一种基于广义点集距离的信息个性化推荐及提示方法与流程
本发明涉及个性化推荐系统技术领域,具体涉及一种基于广义点集距离的信息个性化推荐及提示方法。
背景技术
个性化推荐系统旨在依据一定的算法向用户提供个性化的信息服务和决策支持,目前广泛应用在新闻推荐、商务推荐、娱乐推荐、学习推荐、生活推荐、决策支持等多个领域。
得益于广泛的应用,个性化推荐已成为学术界与工业界的研究热点。已有的信息个性化推荐技术包括基于协同过滤的推荐系统、基于点集距离的推荐系统等,后者是最接近本发明的现有技术。
基于协同过滤的推荐系统利用某兴趣相投、拥有共同经验之群体的喜好来推荐用户感兴趣的信息,但对于新信息、新用户推荐效果较差,即存在“冷启动”问题。
基于点集距离的推荐系统,适合对具有标签的信息进行个性化推荐,即直接向符合该标签的用户推荐信息,本质就是当点集距离为0时,推荐该信息,这里的点就是用户属性,集就是符合拟推荐信息适用的用户属性集合(范围)。该方法仅用面向数值属性的普通点集距离,未包括其它距离方法,如海明距离等;并且该方法未对“差点就符合推荐要求”的用户进行推荐及提示其欠缺条件。
技术实现要素:
本发明的目的在于针对现有技术中的不足之处,提供一种兼容更多数据类型,对接近个性化推荐要求的用户,给出其欠缺条件提示的基于广义点集距离的信息个性化推荐及提示方法。
为达此目的,本发明采用以下技术方案:
一种基于广义点集距离的信息个性化推荐及提示方法,包括如下步骤;
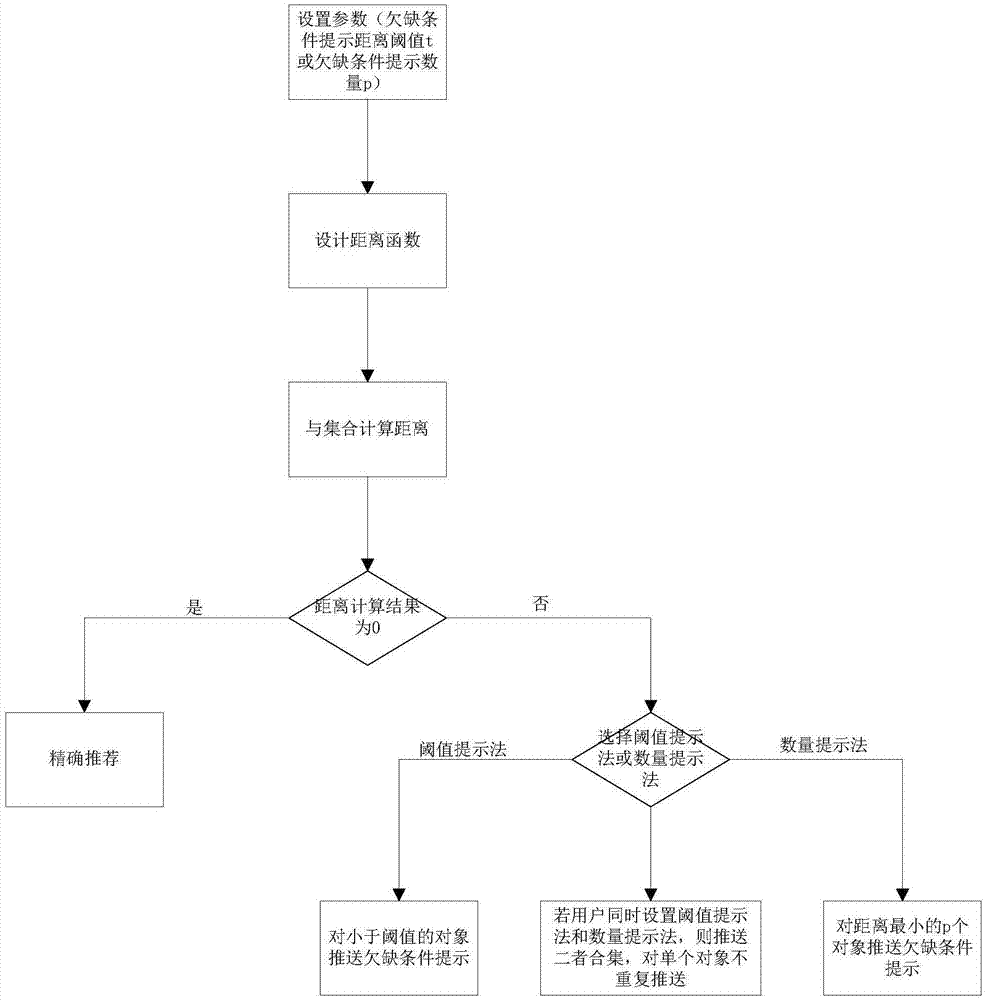
步骤a,设置参数;用户从阈值提示法和数量提示法中至少选择一项作为提示方法,并设置对应的欠缺条件提示距离阈值t或欠缺条件提示数量p;
步骤b,设置距离函数;根据实际使用的点集距离设计相应的距离函数d(x,y);设推荐信息适用的用户属性集合(即广义点集距离的“集”)为x,某用户属性(即广义点集距离的“点”)为y,并令ximin表示数值属性范围xi的最小值,令ximax表示数值属性范围xi的最大值,令yi表示用户属性的第i个数值属性的值;所述用户属性包括m个数值属性(即0≤i≤m)和n个非数值属性(其中m≥0,n≥0,并且m+n≥1),广义点集的所述距离函数d(x,y)表示如下:
其中c(xi,yi)为用户对非数值属性自行定义的距离函数;
步骤c,计算距离值d并推送相关信息;若距离值d=0,则符合精准推荐条件,直接向其推送相关信息;若距离值d不为0,则不直接推送信息,根据用户设定的提示法作相应处理;如果用户设定的是阈值提示法,则对距离值d小于阈值t的所有对象推送欠缺条件提示;如果用户设定的是数量提示法,则对距离值d最小的p个对象推送欠缺条件提示;如果用户同时设定阈值提示法和数量提示法,则推送阈值提示法和数量提示法推送结果的合集。
更进一步的说明,对距离值d小于阈值t的所有对象推送欠缺条件提示信息时,使用逐个计算距离并推送或对所有对象计算距离之后,一次性对距离值d小于阈值t的所有对象批量推送的方法;对距离值d最小的p个对象推送欠缺条件提示信息时,逐个计算距离并保留距离值最小的p个对象,再一次性批量推送。
