对人工神经网络及浮点神经网络进行量化的方法及装置与流程
本申请主张在2017年9月25日在韩国知识产权局提出申请的韩国专利申请第10-2017-0123658号的优先权,所述韩国专利申请的公开内容全文并入本申请供参考。
根据示例性实施例的装置及方法涉及人工神经网络,且更具体来说,涉及对人工神经网络进行量化。
背景技术:
人工神经网络可指用于产生人工神经元(或神经元模型)的互连集合的由计算器件实行的方法或者计算器件。人工神经元可通过对输入数据实行简单的操作来产生输出数据,且输出数据可被传送到其他神经元。作为人工神经网络的实例,深度神经网络或深度学习架构可具有多层式结构且可通过根据多个样本对各个层中的每一个进行训练来产生多个样本分布。
技术实现要素:
一个或多个示例性实施例提供一种对人工神经网络进行量化的方法,所述方法同时提供人工神经网络的高的准确性及低的计算复杂度。
一个或多个示例性实施例还提供一种用于对人工神经网络进行量化的装置,所述装置同时提供人工神经网络的高的准确性及低的计算复杂度。
根据示例性实施例的一方面,提供一种对人工神经网络进行量化的方法,所述方法包括:将所述人工神经网络的输入分布划分成多个节段;通过对所述多个节段中的每一个进行近似来产生近似密度函数;基于所述近似密度函数来计算与用于对所述人工神经网络进行量化的至少一个步长(stepsize)对应的至少一个量化误差;以及基于所述至少一个量化误差来确定用于对所述人工神经网络进行量化的最终步长。
根据另一个示例性实施例的一方面,提供一种装置,所述装置包括:存储器;以及至少一个处理器,被配置成执行存储在所述存储器中的计算机可执行流程,其中所述计算机可执行流程包括:近似器,被配置成通过对从人工神经网络的输入分布划分得到的多个节段中的每一个进行近似来产生近似密度函数,以及量化器,被配置成基于所述近似密度函数来计算与用于对所述人工神经网络进行量化的至少一个步长对应的至少一个量化误差,并根据所述至少一个量化误差来确定用于对所述人工神经网络进行量化的最终步长。
根据另一个示例性实施例的一方面,提供一种对浮点神经网络进行量化的方法,所述方法包括:将所述浮点神经网络的输入分布划分成具有均匀宽度的多个节段;通过将所述多个节段中的每一个近似成多项式来产生近似密度函数;基于所述近似密度函数来计算与至少一个分数长度对应的至少一个量化误差;以及基于所述至少一个量化误差来确定用于量化所述浮点神经网络的最终步长。
附图说明
通过结合附图阅读以下详细说明,将更清楚地理解以上及/或方面,在附图中:
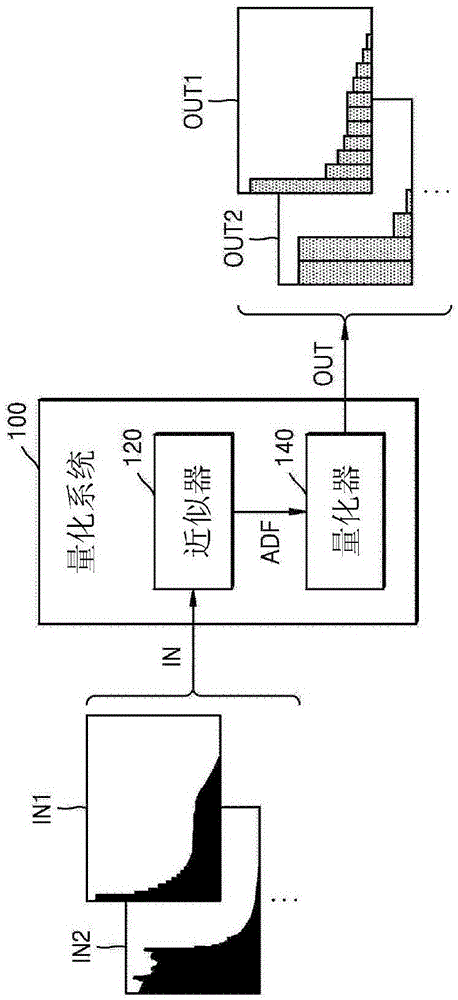
图1是示出根据示例性实施例的量化系统的方块图。
图2是示出根据示例性实施例的人工神经网络的实例的图。
图3是示出根据示例性实施例的对人工神经网络进行量化的方法的流程图。
图4是示出根据示例性实施例的对输入分布进行近似的操作的图。
图5是示出根据示例性实施例的图3所示操作s400的实例的流程图。
图6是示出根据示例性实施例的对人工神经网络进行量化的方法的流程图。
图7是示出根据示例性实施例的图3所示操作s600的实例的流程图。
图8是示出根据示例性实施例的计算量化误差的操作的实例的图。
图9是示出根据示例性实施例的计算量化误差的操作的实例的图。
图10及图11是示出根据示例性实施例的图3所示操作s600及操作s800的实例的流程图。
图12是根据示例性实施例的计算系统的方块图。
图13是根据示例性实施例的移动计算器件的方块图。
[符号的说明]
20:深度神经网络
100:量化系统
120:近似器
140:量化器
200:计算系统
210:系统存储器
212:程序
230:处理器
250、314:存储装置
270、330:输入/输出器件
290:通信连接
300:移动计算器件
310:存储器子系统
312:随机存取存储器
350:处理单元
352:中央处理器
354:图形处理单元
356:数字信号处理器
358:神经处理单元
370:网络接口
390:总线
adf:近似密度函数
ch11~ch1x、ch21~ch2y、ch31~ch3z:信道
d11:分数长度集合
d61:输入参数
d(fli)、d(fl(i-1)):量化误差
dover(fli):过载畸变
dgran(fli):粒度畸变
d(δ):量化误差
fl:分数长度
fl1:分数长度/第一分数长度
flp:分数长度/最终分数长度
fli、fl(i-1)、flmin:分数长度
f(x):近似密度函数
fi(x)、f-m(x)~fm-1(x):函数/近似函数
fp(x):概率密度函数
g(z)、g1(z)、gn(z)、g(-z):函数
i:索引
in、in1、in2、inx:输入分布
kth:多项式的次数/次数
l_1:第一层
l_2:第二层
l_3~l_n:第三层~第n层
max:最大值
min:最小值
nset:节段的数目
out:经量化的输出
