基于网络社交平台的隐私信息甄别方法与流程
本发明涉及隐私保护技术领域,尤其涉及一种基于网络社交平台的隐私信息甄别方法。
背景技术:
随着社交媒体的兴起,人们逐渐习惯在社交网络上分享个人的想法和经历。然而,用户在享受社交媒体自由表达的同时,也承担了隐私泄露的风险。隐私是指可确认特定个人(或团体)身份或其特征,但个人(或团体)不愿被暴露的敏感信息。用户在社交网络中发布内容时,很可能会不自觉地暴露自身的敏感信息,给个人的生活带来极大的影响和潜在风险。因此,能否利用技术手段对用户发布内容中涉及到的隐私信息进行有效甄别以减少隐私泄露,成为自媒体时代亟待解决的问题。
在现有技术中,隐私信息甄别方法主要包括基于问卷调查的方法和基于机器学习的方法。基于问卷调查的方法是通过专家经验和问卷调查来进行隐私内容的甄别,例如,m.s.ackerman等人用这种方式研究在电子商务领域用户的隐私偏好,g.bansal等人研究人们对健康隐私的保护需求,s.patil等人研究人们对于位置隐私的保护需求,r.kang等人研究不同年龄、职业的用户群体对于隐私属性的认知等。然而,问卷调查的方法存在着很大局限性,一方面,随着用户在社交媒体上发布的内容越来越多,涉及到的隐私信息远远超出了传统隐私列表的范围,另一方面,问卷调查方法存在着调研成本高、调研结果不精确的问题。基于机器学习的方法是通过研究用户的匿名行为来分析用户的隐私需求,并采用机器学习的方法对隐私内容进行自动甄别,其中,匿名行为通常包括对内容可见范围的设置,如设置为仅自己可见或仅好友可见等,ralphgross和alessandroacquisti等人通过分析用户的隐私设置对隐私信息的暴露量以及潜在的风险进行评估。然而,现有的机器学习的方法对隐私内容进行自动甄别时,通常是通过用户匿名行为对实验数据进行隐私性的标注,例如,d.correa等人分别从非匿名网站(如twitter)和匿名网站(如whisper)中收集用户发布的内容,作为隐私分类实验的正负样本,j.-m.xu等人通过研究用户删除的内容来分析他们的隐私偏好,此外,现有的机器学习方法通常仅仅关注文本表层的语义特征,没有对用户发布内容之间的关联性进行更加深入全面的建模和语义理解,从而影响了隐私信息甄别的效果。
综上,随着社交媒体的发展和机器学习在各领域的突破性进展,需要对现有的隐私信息甄别技术进行改进,以提高利用机器学习方法进行信息隐私信息自动甄别的效果,使其更适合于网络社交平台的特点。
技术实现要素:
本发明的目的在于克服上述现有技术的缺陷,提供一种基于网络社交平台的隐私信息甄别方法。
根据本发明的第一方面,提供了一种基于网络社交平台构建隐私信息甄别模型的方法。该方法包括以下步骤:
步骤1:根据网络社交平台上已发布的问题及相关答案之间的结构特征构建由多组分析数据构成的训练样本集,其中,每组分析数据包括问题信息、相关的答案列表信息以及对应的隐私性标签;
步骤2:以所述训练样本集中的问题信息、相关的答案列表信息为输入,以对应的隐私性标签为输出训练深度学习模型,以获得基于所述深度学习模型的隐私信息甄别模型。
在一个实施例中,步骤1包括以下子步骤:
步骤11:获取网络社交平台上多个话题下的问题信息以及相关的答案列表信息;
步骤12:对于所获得的每一问题信息及相关的答案列表信息,根据相关用户的匿名行为确定该问题对应的隐私性标签,以构建所述训练样本集。
在一个实施例中,所述匿名行为包括问题答案匿名率、问题关注匿名率和问题是否匿名提出中的至少一项,所述问题答案匿名率表示一个问题的匿名答案数与全部答案数之比,所述问题关注匿名率表示一个问题的匿名关注者数与全部关注者数之比