更进一步的说明,进行逐个计算距离并保留最小的p个对象这一操作时,根据距离值建立大根堆结构,维护最小的p个对象在所述大根堆上。
更进一步的说明,所述距离函数适用数值属性时还可以采用的包括欧氏距离、曼哈顿距离或标准化欧氏距离表示的距离函数;假设数据x、y分别有n个数值属性,则欧氏距离、曼哈顿距离或标准化欧氏距离表示的距离函数的计算方法分别如下:
欧氏距离:
曼哈顿距离:
标准化欧氏距离:
更进一步的说明,所述距离函数适用非数值属性时,若用户属性为字符串的表现形式,则使用海明距离或编辑距离的计算方式,或用户自定义的计算方式;海明距离的计算公式为:
其中a、b为字符串;
编辑距离的计算公式为:
其中a、b为字符串。
更进一步的说明,步骤a中,若用户选择提示方法但没设置欠缺条件提示距离阈值t或欠缺条件提示数量p,则使用预设的缺省值。
更进一步的说明,步骤c中,推送的阈值提示法和数量提示法推送结果的合集为阈值提示法和数量提示法推送结果的并集,且对重复的单个推送对象不再重复推送。
更进一步的说明,进行逐个计算距离并保留最小的p个对象这一操作时,还可以使用插入排序,或者在所有对象计算完之后,使用快速排序或归并排序的方式。
更进一步的说明,用户可对所述距离函数d(x,y)进行修正改进,对数值属性和非数值属性设定权重加成;
权重加成的计算公式为:
其中w1、w2、w3分别为对象x、y的第1、2、3个属性的权重。
更进一步的说明,当用户属性为非数值属性时,若实际的用户属性在设定的用户属性集合中,则距离值为0;若实际的用户属性不在设定的用户属性集合中,则距离值由用户自定义的距离函数c(xi,yi)计算得出。
本发明的有益效果:
(1)将普通的点集距离发展为广义点集距离,以兼容更多数据类型。
(2)兼顾信息精准推荐与欠缺条件提示信息推送,对接近个性化推荐要求的用户进行排序,给出其欠缺条件提示,提高推送的精准度和用户的区分度。
附图说明
下面结合附图和实施例对本发明进一步说明。
图1是本发明的一个实施例的流程图。
具体实施方式
下面结合附图并通过具体实施方式来进一步说明本发明的技术方案。
如图1所示,一种基于广义点集距离的信息个性化推荐及提示方法,包括如下步骤;
步骤a,设置参数;用户从阈值提示法和数量提示法中至少选择一项作为提示方法,并设置对应的欠缺条件提示距离阈值t或欠缺条件提示数量p;
步骤b,设置距离函数;根据实际使用的点集距离设计相应的距离函数d(x,y);设推荐信息适用的用户属性集合(即广义点集距离的“集”)为x,某用户属性(即广义点集距离的“点”)为y,并令ximin表示数值属性范围xi的最小值,令ximax表示数值属性范围xi的最大值,令yi表示用户属性的第i个数值属性的值;所述用户属性包括m个数值属性(即0≤i≤m)和n个非数值属性(其中m≥0,n≥0,并且m+n≥1),广义点集的所述距离函数d(x,y)表示如下:
其中c(xi,yi)为用户对非数值属性自行定义的距离函数;
