抬头纹检测方法及装置与流程
本申请涉及计算机技术领域,尤其涉及一种抬头纹检测方法及装置。
背景技术
人脸皮肤老化的标志之一是皱纹,因此人脸额头上的抬头纹可以看作人脸中一个重要的皮肤特征。同时由于性别、年龄以及地域属性等不同,也会导致抬头纹的严重程度各不相同。
在美容美妆领域可以通过手机自拍图片自动检测人脸抬头纹的严重程度,再结合人脸其他的皮肤特征,从而为用户提供护肤意见。以及在图像识别领域检测抬头纹的严重程度对表情识别和年龄识别也有很大的应用价值。
由此可见,如何检测抬头纹是本领域技术人员正在研究的问题。
技术实现要素:
本申请提供了一种抬头纹检测方法及装置,可提高抬头纹检测的准确性。
第一方面,本申请实施例提供了一种抬头纹检测方法,包括:
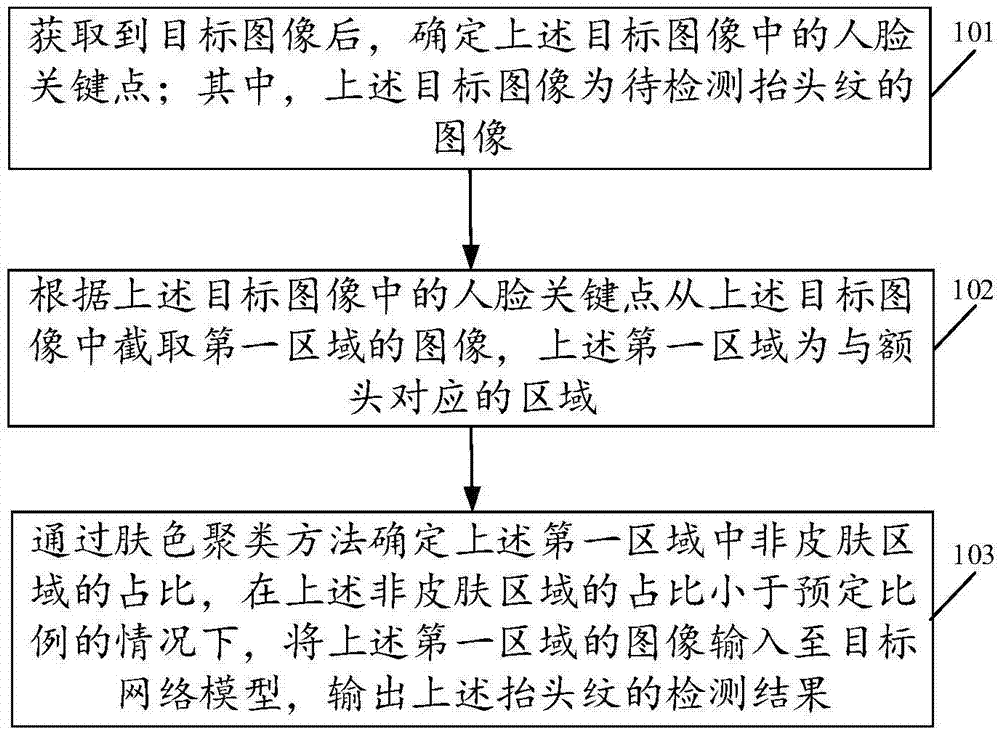
获取到目标图像后,确定所述目标图像中的人脸关键点;其中,所述目标图像为待检测抬头纹的图像;
根据所述目标图像中的人脸关键点从所述目标图像中截取第一区域的图像,所述第一区域为与额头对应的区域;
通过肤色聚类方法确定所述第一区域中非皮肤区域的占比,在所述非皮肤区域的占比小于预定比例的情况下,将所述第一区域的图像输入至目标网络模型,输出所述抬头纹的检测结果。
本申请实施例中,在获取到第一区域的图像后,通过肤色聚类方法先来确定非皮肤区域的占比,在该非皮肤区域的占比小于预定比例时,将该第一区域的图像输入至目标网络模型;可以有效避免由于第一区域的图像被其他物体如头发、头巾或帽子遮挡,而导致目标网络模型无法有效识别的情况;通过实施本申请实施例,可以优先确定非皮肤区域的占比,从而根据该非皮肤区域的占比来决定是否输入至目标网络模型来检测抬头纹,进而可提高目标网络模型输出的准确性,提高输出效率。
在一种可能的实现方式中,所述将所述第一区域的图像输入至目标网络模型,输出所述抬头纹的检测结果,包括:
切割所述第一区域,获得第一数量的子区域,将包含所述第一数量的子区域的图像分别输入至所述目标网络模型;
输出所述第一数量的抬头纹的检测结果,根据有抬头纹的图像的占比确定所述抬头纹的严重程度。
本申请实施例中,通过将第一区域进行分割,从而将分割后的子区域输入至目标网络模型,进而根据各个子区域的检测结果来确定抬头纹的严重程度,可以有效提高抬头纹检测的准确性,提高目标网络模型检测抬头纹的准确率。
在一种可能的实现方式中,所述目标图像中的人脸关键点包括第一关键点和第二关键点;所述第一关键点为所述人脸关键点中左边眉毛的最高点,所述第二关键点为所述人脸关键点中右边眉毛的最高点;
所述根据所述目标图像中的人脸关键点从所述目标图像中截取第一区域的图像,包括:
根据所述第一关键点的横坐标和所述第二关键点的横坐标确定所述第一区域的第一边长;
根据所述第一关键点或所述第二关键点的纵坐标的平移量确定所述第一区域的第二边长;
根据所述第一边长和所述第二边长截取所述第一区域的图像。
本申请实施例中,通过以第一关键点和第二关键点来确定第一区域,简单可行,提高第一区域的截取效率。
在一种可能的实现方式中,所述方法还包括:
在所述非皮肤区域的占比不小于所述预定比例的情况下,确定所述目标图像无所述抬头纹。
在一种可能的实现方式中,所述将所述第一区域的图像输入至目标网络模型之前,所述方法还包括:
采集到人脸图像样本后,确定所述人脸图像样本的人脸关键点;
根据所述人脸图像样本的人脸关键点截取第二区域的图像;
