突发事件检测与预测的方法与流程
本发明涉及一种话题检测技术与话题跟踪技术。特别是涉及一种突发事件检测与预测的方法。
背景技术
目前话题检测文本聚类所使用的算法主要分为两类:一类是增量聚类算法。增量聚类是维持或改变k个簇的结构。增量聚类算法只需要对新的数据进行聚类,不需要重新对所有数据聚类,因此在处理大量的新数据时算法执行效率高。增量聚类中典型算法为single-pass算法。传统的single-pass只设置了单一的固定阈值,现实情况中各类事件文本的相似度最佳聚类阈值不一定是一样的。因此采用single-pass算法对文本分类,当文本之间的相似度比较一致时,文本分类结果比较准确。但实际上新闻文本信息量巨大,表达方式存在差异,以及随着事件的进展,重心可能发生变化,因此单一阈值会影响到分类结果的准确性。
另一类文本聚类方法是非增量聚类算法。非增量聚类初始化时将抽取的每个文本作为一个簇,剩余文本将其划分到与之距离最近的簇中,重新计算聚类的质心,重复这一过程,直到准则函数收敛。非增量聚类算法包括k-means算法和层次聚类算法等。k-means算法的伸缩性较好,计算复杂度低。缺点在于需要多次读取全部数据,另外只在处理球形的类时效果较好。层次聚类算法需要维持一个相似度矩阵,算法时间复杂度髙,在处理大数据集时效率较低。
目前突发事件预测所使用的方法主要分为两类:一种是基于增长率预测。基于增长率预测对发展过程与理想能量变化曲线一致的事件预测准确率高,反之则适应性较低。由于新闻文档的到来时间不具有稳定性,能量值变化与新闻文档的到来呈现不确定性变化,在一阶增长率呈现明显波动变化的情况下,二阶增长率便具有更高的不确定性,难以进行计算。同时,对于每个事件从出现到成为热点事件所经历的时间长度不同,因此通过固定的增长率阈值的方式也会导致那些增长率较低但连续且稳定的热点事件难以被检测出来。
另一类是基于时间序列预测。基于时间序列的生长曲线拟合方法能够直观的观察事物的变化情况,预测事物的发展趋势,但是由于数据规模、噪声等问题,很容易产生曲线过拟合的情况。
技术实现要素:
本发明所要解决的技术问题是,提供一种能够提高对新闻事件预测的准确率的突发事件检测与预测的方法。
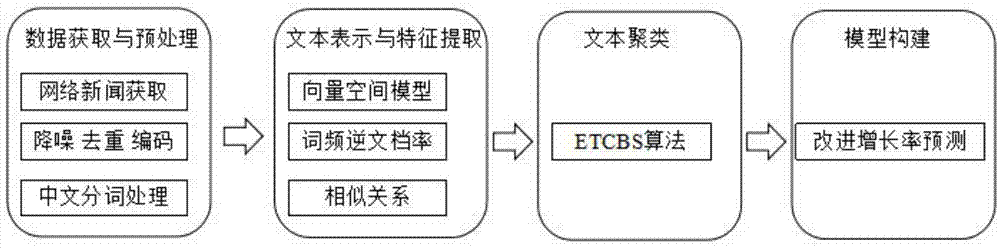
本发明所采用的技术方案是:一种突发事件检测与预测的方法,包括如下步骤:
1)数据获取与预处理;
2)文本表示与特征提取;
3)采用etcbs算法对文本聚类;
4)构建事件生命周期模型。
步骤1)包括:
(1)获取新闻信息包括新闻标题、新闻url、新闻发布时间、新闻正文文本内容这四个主要信息:
(2)对新闻数据进行降噪、去重和编码处理;
(3)对汉字序列进行中文分词,按照中文规范分解为由单独的词语构成的序列。
步骤2)包括:
(1)采用向量空间模型又称词袋模型表示文本,通过一个向量用于表示文本,其中向量中每个位置表示一个单词,因此向量空间模型还需要一个字典,所述的字典就是向量中每个位置对应单词的集合;
(2)特征词的权重采用词频逆文档率计算词语权重做特征提取,词频逆文档率的计算公式如下:
tf-idf(t,d)=tf(t,d)*idf(t)(1)
式中,tf(t)表示词语t在文档d中的频率,idf(t)表示词语t在文档集合中的逆文档频率,tf-idf(t,d)表示词语t在文档d中的词频逆文档率;
(3)文档d1,d2的相似度采用余弦相似度计算公式如下:
sim(d1,d2)=v(d1)*v(d2)/(|v(d1)|*|v(d2)|)(2)
式中,分子部分表示向量间点积,分母部分表示向量间欧几里得长度的乘积。
步骤3)包括:
(1)初始化文档集合与阈值thre1、thre2,设置最大文档相似度为0,输入新文档;
(2)计算新文档与各集合的相似度,记录最大文档相似度与当前集合;
(3)将最大文档相似度与设定的阈值thre1与thre2进行比较;如果最大文档相似度大于thre1,直接将新文档加入到当前集合中;如果最大文档相似度小于thre1且大于thre2,则计算新文档与当前集合中的所有文档的相似度;如果相似度大于thre1,则将新文档加入到当前集合之中,反之,算法终止。
步骤4)包括:
(1)确定预测能量区间[fa:fb],fa处在增长率曲线所在最大值处,fb处于能量值函数接近最大值处,选取g(x)函数,本发明采用的g(x)函数形式如下式:
g(x)=a*x2+b*x+c(3)
