一种游戏场景描述方法、装置、设备及其存储介质与流程
本发明实施例涉及人工智能技术,尤其涉及一种游戏场景描述方法、装置、设备及其存储介质。
背景技术:
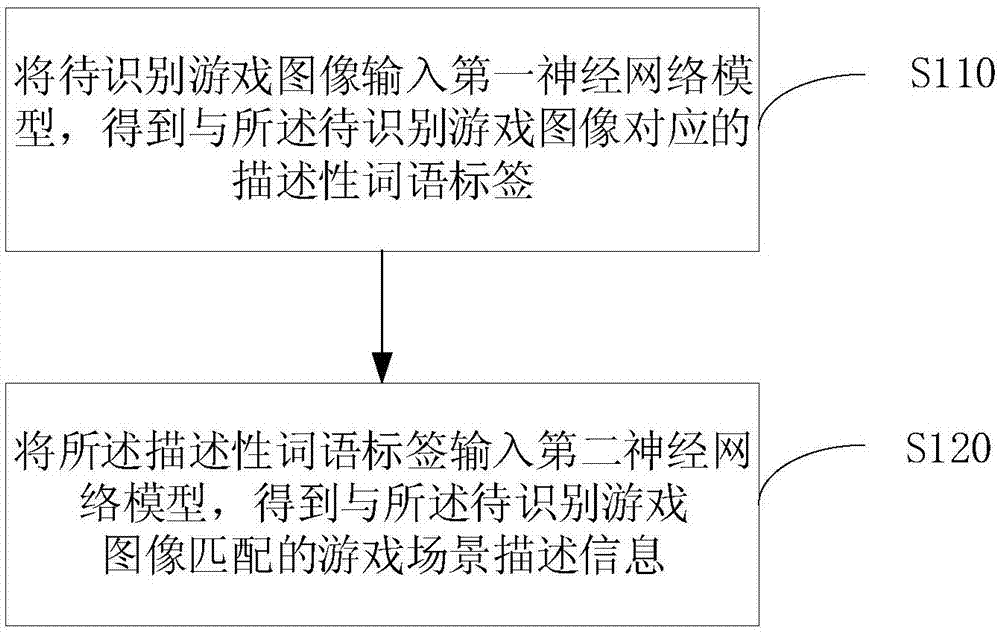
随着互联网技术的爆炸式发展,各种图像、视频和直播网站如雨后春笋般涌现。人们接触到的东西也渐渐由文字变成了图像、视频或直播等更具表现力的内容。这些网站会产生大量的图像、视频数据,图像比文字包含更多的信息。大量的图像和视频信息要求平台方更加高效的提供符合用户口味的内容,也要求及时把用户可能感兴趣的内容置顶,加大平台对用户的粘性。所有这些的前提就是需要视频提供平台对视频进行描述和分类。以对游戏直播中的场景进行描述为例,传统方法是依赖人工去辨识和分类。如招募大量熟悉游戏的客服人员观看游戏直播视频,识别直播中游戏的类型、游戏的名称;识别moba(multiplayeronlinebattlearena,多人在线战术竞技游戏)类游戏中玩家使用的游戏角色;识别第一人称射击类游戏中玩家携带的装备等。或者是通过跟踪观看某一游戏的直播,对游戏进行文字直播,如果要对游戏进行直播,一般需要通过多个客服人员同时观看游戏,对自己负责部分的场景进行描述,通过轮流打字,对游戏进行文字直播。使用客服人员对游戏进行打标签和场景描述,虽然也能获得很高的精度(约99%)。但人工识别的速度约10fps(framespersecond,每秒传输帧数),同时人工的文字输入速度也较低。因此,使用人工识别游戏场景的实施成本很高,效率低下。技术实现要素:本发明提供一种游戏场景描述方法、装置、设备及其存储介质,以实现自动识别视频直播平台主播正在进行的直播游戏,自动对直播间进行分类,自动对游戏场景进行文字直播。第一方面,本发明实施例提供了一种游戏场景描述方法,包括:将待识别游戏图像输入第一神经网络模型,得到与所述待识别游戏图像对应的描述性词语标签;将所述描述性词语标签输入第二神经网络模型,得到与所述待识别游戏图像匹配的游戏场景描述信息;其中,所述第一神经网络模型包括:特征提取网络子模型以及目标探测网络子模型;所述特征提取网络子模型用于对输入的图像进行图像特征提取并输入至所述目标探测网络子模型,所述目标探测网络子模型用于对输入的图像特征进行检测,得到与图像特征对应的描述性词语标签。第二方面,本发明实施例还提供了一种游戏场景描述装置,包括:词语标签获取模块,用于将待识别游戏图像输入第一神经网络模型,得到与所述待识别游戏图像对应的描述性词语标签;场景信息获取模块,用于将所述描述性词语标签输入第二神经网络模型,得到与所述待识别游戏图像匹配的游戏场景描述信息;其中,所述第一神经网络模型包括:特征提取网络子模型以及目标探测网络子模型;所述特征提取网络子模型用于对输入的图像进行图像特征提取并输入至所述目标探测网络子模型,所述目标探测网络子模型用于对输入的图像特征进行检测,得到与图像特征对应的描述性词语标签。第三方面,本发明实施例还提供了一种设备,包括:一个或多个处理器;存储器,用于存储一个或多个程序;当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现如实施例任一所述的一种游戏场景描述方法。第四方面,本发明实施例还提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现如实施例任一所述的一种游戏场景描述方法。本发明通过构建神经网络,解决游戏视频直播过程中需要人工对游戏直播间中的场景进行描述和分类的问题,实现自动识别视频直播平台主播正在进行的直播游戏,自动对直播间进行分类等,以及自动对游戏场景进行文字直播。附图说明图1为本发明实施例一提供的一种游戏场景描述方法的流程图;图2为本发明实施例一提供的英雄联盟游戏的一张游戏画面;图3为本发明实施例二提供的一种游戏场景描述方法的流程图;图4为本发明实施例二提供的训练样本集中一张王者荣耀游戏的游戏图片;图5为本发明实施例二提供的训练样本集中一张王者荣耀游戏的游戏图片;图6为本发明实施例二提供的训练样本集中一张王者荣耀游戏的游戏图片;图7为本发明实施例二提供的训练样本集中一张王者荣耀游戏的游戏图片;图8为本发明实施例二提供的训练样本集中一张王者荣耀游戏的游戏图片;图9为本发明实施例二提供的一种vgg-16神经网络模型的结构示意图;图10为本发明实施例二提供的一种通过标准神经网络模型提取图像的效果示意图;图11是本发明实施例二提供的一种神经网络的结构示意图;图12为本发明实施例二提供的一种训练得到第一神经网络模型的示意图;图13为本发明实施例二提供的一种训练得到第二神经网络模型的示意图;图14为本发明实施例三提供的一种游戏场景描述方法的流程图;图15为本发明实施例三提供的游戏直播间列表的示意图;图16为本发明实施例三提供的游戏直播间游戏画面的一张截图;图17为本发明实施例三提供的游戏直播间游戏画面的一张截图;图18为本发明实施例四提供的一种游戏场景描述装置的结构图;图19为本发明实施例五提供的一种设备的结构示意图。