out1、out2:经量化的数据
p:元素的数目/预定数目
res:结果
s100、s200、s200'、s400、s400'、s400a、s410、s430、s450、s470、s490、s600、s600'、s600a、s600b、s600c、s610c、s620、s620b、s620c、s630c、s640、s640b、s640c、s650c、s660、s660b、s660c、s800、s800'、s800b、s800c、s820c、s840c:操作
sam:样本
seg-m~seg-2、seg-1、seg0、seg1、seg2~seg(m-3)、seg(m-2)、seg(m-1)、segi:节段
w:宽度
δ:步长
-x(m+1)、-xm、-x3、-x2、-x1、x1、x2、x3~x(m-3)、x(m-2)、x(m-1)、xm:节段的边界值
1/δ、2/δ:值
具体实施方式
现将参照附图详细地提及示例性实施例。在图式中,省略与所述说明无关的部分以清楚地阐述示例性实施例,且相同的参考编号在本说明书通篇中指代相同的元件。就此来说,本发明各示例性实施例可具有不同的形式且不应被视为仅限于本文所述说明。
图1是示出根据示例性实施例的量化系统100的方块图。人工神经网络可指根据形成动物大脑的生物神经网络启发得到的计算系统。不同于根据预定条件实行任务的传统的不以神经网络为基础的算法(例如,基于规则的编程),人工神经网络可通过考虑多个样本(或实例)来学习实行任务。人工神经网络可具有其中人工神经元(或神经元)彼此连接的结构,且各神经元之间的连接可被称为突触。神经元中的每一个可处理接收到的信号并通过突触将经过处理的信号传送到另一个神经元。神经元的输出可被称为“激活”。神经元及/或突触可具有变化的权重,且由神经元处理的信号的影响可根据神经元的权重而增大或减小。具体来说,与各别神经元相关联的权重可被称为偏置(bias)。
深度神经网络或深度学习架构可具有层结构,且特定层的输出可为下一层的输入。在此种多层式结构中,可根据多个样本来训练各个层中的每一个。人工神经网络(例如深度神经网络)可由多个处理节点来实施(所述多个处理节点中的每一个对应于人工神经元),且可能需要高的计算复杂度以获得良好的结果(例如,高准确性结果),且因此可能需要大数目的计算资源。
为降低计算复杂度,可对人工神经网络进行量化。量化可指将输入值映射到数目比输入值的数目小的值,例如通过舍入来将实数映射到整数。在人工神经网络中,量化可涉及将浮点神经网络转换成固定点神经网络的过程。举例来说,在人工神经网络中,可对层激活、权重、偏置等应用量化。浮点数可包括符号、指数、及有效数字(或有效数),其中固定点数可包括整数部分及分数部分。在一些实例中,固定点数的整数部分可包括符号位。使用浮点数的人工神经网络(即,浮点神经网络)可具有较高的准确性以及计算复杂度,而使用固定点数的人工神经网络(即,固定点神经网络)可具有进一步降低的准确性及计算复杂度。
由于人工神经网络中的结果准确性与计算复杂度之间存在折衷关系,因此人工神经网络的量化可导致准确性降低,且准确性降低的程度可取决于量化方法的类型。如以下参照图式所阐述,根据示例性实施例的量化系统100可在使准确性的降低最小化的同时根据需要提供量化,且因此,可提供性能良好且复杂度降低的固定点神经网络。
量化系统100可为根据示例性实施例实行量化的任何系统,且可被称为量化装置。举例来说,量化系统100可为包括至少一个处理器及存储器的计算系统。作为非限制性实例,量化系统100可为移动计算系统(例如,膝上型计算机及智能电话)以及静止的计算系统(例如,桌上型计算机及服务器)。如图1所示,量化系统100可包括近似器120及量化器140,且近似器120及量化器140中的每一个可利用通过逻辑综合来实施的逻辑块、由处理器实行的软件块、或其组合来实施。在一些实施例中,近似器120及量化器140中的每一个可为呈由处理器执行的指令集形式的流程,且可被存储在可由处理器存取的存储器(例如,易失性存储器或非易失性存储器)中。
参照图1,量化系统100可接收输入分布in且可产生经量化的输出out。输入分布in可包括多个输入分布in1及in2(例如,激活值的分布及权重的分布),且经量化的输出out可包括分别对应于输入分布in1及in2的经量化的数据out1及out2。如图1所示,输入分布in1及in2可具有与众所周知的分布(例如,高斯分布(gaussiandistribution)、拉普拉斯分布(laplaciandistribution)、及伽马分布(gammadistribution))不同的形状。因此,基于众所周知的分布来对具有不规则形状的输入分布in1及in2实行量化可受到限制且无法提供高准确性。如以下所阐述,根据示例性实施例的量化系统100可不受限于输入分布in的形状且可对具有任意形状的输入分布in提供准确性得到提高的量化。
