基于颜色特征增强的没有单一显著残差的协同检测算法的制作方法
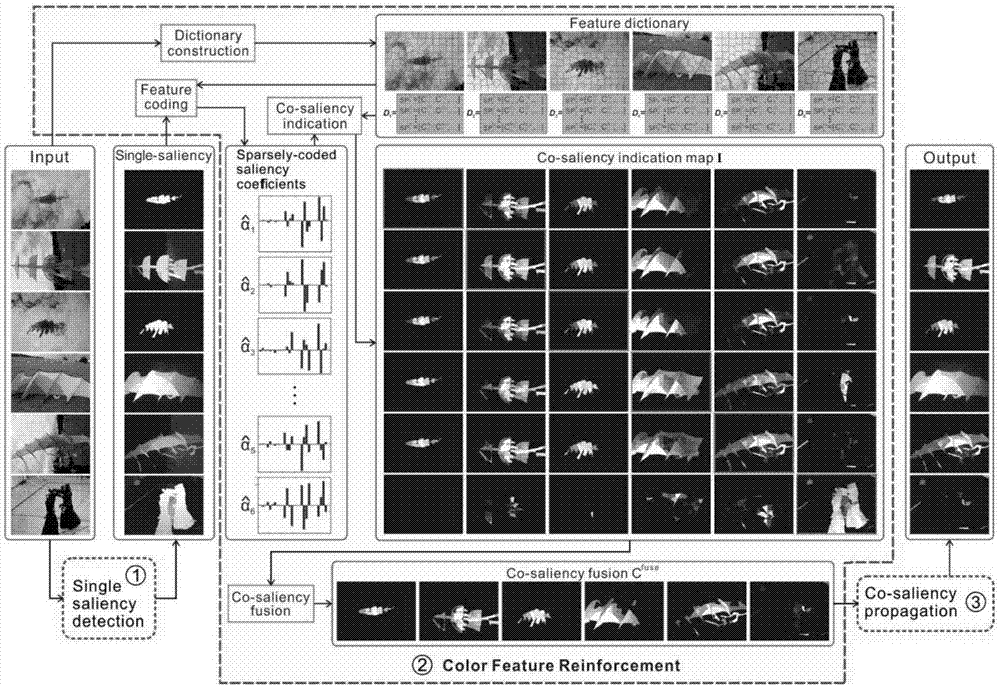
本发明属于计算机视觉领域,涉及一种图像视觉协同显著性检测技术,特别是涉及一种基于颜色特征增强的没有单一显著残差的协同检测算法。
背景技术:
协同显著性检测旨在检测一组图像中共同的显著性对象,那些只在个别图像或小部分图像群体中显着的对象在概念上被视为背景。协同显著性检测在计算机视觉应用中被广泛使用,比如图像协同分割,图像匹配,对象联合识别。
jacobs等人[1]首次提出了协同显著性检测问题;li和ngan[2]将协同显著性检测建模为某种单图像显著性和图像间相似性的显式组合;cheng[3]等人通过最大化图像间相似性和图像内清晰度来识别图像集合中的协同显著性对象;cao[4]计算自适应权重以融合多个单显着图,并使用秩约束来导出协同显著图。
liu[5]等人提出了使用联合fine-scale区域相似度和coarse-scale物体先验进行分层分割来检测协同显著性对象,ye[6]等人提出有效的协同显著对象发现和恢复策略。huang[7]等人提出了一个高斯混合模型来生成协同显著性先验并且通过用这些先验融合各个显著图来得到多幅图像的协同显著性。尽管融合方案多种多样,这种单一图像显著性和图像间相似性的显式组合可能导致协同显著检测中的单一显著残差,即将个别图像或者小部分图像群体中的显著性对象也检测出来。
技术实现要素:
本发明提出一种新的协同显著检测方法,可以有效的消除协同显著检测中的单一显著残差问题。本发明源于这样的观察:在一些丰富的颜色特征空间内,协同显著物体具有相似的颜色分布。技术方案如下:
1.一种基于颜色特征增强的没有单一显著残差的协同检测算法,包括下列步骤:
步骤1:单一显著图的预处理阶段
作为预处理步骤,对于一副输入图像,通过平均两个已有的显著检测器的结果来提取潜在的显著性区域,然后通过流形排序算法优化初始的单一显著图,提取到的图像i的单一显著图表示为si;
步骤2:颜色特征增强
步骤2.1:显著性前景字典的创建
采用具有四个指数,即0.5,1,1.5,2.5,的八种颜色特征,包括rgb,lab,色调,饱和度,来形容这个32维的丰富的颜色特征空间,用图像超像素来表示每一副图像;本发明对每一副图像i使用di表示超像素水平的颜色特征字典矩阵,字典创建包括超像素分割,超像素水平颜色特征提取和转换;
步骤2.2:对步骤2.1提取到的颜色特征进行编码
为保证判别能力以及获得更可靠的特征系数
步骤2.3:协同显著性标示
图像j关于图像i的协同显著程度可以经由显著性前景字典的加强乘积和
步骤2.4:协同显著性融合
应用混合融合策略,依靠多数投票来自适应的选择使用加法还是乘法整合多个协同显著性信息,以结合它们各自的优点,即:若超过一半的输入图像投票的超像素p对其他图像是协同显著的,使用归一化加法来融合协同显著标示信息,相反使用乘法来融合他们;
步骤3:融合后的协同显著图由全局协同显著性传播进行后处理
为提高协同显著前景的完备性,使用元胞自动机扩展模型(cellularautomatapropagation)对融合后的协同显著图进行后处理。
附图说明
图1:协同显著性检测方法框架图
图2:imagepair[17]数据集上不同方法的协同显著性检测结果的四个例子
图3:icoseg[18]数据集上不同方法的协同显著性检测结果的两个例子
图4(a)和(b):分别为两个基准数据集上不同方法的平均pr曲线
具体实施方式
本发明由三个主要步骤组成。首先,作为预处理步骤,我们导出每个输入图像的单一显着图。然后,通过颜色特征增强来进行协同显著预测和协同显著融合。最后,融合后的协同显著图由全局协同显著性传播进行后处理。具体实施方式如下:
步骤1:单一显著图的预处理阶段
作为预处理步骤,对于一副输入图像,通过平均两个先进的显著检测器的结果来提取潜在的显著性区域,使用两个显著检测器的结果的平均可以结合两种方法的优点。然后我们通过流形排序算法优化初始的单一显著图,提取到的图像i的单一显著图表示为si。
步骤2:颜色特征增强
本发明的核心是颜色特征增强,它在一个32维的丰富的颜色特征空间中稀疏的编码每一个输入图像的显著前景,通过显著性前景字典
步骤2.1:显著性前景字典的创建