切割所述第二区域,获得第二数量的子区域;
将所述第二数量的子区域分别输入至网络模型,训练所述网络模型,得到所述目标网络模型。
其中,采集到人脸图像样本后,确定该人脸图像样本的人脸关键点,可理解为确定该人脸图像样本中每个图像中的人脸关键点;根据该人脸图像样本的人脸关键点截取第二区域的图像,可理解为根据该人脸图像样本中每个图像中的人脸关键点截取第二区域的图像;也就是说,该人脸图像样本的个数至少为两个,在确定人脸关键点和截取第二区域的图像时,可分别对该人脸图像样本中的每个图像来操作。
本申请实施例中,通过以上方法训练网络模型,可有效提高训练的网络模型的效率,即提高了网络模型输出检测结果的准确性。
在一种可能的实现方式中,所述将所述第一区域的图像输入至目标网络模型之前,所述方法还包括:
接收来自训练装置的所述目标网络模型;其中,所述训练装置用于训练网络模型,得到所述目标网络模型。
第二方面,本申请实施例提供了抬头纹检测装置,包括:
第一确定单元,用于获取到目标图像后,确定所述目标图像中的人脸关键点;其中,所述目标图像为待检测抬头纹的图像;
截取单元,用于根据所述目标图像中的人脸关键点从所述目标图像中截取第一区域的图像,所述第一区域为与额头对应的区域;
第二确定单元,用于通过肤色聚类方法确定所述第一区域中非皮肤区域的占比;
输入单元,用于在所述非皮肤区域的占比小于预定比例的情况下,将所述第一区域的图像输入至目标网络模型;
输出单元,用于输出所述抬头纹的检测结果。
在一种可能的实现方式中,所述输入单元包括:
切割子单元,用于切割所述第一区域,获得第一数量的子区域;
输入子单元,用于将包含所述第一数量的子区域的图像分别输入至所述目标网络模型;
所述输出单元包括:
输出子单元,用于输出所述第一数量的抬头纹的检测结果;
第一确定子单元,用于根据有抬头纹的图像的占比确定所述抬头纹的严重程度。
在一种可能的实现方式中,第一关键点和第二关键点;所述第一关键点为所述人脸关键点中左边眉毛的最高点,所述第二关键点为所述人脸关键点中右边眉毛的最高点;所述截取单元包括:
第二确定子单元,用于根据所述第一关键点的横坐标和所述第二关键点的横坐标确定所述第一区域的第一边长;
第三确定子单元,用于根据所述第一关键点或所述第二关键点的纵坐标的平移量确定所述第一区域的第二边长;
截取子单元,用于根据所述第一边长和所述第二边长截取所述第一区域的图像。
在一种可能的实现方式中,所述装置还包括:
第三确定单元,用于在所述非皮肤区域的占比不小于所述预定比例的情况下,确定所述目标图像无所述抬头纹。
在一种可能的实现方式中,所述第一确定单元,还用于采集到人脸图像样本后,确定所述人脸图像样本的人脸关键点;
所述截取单元,还用于根据所述人脸图像样本的人脸关键点截取第二区域的图像;
所述装置还包括:
训练单元,用于切割所述第二区域,获得第二数量的子区域;并将所述第二数量的子区域分别输入至网络模型,训练所述网络模型,得到所述目标网络模型。
在一种可能的实现方式中,所述装置还包括:
接收单元,用于接收来自训练装置的所述目标网络模型;其中,所述训练装置用于训练网络模型,得到所述目标网络模型。
第三方面,本申请实施例还提供了一种抬头纹检测装置,包括:处理器、存储器和输入输出接口,所述处理器和所述存储器、所述输入输出接口通过线路互联;其中,所述存储器存储有程序指令;所述程序指令被所述处理器执行时,使所述处理器执行如第一方面所述的相应的方法。