近似器120可接收输入分布in,且可产生近似密度函数adf并将所产生的近似密度函数adf提供到量化器140。在一些实施例中,近似器120可将输入分布in划分成多个节段且可通过对彼此独立的所述多个节段中的每一个进行近似来产生近似密度函数adf。举例来说,近似器120可将输入分布in均匀地划分成具有相同宽度的多个节段,通过对所述多个节段中的每一个进行近似来导出与所述多个节段中的每一个对应的函数,并通过组合所导出的函数来产生近似密度函数adf。因此,可产生与具有任意形状的输入分布in对应的具有低误差的近似密度函数adf,且可基于近似密度函数adf导出最优化步长,如下所述。本文中针对量化所使用的用语“误差”是指输入值与输入值的经量化值之间的差值。稍后将参照图4等来阐述近似器120的实例。
量化器140可从近似器120接收近似密度函数adf且可通过对近似密度函数adf进行量化来产生经量化的输出out。量化器140可基于近似密度函数adf来计算与步长对应的量化误差且可基于量化误差来确定最终步长。在一些实施例中,量化器140可计算与多个不同的量化步阶对应的多个量化误差,且可确定与所述多个量化误差中的最小量化误差对应的量化步阶作为最终量化步阶。另外,量化器140可基于最终量化步长来对输入分布in进行量化且可产生经量化的输出out。如上所述,可使用经量化的输出out来实现固定点神经网络且与浮点神经网络相比可在使准确性劣化最小化的同时使人工神经网络的计算复杂度降低。
图2是示出根据示例性实施例的人工神经网络的实例的图。具体来说,
图2是示意性地示出深度神经网络20的结构作为人工神经网络的实例的图。
如图2所示,深度神经网络20可包括多个层(即,第一层到第n层l_1、l_2、l_3、...、及l_n),且第一层到第n层l_1、l_2、l_3、...、及l_n中的每一个的输出可通过至少一个信道被输入到下一层。举例来说,第一层l_1可通过对样本sam进行处理来通过多个信道ch11到ch1x将输出提供到第二层l_2,且第二层l_2还可通过多个信道ch21到ch2y将输出提供到第三层l_3。最终,第n层l_n可输出结果res,且结果res可包括与样本sam相关联的至少一个值。用于分别导出第一层到第n层l_1、l_2、l_3、...及l_n的输出的信道的数目可彼此相等或彼此不同。举例来说,第二层l_2的沟道ch21到ch2y的数目与第三层l_3的沟道ch31到ch3z的数目可彼此相等或彼此不同。
样本sam可为将由深度神经网络20处理的输入数据。举例来说,样本sam可为包含人用笔书写的字母的图像,且深度神经网络20可通过从图像识别所述字母来输出含有表示所述字母的值的结果res。结果res可包括对应于不同字母(即,候选项)的多个概率,且不同字母中最有可能的字母可对应于最高概率。深度神经网络20的第一层到第n层l_1、l_2、l_3、...、及l_n中的每一个可通过基于通过学习包含字母的多个图像而产生的值(例如,权重、偏置等)对样本sam或前一层的输出进行处理来产生各自的输出。
根据示例性实施例的用于对人工神经网络进行量化的方法及装置(例如,图1中的量化系统100)可以人工神经网络(例如,深度神经网络20)的层为单位及/或以人工神经网络的信道为单位来获得输入分布。举例来说,由图1所示量化系统100接收到的输入分布in可从由一个层通过多个信道生成的输出获得,且也可从与一个信道对应的输出获得。
图3是示出根据示例性实施例的对人工神经网络进行量化的方法的流程图。举例来说,图3所示量化方法可由图1所示量化系统100来实行。在下文中,将参照图1阐述图3。
参照图3,在操作s200中,可实行将输入分布in划分成多个节段的操作。举例来说,近似器120可将输入分布in划分成两个或更多个节段。在一些实施例中,近似器120可基于输入分布in的最大值及最小值来划分输入分布in。在一些实施例中,近似器120可基于从量化系统100外部提供的输入参数来划分输入分布in。稍后将参照图4来阐述操作s200的实例。
在操作s400中,可实行产生近似密度函数adf的操作。举例来说,近似器120可对通过对彼此独立的输入分布in进行划分获得的节段进行近似,且可基于各种方式来对节段中的每一个进行近似。在一些示例性实施例中,近似器120可根据给定次数的多项式来对节段中的每一个进行近似。另外,近似器120可根据相同的方式(例如,相同次数的多项式)来对各个节段进行近似,或者可根据不同的方式(例如,不同次数的多项式)来对各个节段进行近似。稍后将参照图5来阐述操作s400的实例。
在操作s600中,可实行计算量化误差的操作。举例来说,量化器140可基于近似密度函数adf来计算与给定步长对应的量化误差。在一些示例性实施例中,量化器140可将量化误差表示为步长的函数,且可计算与多个不同的步长对应的多个量化误差。在一些示例性实施例中,可基于过载畸变(overloaddistortion)及粒度畸变(granulardistortion)来计算量化误差。稍后将参照图7至图11来阐述操作s600的实例。
