一种基于地平面假设的视觉惯导SLAM方法与流程
本发明涉及一种定位及建图技术,具体为一种基于地平面假设的视觉惯导slam方法。
背景技术:
slam全称是同时定位和地图构建,由摄像头实时采集图像,通过一帧帧的图像估计相机的运动轨迹,并重建相机运动场景的地图。传统视觉slam使用场景中颜色变化明显的点、线作为地图的路标点,没有任何实际含义,也没有任何的上下文语义,在商场环境中受光照和行人遮挡影响严重。为了让机器人在室内外环境自由移动,为了ar应用能够更加真实的与场景融为一体,slam成为近年研究的热点,而单目相机体积小、成本低,能够方便的嵌入其他设备中等优点逐渐成为关注的焦点。但是传统的基于纯视觉的slam受到光照变化和遮挡后精度和连贯性上面都会明显下降。
技术实现要素:
针对现有技术中基于纯视觉的slam受到光照变化和遮挡后精度和连贯性明显下降等不足,本发明要解决的问题是提供一种定位鲁棒性、连续性更强,可恢复真实尺度的基于地平面假设的视觉惯导slam方法。
为解决上述技术问题,本发明采用的技术方案是:
本发明一种基于地平面假设的视觉惯导slam方法,包括以下步骤:
1)从一图像中提取特征点,对上述特征点进行imu预积分,建立相机投影模型,并进行相机内参标定、imu和相机之间的外参标定;
2)基于地面标识物的visual-inertialslam系统的初始化,将视觉观测到的点云和相机位姿对齐到imu预积分上,并且用地面上的已知尺寸、坐标的标识物来恢复地面方程和相机位姿;
3)通过visual-inertialodometry得到相机相对地面的旋转和高度,对步骤2)中的地面进行初始化,得到地面方程,确定当前相机位姿下的地面方程,并把这个地面方程反投影到7图像坐标系上,使用图像处理方法获取更加准确的地面区域;
4)基于先验地面特征点深度的visual-inertial状态估计,详细推导出各种传感器的观测模型,将相机观测、imu观测和地面特征观测融合在一起来做状态估计,使用图优化模型来做状态估计,使用稀疏图优化和梯度下降法来实现整个优化。
步骤1)中建立相机投影模型为:
101)世界坐标系和相机坐标系转换公式为
其中
图像坐标系到像素坐标系转换公式为
x、y、z代表相机坐标系,x、y代表图像平面坐标系,f表示一个线性倍数;
102)将相机坐标在u轴上放大fx倍,在v轴上放大fy倍,原点平移cx,cy,得到像素坐标系:
103)整理世界坐标系到像素坐标系的转换,其中包含一个其次坐标到非齐次坐标的转换,如公式:
其中
104)对每张图像,首先使用shi-tomasi检测特征点,利用滑动窗口在各个方向上变化,确定是否为角点;
105)将关键帧之间imu测量值积分分成两帧之间相对运动的约束,消除初始条件变化造成的重复积分,在每个关键帧到来之前对imu数据积分;
106)利用“张正友标定法”对相机进行标定。
3.根据权利要求2所述的基于地平面假设的视觉惯导slam方法,其特征在于:步骤1)中,相机投影模型中具有一个归一化平面,在相机坐标系下,用
归一化平面的归一化坐标是在z的方向上,当z=1时用一个平面截断,光心与3d点的连线在此平面上的点为该3d点的归一化点,表示为公式:
106)归一化坐标经过内参的左乘之后得到相机坐标,如公式所示:
其中,k为其中相机内参k矩阵为
步骤2)中,基于地面标识物的visual-inertialslam系统的初始化,将视觉观测到的点云和相机位姿对齐到imu观测上,并且用地面上的已知尺寸、坐标的标识物来恢复地面方程和相机位姿,包括以下步骤:
