一种基于深度图像的三维手势识别方法及交互系统与流程
本发明涉及计算机图形学、深度学习和人机交互技术领域,特别涉及一种基于深度图像和深度学习的三维手势识别方法及其交互系统。
背景技术
自然人机交互一直是计算机图形学以及计算机人机交互领域的一个重要研究方向,三维手势识别作为自然人机交互的一个重要组成成分,自然受到了极大的关注。同时,近几年来一些相对成熟的深度摄像头也相继上市,比如微软的kinect,深度摄像头获取的深度图像,避免了传统rgb图像容易受到光照及复杂背景等影响的缺点,给手势识别带了便利。三维手势识别所需要实现的应该不单单是判断出图像中的手属于哪一种手势状态,而是应该将整个手的所有关节点的坐标位置识别出来。然而,因为手部具有高自由度及自遮挡等特性,三维手势识别仍然是一个具有挑战性的问题,所以目前许多手势识别更多的是追踪手的运动轨迹来实现非常简单的人机交互,还有的就是预定好多个手势模板,然后根据传感器得到的特征信息去匹配预定义模板来判断手势,极大地限制了手势识别的自由度和泛化性。
手势识别的方法目前主要有三种:第一,基于传统图形学算法的手势识别,通过各种复杂的图形学算法,识别出手的各个关键点,这类方法不但复杂而且精确度不高;第二,基于手部模型的手势识别,先预定义好手部的3d模型,然后将变换3d模型与图像结果进行匹配,这种方法不但复杂,还需将手部3d模型预先和用户的手部图像相适应;第三,基于数据驱动的手势识别,利用带标签的数据训练深度网络,将图像输入到训练好的网络中,自动检测出手势。其中,第三种方法在手势识别的精度和系统的泛化性上远远优于前两种方法。
技术实现要素:
本发明的主要目的在于克服现有技术的缺点与不足,一种基于深度图像和深度学习的三维手势识别方法,既可以优秀地识别出手部关节点的三维坐标,又可以判断手势语义动作,通过本方法实现的三维手势识别系统,可以应用于在自然人机交互、机械操控和体感游戏等领域,具有广泛的应用前景。
本发明的另一目的在于提供一种基于深度图像和深度学习的三维手势识别交互系统,能广泛应用于各类三维手势识别场景并且达到良好的人机交互目的。
本发明的目的通过以下的技术方案实现:
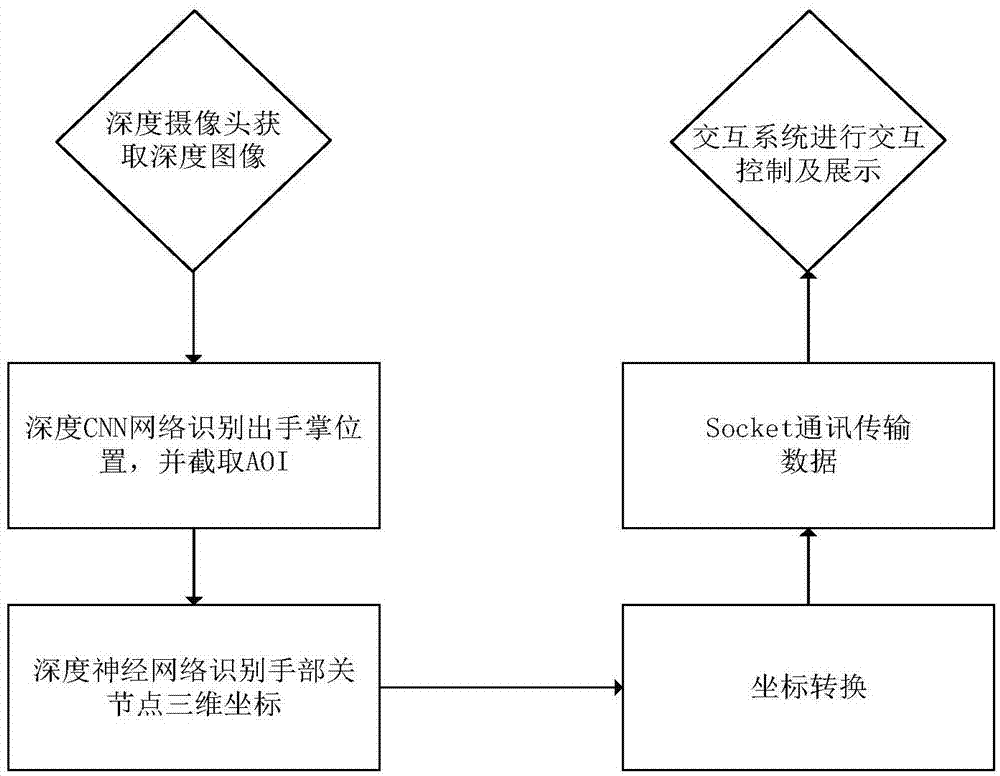
一种基于深度图像的三维手势识别方法,包括以下步骤:
1)使用深度传感器获取深度信息图;
2)数据预处理,对获取的深度信息图利用卷积神经网络,即cnn,识别出aoi,切割出待识别的手部深度信息图;
3)将从cnn中获得的手部深度信息图传入以resnet为基本结构的已经训练好的手势识别网络进行识别,获得识别出的手部关键节点三维坐标;
4)将从网络中识别输出的手部关键节点坐标进行坐标转换,以适应交互系统的世界坐标;
5)利用socket通讯,将变换坐标后的手部关键节点坐标序列传送到交互系统;
6)交互系统获取手部关键节点信息,结合用户设定的语义判断条件,利用其物理引擎展示交互结果。
优选的,在步骤1)中,用户使用深度传感器,包括kinect,获取到深度信息图,电脑端通过openni获取到深度传感器中的深度信息图。