颜色是人们理解世界的重要线索之一,因此很多显著性检测器或者协同显著性检测器都基于颜色信息得出结论。本发明采用具有四个指数(即0.5,1,1.5,2.5)的八种颜色特征(即rgb,lab,色调,饱和度等)来形容这个32维的丰富的颜色特征空间。为了提高效率,我们用图像超像素来表示每一副图像。本发明对每一副图像i使用di表示超像素水平的颜色特征字典矩阵,其中di的第p行表示超像素p相应的32维颜色特征,表示为
步骤2.2:对步骤2.1提取到的颜色特征进行编码
理想情况下,图像i的单一显著图si可以被表示为si=diαi,其中
其中λ=0.5来控制αi的稀疏性。由以上公式可以看出特征编码实际上是一个稀疏编码问题,复杂度为
步骤2.3:协同显著性标示
本发明使用
其中dj和bin(si)分别是特征字典以及图像j的二进制单一显著性向量。协同显著性标示的时间复杂度是
协同显著性指示图
步骤2.4:协同显著性融合
一般而言,以前的协同显著性检测方法使用加法或者乘法来整合多个协同显著性信息,然而通过一个简单的算术运算不能得到令人满意的协同显著性检测结果。归一化加法不能消除只存在于少数输入图像中的不常见但是显著的物体,乘法往往会丢失存在于多数输入图像中的协同显著前景。相反,我们应用混合融合策略,依靠多数投票来自适应的选择使用加法还是乘法整合多个协同显著性信息,以结合它们各自的优点。具体来说,超过一半的输入图像投票的超像素p对其他图像是协同显著的,我们就使用归一化加法来融合协同显著标示信息,相反我们使用乘法来融合他们。本发明的融合协同显著图由如下公式得到:
其中bin(·)表示得是otsu自适应阈值[8],
步骤3:融合后的协同显著图由全局协同显著性传播进行后处理
为了提高协同显著前景的完备性,本发明使用元胞自动机扩展模型(cellularautomatapropagation)[9]来对我们融合后的协同显著图进行后处理,此方法的有效性已经在单一显著性检测[10]中被证实。
步骤4:显著性融合检测模型的结果测试
对于一组图像经由上述三个步骤的操作,得到协同显著性检测的结果输出。本发明在两个测试基准数据集上和五个先进的协同显著性检测方法进行比较,方法包括cp[2],cb[11],hs[5],codr[6]和mlrf[7],两个基准数据集是imagepair[2]和icoseg[12]。我们在评估中比较了两种形式的结果,包括融合的协同显著图
我们首先展示在imagepair[2]和icoseg[12]数据集上的协同显著性检测结果的几个特例,如图2和图3所示。在所有的比较方法中,cp[2]不能准确的突出显示协同显著性物体也不能很好的抑制背景,因此会生成错误的显著图,比如图2中的第三组和第四组图像。cb[12]的大多数结果是不完整的。hs[5]和codr[6]通常可以检测出协同的显著性前景,但是不能很好的抑制背景。mlrf[7]的结果要稍好一点,但是在其协同显著图中依然可以看到单一显著性残差,如图3所示。与其他方法相比,本发明的协同显著性检测结果在背景中更清晰和完整,并且检测到的协同显著性物体更加均匀的突出。本发明在单一显著性残差方面表现出更好的能力,比如图2中的第二组和第四组图像还有图3所示。与ouri相比,ourf保留了更高的准确性,也有更高的完整性。
图4展示了在两个基准数据集上所有方法的平均pr曲线,我们可以看出cb[12]在两个数据集上表现最差。尽管图4中其他方法的pr曲线比较接近,我们依然可以看出本发明在两个数据集上达到最高的pr曲线。
表1进一步定量分析了本发明的优越性能。可以看出在两个数据集上,ourf具有最高的精确度和f-measure,与codr[6]相比,mlrf[7]在两个数据集上表现一致很好。与mlrf[7]相比,本发明的mae评估值在imagepair[2]和icoseg[12]数据集上分别实现了12.45%和11.11%的相对减少,本发明的f-measure评估值在imagepair[2]和icoseg[12]数据集上分别实现了2.65%和6.36%的提升。此外,我们做了方差分析,以证明我们的结果和最好的竞争对手mlrf[7]的统计学意义。测试统计分别是我们的方法和mlrf[7]的评估结果,即mae评估值和f-measure评估值的差异。具体来说,在两个数据集上mae减少量的p值是0.014<0.05和2.06-5<<0.05,在两个数据集上f-measure提升量的p值是0.0049<0.05和2.36-7<<0.05。由于icoseg[12]数据集包含更具有挑战性的多图像协同显著性检测案例,因此本发明在此数据集上的提升具有更多的意义。同样,除了ourf,ouri在mae评估值和f-measure评估值上也实现了可观的表现。