201)从两张图片中,得到一对配对好的特征点,利用对极约束,给出两个匹配点的空间位置关系:平移和旋转;
202)用八点法求解本质矩阵e:
e=t^r
e为一个3*3的矩阵,内有9个未知数;t为平移矩阵,r为旋转矩阵;
上述一对特征点的归一化坐标为x1=[u1,v1,1]t,x2=[u2,v2,1]t,根据对极约束,有公式:
(u1,v1,1)和
利用八对匹配点组成的矩阵满足秩为8的条件,本质矩阵e根据上述方程求得;
203)利用svd分解求出两个关键帧之间的相对旋转和平移设本质矩阵e的svd分解为公式:
e=uσvt
其中∑为奇异值矩阵,u和v为对角矩阵,根据e的内在性质,在svd分解中,对于任意一个e,存在四个可能的r,t与它对应,其中只有一组解中p矩阵即r和t组成的矩阵在两个相机中都具有正的深度,取那个解;
204)恢复位姿后,利用三角化恢复特征点深度;
设x1,x2为两个特征点的归一化坐标,满足公式:
s1x1=s2rx2+t
求解的是两个特征点的深度s1,s2。对公式等式两边左乘x1^,左侧为零,右侧可以看成是s2的一个方程,可以直接求出s2,有了s2,s1也自然能求出,于是,得到了两帧下的点的深度,确定了它们的空间坐标;
205)将视觉和惯导紧耦合对齐;
206)使用suft角点作为图像中特征点,搜索实时图像中标识物的位置,并使用suft描述子来寻找匹配的特征点,当匹配的特征点超过10个,再使用ransac算法,使得取出任意四对儿匹配的特征点,满足同一个单应性矩阵;
207)假定这个平面标识物的中心为世界坐标的原点,它的四个顶点都在同一个平面上,它的四个顶点的真实世界坐标为(-a,-b,0),(-a,b,0),(a,-b,0)和(a,b,0);已知3d,2d的匹配点对儿,使用pnp算法来求解相机相对这个标识物的旋转和平移矩阵。
步骤3)中,对预选定的地面进行初始化,得到地面方程,确定当前相机位姿下的地面方程,并把这个地面方程反投影到图像坐标系上,使用图像处理方法获取更加准确的地面区域,具体为:
301)通过visual-inertialodometry的迭代求解获取带有累积误差的相机位姿
nwtpw+dw=0
其中nw代表地面方程的法向量,pw=(xw,yw,zw)代表地面上任意一点,dw是世界坐标系原点到地面平面的距离;
302)准备一个地面模型图像,假设m是模型直方图数据、i是图像直方图数据,j为像素bin的个数,直方图交叉描述为:
303)根据直方图图像的每个像素点i(x,y)的像素值获得相应的直方图分布概率,对得到分布概率图像做卷积,求取局部最大值,即得到已知物体位置信息。
步骤4)中,将相机观测、imu观测和地面特征观测融合在一起来做状态估计包括以下步骤:
401)使用一个紧耦合滑动窗口将图像帧和imu观测融合在一起,保证计算量保持在可控范围内;
402)定义惯导观测模型为:
其中,第一行代表位置残差,第二行代表速度残差,第三行代表朝向残差,第四行代表加速度计bias残差,第五行代表陀螺仪bias残差;
403)建立视觉差模型,用三角化的带深度的特征点云,依据当前估计的相机位姿投影到相机的像素坐标系上,然后算投影特征点和与它匹配的真实特征点位置的偏移量;
404)建立地面观测模型,得到地面特征点深度的观测残差;
405)融合视觉差模型、惯导观测模型以及面观测模型,对三个模型的特征点深度进行捆集优化;