第四方面,本申请实施例提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机程序,所述计算机程序包括程序指令,所述程序指令当被抬头纹检测装置的处理器执行时,使所述处理器执行第一方面所述的方法。
第五方面,本申请实施例提供了一种包含指令的计算机程序产品,当其在计算机上运行时,使得计算机执行上述第一方面所述的方法。
附图说明
为了更清楚地说明本申请实施例或背景技术中的技术方案,下面将对本申请实施例或背景技术中所需要使用的附图进行说明。
图1是本申请实施例提供的一种抬头纹检测方法的流程示意图;
图2是本申请实施例提供的一种人脸关键点的示意图;
图3是本申请实施例提供的一种确定第一区域的示意图;
图4是本申请实施例提供的一种原始额头示意图;
图5是本申请实施例提供的一种经过肤色聚类后的额头示意图;
图6是本申请实施例提供的一种切割子区域的示意图;
图7是本申请实施例提供的一种目标网络模型训练方法的流程示意图;
图8是本申请实施例提供的一种抬头纹检测装置的结构示意图;
图9a是本申请实施例提供的一种输入单元的结构示意图;
图9b是本申请实施例提供的一种输出单元的结构示意图;
图9c是本申请实施例提供的一种截取单元的结构示意图;
图10是本申请实施例提供的另一种抬头纹检测装置的结构示意图;
图11是本申请实施例提供的又一种抬头纹检测装置的结构示意图。
具体实施方式
为了使本申请的目的、技术方案和优点更加清楚,下面将结合附图对本申请作进一步地详细描述。
本申请的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别不同的对象,而不是用于描述特定顺序。此外,术语“包括”和“具有”以及它们任何变形,意图在于覆盖不排他的包含。例如包含了一系列步骤或单元的过程、方法、系统、产品或设备没有限定于已列出的步骤或单元,而是可选地还包括没有列出的步骤或单元,或可选地还包括对于这些过程、方法或设备固有的其他步骤或单元。
参见图1,图1是本申请实施例提供的一种抬头纹检测方法的流程示意图,该抬头纹检测方法可应用于抬头纹检测装置,该抬头纹检测装置可包括服务器或终端设备,该终端设备可包括手机、台式电脑、手提电脑和其他设备等等,本申请实施例对于该抬头纹检测装置的具体形式不作限定。
如图1所示,该抬头纹检测方法包括:
101、获取到目标图像后,确定上述目标图像中的人脸关键点;其中,上述目标图像为待检测抬头纹的图像。
本申请实施例中,获取到目标图像可理解为该抬头纹检测装置采集目标图像,从而获取该目标图像;也可理解为该抬头纹检测装置从其他装置处获取该目标图像,对于该抬头纹检测装置如何获取目标图像,本申请实施例不作限定。可理解,该目标图像为待检测抬头纹的图像,即该目标图像为需要确定抬头纹的严重程度的图像,或者该目标图像为需要目标网络模型进行预测抬头纹的严重程度的图像。
本申请实施例中,确定目标图像中的人脸关键点的方法包括:可以通过算法如边缘检测robert算法,索贝尔sobel算法等;也可通过相关模型如主动轮廓线snake模型等等。
尽管采用上述各种算法或模型可以确定目标图像中的人脸关键点,但是以上方法一方面比较复杂,另一方面效果较差。因此,本申请实施例提供了一种简单方法,不仅实现简单,而且还可有效的确定人脸关键点,如下所示:
上述确定上述目标图像中的人脸关键点,包括:
通过第三方应用确定上述目标图像中的人脸关键点。
