一种基于历史数据的在线社交平台用户兴趣推荐方法与流程
本发明涉及一种在线社交平台用户兴趣推荐方法,具体是一种利用用户发布的历史数据通过数据挖掘技术根据用户兴趣进行分类,利用聚类算法向拥有共同兴趣的用户推荐相关内容的方法。
背景技术:
随着移动网络的快速发展,互联网社交平台获得了长足的发展。在线社交平台用户通过发布文本内容表达个人的观点态度,进而反映其个人兴趣。分析社交平台用户数据,对挖掘社会信息、舆情分析、定制推荐有重要意义。
传统对用户兴趣推荐算法对用户所有文本进行静态分析,对在线社交平台中主题的动态变化不敏感,并且由于社交平台用户文本短小,使传统算法对用户的兴趣预测不不精确。本发明利用主题追踪模型对用户动态兴趣变化进行追踪,挖掘具有类似兴趣的用户群体并进行相关推荐,达到精准营销的目的。
技术实现要素:
本发明目的在于,对于社交平台中用户发布内容的数据集,在时序上进行数据内容的切分,根据用户文本利用主题追踪模型和词对模型对社交平台用户的兴趣进行实时挖掘分析,并根据k-means算法将具有相同兴趣的用户聚类,对同一个兴趣主题下的用户实现定制化的推荐服务。本发明针对目前互联网社交平台用户根据用户兴趣进行定制化推荐提出了一种解决方案。
为解决以上问题,本发明的技术方案是:基于历史数据并采用主题追踪模型技术的在线社交平台用户兴趣推荐方法,包括如下步骤:
1)用户数据预处理阶段:
a获取社交平台中用户发布的所有文本数据;
b指定时间片长度,将用户文本数据按照时间片长度划分为不同文本集合;
c结束;
2)用户兴趣发现阶段:
a对用户文本数据进行词对采样;
b利用btm生成历史时间上的用户兴趣分布;
c根据用户历史兴趣分布和当前时间内文本内容利用主题追踪模型生成用户最新兴趣分布;
d保存当前用户兴趣分布情况作为未来预测的历史数据;
e结束;
3)用户推荐阶段:
a利用k-means聚类算法得到兴趣类似用户群体;
b利用topn推荐算法为同一簇中的兴趣相似用户提供推荐;
c结束。
步骤1)-a中获取用户数据构造过程如下:
1)调用公开社交平台api编写网络爬虫,选择种子用户之后,在抓取种子用户所有文本数据的同时,获取种子用户的所有关注用户,并将其作为新的种子用户进行文本数据获取。
2)对于每一名用户设置唯一的user_id,且每一篇用户发布的文本(包括原创和转发)均记录其发布的时间戳timestamp,最后得到的是具有用户标识user_id和发布时间timestamp的每一条独立文本内容。
3)对文本进行数据预处理,通过hanlp进行分词操作,去除常用词语,并将词语数量小于等于2的文本剔除。
步骤1)-b中时间片长度选择根据数据集大小以一个自然月或一个自然季度为长度进行划分,从基准时间开始用户的文本数据按照时间片划分为不同的文档集合。
步骤2)-a中利用btm模型分析某时间片上用户兴趣情况过程如下:
1)设置社交平台主题数目k,并跟设置方法的参数
2)根据多项分布选取主题z~multi(θ),其中θ满足参数α的狄利克雷分布。
3)从用户文档中采样两个词wi,wj且均满足与主题z的多项分布,将这两个词作为一个词对采样。