优选的,在步骤2)中,对于从深度传感器获得深度信息图,使用经过训练的cnn网络进行识别手部位置,切割出包含手部的深度信息的aoi。
优选的,在步骤3)中,首先通过对输入的截取有手部深度信息的aoi进行大小变换以适应网络的输入要求;输入的手部深度信息图经网络识别后,会输出一个手部关键节点的三维坐标点序列。
具体的,其中识别网络以resnet为基本结构,在最后加入了自编码层,采用自编码层自动提取特征,去除相关性。
优选的,在步骤4)中,将步骤3)输出的手部关键节点坐标序列通过坐标变换,包括:旋转、平移变换,此步骤中将获得的手部关节点的三维坐标点序列,坐标转换成为交互系统中用户设定的世界坐标系中的坐标点序列。
优选的,在步骤6)中,使用步骤5)发送来的三维坐标点序列,根据关键节点的距离和角度变化,用户可以自行设定变化的阈值,从而可以得到不同的手势语义。
一种上述基于深度图像和深度学习的三维手势识别方法的交互系统,通过3d游戏引擎实现手势的展示以及通过其物理引擎实现与虚拟内容的物理交互。
本发明与现有技术相比,具有如下优点和有益效果:
1、与现有的手势识别方法相比,本发明克服了模板匹配的局限性,能够实现用户自定义的语义。传统的方法是通过对切割出来的手部进行有限几个的识别模型的分类匹配,并且类别个数在网络训练好后无法任意变更,必须加入新的模板数据,并重新训练新的网络,才能扩展手势的语义。而本方法通过识别手部关键节点的坐标而并不是单纯的手势分类,将语义的定制权交给用户,用户可以通过设定对关键节点的变化进行阈值限制,从而触发某种交互效果,丰富了手势识别的用途,使基于本方法的二次开发成为可能。
2、与现有的手势识别方法相比,本发明的识别准确率较高。本发明通过自编码器自动提取特征,另外利用了resnet网络结构,通过深层次的网络学习获得了相对传统方法更多的信息,传统的手势识别方法的误差由于模型较为低效,误差较大,而本发明将误差降到九毫米以内,更为准确。
附图说明
图1为实施例方法的流程图。
图2为利用kinect扫描获得的深度信息图。
图3为进行cnn识别后的裁剪的aoi结果图。
图4为使用网络识别后的结果三维立体图。
图5为使用网络识别后的结果与手部图像的叠加效果图。
图6为识别的手势在交互系统中的交互结果图。
图7为识别的手势在交互系统中的交互结果图。
具体实施方式
下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
实施例1
为了解决手势识别精度不高、模板匹配方法多样性、方法识别结果有限且用户无法修改等问题,本发明基于第三种方法,即训练深度神经网络进行手势识别,先通过深度卷积神经网络检测出手的位置,再通过resnet以及自编码器得出最终的手掌各个关节点的三维坐标,最后通过手势交互系统将整个手掌还原并进行相应的交互动作,从而达到较好的三维手势识别以及交互效果。
如图1所示,本实施例提供的基于深度信息图的手势识别方法及其交互系统,包括以下步骤:
1)使用深度传感器获取深度信息图;