本申请实施例中,第三方应用可为第三方工具包dlib,dlib是开源的人脸关键点定位效果较好的工具包且是一个包含机器学习算法的c++开源工具包。目前工具包dlib被广泛应用在包括机器人,嵌入式设备,移动电话和大型高性能计算环境领域。因此可有效的利用该工具包做人脸关键点定位,得到人脸关键点。具体的,该人脸关键点可为68个人脸关键点等等。如图2所示,图2是本申请实施例提供的一种人脸关键点的示意图。从中可以看出人脸关键点可包括关键点0、关键点1……关键点67,即68个关键点。
102、根据上述目标图像中的人脸关键点从上述目标图像中截取第一区域的图像,上述第一区域为与额头对应的区域。
本申请实施例中,可以直接从目标图像中截取出额头区域,如以固定长宽为依据来截取等等。但是在以固定长宽来截取时,往往会因为每个人额头大小不一样,而导致截取出的第一区域不同。因此,本申请实施例还提供了一种截取第一区域的图像的方法,如下所示:
上述根据上述目标图像中的人脸关键点从上述目标图像中截取第一区域的图像,包括:
根据上述第一关键点的横坐标和上述第二关键点的横坐标确定上述第一区域的第一边长;
根据上述第一关键点或上述第二关键点的纵坐标的平移量确定上述第一区域的第二边长;
根据上述第一边长和上述第二边长截取上述第一区域的图像。
本申请实施例中,上述第一关键点为上述人脸关键点中左边眉毛的最高点,上述第二关键点为上述人脸关键点中右边眉毛的最高点。也就是说,该第一关键点和该第二关键点可分别为眉毛的最高点。具体的,如图2所示,人脸关键点中包括关键点19和关键点24,且处于额头区域,且为眉毛的最高点,因此,以关键点19和24为基准关键点。可理解,在通过人脸关键点定位人脸关键点时,每个关键点均有坐标,即像素点坐标。
因此,以关键点19和24的横坐标作为第一区域的第一边长,以关键点19或24的纵坐标的平移量作为第一区域的第二边长。本申请实施例还提供了一种确定第二边长的方法,即以人脸关键点中的两个关键点的横坐标像素差值作为平移量。如以关键点31和关键点32之间的横坐标差量作为上述平移量,以上述平移量确定第二边长。或者,以关键点31和32之间的横坐标差量作为基本单位,从而将关键点19或24的纵坐标向上平移1个基本单位,再将关键点19或24的纵坐标向上平移4个基本单位,该关键点19或24两次平移的差量即3个基本单位即为第二边长。
举例来说,选取眉毛两边最高的关键点19,24作为基准点,x1坐标为关键点19横坐标,x2坐标为关键点24的横坐标,假设像素单元union为关键点32和关键点31之间横坐标的差(这里的差值表示绝对值的差,以下类似),y1坐标为关键点19的纵坐标向上平移1个union后的坐标,y2坐标为关键点19纵坐标向上平均4个union后的坐标,则通过坐标(x1,y1,x2,y2)确定额头区域,从而截取该额头区域的图像作为第一区域的图像。如图3所示。图3是本申请实施例提供的一种确定第一区域的示意图。图3中,第一区域的长即为关键点19和24的横坐标的差,第一区域的宽即为关键点19向上平移1个union和平移4个union的差,即第一区域的宽为3个union。
可理解,本申请实施例中,第一关键点的横坐标和纵坐标的坐标系标准一致,以及与第二关键点的横坐标和纵坐标的坐标系一致。举例来说,上述第一关键点的横坐标和上述第二关键点的横坐标可以以像素坐标系中的坐标为标准,以及上述第一关键点或第二关键点的纵坐标也可以像素坐标系为标准。
