一种基于实时端到端双流网络的行为检测架构的制作方法
本发明涉及行为检测领域,尤其是涉及了一种基于实时端到端双流网络的行为检测架构。
背景技术
检测视频中人类的行为动作是计算机视觉重要任务之一,其目标是从视频中提取、分析和表述人体行为动作信息。受人脑视觉机理启发,深度学习框架使得机器学习取得巨大进展,也为研究人体行为检测开拓了新方向。在交通管理方面,可通过行为检测技术及时发现并制止行人闯红灯、在非斑马线区域过马路等违反交通法规的行为,以防止交通事故的发生;在体育运动领域,可通过行为检测技术对运动员的技术动作进行分析,从而对动作进行完善以取得更好的竞技成绩;在安保方面,通过行为检测技术能够对犯罪分子的犯罪行为进行捕捉和监控,为其犯罪事实提供了证据;另外,行为检测技术在人机交互、虚拟现实等领域也有广泛的应用。然而,现有的行为检测架构存在检测效率低下、检测精度不高和无法进行实时检测等问题。
本发明提出了本发明中提出的一种基于实时端到端双流网络的行为检测架构,先采用光流网2(光流网的升级版本,是一种针对光流计算的深度卷积神经网络)将光流计算与检测架构结合,使架构能够完全地进行端对端训练并提高gpu(图形处理器)的计算能力;然后,对时间网络和空间网络进行前期融合,并且对整个架构进行端到端训练;最后,采用kinetics数据库对检测架构进行预训练,以对网络进行完全的初始化。本架构相比起已有的行为检测架构具有更高的检测效率,其结果的精确性更高,并且能够进行实时检测。
技术实现要素:
针对现有的行为检测架构存在检测效率低下、检测精度不高和无法进行实时检测的问题,本发明的目的在于提供一种基于实时端到端双流网络的行为检测架构,先采用光流网2(光流网的升级版本,是一种针对光流计算的深度卷积神经网络)将光流计算与检测架构结合,使架构能够完全地进行端对端训练并提高gpu(图形处理器)的计算能力;然后,对时间网络和空间网络进行前期融合,并且对整个架构进行端到端训练;最后,采用kinetics数据库对检测架构进行预训练,以对网络进行完全的初始化。
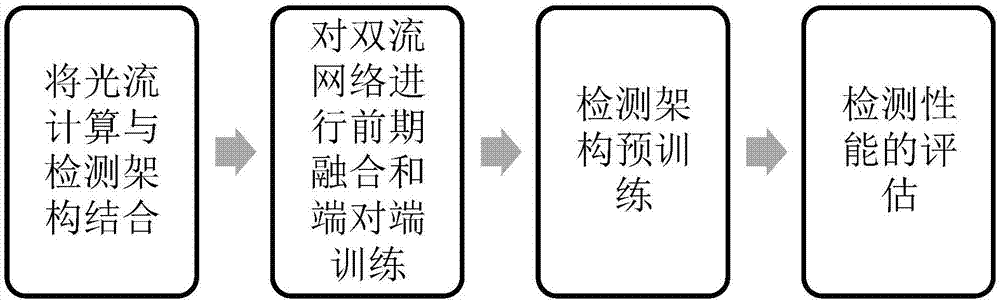
为解决上述问题,本发明提供一种基于实时端到端双流网络的行为检测架构,其主要内容包括:
(一)光流计算与检测架构结合;
(二)对双流网络进行前期融合和端对端训练;
(三)检测架构预训练;
(四)检测性能的评估。
其中,所述的双流网络,主要包括空间网络和时间网络;空间网络用于模拟外观,它传输的是红绿蓝(rgb)帧信号;时间网络主要用于模拟动作,它传输的光流信号。
其中,所述的光流,是由场景中前景目标本身的移动、相机的运动,或者两者的共同运动所产生的;光流是指空间运动物体在观察成像平面上的像素运动瞬时速度;光流可以利用图像序列中像素在时间域上的变化,以及相邻帧之间的相关性来找到上一帧跟当前帧之间存在的相应关系;光流的计算主要采用一种第三方算法进行,这个算法能够独立工作而不受空间网络的影响
其中,所述的将光流计算与检测架构结合,主要使用光流网2(flownet2)进行,这个过程有两个优点:使架构能够完全的进行端对端训练和提高gpu(图形处理器)的计算能力。
进一步地,所述的光流网2,是光流网的升级版本,光流网是一种针对光流计算的深度卷积神经网络;光流网可进行端对端训练,训练过程主要是使用合成数据来优化终点误差;光流网2相对光流网的提升在于对微小位移实时数据的处理更加精确,主要是由于光流网2采用了一种多层体系结构。
其中,所述的对双流网络进行前期融合和端对端训练,前期融合主要是对双流通道的最终激活(可复原边界框、分类得分和重叠计算)进行连接;在连接处内置了一个1×1的卷积核心,通过这个卷积核心,可将双流网络中的特征信号合并起来,这个特征信号包括图像中每一个具有高度相似性的点;前期融合结束后对双流网络进行端对端训练。
其中,所述的检测架构预训练,为了对网络进行初始化,需要对检测架构进行预训练,使其从行为识别状态转换为行为检测状态;预训练过程是基于一个大规模的动力学(kinetics)数据库;在整个架构的初始阶段,通常采用帕斯卡voc数据集对目标进行预训练,然后用kinetics在较低学习速率的情况下对整个架构进行预训练,从而起到保存定位特征的作用
其中,所述的检测性能的评估,主要包括评估数据集和评估度量标准
进一步地,所述的评估数据集,即ucf-101数据集,包含了人类的101个在现实环境中的基本行为,这些行为来源于youtube(谷歌公司旗下视频网站);ucf-101数据集是当今最大的可用于行为检测的数据集,主要采用其中一个含有24个行为子集(包含3207个视频)即ucf-101-24进行评估;ucf-101-24中包含了修饰视频和未修饰视频,由于本架构不含时间定位部件,所以只能选择修饰视频进行评估;评估过程主要是将本架构和其它架构分别在ucf-101-24上进行行为检测,再对它们的精确性和效率进行对比。
