一种基于迁移学习的缺陷报告跨项目分类方法与流程
本发明属于缺陷报告自动分类技术领域,尤其涉及一种基于迁移学习的缺陷报告跨项目分类方法。
背景技术
传统机器学习方法基于的假设是训练数据和测试数据服从相同的特征分布,要求训练数据和测试数据具有相同的数据分布。当训练数据和测试数据之间的数据分布存在差异时,传统的机器学习方法对结果的预测就会变差。然而,在一些实际的机器学习场景中,获得与测试数据具有相同特征空间和数据分布的训练数据是很困难的,或者需要花费很大的代价,使得这种假设往往无法满足。在对缺陷进行预测时就面临这样的问题,对于一个新的项目或者历史数据较少的项目,往往无法获得足够的缺陷报告,而且对新数据进行标记的代价也很高。如何最大限度地利用已有项目的数据对新的项目数据进行分类成为一个关键问题。
在对缺陷报告进行自动分类时,假设已经获得了大量标记过的linux系统的缺陷报告,如果训练数据和所要分类的目标数据都是来自linux软件系统,那么传统的机器学习方法就可以得到很好的预测结果。但是如果训练数据来自linux,而目标数据来自mysql缺陷报告,由于缺陷报告来自不同的项目,机器学习方法的预测结果就会变差。
为了弥补上述方法的不足,本发明提出了一种基于迁移学习的缺陷报告跨项目分类方法。一方面迁移学习打破了传统机器学习方法的假设,可以从其他相关领域迁移信息来提高对某一领域的信息的学习。另一方面,提高了缺陷报告跨项目分类的准确率。
技术实现要素:
本发明的目的是:使用迁移学习的方法,提高对缺陷报告跨项目分类的准确率,打破了传统机器学习方法要求训练数据和测试数据服从相同分布的假设,可以从相关领域迁移信息来提高对某一领域信息的学习,提出了一种基于迁移学习的缺陷报告跨项目分类方法。
本发明的技术方案是:一种基于迁移学习的缺陷报告跨项目分类方法,包括以下步骤:
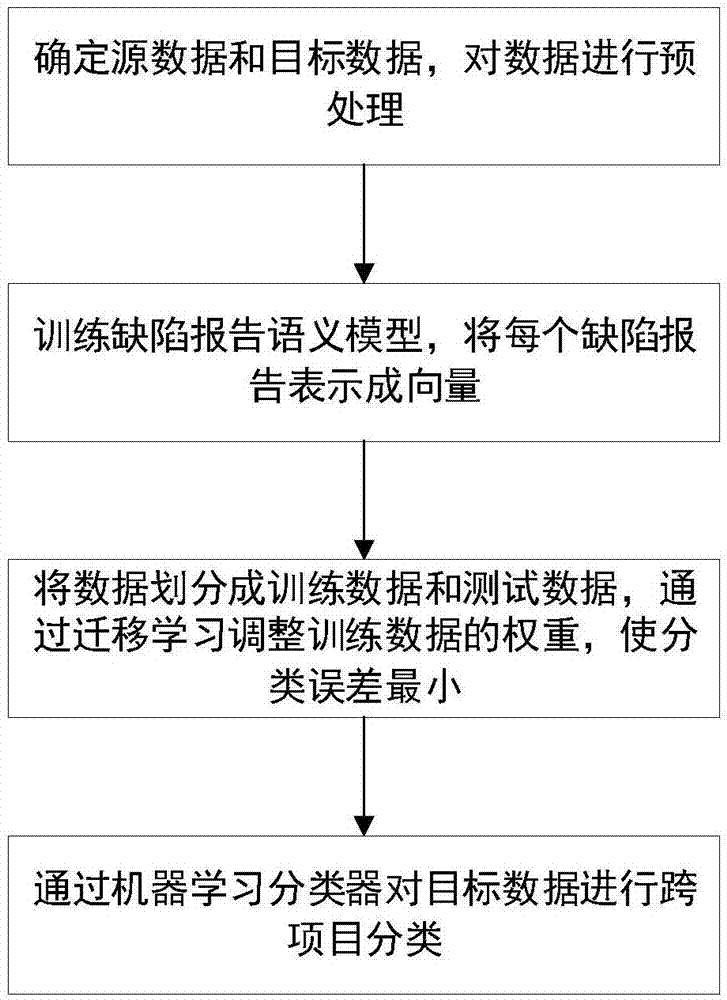
步骤1)、明确所要分类的目标数据,根据目标数据的特点选择与之有相近特征的源数据,并对目标数据和源数据均进行文本预处理;所述的预处理包括分词、移除停用词和词形还原,排除文本中包含的干扰信息;
步骤2)、训练缺陷报告语义模型,使用大量的无标签的缺陷报告训练缺陷报告语义模型,得到每个单词的向量表示,并将步骤1)源数据和目标数据中的每个缺陷报告都表示成向量的形式;
步骤3)、将步骤2)中的得到的源数据和目标数据划分成训练数据和测试数据,其中训练数据包括所有的源数据和10%~20%的目标数据,测试数据包括其余的目标数据;对训练数据赋予初始权重,通过迁移学习不断调整训练数据的权重,使对目标数据的分类误差最小;
步骤4)、使用步骤3)中迁移得到的训练数据训练机器学习分类器,并使用机器学习分类器对测试数据进行自动分类,得到缺陷报告的跨项目分类结果。
本发明一种基于迁移学习的缺陷报告跨项目分类方法,与现有方法相比较的优点在于:本发明打破了传统机器学习方法要求训练数据和测试数据服从相同分布的假设,可以从相关领域迁移信息来提高对某一领域信息的学习,提高了缺陷报告跨项目分类的准确率。