103、通过肤色聚类方法确定上述第一区域中非皮肤区域的占比,在上述非皮肤区域的占比小于预定比例的情况下,将上述第一区域的图像输入至目标网络模型,输出上述抬头纹的检测结果。
其中,上述方法还包括:在上述非皮肤区域的占比不小于上述预定比例的情况下,确定上述目标图像无上述抬头纹。
也就是说,步骤103,也可为通过肤色聚类方法确定上述第一区域中非皮肤区域的占比,判断上述非皮肤区域的占比是否小于预定比例,在小于上述预定比例的情况下,将上述第一区域的图像输入至目标网络模型,输出上述抬头纹的检测结果;在不小于上述预定比例的情况下,确定上述目标图像无上述抬头纹。
以下具体分析非皮肤区域的占比的影响:
由于额头很多时候会被头发、头巾、帽子等遮挡,从而很容易对抬头纹的检测造成误判,因此在检测抬头纹之前可先通过基于肤色聚类的办法判断额头中非皮肤区域的占比。本申请实施例是基于红绿蓝(redgreenblue,rgb)颜色空间进行肤色聚类,根据rgb颜色模型找出定义好的肤色范围内的像素点,范围外的像素点设为黑色。如肤色在rgb模型下的范围满足以下约束:在均匀光照下满足以下判别式:r>95,g>40,b>20、max(r,g,b)-min(r,g,b)>15、abs(r-g)>15、r>g和r>b;在侧光拍摄环境下:r>220、g>210、b>170、abs(r-g)<=15、r>b和g>b。可理解,以上所示的约束在具体实现中,可需要同时满足,如均匀光照下满足以上所示判别式,而在侧光拍摄下需满足以上判别式。
如图4为原始额头图,图5为经过肤色聚类后的图,黑色区域为非肤色区域,白色为肤色区域,若非肤色区域占总的额头面积的比值如果不小于90%直接判断无皱纹,由此还可节省检测时间。可理解,图4所示的原始额头图仅为一种示例,该原始额头图还可以为其他颜色,这里不一一示出。
可理解,本申请实施例中,在非皮肤区域的占比小于预定示例的情况下,可以直接将第一区域的图像输入至目标网络模型来检测抬头纹的严重程度。但是,本申请实施例还提供了一种方法,可以更好的检测抬头纹,提高检测效率和准确性。如下所示:
上述将上述第一区域的图像输入至目标网络模型,输出上述抬头纹的检测结果,包括:
切割上述第一区域,获得第一数量的子区域,将包含上述第一数量的子区域的图像分别输入至上述目标网络模型;
输出上述第一数量的抬头纹的检测结果,根据有抬头纹的图像的占比确定上述抬头纹的严重程度。
具体的,将第一区域切分为第一数量的子区域,该第一数量至少为2,且每个子区域的像素大小相同。如图6所示,图6是本申请实施例提供的一种子区域的示意图。图6中,将第一区域切割成了30个子区域,该30即为第一数量。为了保证各个子区域相同,所以在切割过程中会出现有的区域无法与其他区域保持像素大小相同,因此,本申请实施例会舍弃这些区域,如图6中最下面的一行所代表的区域。
在将第一区域切换成第一数量的子区域后,可将每个子区域缩小或放大至227*227像素,从而输入至目标网络模型。在将该第一数量的子区域分别输入至目标网络模型后,输入第一数量的检测结果,该检测结果可表示子区域是否有抬头纹。在得到第一数量的检测结果后,可以根据有抬头纹的占比来确定抬头纹的严重程度。其中,抬头纹的严重程度可分为重度、中度、轻度和无。具体的,如有抬头纹的占比大于或等于0.5,则表示抬头纹重度;如有抬头纹的占比大于0.2小于0.5,则表示抬头纹中度;如有抬头纹的占比大于0.05小于或等于0.2,则表示抬头纹轻度,如有抬头纹的占比小于或等于0.05,则表示无抬头纹。可理解,以上仅为一种示例,不应理解为对本申请实施例的限定。