步骤c,计算距离值d并推送相关信息;若距离值d=0,则符合精准推荐条件,直接向其推送相关信息;若距离值d不为0,则不直接推送信息,根据用户设定的提示法作相应处理;如果用户设定的是阈值提示法,则对距离值d小于阈值t的所有对象推送欠缺条件提示;如果用户设定的是数量提示法,则对距离值d最小的p个对象推送欠缺条件提示;如果用户同时设定阈值提示法和数量提示法,则推送阈值提示法和数量提示法推送结果的合集。
将用户属性分为数值类和非数值类两大类,从而将普通的点集距离发展为广义点集距离,可以兼容更多数据类型。对于数值属性的用户属性进行系统预设距离函数的计算或通过用户自行设定的距离函数进行运算,对于非数值属性的用户属性进行自行设定的距离函数的运算。通过对运算结果的分析,用户从阈值提示法和数量提示法至少选择一个方式对完全符合以及接近个性化推荐要求的用户给出其欠缺条件提示。例如信息推荐的要求是年龄30-50岁(这是一个集合,包括30、31、32……50一共21个整数),而拟推荐对象的年龄是28岁,那么可以使用28与30的差的绝对值与信息推荐要求年龄跨度的商为距离函数,这个距离的值d为0.1(即|28-30|/(50-30)=0.1)。而如果拟推荐对象的年龄是32,由于32包含在集合30-50岁中,因此它们的距离值d是0。从而可以将完全符合推荐要求的用户和接近推荐要求的用户进行区分,并分别进行推送,使用户推送的区分度和精准度更高。
更进一步的说明,对距离值d小于阈值t的所有对象推送欠缺条件提示信息时,使用逐个计算距离并推送或对所有对象计算距离之后,一次性对距离值d小于阈值t的所有对象批量推送的方法;对距离值d最小的p个对象推送欠缺条件提示信息时,逐个计算距离并保留距离值最小的p个对象,再一次性批量推送。
由于阈值提示法需要分别计算每一个对象的距离值,然后逐个进行比对判断,因此逐个发送或批量发送不会影响程序的运行。而数量提示法必须从所有对象中挑选处距离值最小的p个对象,因此必须将全部对象的距离值计算出来后进行排序然后再批量发送才能保证程序的正常运行。
更进一步的说明,进行逐个计算距离并保留最小的p个对象这一操作时,根据距离值建立大根堆结构,维护最小的p个对象在所述大根堆上。
堆排序是指利用堆积树(堆)这种数据结构所设计的一种排序算法,它是选择排序的一种。可以利用数组的特点快速定位指定索引的元素。堆分为大根堆和小根堆,是完全二叉树。而大根堆的要求是每个节点的值都不大于其父节点的值。在数组的非降序排序中,需要使用的就是大根堆,因为根据大根堆的要求可知,最大的值一定在堆顶。因此可以满足距离计算的需求。
更进一步的说明,所述距离函数适用数值属性时还可以采用的包括欧氏距离、曼哈顿距离或标准化欧氏距离表示的距离函数;
假设数据x、y分别有n个数值属性,则欧氏距离、曼哈顿距离或标准化欧氏距离表示的距离函数的计算方法分别如下:
欧氏距离:
曼哈顿距离:
标准化欧氏距离:
用户可以根据数值的类型选取最合适的距离函数来达到最佳的运算结果。
更进一步的说明,所述距离函数适用非数值属性时,若用户属性为字符串的表现形式,则使用海明距离或编辑距离的计算方式,或用户自定义的计算方式;