在操作s800中,可实行确定最终步长的操作。举例来说,量化器140可确定与最小量化误差对应的步长。在一些实施例中,量化器140可选择与多个步长对应的多个量化误差中的一者。在一些实施例中,量化器140可基于被表示为步长的函数的量化误差的特性来确定步长。
图4是示出根据示例性实施例的对输入分布in进行近似的操作的图。举例来说,图4示出其中在图3所示操作s200及s400中对输入分布in进行处理的操作的实例。尽管图4示出其中输入分布in被划分成偶数个节段的实例,然而应理解,输入分布in可被划分成奇数个节段。
参照图4,输入分布inx可具有最大值max及最小值min且可具有介于最大值max与最小值min之间的值处的任何密度。如上所述,为对输入分布inx进行近似,当m是大于或等于1的整数时,可将输入分布inx划分成2m个节段seg-m、...、及seg(m-1)。如图4所示,包括输入分布inx的最大值max及最小值min的节段可被划分成具有相同宽度w的2m个节段seg-m...、及seg(m-1)。举例来说,在包括最大值max及最小值min的区段[-x(m+1),xm]中,输入分布inx可被划分成2m个节段seg-m...、及seg(m-1)。包括最大值max的节段seg(m-1)可对应于区段[x(m-1),xm],包括最小值min的节段seg-m可对应于区段[-x(m+1),-xm],且‘xm-x(m-1)’可与‘-xm-(-x(m+1))’匹配。换句话说,节段seg-m及seg(m-1)可具有均匀的宽度。
在一些示例性实施例中,不同于图4所示实例,输入分布inx可被划分成具有不同宽度的节段。举例来说,输入分布inx可被划分成宽度与输入分布inx的密度成反比的节段。这样一来,由于输入分布inx被划分成2m个节段seg-m...、及seg(m-1)且2m个节段seg-m...、及seg(m-1)中的每一个被独立地近似,因此可将具有任意形状的输入分布近似成近似密度函数f(x)(例如,图1中的近似密度函数adf),且可基于近似密度函数f(x)来计算量化误差,如下所述。在下文中,为便于说明起见,将参照图4所示实例来阐述示例性实施例,然而应理解,示例性实施例并非仅限于此。
图5是示出根据示例性实施例的图3所示操作s400的实例的流程图。如以上参照图3所阐述,在图5所示操作s400a中可实行产生近似密度函数的操作。在下文中,将参照图4阐述图5。
参照图5,在操作s410中,可实行将变量初始化的操作。如图5所示,可将索引i设定成-m,即与图4中的最小值min对应的节段seg-m的索引。
在操作s430中,可实行对节段segi中的输入分布inx进行近似的操作。也就是说,可单独地对图4中的2m个节段seg-m...、及seg(m-1)中的每一个进行近似。输入分布inx的节段segi可通过各种方式进行近似。举例来说,可将节段segi近似成预定次数的多项式(例如,正整数或零),此仅作为非限制性实例,并且可使用切比雪夫近似(chebyshevapproximation)、remez算法等。在图4所示实例中,示出其中将输入分布inx的2m个节段seg-m...、及seg(m-1)中的每一个近似成一次多项式的情形。然而可理解,示例性实施例并非仅限于此。通过对输入分布inx的节段segi进行近似,可产生函数fi(x)。
在操作s450中,可判断索引i是否与m-1匹配。换句话说,可判断是否已完成对与最大值max对应的节段segm-1的近似。当索引i不与m-1匹配时,也就是说,当仍存在要进行近似的节段时,在操作s470中可实行将索引i递增1的操作,且随后,可在操作s430中实行对节段segi进行近似的操作。另一方面,当索引i与m-1匹配时,即,当输入分布inx的2m个节段seg-m...、及seg(m-1)分别被近似成2m个函数f-m(x)...、及fm-1(x)时,随后可实行操作s490。
在操作s490中,可实行对2m个近似函数f-m(x)...及fm-1(x)进行组合的操作,且可产生近似密度函数f(x)。举例来说,可由以下方程式1来定义近似密度函数f(x)。
[方程式1]
近似密度函数f(x)在节段的边界处可为连续的或不连续的。换句话说,根据近似方法,在操作s430中进行近似的函数fi(x)可具有与节段segi的边界值(即,xi及x(i+1))处的输入分布inx的密度匹配的值、或者不同于输入分布inx的密度的值。在一些实施例中,当近似函数fi(x)是使用多项式最小化均方误差(meansquarederror,mse)从节段segi近似得到时,fi(xi)及fi(x(i+1))可具有与输入分布inx不同的值,且近似密度函数fx可为不连续的。另一方面,在一些示例性实施例中,近似函数fi(x)可被近似成具有与节段segi的边界值匹配的值,且近似密度函数f(x)可为连续的。