可理解,本申请实施例中的目标网络模型可以为该抬头纹检测装置自己训练,或者,该目标网络模型也可以为其他装置如训练装置训练好之后,发送给该抬头纹检测装置的网络模型。其中,该抬头纹检测装置自己训练目标网络模型的实现方式可参考图7所示的方法。在该目标网络模型为训练装置发送给该抬头纹检测装置的情况下,上述将上述第一区域的图像输入至目标网络模型之前,上述方法还包括:
接收来自训练装置的上述目标网络模型;其中,上述训练装置用于训练网络模型,得到上述目标网络模型。
本申请实施例中,训练装置可为任意的设备,如可为服务器,还可为终端设备等等,本申请实施例对于该训练装置不作限定。以及本申请实施例对于该训练装置如何训练目标网络模型也不作限定。
本申请实施例中,在获取到第一区域的图像后,通过肤色聚类方法先来确定非皮肤区域的占比,在该非皮肤区域的占比小于预定比例时,将该第一区域的图像输入至目标网络模型;可以有效避免由于第一区域的图像被其他物体如头发、头巾或帽子遮挡,而导致目标网络模型无法有效识别的情况;通过实施本申请实施例,可以优先确定非皮肤区域的占比,从而根据该非皮肤区域的占比来决定是否输入至目标网络模型来检测抬头纹,进而可提高目标网络模型输出的准确性,提高输出效率。
对于图1所示的抬头纹检测方法,目标网络模型为已训练好的网络模型,即对网络模型进行训练,而得到的目标网络模型。因此,本申请实施例还提供了一种训练网络模型的方法,参见图7,图7是本申请实施例提供的一种目标网络模型训练方法的流程示意图,如图7所示,该训练方法包括:
701、采集到人脸图像样本后,确定上述人脸图像样本的人脸关键点。
其中,该抬头纹检测装置可以采集该人脸图像样本,也可经过其他装置采集该人脸图像样本。以下以该抬头纹检测装置采集人脸图像样本为例,来说明如何采集人脸图像样本。上述采集人脸图像样本,包括:采集第三数量的人脸图像作为上述人脸图像样本。
其中,如上述第三数量为大于或等于300。本申请实施例中,采集人脸图像样本具体为采集人脸图像,该人脸图像至少为300张,且该人脸图像为具有额头图像的人脸图像。其中,为了更好的训练网络模型,该人脸图像样本中可包括额头有抬头纹的图像,也可包括额头无抬头纹的图像。本申请实施例对于采用何种装置采集人脸图像样本不作限定。如可采用手机来采集,也可采用照相机采集等等。
其中,采集的人脸图像样本至少为300张,是由于在训练过程中,少于300张的人脸图像样本的训练效果没有大于或等于300张的训练效果好。另一方面,采集的人脸图像样本大于或等于300张时,所训练的网络模型的泛化能力更好。
本申请实施例中,上述确定上述人脸图像样本的人脸关键点,包括:
通过第三方应用确定上述人脸图像样本的人脸关键点。
该第三方应用可以第三方工具包dlib,该人脸关键点的确定方法的实现方式可参考图1所示的具体实现方式,这里不再详述。
702、根据上述人脸图像样本的人脸关键点截取第二区域的图像。
本申请实施例中,第二区域为与额头对应的区域,如可根据人脸关键点中的关键点19和24的横坐标确定第二区域的第一边长;根据该关键点19或24的纵坐标的平移量确定第二区域的第二边长。该第二区域的截取方法具体可参考图1所示的实现方式,这里不再一一赘述。
703、切割上述第二区域,获得第二数量的子区域。
