一种基于电子政务网的档案数据采集方法与流程
本发明涉及政务网与档案系统的数据采集方法领域,尤其是一种基于电子政务网的档案数据采集方法。
背景技术:
电子政务系统是基于互联网技术的面向政府机关内部、其他政府机构的信息服务和信息处理系统,政府的主要职能在于经济管理、市场监管、社会管理和公共服务,而电子政务需要将四大职能电子化和网络化,实现利用高现代信息技术对政府进行信息化改造以提高政府部门依法行政的水平;电子政务的4个突出的特点:电子政务将政务工作更有效、更精简;电子政务将政府工作更公开、更透明;电子政务将为企业和居民提供更好的服务;电子政务将重新构造政府、企业、居民之间的关系,使之比以前更加协调,使企业和居民能够更好的参与政府的管理;处理电子政务的电子政务网,因为其性质对外未设置开发接口,外界无法采集公文数据,因此无法将档案系统与电子政务网进行连接实现线上的数据采集与管理。
插件是一种遵循一定规范的应用程序接口编写出来的程序,插件需要调用原纯净系统提供的函数库或者数据,其只能运行在程序规定的系统平台下,而不能脱离指定的平台单独运行。
其中电子政务网中的公文需要按规定每年移交至档案局进行保管,现有采用将公文打印,封装成册线下移交,档案局工作人员录入档案系统完成公文的存档和保管,采用这种方法处理速度慢,容易出现公文信息的重复录入或者错误录入,工作人员的工作量极大,因此需要改进现有的公文档案管理方法。
技术实现要素:
本发明的目的在于:本发明提供了一种基于电子政务网的档案数据采集方法,解决了现有政务网对外未设置开发接口导致采用线下采集公文数据进行档案管理带来的工作效率和工作质量低的问题。
本发明采用的技术方案如下:
一种基于电子政务网的档案数据采集方法,包括如下步骤:
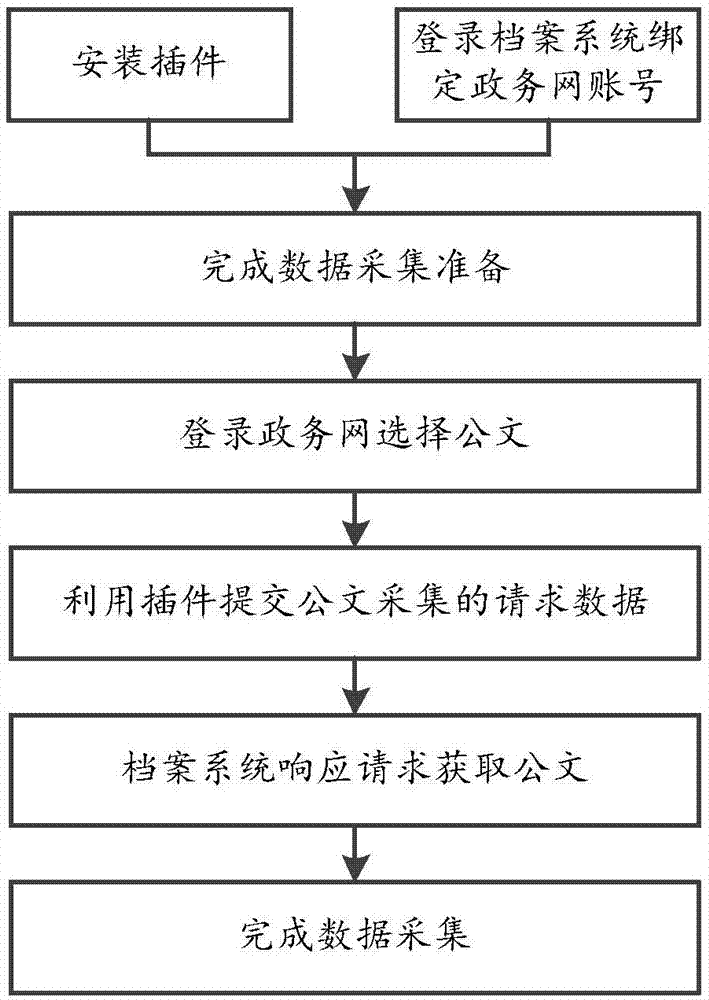
步骤1:安装插件并登录档案系统绑定政务网账号完成数据采集准备;
步骤2:登录政务网选择公文后利用插件提交公文采集的请求数据;
步骤3:档案系统根据请求数据响应请求获取公文完成数据采集。
优选地,所述步骤2包括如下步骤:
步骤2.1:在浏览器中登录政务网,选择需要移交的公文;
步骤2.2:右击鼠标选中一键采集菜单,插件完成解析html后提取公文元数据并提交公文采集的请求数据。
优选地,所述步骤3包括如下步骤:
步骤3.1:档案系统根据请求数据判断是否重复采集,若是,则结束采集,若否,则跳至步骤3.2;
步骤3.2:模拟登录政务网后判断登录是否成功,若是,档案系统采集政务网公文交换系统公文附件后跳至步骤3.3;若否,则结束采集;
步骤3.3:档案系统存储公文附件数据和公文元数据完成数据采集。
优选地,所述插件基于ie浏览器安装。
优选地,所述公文元数据包括文号、提名、责任者、成文日期、附件路径和页数;提取方式采用逐个提取方式。
综上所述,由于采用了上述技术方案,本发明的有益效果是:
1.本发明通过设置基于浏览器的公文采集插件,插件获取和过滤公文数据,档案系统获取公文附件数据,实现公文数据线上采集和档案管理,解决了现有政务网对外未设置开发接口导致采用线下采集公文数据进行档案管理带来的工作效率和工作质量低的问题,达到了简便公文数据的档案管理,提高档案管理效率的效果;
2.本发明的插件设计时需要考虑插件与档案系统之间参数的匹配满足其的兼容性,提交到档案系统的参数按照正则表达式的格式提交考虑采集量过度时的优化措施,保证数据采集的稳定性和安全性,实现政务网与档案系统的数据共享。