具体实施方式下面结合附图和实施例对本发明作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释本发明,而非对本发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与本发明相关的部分而非全部结构。实施例一图1为本发明实施例一提供的一种游戏场景描述方法的流程图。该方法基于人工智能领域各类技术的运用,尤其是图像识别技术和自然语言处理技术的运用和构造。该方法可以由一种游戏场景描述装置来执行,该装置可以通过软件和/或硬件的方式实现,并集成在设备中。其中,图像识别技术是以图像的主要特征为基础的。每个图像都有它的特征,如字母a有个尖,p有个圈,y的中心有个锐角等。对图像识别时眼动的研究表明,视线总是集中在图像的主要特征上,也就是集中在图像轮廓曲度最大或轮廓方向突然改变的地方,这些地方的信息量最大。而且眼睛的扫描路线也总是依次从一个特征转到另一个特征上。由此可见,在图像识别过程中,知觉机制必须排除输入的多余信息,抽出关键的信息。自然语言处理技术在本方案中主要运用到了以下三种技术:1、句法语义分析:对于给定的句子,进行分词、词性标记、命名实体识别和链接、句法分析、语义角色识别和多义词消歧。2、信息抽取:从给定文本中抽取重要的信息,比如,抽取的信息可以是时间、地点、人物、事件、原因、结果、数字、日期、货币以及专有名词等等。通俗说来,就是要了解谁在什么时候、什么原因、对谁、做了什么事以及有什么结果。涉及到实体识别、时间抽取和因果关系抽取等关键技术。3、文本挖掘(或者文本数据挖掘):包括文本聚类、分类、信息抽取、摘要、情感分析以及对挖掘的信息和知识的可视化和交互式的表达界面。目前主流的技术都是基于统计机器学习的。结合图1,本实施例具体包括如下步骤:s110、将待识别游戏图像输入第一神经网络模型,得到与所述待识别游戏图像对应的描述性词语标签。其中,游戏图像是指从与至少一个游戏直播间对应的直播视频流中获取的视频帧,并将经过预处理后的所述视频帧作为所述待识别游戏图像。描述性词语标签是指包括下述至少一项信息的标签,该信息包括:游戏角色名、游戏成就信息、游戏进程描述信息以及游戏状态信息。该信息具体包括的内容,可以根据游戏的发展进行添加和修改。描述性词语标签的种类可以根据视频直播平台需求以及服务器和处理器的实际承载能力进行调整。神经网络模型是一种模仿动物神经网络行为特征,进行分布式并行信息处理的算法模型,通过调整模型内部大量节点之间相互连接关系,达到处理信息的目的。可选的,第一神经网络为卷积神经网络,卷积神经网络(convolutionalneuralnetwork,cnn)是一种前馈神经网络,至少包括卷积层和归一化层。应当理解,除了卷积神经网络之外,第一神经网络还可为非卷积类型的神经网络,神经网络的网络结构除了上述列举的例子之外,还可选用层数、层、不同卷积核和/或权重等网络参数的其他网络结构。其中,本实施例中第一神经网络模型包括:特征提取网络子模型以及目标探测网络子模型;特征提取网络子模型用于对输入的图像进行图像特征提取并输入至所述目标探测网络子模型,目标探测网络子模型用于对输入的图像特征进行检测,得到与图像特征对应的描述性词语标签。具体的,一张待识别的游戏图像输入到第一神经网络中,首先,特征提取网络子模型对输入的待识别游戏图像进行图像特征提取,并将提取出的图像特征结果作为目标探测网络子模型的输入,目标探测网络子模型根据图像特征匹配相关的一个或多个描述性词语标签。