附图说明
图1基于迁移学习的缺陷报告跨项目分类方法流程示意图。
图2迁移学习框架图。
具体实施方式
在具体描述之前,首先对所使用的迁移学习的定义进行介绍。
迁移学习:给定一个源域ds和目标域
同构迁移/异构迁移:给定迁移学习的定义后,源域
在对缺陷报告进行分类时,异构迁移学习是指源软件项目和目标软件项目有不同的特征,本文中是指源数据和目标数据来自不同的项目,同构迁移学习是指源软件项目和目标软件项目具有相同的特征,本文中是指源数据和目标数据来自相同的项目。
下面结合附图对本发明作更近一步的说明。以下将结合附图1,对本发明的技术方案进行详细说明,其具体实施步骤如下:
步骤1、选择数据,明确所要分类的目标数据,并确定所要使用的源数据。首先选择与所要分类的项目不同领域的数据,这部分数据是带标签的,被称为源数据,用td表示。被预测的项目中的数据称为目标数据,目标数据中包含两部分数据,其中一部分是少量的标记数据,用ts表示,另一部分是未标记数据,用s表示。确定所要使用的目标数据和源数据后,需要对数据进行文本预处理,包括分词、移除停用词和词形还原三个步骤,排除文本中包含的干扰信息;
步骤2、训练缺陷报告语义模型。从缺陷追踪系统中下载大量无标签的缺陷报告,在对缺陷报告进行文本预处理(包括分词,移除停用词和词形还原)之后,使用word2vec工具中的skip-gram模型训练缺陷报告语义模型,将缺陷报告中的每个单词都以向量的形式表示。并通过对每个缺陷报告中的所有单词词向量取平均值,将步骤1中的源数据(td)和目标数据(ts和s)中的缺陷报告都表示成向量的形式;
步骤3、使用迁移学习的方法实现缺陷报告的跨项目分类。本发明对缺陷报告跨项目预测的思想来自tradaboost迁移学习框架,通过自动调整训练样本的权重,使用boosting过滤源数据中与目标数据差异很大的训练样本。在目标数据中的标记数据很少时,将源数据中的数据当作额外的训练数据,从而提高缺陷报告跨项目分类的结果。如图2所示,将步骤2中的得到的源数据td与目标数据中的ts合并作为训练数据,用t表示,并为训练数据赋予权重wt,作为训练分类器的输入,使用训练后的分类器对目标数据中的标记数据ts进行分类,将分类结果与ts的标签进行对比,根据分类结果的误差更新训练数据t的权重wt;
步骤4、使用步骤3从源数据td中迁移得到的数据训练分类器,通过机器学习分类器对目标数据中的测试集s进行分类,并得到分类结果。在实验中,将目标数据中的80%的数据用作测试,20%的数据和源数据一起做为训练数据,用于从源数据中迁移有用的信息并作为分类器的训练数据。
以上内容对本发明所述基于迁移学习的缺陷报告跨项目分类方法进行了详细的说明,但显然本发明的具体实现形式并不局限于此。对于本技术领域的一般技术人员来说,在不背离本发明的精神和权利要求范围的情况下对它进行的各种显而易见的改变都在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!