其中,由于人脸图像样本中的人脸图像至少为300张,则在对每个图像进行切割后,如每个图像均切割为40个子区域的图像,在得到40个子区域的图像后,可对每个子区域是否有抬头纹进行标记,以为后续训练网络模型做准备。本申请实施例中,在对人脸图像样本中的每个图像进行切割时,各个图像之间所切割的子区域的数量可以相同,也可以不同,本申请实施例不作限定。如人脸图像样本包括样本1和样本2,切割样本1所得到的第二数量的子区域为40个,切割样本2所得到的第二数量的子区域可以为40个,也可以为30个。
704、将上述第二数量的子区域分别输入至网络模型,训练上述网络模型,得到上述目标网络模型。
其中,该网络模型可以通过视觉几何组提出的(visualgeometrygroup,vgg)网络即vggnet来训练,也可通过googlenet或resnet来训练等等。以及本申请实施例中的网络模型还可通过alexnet网络来训练。
可理解,由于本申请实施例所示的人脸图像样本足够多,因此在训练过程中,可训练该alexnet网络的全部层即既训练卷积层,也可训练全连接层。具体的,如根据该alexnet网络输出的检测结果(如有无皱纹)与标记的检测结果的损失函数来训练该alexnet网络。
可理解,本申请实施例中的alexnet网络即为2012年,hinton课题组为了证明深度学习的潜力,首次参加imagenet图像识别比赛,其通过构建的cnn网络即alexnet一举夺得冠军,且碾压第二名的分类性能。但是,本申请实施例通过训练使其更好的适用于抬头纹检测。
本申请实施例中,通过以上方法训练网络模型,可有效提高训练的网络模型的效率,即提高了网络模型输出检测结果的准确性。
可理解,图1和图7所示的方法实施例各有侧重,其中一个实施例中未详尽描述的实现方式还可参考其他实施例。
上述详细阐述了本申请实施例的方法,下面提供了本申请实施例的装置。
参见图8,图8是本申请实施例提供的一种抬头纹检测装置的结构示意图,如图8所示,该抬头纹检测装置包括:
第一确定单元801,用于获取到目标图像后,确定上述目标图像中的人脸关键点;其中,上述目标图像为待检测抬头纹的图像;
截取单元802,用于根据上述目标图像中的人脸关键点从上述目标图像中截取第一区域的图像,上述第一区域为与额头对应的区域;
第二确定单元803,用于通过肤色聚类方法确定上述第一区域中非皮肤区域的占比;
输入单元804,用于在上述非皮肤区域的占比小于预定比例的情况下,将上述第一区域的图像输入至目标网络模型;
输出单元805,用于输出上述抬头纹的检测结果。
本申请实施例中,在获取到第一区域的图像后,通过肤色聚类方法先来确定非皮肤区域的占比,在该非皮肤区域的占比小于预定比例时,将该第一区域的图像输入至目标网络模型;可以有效避免由于第一区域的图像被其他物体如头发、头巾或帽子遮挡,而导致目标网络模型无法有效识别的情况;通过实施本申请实施例,可以优先确定非皮肤区域的占比,从而根据该非皮肤区域的占比来决定是否输入至目标网络模型来检测抬头纹,进而可提高目标网络模型输出的准确性,提高输出效率。
具体的,如图9a所示,上述输入单元804包括:
切割子单元8041,用于切割上述第一区域,获得第一数量的子区域;
输入子单元8042,用于将包含上述第一数量的子区域的图像分别输入至上述目标网络模型;
如图9b所示,上述输出单元805包括:
输出子单元8051,用于输出上述第一数量的抬头纹的检测结果;
第一确定子单元8052,用于根据有抬头纹的图像的占比确定上述抬头纹的严重程度。