图2为本发明实施例一提供的英雄联盟游戏的一张游戏画面,参考图2,以该画面为待识别游戏图像,将该图像输入第一神经网络,在描述性词语标签包括以下所有信息(游戏角色名、游戏成就信息、游戏进程描述信息以及游戏状态信息)时,输出描述性词语标签如下表:表一游戏角色名寒冰射手/艾希/……游戏成就信息五杀/……游戏进程描述信息大乱斗/二塔/左开/……游戏状态信息残血/大招冷却/存活/……可选的,对输出的描述性词语进行刷选,如按照游戏角色名,游戏成就信息(如:三杀、四杀、五杀或超神等)以及游戏状态描述(残血或团战等)进行筛选,并将筛选后的描述性词语标签作为待识别游戏图像聚类的依据。s120、将所述描述性词语标签输入第二神经网络模型,得到与所述待识别游戏图像匹配的游戏场景描述信息。其中,第二神经网络模型根据以下两种方式进行构建。第一,对图像特征进行分析,识别图片中存在的物体以及物体之间所具有的动作关系。然后采用固定的语言模板,如主语+动词+宾语,具体为从所识别物体中确定主语和宾语以及将物体之间的动作关系作为谓语,采用这样的方式生成句子对图像的描述;第二,构造递归神经网络模型得到对待识别游戏图像的游戏场景的描述。第二神经网络是预先训练得到的,通过训练过程调整第二神经网络的网络参数,使得第二神经网络具有针对描述性词语标签的归类、加权计算等处理能力。本发明实施例对第二神经网络的具体训练方法并不限制,本领域技术人员可采用监督、半监督、无监督或者满足深度特征信息处理的任务需求的其他训练方法训练第二神经网络。具体的,当表一的描述性词语标签输入第二神经网络模型后,第二神经网络给出输出结果可能如表二所示:表二1残血艾希五杀2大乱斗艾希二塔五杀,残血存活…………n-1寒冰射手二塔残血n残血寒冰五杀,大招冷却中第二神经网络模型对上述场景描述进行权重的判断,比如“五杀”这一游戏成就信的权重较高,则可能优先选择输出“残血艾希五杀”作为与待识别游戏图像匹配的游戏场景描述信息。本发明通过构建神经网络,解决需要人工对游戏图像进行分类、打标签和对游戏场景进行描述的问题,实现了持续地给出高精度、高效率且不依赖人工的描述性词语标签和游戏场景描述,极大地方便了直播平台对游戏视频直播间进行聚类和输出对游戏场景的文字描述。实施例二图3为本发明实施例二提供的一种游戏场景描述方法的流程图。本实施例是在上述实施例的基础上进行的细化。主要描述了构造和训练第一神经网络模型和第二神经网络模型的过程。具体的:在将待识别游戏图像输入第一神经网络模型,得到与所述待识别游戏图像对应的描述性词语标签之前,还包括:获取训练样本集,所述训练样本集包括:多张游戏图片,以及与游戏图片对应的游戏场景描述信息以及描述性词语标签;使用标准神经网络模型,对所述训练样本集中的游戏图片的神经网络特征进行提取,得到游戏图片的图像特征;将游戏图片的图像特征与游戏图片的描述性词语标签进行交叉匹配,得到与游戏图片的图像特征对应的描述性词语标签;根据所述游戏图片的图像特征,以及与游戏图片的图像特征对应的描述性词语标签,训练得到所述第一神经网络模型;根据与游戏图片对应的游戏场景描述信息以及描述性词语标签,训练得到所述第二神经网络模型。所述游戏图片的描述性词语标签,通过对所述游戏图片的游戏场景描述信息进行分词得到。所述描述性词语标签包括下述至少一项:游戏角色名、游戏成就信息、游戏进程描述信息以及游戏状态信息。参考图3,本实施例提供的具体方法包括:s210、获取训练样本集。其中,训练样本集包括:多张游戏图片,以及与游戏图片对应的游戏场景描述信息以及描述性词语标签。多张游戏图片可以为通过网络获取的游戏图像;或者,可以为游戏直播间视频序列中的视频帧图像。游戏图片对应的游戏场景描述信息是指通过自然语言对游戏图片描述产生的信息。图4、图5、图6、图7和图8分别为本发明实施例二提供的训练样本集中部分王者荣耀游戏的游戏图片,其对应的游戏场景描述信息如表三所示。表三其中,通过对所述游戏图片的游戏场景描述信息进行分词处理,得到游戏图片的描述性词语标签。中文分词是文本挖掘的基础,对于输入的一段中文,成功的进行中文分词,可以达到电脑自动识别语句含义的效果。现有的分词算法可分为三大类:基于字符串匹配的分词方法、基于理解的分词方法和基于统计的分词方法。按照是否与词性标注过程相结合,又可以分为单纯分词方法和分词与标注相结合的一体化方法。本实施例对采用何种分词方式不作限制。描述性词语标签包括下述至少一项:游戏角色名、游戏成就信息、游戏进程描述信息以及游戏状态信息。以描述性词语标签包括游戏角色名(细分为:游戏角色和游戏场景)、游戏成就信息(系统弹出特殊图标的成就)、游戏进程描述信息(细分为:推塔信息和英雄位置)以及游戏状态信息(细分为:血条和是否死亡)为例,针对表三中图片的游戏场景描述信息进行分词处理,获得的描述性词语标签如表四所示。