4)根据3)中采样中采样结果和1)中设置的参数得到初始时间(即t=0)的用户兴趣分布θ0,u和词语主题分布
步骤2)-b中利用主题追踪模型生成用户最新兴趣分布构造过程如下:
1)获取用户u的前一时间片的兴趣分布θt-1,u和词语主题分布
2)根据当前时间片中新增用户文本设置当前时间的参数
3)根据主题追踪模型,由θt-1,u和αt的狄利克雷分布可以得到当前的用户兴趣分布结果θt,u,并根据
步骤2)-c中对之前得到的分布结果情况θt,u和
步骤3)-a中k-means聚类算法具体过程如下(k为社交平台主题数目):
1)在预测集数据集中随机选取k个数据作为每个类别的初始聚簇中心。
2)根据欧氏公式
3)重复2)直到收敛,收敛函数为
步骤3)-b中为同一簇中的兴趣相似用户提供推荐过程如下:
1)规定在同一个类簇中的用户为当前具有相同兴趣的用户群体,在k(k为社交平台主题数目)个社交平台主题中选择每个用户在其对应主题中的topn词语,其中n为选择的词语总数,预先设定。
2)根据同一类簇中所有用户的topn词语,取其中在主题追踪模型中所属最多的主题,可以得到当前类簇对应的相关主题关键词,对同一类簇中用户进行相关主题的兴趣内容推荐。
本发明的有益效果:本发明是利用数据挖掘技术为网络社交平台用户提供符合其实时兴趣的个性化推荐服务方案,利用动态主题追踪提高对用户的实时兴趣的发现准确性。与传统推荐方法相比,本发明更加准确高效,并具有实现简单、复杂度低的优点。
附图说明
图1为基于用户历史数据的社交平台用户兴趣推荐方法的流程图;
图2为用户数据预处理阶段的流程图;
图3为用户兴趣发现的流程图;
图4为用户推荐的流程图。
具体实施方式
为了更了解本发明的技术内容,特举具体实例并配合附图说明如下。
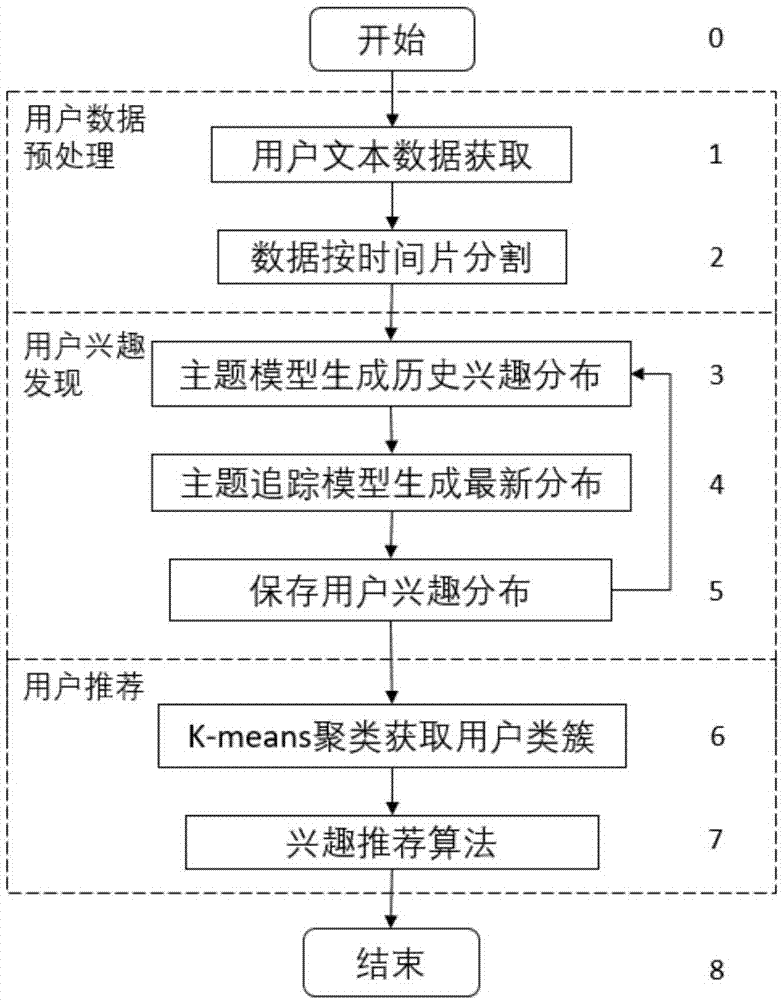
图1是本发明实施例的用于基于历史数据进行社交平台兴趣推荐方法的流程图,包括三个阶段:用户数据预处理、用户兴趣发现、用户推荐。
步骤0为本发明的起始状态;
在用户数据预处理阶段(步骤1-2),步骤1是用户文本数据获取部分,对社交平台中用户发布的文本数据内容进行获取和文本预处理;
步骤2定义社交平台时间片长度,将得到的用户文档数据分别分割为不同时间片中的文档集合;
在用户兴趣发现阶段(步骤3-5),步骤3通过btm主题模型对历史时间片中的用户兴趣根据其在同一时间片下的文档集合内容进行计算挖掘;
步骤4根据步骤3中计算得到的历史时间片的用户兴趣分布情况和当前时间片的用户文档集合内容,通过主题追踪模型对当前用户的兴趣情况进行计算;
步骤5将当前的用户兴趣情况保存,并作为计算未来用户兴趣分布的历史分布数据;
在用户推荐阶段(步骤6-7),步骤6根据在步骤5中计算得到的当前用户兴趣数据,利用k-means算法对拥有相同兴趣分布的用户进行聚类;
步骤7对每一个类簇中的用户通过topn算法计算类中与主题最相关的词语,分析该类簇中用户关注主题,进行相关的定制化推荐;
步骤8是本发明的结束步骤。
图2是对图1中用户数据预处理阶段的具体描述:
步骤1-0是起始步骤;