406)对相机的运动模型和观测模型构成的图进行优化;
407)采用梯度下降方法对上述图优化构造的公式求解最优解;
408)将构造的图进行稀疏性和边缘化处理,得到稀疏图。
步骤404)中,建立地面观测模型,得到地面特征点深度的观测残差包括以下步骤:
404a)假设一帧图像中地面特征点的集合为g,则地面观测残差为公式:
其中
404b)将图像上归一化坐标系的一点对应到相机坐标系下,如公式:
得到
最终结果如公式:
k1=t11(t22t34-t24t32)
+t12(t24t31-t21t34)
+t14(t21t32-t22t31)
k2=t11t22-t12t21
k3=t21t32-t22t31
得到地面特征点深度的观测残差;
其中ki是由
404c)构建一个最小二乘来求解最优的后验状态估计,即代价函数:
通过上式找到一个最优的参数,使得代价函数无限接近于零,则得到地面特征点深度的观测残差。
步骤407)中,梯度下降法为采用梯度下降对构造的方程求最优解为:
407a)通过信赖域法,结合普通梯度下降和高斯牛顿法优化方法,利用局部数据对整体函数进行近似,求得局部最小值;
407b)使用立文伯格马夸特测定法算法进行梯度下降:
给定初始值x0,以及初始优化半径μ;
对于第k次迭代求解,得公式:
计算ρ;
若ρ>3/4,则μ=2μ;
若ρ<1/4,则μ=0.5μ;
如果ρ大于某阈值,则认为近似可行,令xk+1=xk+δxk
判断是否收敛,如果不收敛则返回第二步,否则结束。
步骤408)中,稀疏图优化是将构造的图进行稀疏性和边缘化处理,得到稀疏图,步骤为:
408a)假设一个场景有两个相机位姿(c1,c2)和六个路标(p1,p2,p3,p4,p5,p6),相机位姿和特征点所对应的变量为ti,i=1,2以及xj,j=1,2,相机c1观测到路标点p1,p2,p3,p4,相机c2观测到路标点p3,p4,p5,p6;
408b)场景下的目标函数为:
408c)e11描述了在c1观测到p1,与其他的相机位姿和路标无关;令j11为e11所对应的雅可比矩阵,这里把所有变量以(t1,t2,x1,...,x6)t的顺序摆放,有式:
408d)将这些jij按照顺序列为向量,得到整体雅可比矩阵及相应的h矩阵的稀疏;
408e)在h矩阵中,将左上角维度与相机维度相等的对角矩块记为b,右下角与路标点维度相等的对角矩阵块记为c,其余的非对角矩阵块,左下角的非对角矩阵块记为et,右上角的非对角矩阵块记为e,得到与
其中δxc指代相机位姿的最优变化量,δxp指代特征点三维位置的最优变化量;u,w代表整个代价函数在当前状态下对相机位姿的偏导数和对路标点的偏导数,也就是雅可比矩阵分块之后左右两个区域;
408f)对线形方程组进行高斯消元,消去右上角的非对角部分e,得公式:
把左上角维度与相机维度相等的对角矩块记为b,右下角与路标点维度相等的对角矩阵块记为c,其余的非对角矩阵块,左下角的非对角矩阵块记为et,右上角的非对角矩阵块记为e;
经过消元之后,方程组第一行变成和δxp无关的项,单独取出,得到关于位姿部分的增量方程为式:
[b-ec-1et]δxc=v-ec-1w
408g)通过上述方程,快速计算出δxc的值,然后把解得的δxc带入到原方程中,求解δxp。
本发明具有以下有益效果及优点:
1.本发明基于地面平面假设的visual-inertialslam算法,因为可以实时的获取地面点真实深度,每一帧的误差都会被全局的进行校正,消除位置以及角度的累积误差,所以相较之前的算法有较大的精度上的提升,几乎与真值重合。
