基于k-d树的LOF离群点检测方法与流程
本发明属于计算机技术领域,更进一步涉及数据挖掘技术领域中的一种基于k-d树的局部离群因子lof(localoutlierfactor)的离群点检测方法。k-d树是一种对k维空间中的数据对象进行存储以便对其进行快速检索的树形数据结构,它将k维数据结构拆分为k近邻搜索空间划分树,构建数据对象的层次结构。本发明可用于对网络数据流组成的数据集进行离群点的挖掘,在保证挖掘准确度的同时降低离群点挖掘时的时间与空间复杂度,实现离群点的高效挖掘。
背景技术
离群点挖掘技术是数据挖掘技术的一个重要的研究方向,通过挖掘离群点来发现数据集中潜在的有用信息,如果异常是由确定数据的变异造成的,那么对它们进行分析可以发现蕴藏在其中更深层次的、潜在的、有价值的信息。而且在真实的网络环境中,网络数据流或者数据库中都包含了很多噪声与离群点,对给定数据集进行数据挖掘分析时,离群点检测分析是一项重要的任务,必须采用高效的检测算法对离群点进行处理。通常,离群点常被视为噪声而被剔除,或者直接认定其为异常行为产生的数据,而且,在具体的网络入侵检测应用中,离群点一般被认定为异常入侵数据直接被阻拦或加入到网络异常行为模式库中;然而,离群点可能有着特殊意义,它与其他数据对象产于与完全不同的机制,或者说离群点可能并不是网络入侵行为产生的数据,因此,对于离群点的分析是网络入侵分析检测中的一项重要的任务。该技术一般使用k-d树对k维空间中的数据对象进行存储以便对其进行快速检索,在保证大规模数据集下离群点检测同时的降低了检测的时间与空间复杂度。
哈尔滨工程大学在其申请的专利文献“一种基于偏离特征的离群点挖掘方法”(申请号:201710599251.x,公开号:cn107562778a)中公开一种基于偏离特征的离群点挖掘方法。该方法的步骤包括:通过将数据集的各个维度划分为n个等间距的间隔,整个数据集被划分为n个网格,求出各个网格的质心,并计算质心与数据集中对象的局部离群因子,从而实现了离群点的检测。基于偏离特征的离群点检测算法虽然在一定程度上可以解决挖掘大规模数据集时需要高昂时间与空间开销的问题,但是,该方法仍然存在不足之处有两点,第一,由于划分网格时需要确定划分的粒度,事先确定一些参数,从而导致挖掘结果具有很大波动性。第二,该方法基于各个维度上的划分数为n的假设来将整个数据空间划分为一定数量的网格,由此导致了划分不准确的问题。
中国农业大学在其拥有的发明专利技术“一种自适应无参空间离群点检测方法”(申请号:201610178994.5,授权公告号:cn105844102b)中公开一种自适应无参空间离群点检测方法。该方法的步骤包括:通过基于全局稳定的最近邻确定算法计算出最终最近邻居个数和对象的空间邻域,计算每个对象的空间离群度,对数据集的非空间维度属性进行离群点检测,并设置临界离群点,计算判定空间离群点的门限值,将slov大于门限的点作为潜在空间离群点,进行空间离群点鉴别。自适应无参空间离群点检测方法虽然在一定程度上提高了检测精度与自适应性。但是,该方法仍然存在的不足之处是,由于该方法需要计算数据集中每个对象的空间离群度,因此,计算开销过大。同时,该方法在处理实时大规模的高维数据对象时时间与空间复杂度较高,导致实用性差。
技术实现要素:
本发明的目的在于针对上述现有技术的不足,提出基于k-d树的lof离群点检测方法,以解决当前lof离群点检测方法对大规模数据集检测效率不高和在计算过程中存在的计算开销过大的问题。
为实现上述目的,本发明的具体思路是:使用k-d树对k维空间中的数据对象进行存储以便对其进行快速检索,用垂直于坐标轴的超平面切分k维数据空间构造k-d树,k-d树的每个结点对应于一个k维超矩形区域,所有的离群点检测都在k-d树结构上进行。本发明克服了现有技术中lof离群点检测方法在处理实时大规模的高维数据对象时时间与空间复杂度较高,导致实用性差的问题,在保证大规模数据集下离群点检测同时提高了计算过程的高效性与实用性。
本发明的具体步骤包括如下:
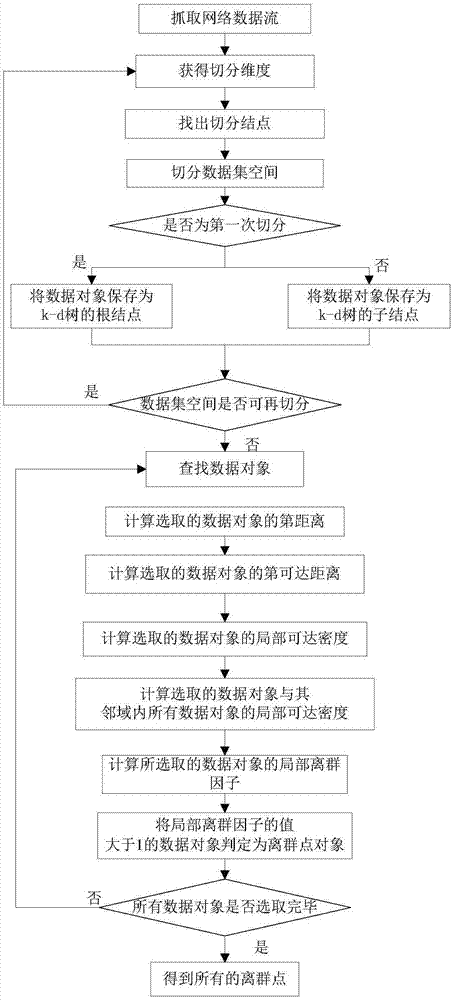
(1)抓取局域网中的数据流,将数据流中的所有数据对象组成k维数据集空间:
(2)获得切分维度:
(2a)利用方差值计算公式,计算k维数据集空间中的所有数据对象在每个维度的方差值;
(2b)对方差值进行降序排列,将其中最大方差值对应的维度作为切分维度;
(3)确定切分结点:
将所有k维数据集空间中的数据对象按照切分维度的属性值排序,将排序后的中间位置的数据对象,作为切分结点;
(4)对k维数据集空间进行切分:
(4a)将通过该切分结点且垂直于当前切分维度坐标轴的k维超矩形平面,作为当前维度的k维超矩形切分平面;
(4b)使用当前维度的k维超矩形切分平面,将k维数据集空间划分为左子数据集空间和右子数据集空间;
(5)判断是否为第一次切分k维数据集空间,若是,则执行步骤(6),否则,执行步骤(7):
(6)将落在当前维度的k维超矩形切分平面上的所有数据对象,保存为k-d树的根结点:
(7)将落在当前维度的k维超矩形切分平面上的所有数据对象,保存为k-d树的子结点:
(8)判断当前每个左、右子数据集空间中是否包含两个以上的数据对象,若是,则执行步骤(2),否则,完成构建空间划分树后执行步骤(9):
(9)查找数据对象:
(9a)在k维数据集空间中任意选取一个数据对象;
(9b)从根结点出发,向下搜索k-d树,如果选取的数据对象在切分维度上的属性值小于切分结点的属性值,在左子空间查找,否则在右子空间查找;
(10)计算选取的数据对象的第t距离:
(10a)利用距离计算公式,计算选取的数据对象与其周围所有数据对象的距离;
(10b)将选取的数据对象与其周围所有数据对象的距离升序排列,将排在第t个的距离作为该数据对象的第t距离,其中t表示常数,1≤t≤n,n表示数据集空间中数据对象的总数;
(11)利用第t可达距离计算公式,计算选取的数据对象的第t可达距离:
(12)利用局部可达密度计算公式,计算选取的数据对象的局部可达密度:
(13)利用局部可达密度计算公式,计算选取的数据对象邻域内的所有数据对象的局部可达密度:
(14)利用局部离群因子计算公式,计算所选取的数据对象的局部离群因子:
(15)将局部离群因子的值大于1的数据对象判定为离群点对象:
(16)判断所有数据对象是否选取完毕,若是,执行步骤(17),否则,执行步骤(9):
(17)得到所有的离群点对象。
本发明与现有的技术相比具有以下优点:
第一,由于本发明通过建立k-d树,将大规模数据对象存储于k-d树,克服了现有技术在处理实时大规模的高维数据对象时,数据存储空间利用率较低的问题,使得本发明在对大规模数据进行离群点挖掘过程中具有高效性的优点。
第二,由于本发明将数据集中每个数据对象都存储于k-d树,克服了现有技术在划分网格时需要确定划分的粒度,事先确定一些参数,从而导致挖掘结果具有很大波动性的问题,使得本发明在进行离群点挖掘时具有很大稳定性的优点。
第三,由于本发明通过k-d树对k维数据集空间进行切分,克服了现有技术是基于各个维度上的划分数为n的假设来将整个数据空间划分为一定数量的网格,从而导致了划分不准确的问题,使得本发明在进行离群点挖掘时具有准确率高的优点。
第四,由于本发明将大规模数据对象存储于k-d树,所有的离群点检测都在k-d树结构上进行,克服了现有技术在处理实时大规模的高维数据对象时时间与空间复杂度较高,导致实用性差问题,使得本发明具有快速查找数据对象,实现大规模数据集下离群点实时检测的优点。
附图说明
图1为本发明的流程图;
图2为本发明仿真实验结果图。
具体实施方式
下面结合附图对本发明做进一步的描述。
参照图1,本发明的具体实施步骤做进一步的描述。
步骤1,抓取局域网中的数据流,将数据流中的所有数据对象组成k维数据集空间。
步骤2,获得切分维度。
利用数据集空间中的数据对象在每个维度的方差值计算公式计算数据集空间中的数据对象在每个维度的方差值。
所述数据集空间中的数据对象在每个维度的方差值计算公式如下:
其中,
对方差值进行降序排列,将其中最大方差值对应的维度作为切分维度。
步骤3,确定切分结点。
将所有数据集空间中的数据对象按照第k维度的属性值排序,选取排序后中间位置的数据对象,作为切分结点。
步骤4,对k维数据集空间进行切分。
将通过该切分结点且垂直于当前切分维度坐标轴的k维超矩形平面,作为当前维度的k维超矩形切分平面。
使用当前维度的k维超矩形切分平面,将k维数据集空间划分为左子数据集空间和右子数据集空间。