参考文献
[1]d.jacobs,b.dan,ande.shechtman,“cosaliency:wherepeoplelookwhencomparingimages,”inproc.23rdannu.acmsymp.userinterfacesoftw.technol.,2010,pp.219–228.
[2]h.liandk.n.ngan,“aco-saliencymodelofimagepairs,”ieeetrans.imageprocess.,vol.20,no.12,pp.3365-3375,dec.2011.
[3]m.cheng,n.j.mitra,x.huang,ands.hu,“salientshape:groupsaliencyinimagecollections,”vis.comput.,vol.30,no.4,pp.443-453,2014.
[4]x.cao,z.tao,b.zhang,h.fu,andw.feng,“self-adaptivelyweightedco-saliencydetectionviarankconstraint,”ieeetrans.imageprocess.,vol.23,no.9,pp.4175-4186,sep.2014.
[5]z.liu,w.zou,l.li,l.shen,ando.l.meur,“co-saliencydetectionbasedonhierarchicalsegmentation,”ieeesignalprocess.lett.,vol.21,no.1,pp.88-92,jan.2014.312.
[6]l.ye,z.liu,j.li,w.-l.zhao,andl.shen,“co-saliencydetectionviaco-salientobjectdiscoveryandrecovery,”ieeesignalprocess.lett.,vol.22,no.11,pp.2073-2077,nov.2015.315.
[7]r.huang,w.feng,andj.sun,“saliencyandco-saliencydetectionbylow-rankmultiscalefusion,”inproc.ieeeint.conf.multimediaexpo,2015,pp.1-6.
[8]n.otsu,“athresholdselectionmethodfromgray-levelhistograms,”ieeetrans.syst.,man,cybern.,vol.smc-9,no.1,pp.62-66,jan.1979.
[9]j.vonneumann,“thegeneralandlogicaltheoryofautomata,”cerebralmech.behavior,vol.1,pp.1-41,1951.340.
[10]y.qin,h.lu,y.xu,andh.wang,“saliencydetectionviacellularautomata,”inproc.ieeeconf.comput.vis.patternrecognit.,2015,342pp.110-119.
[11]h.fu,x.cao,andz.tu,“cluster-basedco-saliencydetection,”ieeetrans.imageprocess.,vol.22,no.10,pp.3766-3778,oct.2013.
[12]d.batra,a.kowdle,d.parikh,j.luo,andt.chen,“interactivelyco-segmentatingtopicallyrelatedimageswithintelligentscribbleguidance,”int.j.comput.vis.,vol.93,no.3,pp.273-292,2011.
表1:不同方法在两个基准数据集上的mae,精确度,召回率和f-measure值的比较。
- 还没有人留言评论。精彩留言会获得点赞!