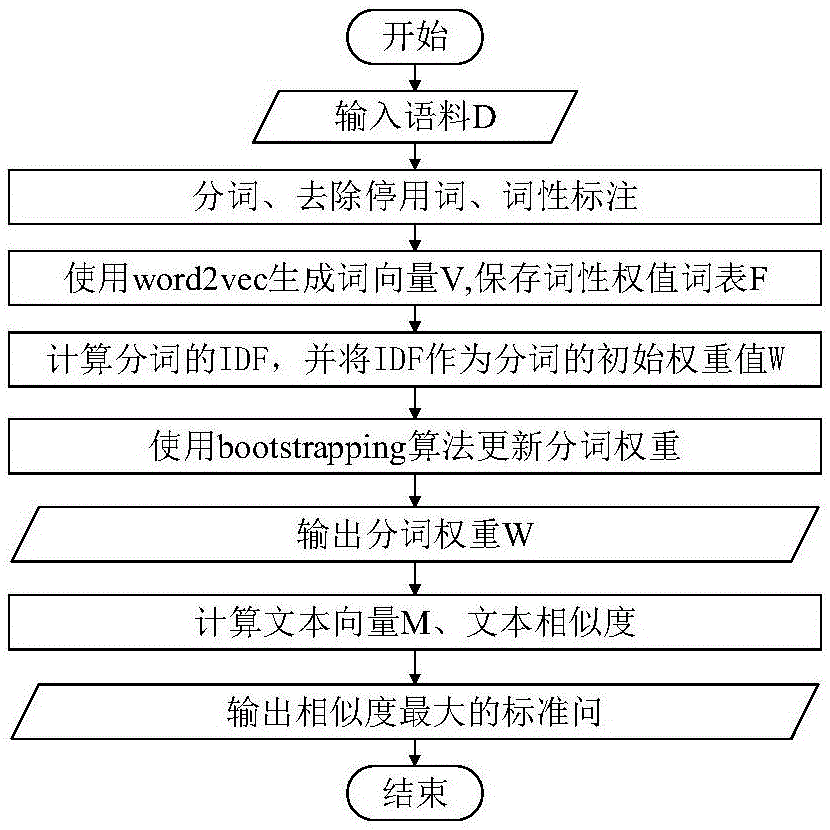
图1是本发明一实施例的文本相似度计算流程图;
图2是本发明一实施例的更新分词权重流程图。
具体实施方式
下面结合附图1、2和实施例对本发明进一步说明。
本实施例将电商平台的客服问答系统中的用户的问题和知识库中的标准问题作为语料库d。
如图1、2所示,将语料库d进行分词、去除停用词和词性标注后,使用word2vec算法生成词向量v并保存。
本实施例中将语料库d中的一条用户问题或者标准问题作为一个文档,计算所有词的逆文档频率,例如计算词ci的逆文档频率idf(ci)公式如下:
其中,|d|是指语料库d的文档总数,|{ci∈d}|是指包含词ci的文档数。选择排名前20的词作为初始核心词表s,从总词表c中去除初始核心词生成候选词表r。初始核心词表s如下表1所示。
表1初始核心词表s
将语料库d中的所有词的逆文档频率作为各自的初始权重值w,使用bootstrapping算法计算相关度t,例如计算初始核心词si和候选词rj的相关度公式如下:
其中,si是指初始核心词表s中第i个词,rj是指候选词表r中第j个词,f(si,rj)是指初始核心词si和候选词rj的共现频次,f(rj)是指包含候选词rj在文档出现的频次。以“发货”和“假期”为候选词,以“我”为初始核心词为例,t(我,发货)=log2(13098)*13098/284020=0.63,t(我,假期)=log2(28)*28/896=0.15。根据相关度阙值p抽取新初始核心词,添加到初始核心词表s中,从候选词表r中剔除,进行下一轮的迭代,直到不再出现新的初始核心词。相关度阙值p的设置取决于相关度t的计算,为了控制每次迭代产生的新初始核心词的数量,p的取值范围控制在[0.8,1]之间。
在迭代过程中,根据候选词rj和每个初始核心词si的相关度t,得到候选词rj权重的更新系数k(rj),更新权重的系数计算公式如下:
其中,maxit(si,rj)是指最大的相关度,|s|是指初始核心词集s中词的个数。以“发货”和“假期”为例,k(发货)=1.878*(1.878-1.218)=1.24,k(假期)=1.167*(1.167-0.992)=0.2。将候选词的更新权重系数k控制在[1,2]的范围内,初始核心词的更新系数默认为2。
使用idf和k更新词权重,例如词ci更新计算公式如下:
其中,j是指第j次迭代,n是指总共迭代的次数,kj(ci)是指第j次迭代中词ci的更新系数。以“发货”和“假期”为例,w(发货)=1/(0.369*1.125*1.011*1.001)/7=0.339,w(请假)=1/(0.112*1.016*1.006*1*0.115)/7=1.235
根据词性以0.1递增,赋值范围控制在[0.2-2],得到的词性权值词表为f,如下表2所示。
表2词性权值词表
计算文本的向量m,使用余弦相似度进行相似度的比较。例如文本di的句向量计算公式如下:
其中,dij是指文本di中的第j个词,|di|是指文本di中的词个数,α参数从0到1反复迭代查找最优值。测试结果如下表3所示:
表3测试结果对比表
使用余弦相似度计算文本向量之间的相似度,相似度最高的标准问作为正确的目标结果。
对本发明保护范围的限制,所属领域技术人员应该明白,在本发明的技术方案的基础上,本领域技术人员不需要付出创造性劳动即可做出的各种修改或变形仍在本发明的保护范围以内。
- 还没有人留言评论。精彩留言会获得点赞!