在一些示例性实施例中,可额外地实行将近似密度函数f(x)归一化的操作。举例来说,可将近似密度函数f(x)归一化成满足以下方程式2的概率密度函数fp(x),且可使用概率密度函数fp(x)来计算量化误差作为近似密度函数。
[方程式2]
图6是示出根据示例性实施例的对人工神经网络进行量化的方法的流程图。与图3所示量化方法相比,图6所示量化方法可包括接收及获得输入参数d61。举例来说,图6所示量化方法可由图1所示量化系统来实行,且将省略图6的与图3的说明相同的说明。
参照图6,在操作s100中,可实行获得输入参数d61的操作。举例来说,量化系统100可从外部接收输入参数d61,输入参数d61包括与量化相关联的值。如图6所示,输入参数d61可包括节段的数目nset及多项式的次数kth中的至少一个。输入参数d61中所包括的值可用于随后的操作中。输入参数d61可包括节段的数目nset及多项式的次数kth中的仅一个,且还可包括除节段的数目nset及多项式的次数kth之外的其他值。
在操作s200'中,可实行将输入分布in划分成多个节段的操作。举例来说,量化系统100的近似器120可根据输入参数d61中所包括的节段的数目nset来对输入分布in进行划分。
在操作s400'中,可实行产生近似密度函数adf的操作。举例来说,量化系统100的近似器120可根据输入参数d61中所包括的多项式的次数kth来将多个节段中的每一个近似成次数为kth的多项式。
在操作s600'中,可实行计算量化误差的操作,且接着在操作s800'中,可实行确定步长的操作。
图7是示出根据示例性实施例的图3所示操作s600的实例的流程图。如以上参照图3所阐述,在图7所示操作s600a中可实行基于近似密度函数adf来计算量化误差的操作。参照图7,操作s600a可包括多个操作s620、s640及s660。在下文中,将参照图4所示实例阐述图7。
在操作s620中,可实行计算与步长对应的过载畸变的操作。过载畸变可表示当对有限面积中的输入实行量化时因输入超出有限面积而造成的误差。当根据n个量化级别以及区段[-l,l)中的步长δ对图4中的近似密度函数f(x)实行量化时,可建立由方程式l=nδ/2表示的关系。另外,当一个步阶的步长是si=[xq,i-(δ/2),xq,i+(δ/2))时,则可建立[-l,l)=s1∪s2∪...∪sn,且在此种情形中,可由以下方程式3来定义过载畸变dover(δ)。
[方程式3]
在操作s640中,可实行计算与步长对应的粒度畸变的操作。输入的有限区内的量化结果之间的间距可被称为粒度,且粒度畸变可表示因间距造成的误差。在与用于定义过载畸变dover(δ)的条件相同的条件下,可由以下方程式4来定义粒度畸变dgran(δ)。
[方程式4]
在操作s660中,可实行将过载畸变与粒度畸变相加的操作。也就是说,可通过方程式5来计算量化误差d(δ)。
[方程式5]
d(δ)=dove7(δ)+dgran(δ)
根据方程式3、方程式4及方程式5,量化误差d(δ)可被表达为步长的函数。
图8是示出根据示例性实施例的计算量化误差的操作的实例的图。具体来说,图8示出计算粒度畸变dgran(δ)的实例,且在此种情形中,假设图4中的2m个节段seg-m...、及seg(m-1)中的每一个的宽度w及步长δ彼此匹配(即,n=2m),且近似密度函数f(x)包括其中2m个节段seg-m...及seg(m-1)中的每一个被近似成一次多项式的函数。另外,假设近似密度函数f(x)通过方程式2被归一化成fp(x)。
参照图8,当通过方程式6将2m个节段seg-m...、及seg(m-1)所近似成的2m个函数f-m(x)...、及fm-1(x)转换成2m个函数g-m(z)...、及g(m-1)(z)时,近似密度函数f(x)可被转换成具有处于区段[-δ/2,δ/2)中的有效值的函数g(z)。
[方程式6]
如在图8的左下部分中所示,n个函数g1(z)...、及gn(z)可在区段[-δ/2,δ/2)中具有有效值。如在图8的左上部分中所示,通过将n个函数g1(z)...、及gn(z)相加获得的函数g(z)也可在区段[-δ/2,δ/2)中具有有效值。由于n个函数g1(z)...、及gn(z)中的每一个是一次多项式,因此函数g(z)也可为一次多项式。因此,函数g(z)可由在区段[-δ/2,δ/2)中具有恒定斜率的直线表示。另外,由于近似密度函数f(x)是归一化的,因此函数g(z)在z=0处可具有值1/δ(即,g(0)=1/δ)。
当近似密度函数f(x)被转换成在区段[-δ/2,δ/2)中具有有效值的函数g(z)时,粒度畸变dgran(δ)可通过方程式7来定义。
[方程式7]
如在图8的右部分中所示,当在区段[0,δ/2)中对函数g(z)进行积分时,粒度畸变dgran(δ)可通过以下方程式8来定义且可被表示为步长δ的简化函数。
[方程式8]
