一种基于Universum学习的多经验核分类器的制作方法
发明涉及模式识别技术领域,是基于universun学习的多经验核学习机制。
背景技术
基于核的算法已经有很多的应用,并取得了良好的效果。核映射方法是一个可以解决非线性问题的有效方法。核映射方法是指将输入空间x通过一个核函数φ映射到一个新的特征空间γ,核函数定义如下φ:x→γ。按映射形式划分,核映射可以分为隐性核映射implicitkernelmapping(ikm)φi和经验核映射empiricalkernelmapping(ekm)φe。隐形核映射是通过核函数k(xi,xj)=φi(xi)·φi(xj)映射而成的,其中φi的具体形式不需要被给出。隐形核映射可以将输入空间映射到一个无限空间,因为隐形核映射后的空间不需要被知道。隐形核映射利用核矩阵参与运算,因此隐形核映射速度更快。相反,经验核映射需要给出具体的核函数形式,以便去获取映射后的具体的映射空间。核函数的类型和参数是确定的。经验核映射下,映射后的新特征空间可以获得,以方便在新的特征空间下作进一步研究。
同时,基于核的学习又可以分为单核学习和多核学习。单核学习,顾名思义是采用某个特定的核函数将输入空间映射到一个新的空间。由于核函数的类型和参数各异,所以这样的单核学习不唯一,不同的核函数在不同的场景下效果也表现各异。而且关于核函数的选择也是一个挑战,我们并没有先验知识和理论去识别哪一个核函数效果会更好。因此学者提出了多核学习的概念。多核学习是指将输入空间通过多个核函数映射到多个特征空间的过程。多核学习的模型定义如下:
另一方面,universum学习也是引入了输入数据的先验知识,取得了不错的效果。universum学习是指给出一些无关样本,这些样本不属于任何一类。这些无标签的样本被称为universum样本。universum样本包含了原始数据的先验知识。而universum学习就是将这些universum样本引入原始数据以丰富样本的多样性。universum学习是有效的,它的有效性在于获得了原始数据的先验知识。
已有将universum学习与单核学习,多核学习,隐形核学习进行结合,都取得了良好的效果。但是universum学习与多经验核仍未有效结合。universum样本的生成可以更加有效地结合多经验核学习,获得更加优秀的性能。
技术实现要素:
技术问题:不同于已有的多核学习算法,本发明将universum学习引入到多经验核学习框架中,且提出了一个新的分类算法multipleuniversum-basedempiricalkernellearning(muekl)。muekl利用映射后的每个新特征空间生成universum样本。本发明根据universum学习的性质设计正则化项runi,并引入到多经验核学习框架中。在平衡数据集上表现优异,同时还可以解决不平衡问题。本发明引入了一个新的生成universum样本的方式imbalancedmodifieduniversum(imu)。imu引入样本的不平衡程度来生成universum样本。
技术方案:首先,将原始样本经过多个经验核映射得到多个对应的映射后的核空间。每个映射空间,原始数据映射后的数据可以显性得到,加以利用。其次,本发明提出了一个新的universum样本生成方法imu,在每个核映射空间利用imu方法生成universum样本,每个核映射空间的universum样本都不同。接着,本发明在每个核空间构建universum学习,universum参与分类。本发明引入正则化项runi到多经验核学习框架,形成muekl算法。
本发明解决其技术问题所采用的技术方案还可以进一步细化。所述的第二步骤中,本发明是根据映射后的数据生成universum样本。先找出类别间的边界样本,再利用边界样本生成universum样本。提出的imu方法引入了不平衡率的概念,生成的universum样本的分布与不平衡率有关。本发明引入正则化项runi到多经验核学习multik-mhks中。但根据不同情况,可以使用另外的多核算法及核映射函数。正则化项runi和universum样本的有效结合使得muekl可以解决不平衡问题。
有益效果:本发明与现有技术相比,具有以下优点:不同于已有的多核学习算法,本章将universum学习引入到多经验核学习框架中,且提出了一个新的分类算法muekl。muekl利用映射后的每个新特征空间生成universum样本,并将新正则化项runi引入到多经验核学习框架中;经验核学习和universum学习的结合在平衡数据集上表现优异,同时还可以解决不平衡问题。universum样本不仅仅弥补和丰富了原始数据的信息,而且扰动分类边界使muekl在不平衡问题上表现更好;本章引入了一个新的生成universum样本的方式imu。imu根据样本的不平衡程度来生成universum样本,这更好地适应不平衡问题。
附图说明
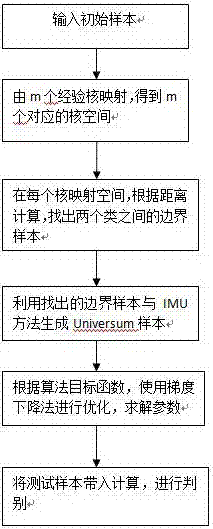
图1是本发明的流程图。
具体实施方式
下面结合附图和表对本发明作进一步介绍:本发明共分四个步骤。假设有数据集x:
第一部分:多经验核映射:多经验核映射是指将原始数据样本x经过m个经验核函数φe映射到相对应的m个新的特征空间
第二部分:生成universum样本:在映射后的特征空间中,利用映射后的样本数据生成universum样本。这里,本发明引入了一种新的universum样本生成方式imu。定义如下:
np表示正类样本的数量,nn表示负类样本的数量。γi是核映射后正类样本,γj表示核映射后的负类样本。xu即是生成的universum样本。
第三部分:构建目标函数。目标函数为:
对于第i个核空间,remp是经验风险项,rreg是正则化项并用来控制分类器的泛化能力,ci≥0是一个正则参数,它平衡remp和rreg的权重。rifsl有着重要的作用,控制多核的输出结果尽可能保持一致。参数γ控制rifsl的权重。这三个正则化项的详细描述分别如下:
remp=(yw-1n×1-bn×1)t(yw-1n×1-bn×1)
其中,
runi=(y*w)t(y*w)
y*表示universum样本的增广矩阵
第四部分:优化,迭代求解。
每个wi可以用启发式梯度下降法进行优化。令目标函数对wi求导,我们可以得到
令它等于0,我们可以得到
bi表示样本到超平面的距离,所以bi的值必须是非负的。我们在优化wi和bi时,采用的是迭代算法。因此,
第五部分:测试算法效果。上面我们已经求解出最优的未知参数。假设新来一个未知样本z,我们可以通过将样本z代入muekl的判别公式进行决策。muekl的判别公式为:
其中,z为待测样本。
实验设计
1)实验数据集选取:该实验分别选择了平衡和不平衡数据集。选取数据集的类数目、样本维度、规模(样本总数)列在表中。表2是平衡数据集uci,表3是不平衡数据集keel。所有使用的数据集均采用五轮交叉验证方式处理,即将数据集各类平均分为五份。每轮迭代选择每类的其中一份作为测试样本,其余四份作为训练样本。一共执行五轮。选取五轮的平均性能作为分类器性能。
2)对比模型:该发明所提出的分类器命名为muekl。另外,我们选择五个经典的多核模型usvm、multik-mhks、sinplemkl、nlmksvm、svm作为对比。
3)性能度量方法:实验在平衡数据集上统一使用准确率acc来记录不同方法在平衡数据集下的分类结果。在不平衡数据集上,我们统一使用受试者工作特征曲线线下面积(theareaunderthereceiveroperatingcharacteristiccurve,auc)来记录不同方法对各数据集的分类结果。结果均为对应算法在该数据集上使用最优参数配置时获得的结果,即最优结果。auc的计算公式为:
其中tp为真正类率,fp为假正类率,tn为真负类率,fn为假负类率。四个指标的关系如下表:
表1混淆矩阵
表2uci数据集描述
表3keel数据集描述
实验结果
所有模型在uci数据集上的分类结果如下表4所示。表4中给出了muekl和所有对比算法的精确度和标准差。最好的结果加粗显示。实验结果后面括号中的数字表示该算法在所有算法中的排名。另外,所有算法的平均精度和平均排名都在表格的最后两行列出来了。muekl算法表现优异。在全部的22个uci数据集中,muekl算法在其中的18个数据集中准确度都最高。muekl在22个uci数据集中的平均精度可达88.71%,平均排名1.59,是所有算法中最好的。排名第二好的算法是multik-mhks,平均精度为88.40%,平均排名2.05。但是muekl比multik-mhks的平均精度高0.31%。muekl算法也比其它算法的平均精度也高出很多,这说明了muekl的高效性。在uci数据集上的实验结果证明了muekl在平衡数据集上表现优异,体现了muekl方法的有效性。
表4所有算法在uci数据集上的实验结果(%)
表5中展示了所有算法在38个数据集中的准确度和标准差,最好的结果加粗显示。表5中结果后括号中的数字表示算法在每一个数据集上的排名。另外算法在所有数据集上的平均性能和排名在表5的最后两行分别列出。如果两个算法的平均排名相同,我们用它们平均排名的平均来代替。
表5keel数据集实验结果(%)
如表5所示,muekl在所有的对比算法中,性能最好。在所有的38个keel数据集中,muekl在其中的32个数据集中准确度最高。muekl在这38个数据集上的平均aacc高达90.27%,平均排名1.47。multik-mhks是表现第二的算法,muekl在平均aacc上比multik-mhks高出1.31%个点。muekl在低不平衡率和高不平衡率的时候准确率都很高。实验结果证明了muekl的有效性。
为了证明imu的有效性,我们选用常用的ibu生成方式与我们所提出的imu在muekl算法上进行对比。数据集仍然选用以上提到的22个uci数据集和38个keel数据集。uci数据集上的实验结果如表6所示,keel数据集上的实验结果如表7所示。ibu计算公式如下:
其中,xi表示选出的正类样本,xj表示选出的负类样本,xu表示由他们生成的universum样本数据。当不平衡率接近于1,根据imu的计算公式可知,imu在平衡数据集中会退化成ibu。
表6uci数据集上,universum数据生成方式的比较(%)
如表6所示,imu和ibu在8个uci数据集上性能相等。imu的平均精度为88.71%,ibu的平均精度为88.60%。imu在其中8个数据集上比ibu的性能好,在其中6个数据集上表现比ibu差一些。因此可以看出,imu和ibu在平衡数据集上表现相似。另一方面,基于ibu的muekl在所有uci数据集上的平均性能比第二好算法mulltik-mhks还要高出0.2%,因此可以说明muekl算法的优越性。如表7所示,imu在keel数据集上性能比ibu好。在38个数据集中,imu在其中的32个数据集都表现最优。同时基于imu的muekl在keel数据集上的平均性能高达90.27%,基于ibu的muekl可达89.52%。universum数据的生成方式在模型性能上也起着重要的作用。imu的有效性在于生成universum样本时,引入了不平衡率的相关概念。一般来说,不平衡率越高,分类边界偏向少数类的程度就越严重。对于不平衡率比较高的数据集来说,生成的universum数据偏向多数类,再由于正则化项的约束,则边界偏向少数类的情况会减轻。从实验数据上来看,基于ibu的muekl比性能第二好的算法multik-mhks好,在平均aacc上高出了0.56%。无论采用的universum数据生成方式是imu还是ibu,muekl都表现较好,基于imu的muekl性能更佳。
表7keel数据集上,universum数据生成方式的比较(%)
- 还没有人留言评论。精彩留言会获得点赞!