表四具体的,获取训练样本集,样本集包括多张游戏图片和与游戏图片对应的游戏场景描述信息,将与游戏图片对应的游戏场景描述信息进行分词处理,得到与游戏场景描述信息相对应的描述性词语标签。可选的,可以对构造的训练集进行处理,预先对游戏图片中不同元素进行切割处理,使得单个元素包含的信息量减少。以图4为例,可以将图4进行裁剪,只保留含有大量游戏细节的部分,如:游戏角色韩信212、游戏角色王昭君211和游戏成就213,分别对应进行文字描述:韩信、王昭君和五杀。s220、使用标准神经网络模型,对所述训练样本集中的游戏图片的神经网络特征进行提取,得到游戏图片的图像特征。其中,使用的标准神经网络模型可以是vgg(visualgeometrygroup)神经网络模型、残差网络(resnet)模型、移动网络(mobilenet)模型或混洗网络(shufflenet)模型中的一个或多个。以使用vgg-16神经网络模型作为标准神经网络模型为例,图9为本发明实施例二提供的vgg-16神经网络模型的结构示意图。参见图9,vgg-16神经网络模型的输入为固定大小的rgb格式图像,示例性的,卷积层3-64表示为卷积层的卷积核为3×3,输出通道数为64。vgg-16神经网络模型整体使用的卷积核比较小(3×3),其中(3×3)是可以表示图像左右、上下和中心这些模式最小的单元。使用多个较小的卷积核的卷积层代替一个卷积核较大的卷积层,一方面可以减少参数,另一方面相当于进行了更多的非线性映射,可以增加网络的拟合和表达能力。内容特征图指的游戏图片经过vgg-16神经网络模型中各层运算后所提取出的特征矩阵。该特征矩阵,即内容特征图,用于表示游戏图片的抽象特征,即用于表示游戏图片的内容。示例性的,该抽象特征可以包括游戏图片的边缘信息和颜色信息等。其中,relu(rectifiedlinearunits,激活函数)用于增加神经网络模型的非线性因素,提高损失函数梯度反传过程中梯度计算的准确度。将图片输入vgg-16神经网络模型之前,要对图片进行预处理,可以将图片中每一个像素减去均值。vgg-16神经网络模型要求输入图片格式为(224×224×3),即边长为224像素的rgb表现形式的图片。当输入图片的边长大于224(像素)时,可以在[smin,smax]scale(预设的图片最大值与图片最小值)上,随机选择一个scale(范围),然后提取224×224×3格式的图片。图10为本发明实施例二提供的通过标准神经网络模型提取图像的效果示意图。参考图10,201是英雄联盟游戏角色“德玛西亚皇子”的头像截图,该截图进过处理,符合(224×224×3)的格式要求,202是经过vgg-16神经网络模型提取特征之后,“德玛西亚皇子”的图像特征。vgg-16神经网络模型处理图片后的输出结果为向量,将该向量进行转化,可以获得人类可以识别的图片这一表象形式。具体的,将训练集中的游戏图片或处理之后的游戏图片元素输入标准神经网络模型,得到游戏图片的图像特征,得到的图像特征会根据使用的提取特征网络子模型的构造或配置参数的不同而有所不同。s230、将游戏图片的图像特征与游戏图片的描述性词语标签进行交叉匹配,得到与游戏图片的图像特征对应的描述性词语标签。其中,交叉匹配是指通过对大量数据的分析和检索,得到图像特征与描述性词语之间的映射关系的过程。以图4为例,图4中至少包括游戏角色王昭君211(该部分通过处理会得到游戏角色王昭君211对应的图像特征)和游戏角色韩信212(该部分通过处理会得到游戏角色韩信212对应的图像特征),以及至少包括“王昭君”、“韩信”和“野区”等描述性词语标签,但是通过这一张图片,并不知道游戏图片的图像特征与游戏图片的描述性词语标签之间的对应关系,即游戏角色王昭君211处理后的图像特征可能对应于“王昭君”、“韩信”和“野区”中任意一个或多个描述性词语标签。通过多张游戏图片的图像特征与与其对应的描述性词语标签之间的容错匹配和整合,能得到与游戏图片的图像特征对应的描述性词语标签。如一百张游戏图片中均有游戏角色妲己的图像特征以及其他随意出现的图像特征,一百张游戏图片中每张关联的描述性词语标签均含有“妲己”以及其他,通过交叉匹配可以建立小于100个游戏角色妲己的图像特征(相似度到达一定程度会保存为同一个图像特征)与描述性词语标签均“妲己”的联系。