步骤5,判断是否为第一次切分k维数据集空间,若是,则执行步骤6,否则,执行步骤7。
步骤6,将落在当前维度的k维超矩形切分平面上的所有数据对象,保存为k-d树的根结点。
步骤7,将落在当前维度的k维超矩形切分平面上的所有数据对象,保存为k-d树的子结点。
步骤8,判断当前每个左、右子数据集空间中是否包含两个以上的数据对象,若是,则执行步骤2,否则,完成构建空间划分树后执行步骤9。
步骤9,查找数据对象。
在k维数据集空间中任意选取一个数据对象。
从根结点出发,向下搜索k-d树,如果选取的数据对象在切分维度上的属性值小于切分结点的属性值,在左子空间查找,否则在右子空间查找。
步骤10,计算选取的数据对象的第t距离。
利用距离计算公式,计算选取的数据对象与其周围所有数据对象的距离。
所述距离计算公式如下:
其中,d(p,o)表示数据对象p与数据对象o之间的距离,xpi表示数据集空间中数据对象p在第i维度的属性值,1≤i≤m,m表示数据对象的维数,xoi表示数据对象o在第i维度的属性值。
将选取的数据对象与其周围所有数据对象的距离升序排列,将排在第t个的距离作为该数据对象的第t距离,其中t表示常数,1≤t≤n,n表示数据集空间中数据对象的总数。
步骤11,利用第t可达距离计算公式,计算选取的数据对象的第t可达距离。
所述第t可达距离计算公式如下:
dt(p,o)=max{dt,d(p,o)}
其中,dt(p,o)表示数据对象o到数据对象p的第t可达距离,t表示常数,1≤t≤n,n表示数据对象的总数,max{...}表示取最大值,dt表示数据对象p的第t距离,d(p,o)表示数据对象p与数据对象o之间的距离。
步骤12,利用局部可达密度计算公式,计算选取的数据对象的局部可达密度。
所述局部可达密度计算公式如下:
其中,lt(p)表示数据对象的局部可达密度,t表示常数,1≤t≤n,n表示数据对象的总数,nt(p)表示数据对象的邻域,|nt(p)|表示数据对象邻域内数据对象的个数,dt(p,o)表示数据对象o到数据对象p的第t可达距离。
步骤13,利用局部可达密度计算公式,计算选取的数据对象邻域内的所有数据对象的局部可达密度。
步骤14,利用局部离群因子计算公式,计算所选取的数据对象的局部离群因子。
所述局部离群因子计算公式如下:
其中,lt(p)表示数据对象的局部离群因子,t表示常数,1≤t≤n,n表示数据对象的总数,lt(o)表示数据对象o的局部可达密度,lt(p)表示数据对象的局部可达密度表示,nt(p)表示数据对象的邻域,|nt(p)|表示数据对象邻域内数据对象的个数。
步骤15,将局部离群因子的值大于1的数据对象判定为离群点对象。
步骤16,判断所有数据对象是否选取完毕,若是,执行步骤17,否则,执行步骤9。
步骤17,得到所有的离群点对象。
本发明的效果可以通过下述仿真实验得到验证。
1.仿真条件:
本发明的仿真实验采用四种数据空间集,每种数据空间集中的数据对象的数量分别为2000个、4000个、6000个、8000、10000,12000个,离群点数据对象数量都为100个。
2.仿真内容:
本发明的仿真实验是采用本发明的方法和现有技术的lof离群点检测方法,对本发明所选取的四种数据空间集进行离群点检测。将采用本发明的方法对数据集中的离群点的检测时间,与现有技术下的离群点检测时间进行对比,得到如图2所示的两条曲线。
3.仿真结果分析:
图2是本发明与现有技术lof离群点检测方法运行时间随数据对象数量变化的曲线图,其中,图2中的横坐标表示数据对象的数量,纵坐标表示离群点检测时间,物理单位为秒。图2中的实线标示的曲线,表示采用现有技术对离群点进行检测的时间曲线,图2中的虚线标示的曲线,表示采用本发明的方法对离群点进行检测的时间曲线。由图2可见,在横坐标表示的相同数量数据对象的条件下,本发明的离群点检测时间比现有技术的lof离群点检测方法时间短很多。
由以上的仿真结果表明:本发明由于采用基于k-d树改进的lof离群点检测方法,使用k-d树对k维空间中的数据对象进行存储以便对其进行快速检索,从而有效提高了数据对象的检索速度,大大降低了处理实时大规模的高维数据对象时时间与空间复杂度,提高了离群点的检测效率。
- 还没有人留言评论。精彩留言会获得点赞!