步骤1-1选择社交平台中一部分用户作为种子用户,用于数据采集和发现其他用户信息;
步骤1-2根据种子用户的关注和被关注,发掘尚未被作为种子的新用户,加入到种子用户中,作为步骤1-1的准备;
步骤1-3对种子用户利用网络爬虫获取其发布的原创与转发本文内容和用户标识user_id、文本发布时间戳timestamp;
步骤1-4对获得的文本内容进行预处理,包括hanlp进行中文分词、去除常见词、剔除词语总数小于3的文本,得到处理完成后的用户文本及其对应user_id、timestamp;
步骤1-5根据数据集合大小和总时间划分时间片长度,通常为一个自然月或季度;
步骤1-6将步骤1-4中获得的用户文本根据其时间戳timestamp在不同时间片下进行划分,得到每个user_id对应于每个时间片中的文本集合;
步骤1-7是结束步骤。
图3是对图1中用户兴趣发现阶段的具体描述:
步骤2-0是起始步骤;
步骤2-1对根据时间由远及近的根据user_id判断的每名用户最远时间片中的文档集合,通过btm模型分析其在初始时间片中的兴趣情况。根据社交平台数据集设置社交平台主题数目k,并跟设置方法的参数
步骤2-2根据步骤2-1中分析得到初始时间片中社交平台中的词语主题分布
步骤2-3根据步骤2-1中分析得到历史时间片中用户u的兴趣分布情况θ0,计算公式为
步骤2-4利用之前计算得到的历史时间t-1中兴趣分布情况加上在当前时间t用户的文本内容通过主题追踪模型计算当前时间t上用户的兴趣分布情况。由θt-1,u和α的狄利克雷分布可以得到当前的用户兴趣分布结果θt,u,并根据
步骤2-5保存在步骤2-4中计算得到的时间t用户的兴趣主题θt,u和词语主题分布
步骤2-6为结束阶段。
图4是对图1中用户推荐阶段的具体描述:
步骤3-0是起始步骤;
步骤3-1从步骤2-5中获得保存计算得到的当前时间片中的用户兴趣θt,u,z;
步骤3-2随机选取k(k为社交平台主题数目)个数据点作为每个类别的初始聚簇中心,其中k预先设定,为聚类簇的个数;
步骤3-3根据欧氏公式
步骤3-4中根据每个类簇中用户兴趣数据集合计算当前类簇中新的中心值;
步骤3-5首先根据收敛函数计算公式
步骤3-6对每一类簇中的每一名用户选择每个用户在其对应主题中的topn词语,其中n为选择的词语总数,预先设定;
步骤3-7根据同一类簇中所有用户的topn词语,取其中在主题追踪模型中所属最多的主题,可以得到当前类簇对应的相关主题关键词,即作为对当前类簇中所有用户进行定制化推荐的依据;
步骤3-8是结束步骤。
综上所述,本发明利用btm和主题追踪模型等数据挖掘方法对在线社交平台用户兴趣的动态变化进行分析,采用k-means算法、topn方法对拥有相同兴趣的用户进行相关主题内容的推荐,能够敏感地对社交平台中主题的实时变化做出反馈,不仅能够准确高效地对用户和社交平台主题兴趣情况进行分析,更能够有针对性地挖掘相同兴趣的用户群体提供适当的定制化推荐服务。
本发明所属技术领域中具有通常知识者,在不脱离本发明的精神和范围内,当可作各种的更动与润饰。因此,本发明的保护范围当视权利要求书所界定者为准。
- 还没有人留言评论。精彩留言会获得点赞!