图9是示出根据示例性实施例的计算量化误差的操作的实例的图。具体来说,图9示出在与图8所示实例相同的条件下计算过载畸变dover(δ)的实例。
在固定点神经网络中,步长δ可与分数长度fl相关。举例来说,当步长δ是2的幂(例如,δ=2-k,其中k是正整数)时,分数长度fl及步长δ可满足以下方程式9所示关系。
[方程式9]
δ=2-fl
换句话说,确定步长δ可对应于确定分数长度fl,且量化误差d(δ)还可被表示为分数长度fl的函数d(fl)。在下文中,假设步长δ及分数长度fl满足图9所示关系。
参照图9,可通过以下方程式10来计算过载畸变dover(fl)。
[方程式10]
其中
且
xn-int,s(fl)=-2-fl2bw-1-2-fl-1。
在方程式10中,flmin表示防止最大值max饱和的分数长度。当固定点神经网络的带符号的位宽度是bw时,可通过方程式11来定义flmin。
[方程式11]
flmin=bw-1-ceil(log2max(abs(x)))
图10及图11是示出根据示例性实施例的图3所示操作s600及操作s800的实例的流程图。如以上参照图3所述,在图10所示操作s600b及图11所示操作s600c中可实行计算量化误差的操作,且在图10所示操作s800b及图11所示操作s800c中可实行确定步长的操作。如以上参照图9所述,确定步长对应于确定分数长度,且因此,将基于分数长度fl来阐述图10及图11所示实例。
参照图10,在一些示例性实施例中,可使用包括多个分数长度fl1到flp的分数长度集合d11来确定分数长度fl。在一些实施例中,可通过基于固定点神经网络的位宽度bw而确定的范围来确定分数长度集合d11。如图10所示,计算量化误差的操作s600b可包括多个操作s620b、s640b及s660b,且在操作s600b之后可实行操作s800b。
在操作s620b中,可实行从分数长度集合d11中的第一分数长度fl1到分数长度flp依序选择分数长度fli的操作。换句话说,为计算分别与分数长度集合d11中所包括的所述多个分数长度fl1到flp对应的量化误差,可依序选择所述多个分数长度fl1到flp。
在一些示例性实施例中,分数长度集合d11可包括按照升序排列的多个分数长度fl1到flp(例如,一次递增1的次序),且因此,具有较高索引的分数长度可大于具有较低索引的分数长度。在一些示例性实施例中,分数长度集合d11可包括按照降序排列的多个分数长度fl1到flp(例如,一次递减1的次序),且因此,具有较高索引的分数长度可小于具有较低索引的分数长度。在一些示例性实施例中,分数长度集合d11可包括按照任何次序排列的多个分数长度fl1到flp。
在操作s640b中,可实行计算量化误差d(fli)的操作。举例来说,如图10所示,可分别计算根据分数长度fli的过载畸变dover(fli)及粒度畸变dgran(fli),且可将量化误差d(fli)作为过载畸变dover(fli)与粒度畸变dgran(fli)之和进行计算。在一些示例性实施例中,可根据上述方程式来计算过载畸变dover(fli)与粒度畸变dgran(fli)。因此,由于在图3所示操作s400中产生的近似密度函数f(x),因此可准确地且容易地计算根据分数长度fli的量化误差。
在操作s660b中,可实行判断索引i是否与分数长度集合d11中的元素的数目p匹配的操作。换句话说,可实行判断是否已完成对分别与分数长度集合d11中的分数长度fl1到flp对应的量化误差d(fl1)到d(flp)的计算的操作。当索引i不与分数长度集合d11的元素的数目p匹配时,可选择根据在操作s620b中发生改变的索引i的分数长度fli。否则,随后可实行操作s800b。
在操作s800b中,可实行确定与最小量化误差对应的分数长度fl的操作。因此,所确定的分数长度fl(或步长)可对应于实质上使量化误差最小化的分数长度,且因此,人工神经网络的量化可提供高准确性。
参照图11,在一些示例性实施例中,可基于作为分数长度fl的函数的量化误差的特性来确定分数长度。举例来说,当分数长度从由方程式11定义的分数长度flmin增大时,作为分数长度fl的函数的量化误差可具有逐渐增大的形状或向下凸出的形状。换句话说,当在针对从方程式11的分数长度flmin依序增大的分数长度来计算量化误差的过程中发生比先前计算的量化误差大的量化误差时,可停止针对额外的分数长度来计算量化误差。如图11所示,计算量化误差的操作s600c可包括多个操作s610c、s620c、s630c、s640c、s650c及s660c,且在操作s600c之后可实行包括操作s820c及s840c的操作s800c。
在操作s610c中,可实行计算分数长度flmin的操作。举例来说,如以上参照图9所述,flmin可表示防止最大值max饱和的分数长度,且分数长度flmin可根据方程式11来计算。
在操作s620c中,可实行将变量初始化的操作。举例来说,如图11所示,索引i可被设定成1且分数长度fli可被设定成在操作s610c中计算的flmin。