具体的,每张输入的游戏图片经过标准神经网络模型的处理会输出多个图像特征;进过分词处理,每张输入游戏图片的游戏场景描述信息会转化为描述性词语标签。将图像特征与描述性词语标签进行交叉匹配,形成一定的映射关系。该映射关系不一定是一一对应的,如图4中的游戏成就图像特征213对应于唯一的描述性词语标签“五杀”,但是图4中的游戏角色王昭君图像特征211可能对应于“王昭君”这一描述性词语标签,也可能对应于“昭君”这一描述性词语标签,同样的“王昭君”这一描述性词语标签不仅仅对应于王昭君图像特征211,也可能是游戏角色“王昭君”的不同角度、不同皮肤甚至不同图像大小情况下的图像特征。s240、根据所述游戏图片的图像特征,以及与游戏图片的图像特征对应的描述性词语标签,训练得到所述第一神经网络模型。其中,第一神经网络模型包括:依次对输入的图像进行处理的下采样卷积子网络、卷积或残差子网络、以及上采样卷积子网络,上采样卷积子网络包括双线性插值层和卷积层。示例性的,参见图11,图11是本发明实施例提供的一种神经网络的结构示意图,其中神经网络例如可以是11层神经网络,包括底层三层卷积神经子网络,用于对输入图像进行下采样,中间五层残差子网络,用于对下采样图像进行残差计算,顶层三层卷积神经子网络,用于对图像进行上采样。每一个卷积层和残差网络均由多个卷积滤波器组成,每个卷积滤波器后均连接有bn(batchnormalization,归一化层)和relu(rectifiedlinearunits,激活函数)层。可选的,顶层三层卷积神经网络中的前两层包括双线性差值和卷积层,其中,每一层的双线性差值的放大倍数例如可以是2。需要说明的是,图11中的神经网络仅是一种可选实例,各子网络的层数以及每一个卷积层的卷积滤波器的数量可以根据实际应用需求设置,其中,实际应用需求包括但不限于图像处理效果和处理速度,本发明实施例对此并不限制。具体的,图12为本发明实施例二提供的训练得到第一神经网络模型的示意图。将游戏图片的图像特征与其对应的描述性词语标签作为训练第一神经网络模型的样本,不断训练并修正第一神经网络。s250、根据与游戏图片对应的游戏场景描述信息以及描述性词语标签,训练得到所述第二神经网络模型。其中,第二神经网络模型是一种语言处理模型,作用是将描述性词语标签进行筛选和组合,输出游戏场景描述信息。图13为本发明实施例二提供的训练得到第二神经网络模型的示意图。如多人对图4进行游戏场景描述,结果如表五所示:表五描述编号游戏场景描述信息001韩信敌方下路野区五杀002韩信carry全场17杀0死并获五杀003韩信满血获五杀004韩信单杀对面五人用一张游戏图片的描述性词语标签和大数据采集的如表五所述的游戏场景描述信息训练和修正第二神经网络模型,直到输出符合人类描述习惯的语言描述。应当理解,上述第一神经网络模型和第二神经网络模型,可以是卷积神经网络,还可为非卷积类型的神经网络,神经网络的网络结构除了上述列举的例子之外,还可选用层数、层、不同卷积核和/或权重等网络参数的其他网络结构。可选的,由于符合人类描述习惯的语言描述一般需要包括大量细节,可以控制第二神经网络模型输出的游戏场景描述信息的字数,输出符合一定阈值的游戏场景描述信息。也可以将生成的游戏场景描述信息按照相关度进行排序,取一定相关度范围内,最长的游戏场景描述信息作为输出结果。以将图4输入第一神经网络模型和第二神经网络模型为例,可能输出如表六中的游戏场景描述信息,并将该信息按照相关度进行排序。表六描述编号游戏场景描述信息001韩信五杀002韩信野区五杀003满血韩信五杀0040死亡韩信野区五杀表六中编号001-编号004的游戏场景描述信息与图4的相关度匹配均在90%以上,则可以选择输出编号004的“0死亡韩信野区五杀”作为图4的游戏场景描述信息。本发明通过构建神经网络模型,对神经网络模型进行训练。通过第一神经网络模型可对输入的游戏图像输出文字标签,便于分类处理;通过第二神经网络模型再对描述性词语标签(即文字标签)进行处理,输出符合人类认知的对游戏场景的自然语言描述。解决需要人工对游戏图像进行分类、标签和描述的问题,极大地方便了直播平台对游戏视频直播间进行聚类和输出对游戏场景的文字描述。实施例三图14为本发明实施例三提供的一种游戏场景描述方法的流程图。本实施例是在上述实施例的基础上进行的细化。