附图说明
本发明将通过例子并参照附图的方式说明,其中:
图1是本发明的流程图;
图2是本发明的流程示意图。
具体实施方式
本说明书中公开的所有特征,或公开的所有方法或过程中的步骤,除了互相排斥的特征和/或步骤以外,均可以以任何方式组合。
下面结合图1、图2对本发明作详细说明。
实施例1
一种基于电子政务网的档案数据采集方法,包括如下步骤:
步骤1:安装插件并登录档案系统绑定政务网账号完成数据采集准备;
步骤2:登录政务网选择公文后利用插件提交公文采集的请求数据;
步骤3:档案系统根据请求数据响应请求获取公文完成数据采集。
步骤2包括如下步骤:
步骤2.1:在浏览器中登录政务网,选择需要移交的公文;
步骤2.2:右击鼠标选中一键采集菜单,执行oncontentmenu函数,通过external.menuarguments.event.srcelement获取到当前公文的html代码,去掉无用的html代码并进行base64编码,将编码后的html代码作为参数调用插件程序,插件程序解析html提取公文元数据向档案系统提交公文采集的请求数据;
步骤3包括如下步骤:
步骤3.1:档案系统根据请求数据判断是否重复采集,若是,则结束采集,若否,则跳至步骤3.2;
步骤3.2:模拟登录政务网后判断登录是否成功,若是,档案系统采集政务网公文交换系统公文附件后跳至步骤3.3;若否,则结束采集;档案系统从政务网获取公文附件的地址,档案系统通过地址下载文件;
步骤3.3:档案系统存储公文附件数据和公文元数据完成数据采集。
在电脑上安装公文采集插件,登录档案系统绑定政务网账号,完成数据采集准备,当档案操作员通过ie浏览器进入政务网管理公文时,选择需要归档或者移交的公文,在浏览器中鼠标右击选择弹出菜单中一键采集,执行oncontentmenu函数,通过external.menuarguments.event.srcelement获取到当前公文的html代码,去掉无用的html代码并进行base64编码,将编码后的html代码作为参数调用插件程序,插件程序对html代码进行base64解码并分析需要的元数据提交给档案系统;档案系统模拟登录到政务网后获取政务网上公文附件的地址,根据地址下载公文附件并保存至本地;整个数据采集过程,插件和档案系统共同参与完成,插件获取和过滤数据公文数据,档案系统获取公文附件数据。
设计的插件用ie浏览器是因为考虑其兼容性,政务网推荐使用ie浏览器,同时ie浏览器支持通过注册表添加浏览器菜单进而调用插件;数据采集过程中采集的html内容太多,会超过cmd命令参数的限制,因此需要分析并提取关键元数据:文号、提名、责任者、成文日期、附件路径、页数,分析时采用正则表达式的方式,比如按照“fileno=文号&title=提名&responsibility=责任者&formationdate=成文日期&attachment=附件路径&pagecount=页数”的格式提交,对上述元数据逐个提取。
本发明通过设置基于浏览器的公文采集插件,插件获取和过滤公文数据,档案系统获取公文附件数据,实现公文数据线上采集和档案管理,解决了现有政务网对外未设置开发接口导致采用线下采集公文数据进行档案管理带来的工作效率和工作质量低的问题,达到了简便公文数据的档案管理,提高档案管理效率的效果。
- 还没有人留言评论。精彩留言会获得点赞!