在操作s630c中,可实行计算量化误差d(fli)的操作。举例来说,如图11所示,可计算根据分数长度fli的过载畸变dover(fli)及粒度畸变dgran(fli),且可将量化误差d(fli)作为过载畸变dover(fli)与粒度畸变dgran(fli)之和进行计算。在一些示例性实施例中,可根据上述方程式来计算过载畸变dover(fli)与粒度畸变dgran(fli)。
在操作s640c中,可实行用于将当前计算的量化误差d(fli)与先前计算的量化误差d(fl(i-1))进行比较的操作。换句话说,可实行将具有索引i的分数长度fli的量化误差d(fli)与具有前一索引i-1的分数长度fl(i-1)的量化误差d(fl(i-1))进行比较的操作。在当前计算的量化误差d(fli)大于先前计算的量化误差d(fl(i-1))时,可在操作s840c中确定用于计算前一量化误差d(fl(i-1))的分数长度fl(i-1),而如果当前计算的量化误差d(fli)不大于先前计算的量化误差d(fl(i-1))时,随后可实行操作s650c。
在操作s650c中,可实行将索引i与预定数目p进行比较的操作。预定数目p可为任何正整数,且可小于固定点神经网络的位宽度。当索引i与预定数目p彼此匹配时,也就是说,当与p个不同的分数长度对应的量化误差连续减小时,可在操作s820c中实行用于确定最终分数长度flp的操作。另一方面,当索引i与预定数目p不彼此匹配时,在操作s660c中,可使分数长度fli及索引i递增1,且随后可实行操作s630c。
图12是根据示例性实施例的计算系统200的方块图。在一些示例性实施例中,图1所示量化系统100可由图12所示计算系统200来实施。如图12所示,计算系统200可包括系统存储器210、处理器230、存储装置250、输入/输出(input/output,i/o)器件270及通信连接290。计算系统200的组件可例如通过总线进行互连。
系统存储器210可包括程序212。程序212可使处理器230实行根据示例性实施例的人工神经网络的量化。举例来说,程序212可包括可由处理器230执行的多个指令,且当处理器230执行程序212中的多个指令时,可执行人工神经网络的量化。作为非限制性实例,系统存储器210可包括例如静态随机存取存储器(staticrandomaccessmemory,sram)及动态随机存取存储器(dynamicrandomaccessmemory,dram)等易失性存储器,或者可包括例如闪存存储器等非易失性存储器。
处理器230可包括能够执行任何指令集(例如,英特尔架构-32(intelarchitecture-32,ia-32)、64位扩展英特尔架构-32、x86-64、增强risc性能优化-性能计算架构(performanceoptimizationwithenhancedrisc–performancecomputing,powerpc)、可扩充处理器架构(scalableprocessorarchitecture,sparc)、无内部互锁流水级的微处理器(microprocessorwithoutinterlockedpipedstages,mips)、高级精简指令集机器(advancedriscmachine,arm)及英特尔架构-64)的至少一个核心。处理器230可执行存储在系统存储器210中的指令且可通过执行程序212来实行人工神经网络的量化。
即使被供应到计算系统200的电力被切断时,存储装置250仍可保持所存储的数据。举例来说,存储装置250可包括非易失性存储器(例如,电可擦只读存储器(electricallyerasableread-onlymemory,eeprom)、闪速存储器、相变随机存取存储器(phasechangerandomaccessmemory,pram)、电阻式随机存取存储器(resistancerandomaccessmemory,rram)、纳米浮栅存储器(nanofloatinggatememory,nfgm)、聚合物随机存取存储器(polymerrandomaccessmemory,poram)、磁性随机存取存储器(magneticrandomaccessmemory,mram)、或铁电式随机存取存储器(ferroelectricrandomaccessmemory,fram)),或可包括存储装置媒体(例如,磁带、光盘、或磁盘)。在一些示例性实施例中,存储装置250可能够从计算系统200分离。
在一些示例性实施例中,存储装置250可存储用于根据示例性实施例对人工神经网络进行量化的程序212,且来自存储装置250的程序212或程序212的至少一部分可在处理器230执行程序212之前被加载到系统存储器210中。在一些示例性实施例中,存储装置250可存储以编程语言写成的文件,且由编译器(compiler)等从所述文件产生的程序212或程序212的至少一部分可被加载至系统存储器210中。