具体的:在将待识别游戏图像输入第一神经网络模型,得到与所述待识别游戏图像对应的描述性词语标签之前,还包括:从与至少一个游戏直播间对应的直播视频流中获取视频帧,并将经过预处理后的所述视频帧作为所述待识别游戏图像;其中,所述预处理操作包括下述至少一项:缩放、裁剪以及旋转。在将待识别游戏图像输入第一神经网络模型,得到与所述待识别游戏图像对应的描述性词语标签之后,还包括:建立待识别游戏图像的描述性词语标签,以及待识别游戏图像的游戏直播间之间的对应关系;根据与至少两个游戏直播间分别对应的描述性词语标签对所述至少两个游戏直播间进行聚类处理;根据聚类处理结果,在设定直播平台中显示所述至少两个游戏直播间。将所述描述性词语标签输入第二神经网络模型,得到与所述待识别游戏图像匹配的游戏场景描述信息之后,包括:对于选定游戏直播间,对应显示与所述游戏直播间对应的所述游戏场景描述信息。参考图14,本实施例提供的具体方法包括:s310、从与至少一个游戏直播间对应的直播视频流中获取视频帧,并将经过预处理后的所述视频帧作为所述待识别游戏图像。其中,在视频直播平台,有多个视频直播间,每个直播间对应一个主播。以游戏直播为例,主播可以选择是否在直播中显示自己视频信息,若选择不显示自己视频信息,则直播中只显示主播进行游戏时的游戏界面;若选择显示自己视频信息,则可以在任意位置放置视频窗口显示自己视频信息。其中,预处理操作包括下述至少一项:缩放、裁剪以及旋转。预处理是为了使输入第一神经网络模型的游戏图片更加符合第一神经网络模型识别的方式。具体的,待识别游戏图像的输入可以为30fps,实际应用一般为5fps为优,选择一定速度,选择待识别游戏图像,判断选取的待识别游戏图像是否符合第一神经网络的识别习惯,即是否在第一神经网络模型的容错范围内,这一步骤可以提高第一神经网络模型输出结果的准确性。如果待识别游戏图像不符合第一神经网络的识别习惯,则对待识别游戏图像进行预处理,如进行缩放、裁剪或者旋转处理。s320、将待识别游戏图像输入第一神经网络模型,得到与所述待识别游戏图像对应的描述性词语标签。s330、建立待识别游戏图像的描述性词语标签,以及待识别游戏图像的游戏直播间之间的对应关系。其中,待识别游戏图像的描述性词语标签中的描述性词语标签可以是经过筛选的、具有大量信息的标签。由于待识别游戏图像来自于游戏直播间,所以对待识别游戏图像的描述性词语标签即是对游戏直播间某一时刻状态的描述。具体的,以图7为例,将该图片输入第一神经网络模型,可能出现的描述性词语标签有:露娜、中路、敌方二塔、半血和三杀等。这些描述性词语标签归属于不同的种类,大致可分类到:游戏角色名、游戏成就信息、游戏进程描述信息以及游戏状态信息。可以认为游戏角色名以及游戏成就信息包含的信息量大,于是可以输出短标签:三杀,也可以输出标签:露娜中路三杀。描述性词语标签输出方式可以由直播平台方自行设定。s331、根据与至少两个游戏直播间分别对应的描述性词语标签对所述至少两个游戏直播间进行聚类处理。其中,描述性词语标签包括下述至少一项:游戏角色名、游戏成就信息、游戏进程描述信息以及游戏状态信息。可以根据任意一项进行聚类,比如:某一时刻有编号001到编号058的58个直播间在进行游戏直播,其中编号006、007、029、031、041、051、055和057这八个直播间的主播使用射手类英雄,其中有编号006、007、029和051这四个直播间的主播使用英雄马可波罗,则将这八个游戏直播间聚类到射手类英雄,将这四个直播间聚类到英雄马可波罗。同时编号001到编号058的58个直播间中编号005、031和055这三个直播间分别检测到游戏成就信息:三杀、四杀和三杀,则将这三个直播间聚类到精彩局势。具体的,如图4所示的游戏画面,起码具有描述性词语标签:五杀、韩信、刺客、战士、野区等,则图4所示的游戏画面所在的直播间此时会被聚类到:精彩局势、韩信、刺客和战士这四个类别。s332、根据聚类处理结果,在设定直播平台中显示所述至少两个游戏直播间。具体的,某一时刻有编号001到编号058的58个直播间在进行游戏直播,其中有编号006、007、029和051这四个直播间的主播使用英雄马可波罗。则在马可波罗这个类别下面显示上述四个直播间。s340、将所述描述性词语标签输入第二神经网络模型,得到与所述待识别游戏图像匹配的游戏场景描述信息。s341、对于选定游戏直播间,对应显示与所述游戏直播间对应的所述游戏场景描述信息。其中,选定游戏直播间既可以是平台选定游戏直播间,也可以是用户选定直播间。