2.本发明方法加入了惯性传感器,把imu的预积分数据也加入到优化框架里,可以在全局限制相机位姿的估计,使得准确度大大提升。
3.本发明方法在重建的三维地图中,能够清晰的构建出地面区域,为后续的ar应用或者机器人应用提供更丰富的信息。
附图说明
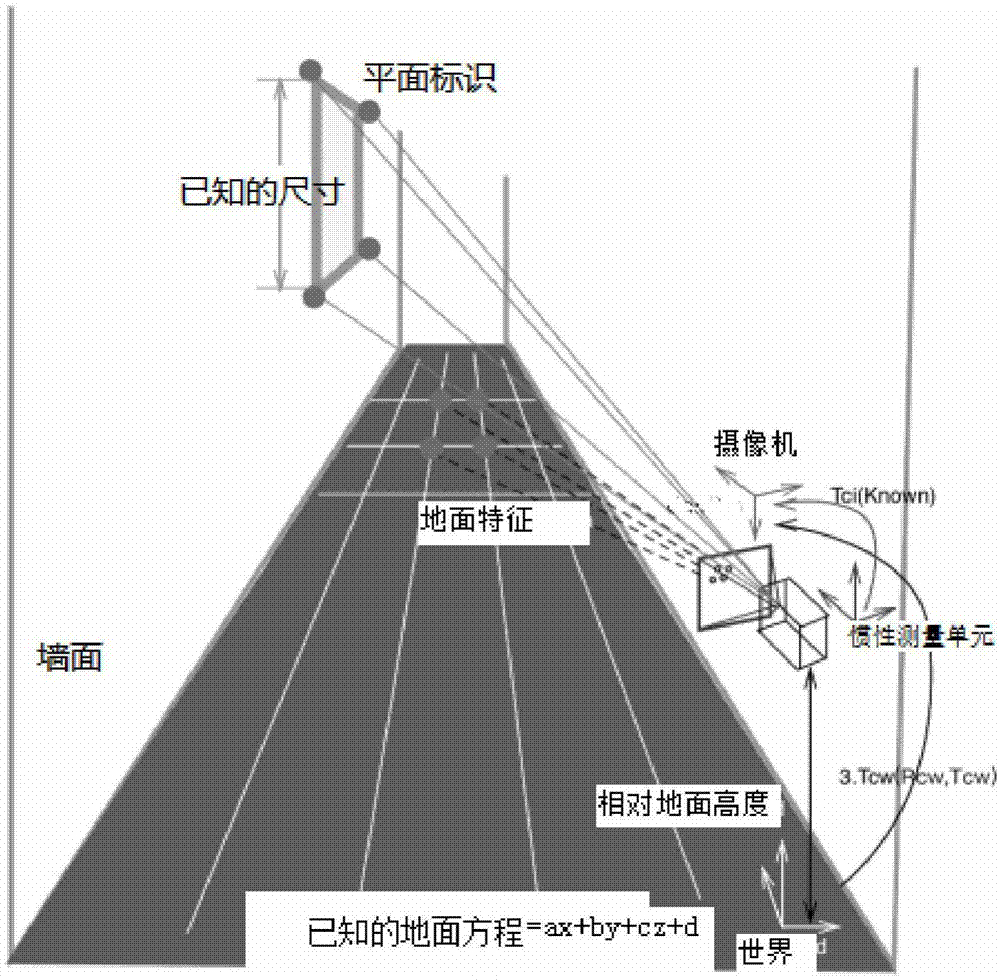
图1为本发明中基于地面假设的visual-inertialslam示意图;
图2为本发明涉及的相机模型图;
图3为本发明中shi-tomasi特征点检测过程示意图;
图4为本发明中对极几何约束示意图;
图5为本发明中视觉和惯导紧耦合对齐过程示意图;
图6为本发明中实际场景和标识物模版特征点匹配图示;
图7为本发明中不同相机位姿下的世界坐标轴对比图;
图8为本发明方法中初始化时的反投影地面区域图片;
图9为本发明中半图像帧和imu观测融合在一起的紧耦合滑动窗口示意图;
图10为本发明中整体的雅可比矩阵及相应的h矩阵的稀疏情况图示;
图11为本发明中真实室内场景测试环境图片;
图12为本发明中人工制作的平面标识物图示;
图13为本发明中将平面路标放置在场景中示意图;
图14为本发明中初始化世界坐标系原点示意图;
图15为本发明中初始化点云图;
图16为本发明中初始化相机位置的性能图;
图17为本发明中地面预选区域图示;
图18为本发明中地面模版和与之对应的颜色概率直方图;
图19为本发明中进行直方图反投影后的地面区域(白色区域);
图20为本发明中的测试场景平面图;
图21为本发明中真实轨迹平面图;
图22为本发明中的vins轨迹图;
图23为本发明中的okvis轨迹图;
图24为本发明中的vigo轨迹图。
具体实施方式
下面结合说明书附图对本发明作进一步阐述。
本发明提出了基于地面平面假设的visual-inertialslam方法(vigo),加入地面上特征点以及平面路标上的特征点作为地图特征实现slam。为了使定位的鲁棒性、连续性更强,恢复真实尺度,本文加入了惯性传感器,把imu的预积分数据也加入到优化框架里。这样可以在全局限制相机位姿的估计,使得准确度大大提升。此外在重建的三维地图中,能够清晰的构建出地面区域,为后续的ar应用或者机器人应用提供更丰富的信息。整体框架如图1所示。
本发明基于地平面假设的视觉惯导slam方法,括以下步骤:
1)从一图像中提取特征点,对上述特征点进行imu预积分,建立相机投影模型,并进行相机内参标定、imu和相机之间的外参标定;
2)基于地面标识物的visual-inertialslam系统的初始化,将视觉观测到的点云和相机位姿对齐到imu预积分上,并且用地面上的已知尺寸、坐标的标识物来恢复地面方程和相机位姿;
3)通过visual-inertialodometry得到相机相对地面的旋转和高度,对步骤2)中的地面进行初始化,得到地面方程,确定当前相机位姿下的地面方程,并把这个地面方程反投影到7图像坐标系上,使用地面模板动态更新、直方图反向投影匹配等图像处理方法获取更加准确的地面区域;
4)基于先验地面特征点深度的visual-inertial状态估计,详细推导出各种传感器的观测模型,将相机观测、imu观测和地面特征观测融合在一起来做状态估计,使用图优化模型来做状态估计,使用稀疏图优化和梯度下降法来实现整个优化。
步骤1)中,建立相机投影模型为:
101)世界坐标系和相机坐标系转换公式为
相机模型如图2所示,其中
图像坐标系到像素坐标系转换公式为
x、y、z代表相机坐标系,x、y代表图像平面坐标系,f表示一个线性倍数;
102)将相机坐标在u轴上放大fx倍,在v轴上放大fy倍,原点平移cx,cy,得到像素坐标系:
103)整理世界坐标系到像素坐标系的转换,其中包含一个其次坐标到非齐次坐标的转换,如公式:
其中
104)对每张图像,首先使用shi-tomasi检测特征点,利用滑动窗口在各个方向上变化,确定是否为角点;
shi-tomasi特征点检测过程如图3所示。想象一个窗口在图像上移动,在平滑区域中,窗口在各个方向没有变化。在边缘区域中,窗口在边缘的方向上没有变化。在角点处窗口在各个方向上都具有变化。shi-tomasi角点检测正是利用了这个物理现象,通过窗口在各个方向上变化,决定是否为角点。
105)将关键帧之间imu测量值积分分成两帧之间相对运动的约束,消除初始条件变化造成的重复积分,在每个关键帧到来之前对imu数据积分;
106)利用“张正友标定法”对相机进行标定。
步骤2)中,基于地面标识物的visual-inertialslam系统的初始化,将视觉观测到的点云和相机位姿对齐到imu观测上,并且用地面上的已知尺寸、坐标的标识物来恢复地面方程和相机位姿,包括以下步骤:
201)从两张图片中,得到一对配对好的特征点,利用对极约束,给出两个匹配点的空间位置关系:平移和旋转;
如图4所示,对极约束包含了平移和旋转。t为平移,r为旋转。
e=t^r
202)用八点法求解本质矩阵e:
e=t^r
e为一个3*3的矩阵,内有9个未知数;
上述一对特征点的归一化坐标为x1=[u1,v1,1]t,x2=[u2,v2,1]t,根据对极约束,有公式:
利用八对匹配点组成的矩阵满足秩为8的条件,本质矩阵e根据上述方程求得;
203)利用svd分解求出两个关键帧之间的相对旋转和平移
设本质矩阵e的svd分解为公式:
e=uσvt
其中∑为奇异值矩阵,u和v为对角矩阵。根据e的内在性质,在svd分解中,对于任意一个e,存在四个可能的r,t与它对应,其中只有一组解中p矩阵即r和t组成的矩阵在两个相机中都具有正的深度,取那个解;
204)恢复位姿后,利用三角化恢复特征点深度;
设x1,x2为两个特征点的归一化坐标,满足公式:
s1x1=s2rx2+t
求解的是两个特征点的深度s1,s2。对公式等式两边左乘x1^,左侧为零,右侧可以看成是s2的一个方程,可以直接求出s2,有了s2,s1也自然能求出,于是,得到了两帧下的点的深度,确定了它们的空间坐标;
205)将视觉和惯导紧耦合对齐;如图5所示。
206)使用suft角点作为图像中特征点,搜索实时图像中标识物的位置,并使用suft描述子来寻找匹配的特征点,当匹配的特征点超过10个,再使用ransac算法,使得取出任意四对儿匹配的特征点,满足同一个单应性矩阵;如图6所示,为实际场景和标识物模版特征点匹配情况:
207)假定这个平面标识物的中心为世界坐标的原点,它的四个顶点都在同一个平面上,它的四个顶点的真实世界坐标为(-a,-b,0),(-a,b,0),(a,-b,0)和(a,b,0);已知3d,2d的匹配点对儿,使用pnp算法来求解相机相对这个标识物的旋转和平移矩阵。
如图7所示,相机相对世界坐标原点的位姿,其中黑线包围区域区域为地面区域,地面上的a4纸区域为标识物平面,三条直线中的灰线和白线分别代表x轴和y轴,黑线代表z轴:
步骤3)中,对预选定的地面进行初始化,得到地面方程,确定当前相机位姿下的地面方程,并把这个地面方程反投影到图像坐标系上,使用图像处理方法获取更加准确的地面区域,具体为:
301)通过visual-inertialodometry的迭代求解获取带有累积误差的相机位姿
nwtpw+dw=0
其中nw=(aw,bw,cw)代表地面方程的法向量,pw=(xwywzw)代表地面上任意一点,dw/||n||是世界坐标系原点到地面平面的距离;
图8为初始化地面预选区域,其中黑线框为初始化时地面在相机图像坐标系下的投影。
302)准备一个地面模型图像,假设m是模型直方图数据、i是图像直方图数据,j为像素bin的个数,直方图交叉描述为:
303)根据直方图图像的每个像素点i(x,y)的像素值获得相应的直方图分布概率,对得到分布概率图像做卷积,求取局部最大值,即得到已知物体位置信息。
步骤4)中,将相机观测、imu观测和地面特征观测融合在一起来做状态估计包括以下步骤:
401)使用一个紧耦合滑动窗口将图像帧和imu观测融合在一起,保证计算量保持在可控范围内;如图9所示.
402)定义惯导观测模型为:
其中,第一行代表位置残差,第二行代表速度残差,第三行代表朝向残差,第四行代表加速度计bias残差,第五行代表陀螺仪bias残差;
403)建立视觉差模型,用三角化的带深度的特征点云,依据当前估计的相机位姿投影到相机的像素坐标系上,然后算投影特征点和与它匹配的真实特征点位置的偏移量;
404)建立地面观测模型,得到地面特征点深度的观测残差;
假设一帧图像中地面特征点的集合为g,则地面观测残差为公式:
其中
404b)将图像上归一化坐标系的一点对应到相机坐标系下,如公式:
得到
最终结果如公式:
k1=t11(t22t34-t24t32)
+t12(t24t31-t21t34)
+t14(t21t32-t22t31)
k2=t11t22-t12t21
k3=t21t32-t22t31
得到地面特征点深度的观测残差;
其中ki是由
404c)构建一个最小二乘来求解最优的后验状态估计,即代价函数:
通过上式找到一个最优的参数,使得代价函数无限接近于零,则得到地面特征点深度的观测残差。
405)融合视觉差模型、惯导观测模型以及面观测模型,对三个模型的特征点深度进行捆集优化;
406)对相机的运动模型和观测模型构成的图进行优化;
406a)假设在时刻k,机器人在位置xk处,用传感器进行了一次测量,得到数据zk。
406b)传感器的观测方程为式:
zk=h(xk)
406c)由于噪声就有了误差,所以真正的观测误差如式
ek=zk-h(xk)
406d)这里以xk为优化变量,以minxf(xk)=||ek||为目标函数,求得xk的估计值。以imu观测方程为例,
步骤407)中,梯度下降法为采用梯度下降对构造的方程求最优解为:
407a)通过信赖域法,结合普通梯度下降和高斯牛顿法优化方法,利用局部数据对整体函数进行近似,求得局部最小值;
407b)使用lm(levenberg–marquardt)(立文伯格马夸特测定法)算法进行梯度下降:
给定初始值x0,以及初始优化半径μ;
对于第k次迭代求解,得公式:
计算ρ。
若ρ>3/4,则μ=2μ。
若ρ<1/4,则μ=0.5μ。
如果ρ大于某阈值,则认为近似可行,令xk+1=xk+δxk
判断是否收敛。如果不收敛则返回第二步,否则结束。