在一些示例性实施例中,存储装置250可存储将由处理器230处理的数据及/或经过处理器230处理的数据。举例来说,存储装置250可存储与图1所示输入分布in及/或图6所示输入参数d61对应的数据,可存储与图1所示经量化的输出out对应的数据,且可存储在量化期间产生的数据(例如,步长及分数长度)。
输入/输出器件270可包括输入器件(例如,键盘及定点器件(例如,鼠标、触摸板等)),且可包括输出器件(例如,显示器件及打印机)。举例来说,用户可通过输入/输出器件270来触发由处理器230执行程序212,可输入图6所示输入参数d61,且可检查图1所示经量化的输出out及/或错误消息。
通信连接290(例如,通信接口、网络适配器、天线等)可提供对计算系统200外部的网络的存取。举例来说,网络可包括多个计算系统与通信链路,且通信链路可包括有线链路、光学链路、无线链路、或任何其他类型的链路。
图13是根据示例性实施例的移动计算器件300的方块图。在一些示例性实施例中,在移动计算器件300中可实施根据示例性实施例量化的固定点神经网络。作为非限制性实例,移动计算器件300可为由电池供电或自行发电的任何移动电子器件(例如,移动电话、平板个人电脑(personalcomputer,pc)、可穿戴器件、及/或物件互联网器件(例如,物联网器件))。
如图13所示,移动计算器件300可包括存储器子系统310、输入/输出(i/o)器件330、处理单元350及网络接口370。存储器子系统310、输入/输出器件330、处理单元350及网络接口可通过总线390来彼此通信。在一些示例性实施例中,存储器子系统310、输入/输出器件330、处理单元350及网络接口中的至少两者可包括在一个封装中作为系统级芯片(system-on-chip,soc)。
存储器子系统310可包括随机存取存储器312及存储装置314。随机存取存储器312及/或存储装置314可存储由处理单元350执行的指令、以及经过处理单元350处理的数据。举例来说,随机存取存储器312及/或存储装置314可存储变量(例如,人工神经网络的信号、权重及偏置)且还可存储人工神经网络的人工神经元(或计算节点)的参数。在一些示例性实施例中,存储装置314可包括非易失性存储器。
处理单元350可包括中央处理器(centralprocessingunit,cpu)352、图形处理单元(graphicsprocessingunit,gpu)354、数字信号处理器(digitalsignalprocessor,dsp)356、及神经处理单元(neuralprocessingunit,npu)358。不同于图13中所示,在一些示例性实施例中,处理单元350可包括中央处理器352、图形处理单元354、数字信号处理器356、及神经处理单元358中的仅一些。
中央处理器352可控制移动计算器件300的总体操作。举例来说,中央处理器352可响应于通过输入/输出器件330接收的外部输入来直接实行特定任务,或者可指示处理单元350的其他组件来实行任务。图形处理单元354可产生通过输入/输出器件330中的显示器件输出的图像的数据且可对从输入/输出器件330中的照相机接收到的数据进行编码。数字信号处理器356可通过对数字信号(例如,从网络接口370提供的数字信号)进行处理来产生有用的数据。
作为人工神经网络的专用硬件的神经处理单元358可包括与构成人工神经网络的至少一些人工神经元对应的多个计算节点,且所述多个计算节点中的至少一些计算节点可并行地处理信号。根据示例性实施例进行量化的人工神经网络(例如,深度神经网络)具有低计算复杂度以及高准确性,且因此可易于在图13所示移动计算器件300中实施,可具有快速的处理速度,且还可由例如简单的且小规模的神经处理单元来实施。
输入/输出器件330可包括输入器件(例如,触摸式输入器件、声音输入器件及照相机)以及输出器件(例如,显示器件及声音输出器件)。举例来说,当通过声音输入器件输入用户的声音时,所述声音可由在移动计算器件300中实施的深度神经网络识别出,且可触发对应的操作。另外,当通过照相机输入图像时,图像中的物件可由在移动计算器件300中实施的深度神经网络识别出,且可将例如虚拟现实等输出提供给用户。网络接口370可为移动计算器件300提供对移动通信网络(例如,长期演进(longtermevolution,lte)或5g)的存取且可提供通过无线保真(wirelessfidelity,wi-fi)协议对局域网(例如,无线局域网(wirelesslocalnetwork,wlan))的存取。
尽管已参照本公开的示例性实施例具体示出并阐述了本公开,然而应理解,在不背离以上权利要求书的精神及范围的条件下,可在本文中作出形式及细节上的各种改变。
- 还没有人留言评论。精彩留言会获得点赞!