在一个实施例中,所述深度学习模型包括答案子网络、问题子网络和分类器,所述问题子网络用于对所述训练样本集中的问题信息进行特征学习,获得问题信息的向量表示q,所述答案子网络用于对所述训练样本集中的答案列表信息进行特征学习,获得答案列表的向量表示a,所述分类器用于对获得的q和a进行隐私信息分类。
在一个实施例中,步骤2中,对于所述训练集中的每一条分析数据执行以下子步骤:
步骤51:将所述训练样本集中的问题信息转换为词向量输入到双向长短时记忆网络进行特征学习,获得问题信息中单词wt的向量表示
步骤52:将向量ht进行平均,获得该问题信息的向量表示q;
步骤53:将该问题信息相关的答案列表信息转换为词向量输入到双向长短时记忆网络进行特征学习,获得该答案列表中每条答案的向量表示at;
步骤54:将每条答案的向量表示at输入到双向长短时记忆网络进行特征学习,获得该答案列表的向量表示a。
在一个实施例中,所述分类器为softmax模型、svm或朴素贝叶斯。
在一个实施例中,所述隐私性标签为属于隐私信息或不属于隐私信息。
根据本发明的第二方面,提供了一种基于网络社交平台的隐私信息甄别方法。该方法包括以下步骤:
步骤81:获取社交网络平台上发布的一个问题信息以及相关答案列表信息;
步骤82:将所述问题信息和相关答案列表信息输入到本发明所构建的隐私信息甄别模型,获得该问题信息是否属于隐私信息的标注。
与现有技术相比,本发明的优点在于:通过分析网络社交平台上用户发布内容的结构特征构建训练样本集,结合问题信息本身和相关答案之间内在逻辑关系和相互作用设计深度学习模型进行训练,获得有效的隐私信息甄别模型,从而对用户在网络社交平台上发布的新内容的隐私性能够进行准确标注,以有效地反映用户的隐私偏好。
附图说明
以下附图仅对本发明作示意性的说明和解释,并不用于限定本发明的范围,其中:
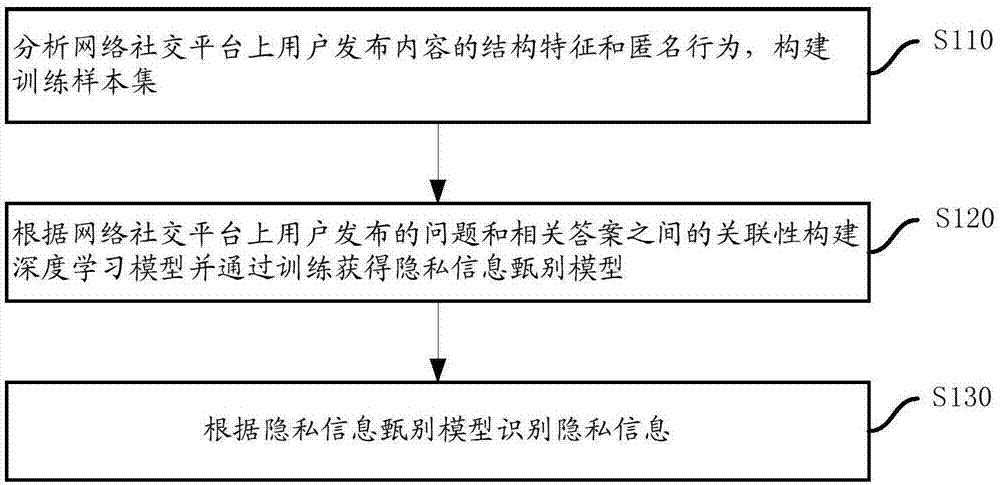
图1示出了根据本发明一个实施例的基于网络社交平台的隐私信息甄别方法的流程图;
图2示出了互联网隐私类别和传统隐私类别的分析对比图;
图3示出了根据本发明一个实施例的深度学习模型的框架示意图。
具体实施方式
为了使本发明的目的、技术方案、设计方法及优点更加清楚明了,以下结合附图通过具体实施例对本发明进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
根据本发明的一个实施例,提供了一种基于网络社交平台的用户隐私信息甄别方法,概括而言,该方法包括通过分析现有网络社交平台上用户发布内容的结构特征和用户的匿名行为采集带标签的问答数据集作为训练样本集;构建深度学习模型并基于训练样本集进行训练,以获得用户隐私信息甄别模型;根据获得的隐私信息甄别模型对用户在社交平台上发布的新内容进行隐私性标注。具体地,参见图1所示,包括以下步骤:
步骤s110,分析网络社交平台上用户发布内容的结构特征和匿名行为,构建训练样本集。
在此步骤中,从现有的网络社交平台上抓取大量数据,并根据用户的网上行为进行隐私性标注,以获得带有隐私性标签的训练样本集。为了获得完备的训练样本,在本发明中从目前内容相对丰富的知乎社交平台上抓取数据,并以知乎平台为例进行说明。
经过分析,知乎社交平台具有以下特征:丰富的用户发布内容、结构完整并且涉及的主题或话题范围广,例如,知乎社交平台上包含教育、医疗、娱乐等多种话题类型,根据这些特征,发明人抓取知乎上所有话题下的精华问答作为实验数据集,具体地,首先,抓取知乎的完整话题结构,然后,在每个话题下抓取话题精华,例如,top1000的高票回答,根据精华回答追溯到相关问题,去重后抓取该问题完整的相关信息,例如,针对该问题的回答、对于该问题的关注度等。为了获取完整的实验数据集,可针对每个问题抓取问题页面、答案页面和关注者页面,以获取用户发布内容以及相关用户的匿名行为。