如图9c所示,上述截取单元802包括:
第二确定子单元8021,用于根据上述第一关键点的横坐标和上述第二关键点的横坐标确定上述第一区域的第一边长;
第三确定子单元8022,用于根据上述第一关键点或上述第二关键点的纵坐标的平移量确定上述第一区域的第二边长;
截取子单元8023,用于根据上述第一边长和上述第二边长截取上述第一区域的图像。
可选的,如图10所示,所述装置还包括:
第三确定单元806,用于在所述非皮肤区域的占比不小于所述预定比例的情况下,确定上述目标图像无上述抬头纹。
具体的,上述第一确定单元801,还用于采集到人脸图像样本后,确定上述人脸图像样本的人脸关键点;
上述截取单元802,还用于根据上述人脸图像样本的人脸关键点截取第二区域的图像;
如图10所示,上述装置还包括:
训练单元807,用于切割上述第二区域,获得第二数量的子区域;并将上述第二数量的子区域分别输入至网络模型,训练上述网络模型,得到上述目标网络模型。
可选的,如图10所示,上述装置还包括:
接收单元808,用于接收来自训练装置的上述目标网络模型;其中,上述训练装置用于训练网络模型,得到上述目标网络模型。
本申请实施例中各个单元的实现还可以对应参照图1和图7所示的方法实施例的相应描述,这里不再一一详述。
参见图11,图11是本申请实施例提供的一种抬头纹检测装置的结构示意图,该抬头纹检测装置包括处理器1101、存储器1102和输入输出接口1103,所述处理器1101、存储器1102和输入输出接口1103通过总线相互连接。
存储器1102包括但不限于是随机存储记忆体(randomaccessmemory,ram)、只读存储器(read-onlymemory,rom)、可擦除可编程只读存储器(erasableprogrammablereadonlymemory,eprom)、或便携式只读存储器(compactdiscread-onlymemory,cd-rom),该存储器1102用于相关指令及数据。
输入输出接口1103,例如可通过该输入输出接口与其他装置进行通信等。
处理器1101可以是一个或多个中央处理器(centralprocessingunit,cpu),在处理器1101是一个cpu的情况下,该cpu可以是单核cpu,也可以是多核cpu。
具体的,各个操作的实现还可以对应参照图1和图7所示的方法实施例的相应描述。以及各个操作的实现还可对应参照图8、图9a至图9c以及图10所示的装置实施例的相应描述。
如在一个实施例中,处理器1101可用于执行步骤101所示的方法,又如该处理器1101还可用于执行第一确定单元801、截取单元802、第二确定单元803等所执行的方法。
又如在一个实施例中,处理器1101可用于采集人脸图像样本,或获取目标图像,或者,也可通过输入输出接口1103来采集该人脸图像样本或目标图像等,本申请实施例对于如何获取人脸图像样本或目标图像不作限定。
又如在一个实施例中,输入输出接口1103,还可用于执行接收单元808所执行的方法。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,该流程可以由计算机程序来指令相关的硬件完成,该程序可存储于计算机可读取存储介质中,该程序在执行时,可包括如上述各方法实施例的流程。而前述的存储介质包括:rom或随机存储记忆体ram、磁碟或者光盘等各种可存储程序代码的介质。
- 还没有人留言评论。精彩留言会获得点赞!