进一步地,所述的评估度量标准,主要采用帧平均精度(f-map)来对本架构的检测性能进行度量:计算出检测精度记忆曲线下的面积,若所得面积是一个正值,则表示检测结果与实际情况有一个交叉并集(iou),并且这个交叉并集的值超过了一个阈值α(根据要求的精度的高低,可取α=0.2、0.5或0.75,α值越大,要求的精度越高),此时检测结果为精确,反之则为不精确。
附图说明
图1是本发明一种基于实时端到端双流网络的行为检测架构的系统流程图。
图2是本发明一种基于实时端到端双流网络的行为检测架构的性能评估图。
具体实施方式
需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互结合,下面结合附图和具体实施例对本发明作进一步详细说明。
图1是本发明一种基于实时端到端双流网络的行为检测架构的系统流程图。主要包括将光流计算与检测架构结合、对双流网络进行前期融合和端对端训练、检测架构预训练和检测性能的评估。
双流网络,主要包括空间网络和时间网络;空间网络用于模拟外观,它传输的是红绿蓝(rgb)帧信号;时间网络主要用于模拟动作,它传输的光流信号。
光流,光流是由场景中前景目标本身的移动、相机的运动,或者两者的共同运动所产生的;光流是指空间运动物体在观察成像平面上的像素运动瞬时速度;光流可以利用图像序列中像素在时间域上的变化,以及相邻帧之间的相关性来找到上一帧跟当前帧之间存在的相应关系;光流的计算主要采用一种第三方算法进行,这个算法能够独立工作而不受空间网络的影响。
将光流计算与检测架构结合,主要使用光流网2(flownet2)进行,这个过程有两个优点:使架构能够完全的进行端对端训练和提高gpu(图形处理器)的计算能力。
光流网2,是光流网的升级版本,光流网是一种针对光流计算的深度卷积神经网络;光流网可进行端对端训练,训练过程主要是使用合成数据来优化终点误差;光流网2相对光流网的提升在于对微小位移实时数据的处理更加精确,主要是由于光流网2采用了一种多层体系结构。
对双流网络进行前期融合和端对端训练,前期融合主要是对双流通道的最终激活(可复原边界框、分类得分和重叠计算)进行连接;在连接处内置了一个1×1的卷积核心,通过这个卷积核心,可将双流网络中的特征信号合并起来,这个特征信号包括图像中每一个具有高度相似性的点;前期融合结束后对双流网络进行端对端训练。
检测架构预训练,为了对网络进行初始化,需要对检测架构进行预训练,使其从行为识别状态转换为行为检测状态;预训练过程是基于一个大规模的动力学(kinetics)数据库;在整个架构的初始阶段,通常采用帕斯卡voc数据集对目标进行预训练,然后用kinetics在较低学习速率的情况下对整个架构进行预训练,从而起到保存定位特征的作用。
图2是本发明本发明一种基于实时端到端双流网络的行为检测架构的性能评估图。性能评估主要包括评估数据集和评估度量标准,本图即为本架构在评估数据集上进行测试的结果(骑马、撑杆跳高、滑雪、悬崖跳水),具有相当高的精确性。
评估数据集,即ucf-101数据集,包含了人类的101个在现实环境中的基本行为,这些行为来源于youtube(谷歌公司旗下视频网站);ucf-101数据集是当今最大的可用于行为检测的数据集,主要采用其中一个含有24个行为子集(包含3207个视频)即ucf-101-24进行评估;ucf-101-24中包含了修饰视频和未修饰视频,由于本架构不含时间定位部件,所以只能选择修饰视频进行评估;评估过程主要是将本架构和其它架构分别在ucf-101-24上进行行为检测,再对它们的精确性和效率进行对比。
评估度量标准,主要采用帧平均精度(f-map)来对本架构的检测性能进行度量:计算出检测精度记忆曲线下的面积,若所得面积是一个正值,则表示检测结果与实际情况有一个交叉并集(iou),并且这个交叉并集的值超过了一个阈值α(根据要求的精度的高低,可取α=0.2、0.5或0.75,α值越大,要求的精度越高),此时检测结果为精确,反之则为不精确。
对于本领域技术人员,本发明不限制于上述实施例的细节,在不背离本发明的精神和范围的情况下,能够以其他具体形式实现本发明。此外,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围,这些改进和变型也应视为本发明的保护范围。因此,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
- 还没有人留言评论。精彩留言会获得点赞!