一种基于深度学习的开关柜图像开关状态自动识别方法与流程
本发明涉及电力系统图像处理技术领域,尤其是涉及一种基于深度学习的开关柜图像开关状态自动识别方法。
背景技术:
随着我国电力事业的快速发展,高压机柜设备越来越多。开关柜设备误操作事故是整个电力行业安全生产事故中最严重的事故,也是多发的事故之一。高压开关柜误操作事故的发生有着管理和人为方面的主观原因,同时设备本身存在的安全隐患也是极其重要的客观原因。误操作事故后果轻则引起电力系统受损,重则危害人身安全。因此,迫切需要开发机柜开关的自动识别系统来对高压开关柜进行开关检测和识别。
目前在神经网络领域,目标识别技术主要可以分为两大类,其中一类是将识别作为分类问题进行处理,利用分类器判断网络给出的每一个候选框中是否包含物体以及其所属类别;另一类则将识别作为回归问题来处理,使用一个神经网络通过端到端的方法对一整张图像进行回归,直接识别出图像中存在的物体及其位置信息。
ssd算法是是uncchapelhill(北卡罗来纳大学教堂山分校)的weiliu大神在2016年eccv一篇文章提到的。https://github.com/weiliu89/caffe/tree/ssd。一种直接预测目标类别和boundingbox的多目标检测算法。与fasterrcnn相比,该算法没有生成proposal的过程,这就极大提高了检测速度。针对不同大小的目标检测,传统的做法是先将图像转换成不同大小(图像金字塔),然后分别检测,最后将结果综合起来(nms)。而ssd算法则利用不同卷积层的featuremap进行综合也能达到同样的效果。算法的主网络结构是vgg16,将最后两个全连接层改成卷积层,并随后增加了4个卷积层来构造网络结构。对其中5种不同的卷积层的输出(featuremap)分别用两个不同的3×3的卷积核进行卷积,一个输出分类用的confidence,每个defaultbox生成21个类别confidence;一个输出回归用的localization,每个defaultbox生成4个坐标值(x,y,w,h)。此外,这5个featuremap还经过priorbox层生成priorbox(生成的是坐标)。上述5个featuremap中每一层的defaultbox的数量是给定的(8732个)。最后将前面三个计算结果分别合并然后传给loss层。
技术实现要素:
本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种基于深度学习的开关柜图像开关状态自动识别方法。
本发明的目的可以通过以下技术方案来实现:
一种基于深度学习的开关柜图像开关状态自动识别方法,包括以下步骤:
1)读取待识别的开关柜图像并缩放;
6)根据训练样本的真实框数据通过聚类获取多个先验框;
7)构建卷积神经网络,并且根据先验框的数据对卷积神经网络进行训练;
8)将缩放后的输入图像作为训练后的卷积神经网络的输入,获得检测信息,包括标签、损坏概率和位置坐标;
9)采用非极大值抑制方法对检测信息进行处理,得到最终的预测框;
6)在待识别的开关柜图像中画出预测框并且标出目标所属类别标签。
所述的步骤1)中,缩放后的开关柜图像的尺寸大小为300*300。
所述的步骤2)具体包括以下步骤:
21)标记真实框:
在训练样本中手动标记真实框,并获取训练样本真实框的数据,包括真实框的中心位置、宽度和高度;
22)生成默认框:
对每一张特征图,按照不同的大小和长宽比生成k个默认框,并且确定每个默认框大小;
23)标记数据预处理:
对标签信息进行预处理,并将其对应到相应的默认框上,根据默认框和标记数据框的相似系数重叠值获取对应的默认框,并且选取相似系数重叠值超过0.5的默认框为正样本,其它为负样本。
所述的步骤22)中,默认框大小的计算式为:
其中,sk为默认框大小,smin为最底层特征图默认框大小,smax为最顶层特征图默认框大小,m为特征图数目。
每个默认框的宽
所述的步骤3)具体包括以下步骤:
31)采用ssd模型结构,对每张特征图采用3×3卷积生成默认框的偏移位置和类别置信度;
32)将ssd目标函数分为两部分,分别对应默认框的位置和类别置信度,则ssd目标函数l(x,c,l,g)为:
其中,n为匹配的默认框,lconf(x,c)为置信损失,lloc(x,l,g)为定位损失,α为调节置信损失和定位损失之间的比例参数,c为置信度,smoothl1(·)为fasterrcnn的计算距离损失,x为自变量,m为当前层数,pos为positive正样本,cx、cy分别为默认框的中心坐标,w和h为默认框的宽和高,
所述的步骤5)具体包括以下步骤:
51)将神经网络输出的所有预测框概率降序排列,选取最高分及其对应的预测框;
52)在其余的预测框中,如果存在与当前最高分预测框的重叠面积大于阈值的预测框,则将其剔除;
53)遍历其余的预测框,重复步骤52)获取保留的最终的预测框。
与现有技术相比,本发明具有以下优点:
一、实时性:由于网络结构的特殊化,识别速度快,可以完成视频实时的识别。
二、可以在android设备运行:因为网络结构优化设计,使得其可以拥有实时性,且对设备配置要求不事很苛刻,可在android设备使用,拥有gpu的设备效果更佳。
三、收敛快、选择准确:要想得到一个精确的识别结果,不仅要对目标定位准确,而且要对的大小判断准确,也即要使预测框与真实框的重叠率尽可能接近1。因为开关柜上的开关类型有限,大小固定,我们可以通过聚类从人工标记的真实框中挑选出最具代表性的框作为先验框,以这些先验框的大小作为预测框大小的初始值,卷积神经网络只需在这先验框的基础上微调即可得到很好的预测效果。这样做不仅计算量小有助于卷积神经网络训练和预测,且预测准确。
附图说明
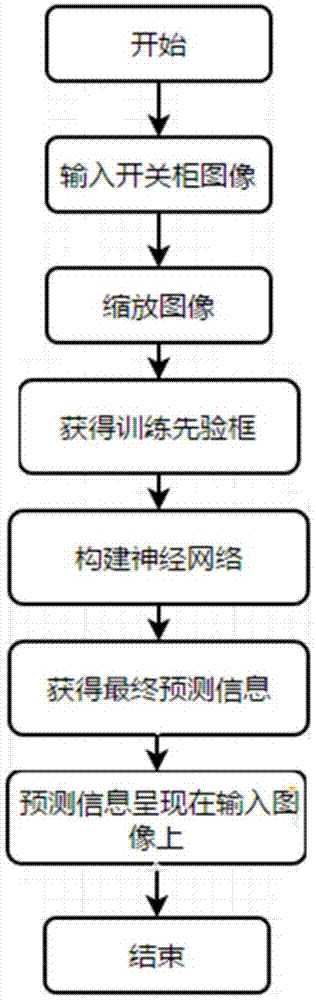
图1为本发明的流程图。
具体实施方式
下面结合附图和具体实施例对本发明进行详细说明。
实施例
如图1所示,本发明具体实施步骤如下:
步骤1:读入待识别的开关柜图像,缩放图片,尺寸大小为300*300,获取缩放后的输入图像。
本发明实施例中输入的待处理的高压柜开关图像,开关图像的像素范围为[800-1000],缩放后图像尺寸大小选择为300*300。
步骤2:聚类获得先验框。
读取训练样本真实框的数据。
本发明实施例中,训练样本真实框是图像中人工标记的目标框信息。
对每一张特征图,按照不同的大小(scale)和长宽比(ratio)生成k个默认框(defaultboxes),默认框数目k=6,其中5×5的红色点代表特征图,因此:5*5*6=150个boxes。每个默认框大小计算公式为:
其中,m为特征图数目,smin为最底层特征图大小(取值为0.15),smax为最顶层特征图默认框大小(取值为0.9)。
每个默认框长宽比根据比例值计算,原比例值为{1,2,3,1/2,1/3},因此,每个默认框的宽为
步骤3:构建神经网络。
ssd模型结构。模型选择的特征图包括:38×38(block4),19×19(block7),10×10(block8),5×5(block9),3×3(block10),1×1(block11)。对于每张特征图,生成采用3×3卷积生成默认框的四个偏移位置和21个类别的置信度。比如block7,默认框(defboxes)数目为6,每个默认框包含4个偏移位置和21个类别置信度(4+21)。因此,block7的最后输出为(19*19)*6*(4+21)。
32)ssd目标函数分为两个部分:对应默认框的位置loss(loc)和类别置信度loss(conf)。定义
其中,n为匹配的默认框。如果n=0,loss为零。lconf为预测框l和groundtruthbox(标记数据框)g的smoothl1loss,α值通过crossvalidation设置为1。
定义如下:
其中,l为预测框,g为groundtruth。(cx,cy)为补偿(regresstooffsets)后的默认框(d)的中心,(w,h)为默认框的宽和高。
lconf定义为多累别softmaxloss,公式如下:
步骤4:对输入图像进行尺寸缩放,得到能输入到网络中的图像;
步骤5:将步骤4得到的图像输入到步骤3构建的网络中进行识别,获得开关目标识别的位置及所属类别信息(标签,概率,坐标);
步骤6:处理获得的位置及所属类别信息,获得最终的预测框:
将所有框的得分降序排列,选中最高分及其对应的框;
遍历其余的框,如果和当前最高分框的重叠面积iou大于一定阈值,将框删除;
从未处理的框中继续选一个得分最高的,重复上述过程,得到保留下来的预测框数据;
步骤7:在检测信息(标签,概率,坐标)勾画在原图中。
- 还没有人留言评论。精彩留言会获得点赞!