步骤408),将构造的图进行稀疏性和边缘化处理,得到稀疏图,具体为:
408a)假设一个场景有两个相机位姿(c1,c2)和六个路标(p1,p2,p3,p4,p5,p6),相机位姿和特征点所对应的变量为ti,i=1,2以及xj,j=1,2,相机c1观测到路标点p1,p2,p3,p4,相机c2观测到路标点p3,p4,p5,p6;
408b)场景下的目标函数为:
408c)e11描述了在c1观测到p1,与其他的相机位姿和路标无关;令j11为e11所对应的雅可比矩阵,这里把所有变量以(t1,t2,x1,...,x6)t的顺序摆放,有式:
408d)将这些jij按照顺序列为向量,得到整体雅可比矩阵及相应的h矩阵的稀疏情况,如图10所示:雅可比矩阵和h矩阵的稀疏性,填色代表有数据,无填色代表零;
408e)在h矩阵中,将左上角维度与相机维度相等的对角矩块记为b,右下角与路标点维度相等的对角矩阵块记为c,其余的非对角矩阵块,左下角的非对角矩阵块记为et,右上角的非对角矩阵块记为e,得到与
其中δxc指代相机位姿的最优变化量,δxp指代特征点三维位置的最优变化量。u,w代表整个代价函数在当前状态下对相机位姿的偏导数和对路标点的偏导数。也就是雅可比矩阵分块之后左右两个区域;
408f)对线形方程组进行高斯消元,消去右上角的非对角部分e,得公式:
把左上角维度与相机维度相等的对角矩块记为b,右下角与路标点维度相等的对角矩阵块记为c,其余的非对角矩阵块,左下角的非对角矩阵块记为et,右上角的非对角矩阵块记为e。
经过消元之后,方程组第一行变成和δxp无关的项,单独取出,得到关于位姿部分的增量方程为式:
[b-ec-1et]δxc=v-ec-1w
408g)通过上述方程,快速计算出δxc的值,然后把解得的δxc带入到原方程中,求解δxp。
本实施例中,图像传感器采用的是全局曝光的黑白图像传感器mt9v034,imu选用icm20602。图像传感器输出640*480尺寸的图像,帧率可调,本实验使用每秒20帧的图像帧率。图像传感器和imu之间的同步通过板载的fpga绝对同步的外触发方式驱动,imu在每次图像传感器曝光时采集数据,保证图像每帧之间50ms内一共采集10个imu数据,即imu的采样率为200hz。实验使用的传感器把相机和imu做在一块pcb板子上,节省了空间。板子的尺寸为9*2.2cm。可以方便的嵌入机器人或者ar眼镜中。图像传感器的镜头采用m12广角镜头,可观测角度为150度,使得机器视觉的感受范围更宽,采集到更多的特征点。
实验用的机器配置为inteli5-4250u处理器,4gddr3内存,linux系统。
选择东北大学信息楼一楼休息区作为实验场地,如图11所示;测试场景还需要一个或多个平面标识物进行世界坐标的确定以及累积误差的修正,制作的平面标识物,如图12所示;这个标识物需要提前布置在场景中,如图13所示。取这个路标的中心点为世界坐标原点,那么四个角点的坐标分别为(-0.21,-0.29),(0.21,-0.29),(-0.21,0.29),(0.21,0.29)。
初始化阶段:
在初始化阶段,用户在休息区测试环境中前后移动摄像头,使用环境中的特征和平面路标点上的特征来构建sfm初始点云,并在跟imu数据对齐之后根据提示,对准平面路标进行世界坐标的确立。如图14所示,为初始化的世界坐标系可视化。
图15为初始化点云:
初始化点云数据可视化,其中2曲线为相机轨迹,1框为相机,白色点为识别出的地面点云,深灰色点为场景内普通点云。