具体的,当选定游戏直播间后,按照一定的频率将该选定游戏直播间的游戏画面输入第一神经网络,将第一神经网络输出的描述性词语标签输入第二神经网络,输出该选定游戏直播间的游戏场景描述信息。图15为本发明实施例三提供的游戏直播间列表的示意图,若用户选择直播间31作为选定直播间,则通过点击进入直播间31。图16和图17均为本发明实施例三提供的游戏直播间游戏画面的截图。当用户选择直播间31作为选定游戏直播间时,游戏场景描述装置在一秒内获取2张截图(每秒获得的游戏截图数可以设定,此处以两张为例进行描述)。游戏场景描述装置对图16描述为“花木兰下路单挑凯”“诸葛亮上路呼叫集合”等,对图17的描述为“花木兰下路被墨子和凯围攻”“敌方典韦上路三杀”等。若用户设置为每一秒进行一次场景描述,则游戏场景描述装置判定对图16和图17的场景描述信息的权重进行判定,并输出权重较高的游戏场景描述作为游戏场景描述信息,如输出“敌方典韦上路三杀”作为这一秒的游戏场景的描述信息。该游戏场景描述信息具体通过何种方式进行展示,本实施例不做限制。结合手机用户的习惯,该游戏场景描述信息可以在文字展示框32进行每秒一次的滚动展示。若平台选择某一直播间为选定直播间。这里的“选定”可以是平台客服人员手动选择,可以是某一直播间的主播到达平台设定的某一标准,也可以是或该直播间直播的内容达到某一标准。若直播间33为平台选择的选定直播间,则直播间33下方的文字展示框34自动进行游戏场景描述信息的滚动展示。本发明通过构建神经网络,解决需要人工对游戏图像进行分类、标签和描述的问题,实现了持续地给出高精度、高效率且不依赖人工的描述性词语标签和游戏场景描述,极大地方便了直播平台对游戏视频直播间进行聚类和输出对游戏场景的文字描述。用户可以在不点击进入某一直播间的情况下了解直播间的直播状况,便于用户选择感兴趣的直播间,提高用户体验。实施例四图18为本发明实施例四提供的一种游戏场景描述装置的结构图。该装置包括:词语标签获取模块41和场景信息获取模块42。词语标签获取模块41,用于将待识别游戏图像输入第一神经网络模型,得到与所述待识别游戏图像对应的描述性词语标签;场景信息获取模块42,用于将所述描述性词语标签输入第二神经网络模型,得到与所述待识别游戏图像匹配的游戏场景描述信息;其中,所述第一神经网络模型包括:特征提取网络子模型以及目标探测网络子模型;所述特征提取网络子模型用于对输入的图像进行图像特征提取并输入至所述目标探测网络子模型,所述目标探测网络子模型用于对输入的图像特征进行检测,得到与图像特征对应的描述性词语标签。本发明通过构建神经网络,解决需要人工对游戏图像进行分类、标签和描述的问题,实现了持续地给出高精度、高效率且不依赖人工的描述性词语标签和游戏场景描述,极大地方便了直播平台对游戏视频直播间进行聚类和输出对游戏场景的文字描述。在上述实施例的基础上,还包括:训练集构造模块,用于获取训练样本集,所述训练样本集包括:多张游戏图片,以及与游戏图片对应的游戏场景描述信息以及描述性词语标签;所述游戏图片的描述性词语标签,通过对所述游戏图片的游戏场景描述信息进行分词得到;所述描述性词语标签包括下述至少一项:游戏角色名、游戏成就信息、游戏进程描述信息以及游戏状态信息;图像特征提取模块,用于使用标准神经网络模型,对所述训练样本集中的游戏图片的神经网络特征进行提取,得到游戏图片的图像特征;交叉匹配模块,用于将游戏图片的图像特征与游戏图片的描述性词语标签进行交叉匹配,得到与游戏图片的图像特征对应的描述性词语标签;第一神经网络训练模块,用于根据所述游戏图片的图像特征,以及与游戏图片的图像特征对应的描述性词语标签,训练得到所述第一神经网络模型;第二神经网络训练模块,用于根据与游戏图片对应的游戏场景描述信息以及描述性词语标签,训练得到所述第二神经网络模型。在上述实施例的基础上还包括:图像获取模块,用于从与至少一个游戏直播间对应的直播视频流中获取视频帧,并将经过预处理后的所述视频帧作为所述待识别游戏图像;其中,所述预处理操作包括下述至少一项:缩放、裁剪以及旋转。在上述实施例的基础上还包括:对应关系建立模块,用于建立待识别游戏图像的描述性词语标签,以及待识别游戏图像的游戏直播间之间的对应关系;聚类处理模块,用于根据与至少两个游戏直播间分别对应的描述性词语标签对所述至少两个游戏直播间进行聚类处理;直播间显示模块,用于根据聚类处理结果,在设定直播平台中显示所述至少两个游戏直播间。