根据预测事件能量曲线函数值及一阶导数值,求得a=-0.225、b=0.315、c=-0.10025,参数a、b、c反映了g(x)函数变化趋势;
(2)考虑能量变化的时间窗口,确定平滑窗口大小,以及对应权重向量c,对增长率进行平滑处理,平滑处理公式如下:
其中tt表示时间窗t处的实际增长率,ci表示窗口i的增长率在计算中对应的权重;
(3)判断事件最新的能量值是否属于区间[fa:fb],若属于,并且当前时间窗口的增长率大于g(x)函数值,则预测结果成为热点事件,反之预测结果不为热点事件。
本发明的突发事件检测与预测的方法,有效克服由于设定单一阈值而产生的事件无法正确归类,忽略事件发展中的讨论内容的重心与关注点变化的问题。另一方面在于改进突发事件预测中基于增长率预测算法,提高对新闻事件预测的准确率。本发明为突发事件检测和预测方法提供了一种新的思路。结合新闻事件的实际特点对传统算法进行改进,对讨论话题范围广泛的文本分类提升效果明显,以及针对不同发展过程的事件预测更加准确。通过对突发事件进行准确预测,紧急处理突发的自然灾害、事故和公共社会事件等,从而大大降低社会损失具有重要意义。
附图说明
图1是本发明突发事件检测与预测的方法的流程图;
图2是事件8增长率曲线图;
图3是对图2中的增长率曲线平滑处理后的图。
具体实施方式
下面结合实施例和附图对本发明的突发事件检测与预测的方法做出详细说明。
如图1所示,本发明的突发事件检测与预测的方法,包括如下步骤:
1)数据获取与预处理;包括:
(1)通过网络爬虫获取新闻数据,本发明选取的新闻数据来源有新浪新闻、凤凰资讯和中新网这三个国内主要新闻门户网站。获取新闻信息包括新闻标题、新闻url、新闻发布时间、新闻正文文本内容这四个主要信息:
(2)对新闻数据进行降噪、去重和编码处理;由于本发明采用javascript正则表达式匹配的方法对噪声进行过滤,主要过滤信息包括爬取站点的布局方式、文章的url地址和javascript脚本代码。去重操作主通过对比新闻的标题、发表事件、正文内容将重复文档删除。采用utf-8的编码格式保存新闻文本数据。
(3)对汉字序列进行中文分词,按照中文规范分解为由单独的词语构成的序列。本发明采用北京理工大学张华平博士研制的nlpir系统进行中文分词。该系统支持多种格式编码,支持用户自定义词库。分词处理后,本发明采用四川大学机器智能实验室的停用词表、哈工大停用词表、百度停用词表过滤掉不需要的停用词。
2)文本表示与特征提取;包括:
(1)采用向量空间模型又称词袋模型表示文本,通过一个向量用于表示文本,其中向量中每个位置表示一个单词,因此向量空间模型还需要一个字典,所述的字典就是向量中每个位置对应单词的集合;向量空间模型的表现形式形如[word1:weight1;word2:weight2;word3:
weight3;:::],即一个词语所在位置对应一个权值,词语也称为特征词,权值也称为该特征词的权重。
(2)特征词的权重采用词频逆文档率计算词语权重做特征提取,其主要思想是,如果一个词语出现在少数的文档中,则该词语越能够区分出这些文档,如果一个词语出现在一篇文档的次数越多,说明该词对于该文档越为重要。词频逆文档率的计算公式如下:
tf-idf(t,d)=tf(t,d)*idf(t)(1)
式中,tf(t)表示词语t在文档d中的频率,idf(t)表示词语t在文档集合中的逆文档频率,tf-idf(t,d)表示词语t在文档d中的词频逆文档率;
(3)本发明通过采用向量进行文本的表示,并采用余弦相似度方法计算文本与文本、文本与事件之间的相似关系。文档d1,d2的相似度采用余弦相似度计算公式如下:
sim(d1,d2)=v(d1)*v(d2)/(|v(d1)|*|v(d2)|)(2)
式中,分子部分表示向量间点积,分母部分表示向量间欧几里得长度的乘积。
3)确定了文本的表示模型、特征提取方法以及相似度计算方法后,本发明采用etcbs算法对文本聚类;包括:
(1)初始化文档集合与阈值thre1、thre2,设置最大文档相似度为0,输入新文档;
(2)计算新文档与各集合的相似度,记录最大文档相似度与当前集合;
(3)将最大文档相似度与设定的阈值thre1与thre2进行比较;如果最大文档相似度大于thre1,直接将新文档加入到当前集合中;如果最大文档相似度小于thre1且大于thre2,则计算新文档与当前集合中的所有文档的相似度;如果相似度大于thre1,则将新文档加入到当前集合之中,反之,算法终止。
