一种基于多面排序网络解决推文预测转发任务的方法与流程
本发明涉及推文转发预测任务,尤其涉及一种基于多面排序网络解决推文预测转发任务的方法。
背景技术:
随着以社交关系为基础的网站的蓬勃发展,对于用户推文转发情况的预测也成为一项具有挑战性的工作,该任务的目的是对于某一用户预测其转发所关注的用户推文的概率大小,但是目前已有的预测方法效果并不是很好。
现有的技术主要是利用推文的文本信息预测未来的用户推文分享情况,但是随着移动式设备的逐渐普及,越来越多的推文开始带有图片,所以在预测推文转发情况时,将推文中的图片信息也考虑进去便成为一项非常重要的任务。
本发明将首先利用已有的用户、推文之间的关系及用户之间的相互关系构建社交媒体网络,之后通过卷积神经网络与lstm网络来分别获取推文的图片及文本的语义表达,利用随机初始化得到用户表达,之后结合用户表达及推文文本及图片的表达得到关于用户本身对于该推文感兴趣程度的损失值。之后通过构建的社交关系网络中的用户之间相互关注的关系,得到用户之间相互影响大小,并利用该影响力数值结合用户表达与推文表达得到反映在用户之间相互影响的前提下用户对于推文感兴趣程度的损失项值。将用户本身对于该推文感兴趣程度的损失值与反映在用户之间相互影响的前提下用户对于推文感兴趣程度的损失项值结合,得到最终的损失目标函数,经过训练,得到用户对于某推文感兴趣程度的大小,并利用该值预测用户对于推文的转发概率。
技术实现要素:
本发明的目的在于解决现有技术中的问题,为了克服现有技术中仅仅关注到推文中的文本没有关注推文中的图片且没有加入反映用户之间相互影响力的问题,本发明提供一种基于多面排序网络解决推文预测转发任务的方法。本发明所采用的具体技术方案是:
基于多面排序网络解决推文预测转发任务的方法,包含如下步骤:
1、针对于一组社交网络用户及其对于的推文转发情况,构建包含用户、推文之间相互关系的社交媒体网络。
2、对于步骤1所得到的社交媒体网络中的带有图片的推文,利用卷积神经网络获取推文图片的表达,利用单词映射网络及lstm网络获取推文文本的语义表达,利用随机初始化获取用户的映射表达。之后结合推文的图片及文本表达获取推文的综合表达,利用推文的综合表达及用户的表达获取反映用户本身对于推文感兴趣程度大小的值。利用步骤1构建的社交媒体网络中的用户之间相互关注的关系及用户表达矩阵,得到用户相互影响力分数,并利用该分数与用户表达及推文综合表达得到反映结合了用户之间相互影响的用户对于推文感兴趣程度的值。两者结合得到最终的损失函数。
3、利用所获得的含有用户推文转发关系及用户间关系的数据集,针对步骤2所得的损失函数,经过训练,得到最终的损失函数,根据该函数可以对于任意用户及其关注的用户发出的任意推文进行排序,将更可能被用户转发的推文排在前列。
上述步骤可具体采用如下实现方式:
1、对于所给出的用户及用户所发的微博,按照实际数据集中的用户之间社交关系及用户与微博博文的发布关系形成社交媒体网络。
2、对于所给出的推文,利用如下方法获取带有图片的推文的综合表达:对于推文中的图片,输入到卷积神经网络中获取对应图片的表达,对于图片ii,输入到卷积神经网络中获取其对应表达xi。对于给定的微博博文,将其单词通过预先训练好的单词映射网络获取其单词映射。对于由一个单词序列构成的微博博文di,设其第t个单词通过预先训练好的单词映射网络获取的单词映射为xit,则将序列(xi1,xi2,...,xik)作为微博博文xi的单词映射表达,之后,将博文di分成若干段,并将各段的单词映射序列作为lstm网络的输入,以lstm网络的最后一个隐藏层的输出作为该段博文的映射表达,之后将各段的输出同时输入一个最大池化层,将池化层的输出yi作为微博博文di的映射表达。
3、利用多模态混合函数来得到推文的图片与文本的混合表达,给定第i条推文的图片表达映射xi与推文中的文本表达yi,则该推文的综合表达如下:
zi=g(w(i)xi+w(d)yi)
其中,w(i)与w(d)为该混合函数用来混合推文的图片表达与文本表达的权重矩阵,g(.)为非线性的双曲正切激活函数。
4、通过随机初始化得到用户的映射矩阵u={u1,u2,...,ul},其中up代表了用户p的映射向量,利用如下公式获取用户p本身对于推文i的感兴趣程度大小值:
5、利用如下公式获取用户p受到其所关注的用户q的影响力大小:
spq=p·tanh(w(s)up+w(n)uq+b)
其中,up代表了用户p的映射向量,uq代表了用户p所关注的用户q的映射向量,w(s)与w(n)为用来反映用户q对于用户p影响力大小的权重矩阵,b为偏置向量,tanh(.)为非线性的双曲正切激活函数。p为用来计算影响力分数大小的参数向量。
针对于用户p会关注多个用户,则针对于用户p关注的用户集合np中的每一个用户q,用户q对于用户p的相对影响力分数大小为;
6、利用步骤5获取的用户p对于用户q的影响力权重α,与步骤4所得到的用户p本身对于推文i的感兴趣程度大小,得到用户p在其所关注的所有用户的影响下,对于推文i感兴趣程度的大小值为:
则结合步骤4所得到的用户p本身对于推文i的感兴趣程度大小
7、给定包含用户之间相互关注关系与用户推文的数据集合(j,i,k,nj),该集合表示用户j对于推文i的转发概率高于对于推文k的转发概率,且用户i所关注的用户集合为nj。同时给定步骤6所得的针对于数据集合(j,i,k,nj)中的所有用户j的转发概况函数
其中,
8、则结合模型中所有参数作为损失项,可得到最终的损失函数如下:
其中,ψ为模型中的所有参数构成的集合,β为对于步骤7所得的带注意力机制的多模态排序损失函数损失项与模型参数值损失项的权衡参数,(j,i,k,nj)为模型对应的所有代表用户j对于推文i的转发概率高于对于推文k的转发概率的数据集合。
9、对于步骤8中的最终的目标函数,本发明使用随机梯度下降的方法来更新参数,并且使用adagrad的学习率更新方法进行网络中的所有参数的更新,获取最终的任意用户j的推文转发概率预测函数
10、利用步骤9所形成的推文转发概率预测函数
附图说明
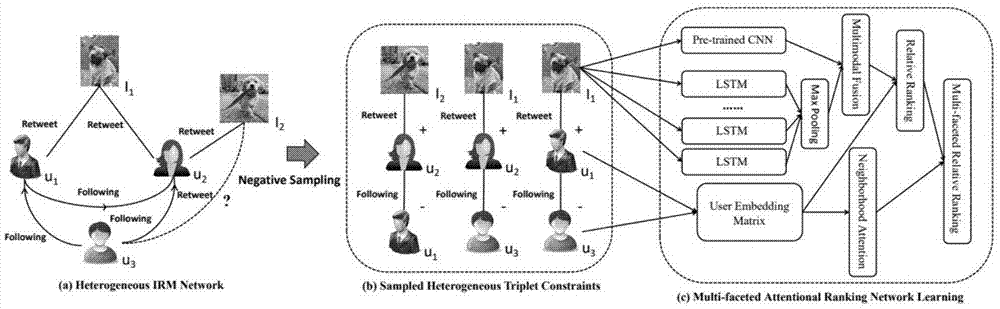
图1是本发明所使用的用于解决推文预测转发任务的多面排序网络模型。
具体实施方式
下面结合附图和具体实施方式对本发明做进一步阐述和说明。
如图1所示,本发明基于多面排序网络解决推文预测转发任务的方法包括如下步骤:
1)针对于一组社交网络用户及其对于的推文转发情况,构建包含用户、推文之间相互关系的社交媒体网络;
2)对于步骤1)所得到的社交媒体网络的带有图片的推文,利用卷积神经网络获取推文图片的表达,利用单词映射网络及lstm网络获取推文文本的语义表达,利用随机初始化获取用户的映射表达;之后结合推文的图片及文本表达获取推文的综合表达,利用推文的综合表达及用户的表达获取反映用户本身对于推文感兴趣程度大小的值;利用步骤1)构建的社交媒体网络中的用户之间相互关注的关系及用户表达矩阵,得到用户相互影响力分数,并利用该分数与用户表达及推文综合表达得到反映结合了用户之间相互影响的用户对于推文感兴趣程度的值;两者结合得到最终的损失函数;
3)利用所获得的含有用户推文转发关系及用户间关系的数据集,针对步骤2)所得的损失函数,经过训练,得到最终的损失函数,根据该函数可以对于任意用户及其关注的用户发出的任意推文进行排序,将更可能被用户转发的推文排在前列。
所述的步骤2)用于获取最终的用户转发推文概率的多面排序网络损失函数的具体步骤为:
2.1)对于所给出的推文,利用如下方法获取带有图片的推文的综合表达:对于推文中的图片,输入到卷积神经网络中获取对应图片的表达,对于图片ii,输入到卷积神经网络中获取其对应表达xi;对于给定的微博博文,将其单词通过预先训练好的单词映射网络获取其单词映射。对于由一个单词序列构成的微博博文di,设其第t个单词通过预先训练好的单词映射网络获取的单词映射为xit,则将序列(xi1,xi2,...,xik)作为微博博文xi的单词映射表达,之后,将博文di分成若干段,并将各段的单词映射序列作为lstm网络的输入,以lstm网络的最后一个隐藏层的输出作为该段博文的映射表达,之后将各段的输出同时输入一个最大池化层,将池化层的输出yi作为微博博文di的映射表达;
2.2)利用多模态混合函数来得到推文的图片与文本的混合表达,给定第i条推文的图片表达映射xi与推文中的文本表达yi,则该推文的综合表达如下:
zi=g(w(i)xi+w(d)yi)
其中,w(i)与w(d)为该混合函数用来混合推文的图片表达与文本表达的权重矩阵,g(.)为非线性的双曲正切激活函数;
2.3)通过随机初始化得到用户的映射矩阵u={u1,u2,...,ul},其中up代表了用户p的映射向量,利用如下公式获取用户p本身对于推文i的感兴趣程度大小值:
2.4)利用如下公式获取用户p受到其所关注的用户q的影响力大小:
spq=p·tanh(w(s)up+w(n)uq+b)
其中,up代表了用户p的映射向量,uq代表了用户p所关注的用户q的映射向量,w(s)与w(n)为用来反映用户q对于用户p影响力大小的权重矩阵,b为偏置向量,tanh(.)为非线性的双曲正切激活函数。p为用来计算影响力分数大小的参数向量;
针对于用户p会关注多个用户,则针对于用户p关注的用户集合np中的每一个用户q,用户q对于用户p的相对影响力分数大小为;
2.5)利用步骤2.4)获取的用户p对于用户q的影响力权重α,与步骤2.3)所得到的用户p本身对于推文i的感兴趣程度大小,得到用户p在其所关注的所有用户的影响下,对于推文i感兴趣程度的大小值为:
则结合步骤4所得到的用户p本身对于推文i的感兴趣程度大小
2.6)给定包含用户之间相互关注关系与用户推文的数据集合(j,i,k,nj),该集合表示用户j对于推文i的转发概率高于对于推文k的转发概率,且用户i所关注的用户集合为nj。同时给定步骤6所得的针对于数据集合(j,i,k,nj)中的所有用户j的转发概况函数
其中,
2.7)结合模型中所有参数作为损失项,可得到最终的损失函数如下:
其中,ψ为模型中的所有参数构成的集合,β为对于步骤7所得的带注意力机制的多模态排序损失函数损失项与模型参数值损失项的权衡参数,(j,i,k,nj)为模型对应的所有代表用户j对于推文i的转发概率高于对于推文k的转发概率的数据集合;
所述的步骤3)用于获取最终的用户转发推文排序结果的具体步骤为:
对于步骤2)中的最终的目标函数,本发明使用随机梯度下降的方法来更新参数,并且使用adagrad的学习率更新方法进行网络中的所有参数的更新,获取最终的任意用户j的推文转发概率预测函数
下面将上述方法应用于下列实施例中,以体现本发明的技术效果,实施例中具体步骤不再赘述。
实施例
本发明在所爬取的微博数据集上面进行实验验证。微博数据集中共包括9583条带图片的微博,包含10438个用户及其之间35211条相互关注关系,平均每个用户的转发博文数目为11.2,平均每条微博被转发的次数为14.1。
为了客观地评价本发明的算法的性能,本发明在所选出的测试集中,使用了precision@1,precision@3,auc来对于本发明的效果进行评价。按照具体实施方式中描述的步骤,所得的实验结果如表1、表2及表3所示,本发明所用的方法记为amnl,且分别针对于所有训练集的60%、70%、80%的训练数据作为最终训练集得到实验结果:
表1本发明针对于precision@1标准下的测试结果
表2本发明针对于precision@3标准下的测试结果
表3本发明针对于auc标准下的测试结果。
- 还没有人留言评论。精彩留言会获得点赞!