为了测试初始化的性能,进行了十次相同位置的对平面路标的观测,如图所示,其中横轴为相机三维坐标轴,纵轴为坐标值,单位是米。十次测试的相机真实位置均为(-0.5,0.5,1.5),图16中用浅色的加号表示。深色的加号表示十次初始化的相机位置,可以看到,x,y轴的误差在±0.01m。z轴的误差在±0.02cm。
实验结果证明算法初始化的精度足够进行初始位置的确定,而且初始化过程完全是自动进行的,不需要用户选取初始点位置,满足实时性要求。地面检测模块:
从初始化时获得的相机位姿,地面方程是在初始化时确定的,地面方程与地面平面路标在同一平面。
基于图17中的预选区域进行反向直方图投影,在进行直方图匹配之前需要对图像进行预先处理,计算反向投影直方图的过程如下:
基于图像中的预选区域进行反向直方图投影,在进行直方图匹配之前需要对图像进行预先处理,计算反向投影直方图的过程如下:
(1)从地面模版的归一化直方图中读取概率值,概率图如图18所示。
(2)把原图像中的每一个像素替换成与之对应的归一化中直方图中的概率值。
(3)把替换成概率值的像素值从0~1替换成0~255的值。
(4)灰度值越大的像素越有可能是目标像素点。
如图19所示为根据模版直方图反向投影得到的与地面模版匹配的地面区域。
非线性优化模块:
实验数据使用第一节介绍的图像传感器和imu,采集的数据来源于东北大学浑南校区信息楼a座一楼休息区。
场景平面图如图20所示,场地占地面积为150平方米,平面图中边缘标注的数字的单位是米,考虑到实际场景中沙发是稳定的参考物,所以只把沙发画在了平面图中:
图21为实验人员的真实行走路径:vins也是使用了visual-inertial紧耦合的方式进行非线性优化,所以转角的角度误差很小,虽然vins也通过初始化恢复了相机的真实尺度,但是在实时跟踪当中,受限于imu有很大的累积误差,导致最终优化的直线部分会存在尺度问题,表现在实验结果中即为直线部分的累积误差。
如图22~24所示,三幅图展示了不同方法在平面图上的轨迹图。如图22所示,其中vins也是使用了visual-inertial紧耦合的方式进行非线性优化,所以转角的角度误差很小,虽然vins也通过初始化恢复了相机的真实尺度,但是在实时跟踪当中,受限于imu有很大的累积误差,导致最终优化的直线部分会存在尺度问题,表现在实验结果中即为直线部分的累积误差。
如图23所示,相对于vins,okvis表现的不够好,虽然和vins一样,是visual-inertial紧耦合的方式进行非线性估计,但是在转弯处的估计会有一些偏差,这个可能跟okvis的边缘化策略有关。
如图24所示,可以看到vins和okvis的计算结果都有一定的累积误差,vins使用了imu进行尺度恢复,所以误差更小一些,在一些局部达到了很高的精度,但是在长时间直线移动后,还是有较大的累积误差。而本文提出的基于地面平面假设的visual-inertialslam算法,因为可以实时的获取地面点真实深度,每一帧的误差都会被全局的进行校正,消除位置以及角度的累积误差,所以相较之前的算法有较大的精度上的提升,几乎与真值重合。
本发明提出的基于地面平面假设的visual-inertialslam算法,因为可以实时的获取地面点真实深度,每一帧的误差都会被全局的进行校正,消除位置以及角度的累积误差,所以相较之前的算法有较大的精度上的提升,几乎与真值重合。
- 还没有人留言评论。精彩留言会获得点赞!