对于获取的实验数据集,分析用户的匿名行为与用户隐私偏好之间的关联性,以对实验数据集进行隐私性标注,例如,以用户的匿名行为作为衡量用户隐私偏好的指标。在一个实施例中,建立了三种用于衡量隐私性的匿名行为指标,包括问题答案匿名率a(t)、问题关注匿名率f(t)以及问题是否匿名提出,其中,问题答案匿名率是指一个问题的匿名答案数与全部答案数之比,问题关注匿名率是指一个问题的匿名关注者数与全部关注者数之比,问题是否匿名提出是指发布该问题的用户是匿名提出还是以实名提出。相关计算公式可分别表示如下:
通过统计分析,上述三个指标是高度相关的,可采用三个指标中的一项指标或多种指标的组合作为最终的隐私衡量标准。例如,选择问题答案匿名率作为隐私衡量指标,如果问题答案匿名率超过一个阈值(如0.27),则就将该问题标注为隐私,否则标注为非隐私。又如,采用问题答案匿名率和问题是否匿名提出两者作为隐私衡量指标,如果问题答案匿名率超过预定的一个阈值并且该问题是匿名提出的情况下,则将该问题标注为隐私。
通过上述过程,可从知乎社交平台上获取多条分析数据来构建训练样本集。下表1示意了训练样本集中的一条数据。
表1:训练样本
表1的训练样本包含问题信息和相关的答案列表信息,由于针对问题“如何评价现在的大学生?”的答案匿名率超过了预定的阈值0.27,因此,将该问题的隐私标签标注为属于隐私信息,可用“1”标识。为了获得完备的训练样本集,可以针对多个话题抓取每个话题下多个精华问题信息和相关答案信息,以提高后续深度学习模型的训练精度。
为了进一步验证采用上述用户匿名行为是否能够准确地反映用户的隐私偏好以及是否适用于网络社交平台,发明人将互联网隐私类别和传统隐私类别进行了对比分析。
目前,现有技术并没有对隐私类别的官方定义,每个在线服务提供商都独立的采用所在机构对敏感内容的规定,结合google、facebook、microsoft、cnil以及theeuropeanparliament等机构关于敏感内容的定义,总结得到15类传统的隐私类别,分别为:保密的就医情况;种族或民族;政治、哲学或宗教信仰;年龄;性取向或性生活;性别;健康状况(包括生理或心理);经济状况;工会成员身份;犯罪记录;武器;赌博,监控设备;痛苦;暴力和剥削;约会等。
在已抓取的知乎数据的基础上,统计得到问题答案匿名率最高的top100个问题,可分类为几大互联网隐私类别,例如,个人经历、关系、教育及教育机构、艺术和娱乐、社会话题、职业、经济状况、暴力等。通过将互联网隐私类别与传统隐私类别进行统计分析发现(参见图2所示):一方面,传统隐私类别和互联网隐私类别在一定程度上彼此支持,例如,经济状况、痛苦等既属于传统隐私类别也属于互联网隐私类别;另一方面,传统隐私类别和互联网隐私类别存在相异,例如,个人经历、职业等属于互联网特有的隐私类别。通过分析可知,问题答案匿名率等用户的匿名行为能够准确的反映中国互联网用户特有的隐私需求。
在此步骤中,构建的训练样本集包含问题信息以及相关答案信息,能够反映网络社交平台上发布内容的结构特征,并且根据用户的匿名行为进行隐私性标注,能够反映互联网用户特有的隐私偏好,从而使构建的训练样本集适用于网络社交平台的内容结构特征并能有效的反映互联网用户的隐私偏好。
步骤s120,根据网络社交平台上用户发布的问题和相关答案之间的关联性构建深度学习模型并通过训练获得隐私信息甄别模型。