4)构建事件生命周期模型;包括:
(1)通过步骤3)将文本聚类,融合生物成长理论,构建出每一个事件的生命周期模型,如图2所示,根据生命周期模型,确定预测能量区间[fa:fb],fa处在增长率曲线所在最大值处,fb处于能量值函数接近最大值处,选取g(x)函数,该函数在预测能量区间[fa:fb]上的取值与理想型增长率函数近似,用于计算一个事件的处在能力值为x时增长率应满足怎样的条件才具备成为热点事件的可能。本发明采用的g(x)函数形式如下式:
g(x)=a*x2+b*x+c(3)
根据预测事件能量曲线函数值及一阶导数值,求得a=-0.225、b=0.315、c=-0.10025,参数a、b、c反映了g(x)函数变化趋势;
(2)考虑能量变化的时间窗口,确定平滑窗口大小,以及对应权重向量c,对增长率进行平滑处理,平滑处理公式如下:
其中tt表示时间窗t处的实际增长率,ci表示窗口i的增长率在计算中对应的权重,经过平滑处理后,增长率的变化更加平稳;图2为事件8增长率曲线,令c=[32,24,16,8,4]时得到图3曲线。经过平滑处理的增长率变化情况能够更好的应用在预测工作中。
(3)判断事件最新的能量值是否属于区间[fa:fb],若属于,并且当前时间窗口的增长率大于g(x)函数值,则预测结果成为热点事件,反之预测结果不为热点事件。
本发明的突发事件检测与预测的方法,所使用的数据集来源凤凰资讯和新浪新闻,从2017年3月25日到2017年3月31日的13084篇新闻。采用人工标注的方式,标注了其中的8个事件。
采用single-pass聚类方法设置文本分类阈值为0.18时得到了最佳效果。在etcbs算法中,设置阈值thre1=0.20、thre2=0.16,得到实验结果与传统single-pass聚类方法比较结果如表1所示。从本发明改进的方法中可以看出,召回率得到明显提升,说明相对于单一阈值设定,讨论范围比较广泛的事件通过进一步与相似度最大的事件中所有文档进行计算,能够被正确归到所属类中。但是,这也会导致在精度上有部分损失。在综合评估f上,本发明改进的方法都得到了较好的结果,并且在8个事件的平均f值得到0.9015的最大值。因此改进的方法确实能够得到更好的效果。
另外,本发明选取与2017年3月和4月的66807篇新闻文本用于训练doc2vec模型,并采用2017年3月25日到2017年3月31日的13084篇新闻文本进行实验和评估。由single-pass算法和etcbs算法进行聚类的结果可知,在事件召回率和综合评估f上etcbs算法明显高于single-pass算法,表明本发明改进etcbs在两种不同的文本表示方式上都有所作用。
以下对改进的增长率预测方法进行分析。本发明对2017年3月25日到2017年3月31日的新闻进行突发事件预测,得到如表2所示的结果。在预测结果中预测有7个事件将成为热点事件,并且其中的6个事件最终成为了热点事件,说明本发明所提出的改进方法在热点事件预测准确率效果良好。事件1、4、5同时被预测为热点事件与突发事件,事件能量值都有较大增长率,预测结果与实际相符。事件6从事件发生到成为热点事件经过了较长的时间,说明其成长过程缓慢,不具备较高增长率的条件,不能被预测出是否能够成为热点事件。事件8最早发生在3月22日,并且迅速得到广泛关注,在25日前已成为热点事件。在此之后世界各地又发生其它袭击事件,导致该事件的关注度较低,因此未成为热点事件。
综上所述,本发明基于生物成长理论对事件进行跟踪,采用改进的增长率预测方法能够较好地预测该事件能否成为热点事件与突发事件。与传统增长率设定固定阈值,根据一阶增长率和二阶增长率方法相比,改进的增长率方法通过对选取区间阈值,并对增长率曲线进行平滑处理,减小波动锯齿形情况,更适用于新闻事件的实际情况,同时对一些发展过程较长的热点事件预测准确率有所提高。
表1空间向量表示模型结果
在表1中,采用空间向量模型表示,对比传统single-pass聚类与etcbs算法,可知etcbs在召回率和综合评估f上表现良好。
表2预测结果
在表2中,参数设置时间窗口的大小为10min,热点事件的能量阈值为0.9,突发事件的时间阈值为30小时。在预测结果中预测有7个事件将成为热点事件,并且其中的6个事件最终成为了热点事件,说明本发明所提出的改进方法在热点事件预测准确率效果良好。
- 还没有人留言评论。精彩留言会获得点赞!