海明距离:在信息论中,两个等长字符串之间的海明距离是两个字符串对应位置的不同字符的个数。换句话说,它就是将一个字符串变换成另外一个字符串所需要替换的字符个数。例如:10101和00110从第一位开始依次有第一位、第四、第五位不同,即总共有3位不同,则海明距离为3。字符串a、b的海明距离为它们异或之后“1”的数量,即:
编辑距离:编辑距离又称为levenshtein距离,指的是由一个字符串转成另一个字符串所需的最少编辑操作次数。允许的编辑操作有三种:把一个字符替换成另一个字符,插入一个字符,删除一个字符。设字符串a、b的长度分别为i、j,则它们的编辑leva,b(i,j)为:
更进一步的说明,步骤a中,若用户选择提示方法但没设置欠缺条件提示距离阈值t或欠缺条件提示数量p,则使用预设的缺省值。
如果用户忘记设置对应的参数值时,预设的缺省值可以保证程序仍可以继续运行。提供了程序正常运行的保证,也便利了用户的操作。
更进一步的说明,步骤c中,推送的阈值提示法和数量提示法推送结果的合集为阈值提示法和数量提示法推送结果的并集,且对重复的单个推送对象不再重复推送。
若阈值提示法的推送对象为甲、乙、丙,而数量提示法的推送对象为丙、丁,那么总的推送对象就是甲、乙、丙、丁,并且每个对象各仅推送一次欠缺条件提示信息,对丙也只推送一次。这样的方式可以避免推送对象接收到重复的推送。
更进一步的说明,进行逐个计算距离并保留最小的p个对象这一操作时,还可以使用插入排序,或者在所有对象计算完之后,使用快速排序或归并排序的方式。
堆排序和插入排序的好处在于,可以一个一个插进这个含有p个对象的队列来排序,并且一直只保留到目前为止最小的p个,其它的则舍弃。而快速排序和归并排序,必须把所有对象都拿来一起排序,时间开销较大(因为它把所有对象都排了,而堆排序和插入排序只排了最小的p个)。
更进一步的说明,用户可对所述距离函数d(x,y)进行修正改进,对数值属性和非数值属性设定权重加成。
例如,假设对象x、y各由3个属性(可以是数值属性或者非数值属性)构成,计算距离时各个属性的权重分别是w1、w2、w3,则它们的加权距离为:
更进一步的说明,当用户属性为非数值属性时,若实际的用户属性在设定的用户属性集合中,则距离值为0;若实际的用户属性不在设定的用户属性集合中,则距离值由用户自定义的距离函数c(xi,yi)计算得出。
例如集合s={本科生,硕士生,博士生},点p=本科生,那么s与p的距离为0;另外,如果集合s={本科生,硕士生,博士生},点p=中学生,那么s与p的距离将不为0,该距离值由用户自行定义。增加了对非数值属性的用户属性的适应度,可以兼容更多数据类型。
以上内容仅为本发明的较佳实施例,对于本领域的普通技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,本说明书内容不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!