对于网络社交平台,一个问题是否属于隐私不仅取决于该问题信息(或称问题文本)的敏感性,还受到上下文的影响,例如,问题是谁提出的,在什么情境下提出的,这些上下文信息无法直接从问题文本中获取,但是通常可以在相关的答案信息中得到一定的体现。因此,为了获得更全面的问题表达,在本发明的一个实施例中,提供了两路的深度学习模型框架,以充分结合问题信息和相关答案的信息。
参见图3所示的深度学习模型的框架示意图,从整体上看,该模型为两路模型框架,包括问题子网络和答案子网络,其中,问题子网络用于获得问题信息的向量表示,答案子网络用于获得答案列表信息的向量表示,进一步地,对问题子网络的输出向量和答案子网络的输出向量拼接之后构成的特征向量利用softmax进行隐私信息分类。具体地,问题子网络包括词向量表示层、双向长短时记忆网络(bilstm)层、问题向量表示层。答案子网络整体上从下至上分为单词层和答案层,单词层包括词向量表示层、bilstm层,答案层包括答案向量表示层、bilstm层和高层答案列表向量表示层。
利用步骤s110中获得的训练样本集可训练图3的深度学习模型,下面分别介绍问题子网络、答案子网络和softmax层的训练过程。
1)关于问题子网络
问题子网络的输入是由单词序列构成的问题文本,例如,对于问题“如何评价现在的大学生?”,为了更好的利用单词的语义信息,将原始的问题文本转换为数值,即生成相应的词向量,可利用word2vec模型或其他现有技术将原始问题文本的单词序列转换为相应的词向量表示。应理解的是,生成词向量之前可包括预处理过程,例如,在对原始问题文本进行分词之后,去除停用词,如“的”、“地”、“得”之类的助词或者像“然而”、“因此”等只能反映句子语法结构的词语和标点符号等。最后获得的词向量表示为w1,w2,…wn,其中,n为问题文本的长度或称问题文本所包含的有效词的数量。
在训练过程中,将问题文本的词向量表示输入到lstm,为了捕获单词的上文和下文信息,本实施例采用双向lstm(bilstm)对问题进行建模(bilstm是指在隐层同时有一个正向lstm和反向lstm,正向lstm捕获上文的特征信息,而反向lstm捕获下文的特征信息)。bilstm包含的正向lstm,按从w1到wn的顺序对问题进行学习,反向lstm从wn到w1进行学习,通过学习得到前向的信息
将前向的信息
2)关于答案子网络
答案子网络的输入是训练样本集中的原始答案列表[a1,a2,…,al],其中,l表示答案的条目,例如,对于问题“如何评价现在的大学生?”,a1为第一个答案“作为一名高校教师,其实我觉得现在的学生都很不错。”,a2为第二个答案“我认为恰恰相反,现在中国的大学的教学水平是配不上学生的努力和天分的。”。
答案子网络的单词层与问题子网络对问题文本的处理类似,即通过对每个答案的文本进行处理,可获得每个答案的向量表示at,t∈[1,l],其中,t为答案列表中各个答案的编号,l为答案列表中的答案数,获得每个答案的向量表示的过程与问题子网络中获得问题的向量表示的过程类似,在此不再赘述,图3中仅示意了a2与单词层的连接,应理解的是,对于任意一个答案的向量表示at均与单词层存在类似于a2的连接。
对于答案层,将在单词层获得的每个答案的向量表示at视为输入,利用bilstm对这些答案的向量表示at进行特征学习提取,得到:
将
3)关于softmax层
将得到的问题向量q与高层答案列表向量a相拼接,得到一个问题的高层表达d,将d作为特征输入到softmax分类器,其输出是标签(例如,0/1,1表示该问题为隐私,0表示该问题是非隐私)上的概率分布,softmax的公式如下:
其中,j=1,…,k,k表示标签的种类索引,p(zj)表示zj对应标签j的概率,z=wcd+bc,在此实施例中,由于有属于隐私和不属于隐私两种标签,因此,k取值为2,d即为上述根据问题子网络的输出和答案子网络的输出所构建的特征向量d,wc和bc为softmax的权重参数和偏置参数,通过该公式可获得训练样本集中每一输入样本属于隐私信息或非隐私信息的概率,在模型训练过程中,通过最小化代价函数可获得softmax的优化权重和偏置。
在此实施例中,通过对深度学习模型训练能够获得对应的隐私信息甄别模型,其中,在softmax层获得了针对训练样本集的优化权重和偏置。
步骤s130、根据隐私信息甄别模型识别隐私信息。
对于用户在网络社交平台上发布一个新问题信息和相关答案信息,采用与训练过程类似的方式,转换为相应的词向量,通过问题子网络和答案子网络分别进行特征提取,得到问题的向量表示q和答案列表的向量表示a,通过拼接获得整个问题的高层表达d,将d输入到已知优化权重和偏置的softmax层,即可获得该新问题属于隐私信息的概率,如果概率大于预定阈值(例如0.5),则将该问题标注为属于隐私信息。应理解的是,该阈值是可调的,通过调整该阈值,能够提高隐私信息甄别模型的预测准确率。
需要说明的是,尽管上文以优选实施例的方式介绍了训练样本集的构建和深度学习模型框架,但在不违背本发明的精神和范围的情况下,本领域的技术人员可对实施例进行适当的改变或变型。例如,可采用gru(gatedrecurrentunit)来代替bilstm对问题信息和相关答案信息进行特征学习;例如,问题子网络和答案子网络不必须采用相同的特征提取方法,如,问题子网络可采用gru,而答案子网络可采用单向或双向lstm;例如,也可以采用svm或朴素贝叶斯等代替softmax实现隐私信息的分类过程。
综上所述,本发明构建的深度学习模型包含问题子网络和答案子网络两路设计,能够针对用户发布内容进行更加全面深入的建模,充分结合了问题本身的信息和相关答案的信息;通过bilstm等进行特征学习提取在关注文本表层语言特征的基础上,深入挖掘了问题和相关答案之间的内在逻辑关系和相互作用;此外,在设计答案子网络时,本发明充分考虑到答案数据的层次结构特性,采用了层次化的rnn(循环神经网络)模型对答案进行分层建模。因此,本发明的隐私信息甄别模型能够对网络社交平台上用户发布的内容有效地进行隐私性预测。
需要说明的是,虽然上文按照特定顺序描述了各个步骤,但是并不意味着必须按照上述特定顺序来执行各个步骤,实际上,这些步骤中的一些可以并发执行,甚至改变顺序,只要能够实现所需要的功能即可。
本发明可以是系统、方法和/或计算机程序产品。计算机程序产品可以包括计算机可读存储介质,其上载有用于使处理器实现本发明的各个方面的计算机可读程序指令。
计算机可读存储介质可以是保持和存储由指令执行设备使用的指令的有形设备。计算机可读存储介质例如可以包括但不限于电存储设备、磁存储设备、光存储设备、电磁存储设备、半导体存储设备或者上述的任意合适的组合。计算机可读存储介质的更具体的例子(非穷举的列表)包括:便携式计算机盘、硬盘、随机存取存储器(ram)、只读存储器(rom)、可擦式可编程只读存储器(eprom或闪存)、静态随机存取存储器(sram)、便携式压缩盘只读存储器(cd-rom)、数字多功能盘(dvd)、记忆棒、软盘、机械编码设备、例如其上存储有指令的打孔卡或凹槽内凸起结构、以及上述的任意合适的组合。
以上已经描述了本发明的各实施例,上述说明是示例性的,并非穷尽性的,并且也不限于所披露的各实施例。在不偏离所说明的各实施例的范围和精神的情况下,对于本技术领域的普通技术人员来说许多修改和变更都是显而易见的。本文中所用术语的选择,旨在最好地解释各实施例的原理、实际应用或对市场中的技术改进,或者使本技术领域的其它普通技术人员能理解本文披露的各实施例。
- 还没有人留言评论。精彩留言会获得点赞!