在上述实施例的基础上还包括:场景描述模块,用于对于选定游戏直播间,对应显示与所述游戏直播间对应的所述游戏场景描述信息。本实施例提供的一种游戏场景描述装置可用于执行上述任一实施例提供的一种游戏场景描述方法,具有相应的功能和有益效果。实施例五图19为本发明实施例五提供的一种设备的结构示意图。如图19所示,该设备包括处理器40、存储器51、通信模块52、输入装置53和输出装置54;设备中处理器50的数量可以是一个或多个,图19中以一个处理器50为例;设备中的处理器50、存储器51、通信模块52、输入装置53和输出装置54可以通过总线或其他方式连接,图19中以通过总线连接为例。存储器51作为一种计算机可读存储介质,可用于存储软件程序、计算机可执行程序以及模块,如本实施例中的一种游戏场景描述方法对应的模块(例如,一种游戏场景描述装置中的词语标签获取模块41和场景信息获取模块42)。处理器50通过运行存储在存储器51中的软件程序、指令以及模块,从而执行设备的各种功能应用以及数据处理,即实现上述的一种游戏场景描述方法。存储器51可主要包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需的应用程序;存储数据区可存储根据设备的使用所创建的数据等。此外,存储器51可以包括高速随机存取存储器,还可以包括非易失性存储器,例如至少一个磁盘存储器件、闪存器件、或其他非易失性固态存储器件。在一些实例中,存储器51可进一步包括相对于处理器50远程设置的存储器,这些远程存储器可以通过网络连接至设备。上述网络的实例包括但不限于互联网、企业内部网、局域网、移动通信网及其组合。通信模块52,用于与显示屏建立连接,并实现与显示屏的数据交互。输入装置53可用于接收输入的数字或字符信息,以及产生与设备的用户设置以及功能控制有关的键信号输入。输出装置54还可包括音箱等设备,也可包括其他可用于输出的装置。本实施例提供的一种设备,可执行本发明任一实施例提供的一种游戏场景描述方法,具体相应的功能和有益效果。实施例六本发明实施例六还提供一种包含计算机可执行指令的存储介质,所述计算机可执行指令在由计算机处理器执行时用于执行一种游戏场景描述方法,该方法包括:将待识别游戏图像输入第一神经网络模型,得到与所述待识别游戏图像对应的描述性词语标签;将所述描述性词语标签输入第二神经网络模型,得到与所述待识别游戏图像匹配的游戏场景描述信息;其中,所述第一神经网络模型包括:特征提取网络子模型以及目标探测网络子模型;所述特征提取网络子模型用于对输入的图像进行图像特征提取并输入至所述目标探测网络子模型,所述目标探测网络子模型用于对输入的图像特征进行检测,得到与图像特征对应的描述性词语标签。当然,本发明实施例所提供的一种包含计算机可执行指令的存储介质,其计算机可执行指令不限于如上所述的方法操作,还可以执行本发明任一实施例所提供的一种游戏场景描述方法中的相关操作。通过以上关于实施方式的描述,所属领域的技术人员可以清楚地了解到,本发明可借助软件及必需的通用硬件来实现,当然也可以通过硬件实现,但很多情况下前者是更佳的实施方式。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品可以存储在计算机可读存储介质中,如计算机的软盘、只读存储器(read-onlymemory,rom)、随机存取存储器(randomaccessmemory,ram)、闪存(flash)、硬盘或光盘等,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例所述的方法。值得注意的是,上述一种游戏场景描述装置的实施例中,所包括的各个单元和模块只是按照功能逻辑进行划分的,但并不局限于上述的划分,只要能够实现相应的功能即可;另外,各功能单元的具体名称也只是为了便于相互区分,并不用于限制本发明的保护范围。注意,上述仅为本发明的较佳实施例及所运用技术原理。本领域技术人员会理解,本发明不限于这里所述的特定实施例,对本领域技术人员来说能够进行各种明显的变化、重新调整和替代而不会脱离本发明的保护范围。因此,虽然通过以上实施例对本发明进行了较为详细的说明,但是本发明不仅仅限于以上实施例,在不脱离本发明构思的情况下,还可以包括更多其他等效实施例,而本发明的范围由所附的权利要求范围决定。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1