用户在kinect的识别范围内进行手势操作,使用kinect连续获取深度信息图,电脑端通过openni获取深度信息图,openni是一个多语言跨平台的框架,提供一组基于传感器设备的api。深度图是一张单通道图像,每一个像素点的值代表该像素点相对于摄像机的距离,每个像素点的取值范围是12位,也就是最远大概可以表示4米左右的距离,具体图像如图2所示。
2)数据预处理;
对获取的深度信息图利用卷积神经网络(cnn)识别出手部所在的区域,切割出aoi(areaofinterest),切割出待识别的手部深度信息图,截取出来的手部图像aoi结果如图3所示。
3)三维手势识别
首先通过对输入的截取有手部深度信息的aoi进行大小变换以适应网络的输入要求。输入的手部深度信息图经网络识别后,会输出一个手部关键节点的三维坐标点序列。其中,识别网络以resnet为基本结构,在最后加入了自编码层,由于手部关节点之间可能存在着某种关联,因此本方法采用自编码层自动提取特征,去除相关性,从而提高网络训练和识别的准确率和效率,同时使模型更具有泛化的能力。
将aoi手部深度信息图传入以resnet为基本结构的已经训练好的手势识别网络进行识别,获得识别出的手部关节点的三维坐标序列,其中序列长度为48,每三个数字组合成一个手关节点的三维坐标,形如:j1(x,y,z)、j2(x,y,z)、j3(x,y,z)……j16(x,y,z)。将识别的结果通过3d方式展现出来,如图4所示;并将识别结果与手部深度图像叠加展示,如图5所示。
4)坐标转换
将从网络中识别输出的手部关键节点序列进行坐标转换,以适应交互系统的世界坐标;
由于深度传感器传来的世界坐标一般以深度传感器自身为原点,与交互系统的世界坐标定位并不吻合,需要经过一定的旋转、平移变换。此步骤中将获得的手部关节点的三维坐标点序列,坐标转换成为交互系统中用户设定的世界坐标系中的坐标点序列。
5)数据传输
利用socket通讯,将变换坐标后的手部关键节点序列传送到交互系统;
6)交互及展示
使用步骤5)发送来的三维坐标点序列,通过对关键节点的距离和角度变化,用户可以自行设定变化的阈值,从而可以得到不同的手势语义。通过3d游戏引擎如unity,实现手势的展示以及通过其物理引擎实现与虚拟内容的物理交互。
交互系统获取手部关键节点信息,结合用户设定的语义判断条件,利用其物理引擎展示交互结果。在图6中,展示的是虚拟世界中张开的手,对应着现实世界张开的手;在图7中,展示的是将要抓取物体的手,对应着现实世界抓取姿态的手部。
本发明经过实验证明其可行性,能广泛应用于各类三维手势识别场景并且达到良好的人机交互目的。
综上所述,本发明提出的一种基于深度图像的三维手势识别方法及交互系统,既可以优秀地识别出手部关节点的三维坐标,又可以判断手势语义动作。通过本方法实现的三维手势识别系统,可以应用于在自然人机交互、机械操控和体感游戏等领域,具有广泛的应用前景。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!