一种基于增量聚类的企业热点事件挖掘方法与流程
本发明涉及数据挖掘技术领域,特别是涉及一种基于增量聚类的企业热点事件挖掘方法。
背景技术:
近年来,利用网络新闻进行数据挖掘分析已有很多课题和任务,例如新闻推荐、文本关键词抽取和舆情监测等。对于网络新闻热点话题也已经有很多的研究,普遍采用话题检测与跟踪方法。同样对于企业热点事件的研究,也可以采用类似话题检测与跟踪的方法,这种基于增量聚类的方法能够更加快速准确的将企业热点新闻提取出来,相对于人工查找、排除、选择热点新闻更为高效。但目前针对于企业的网络新闻研究相对较少,因此本发明将利用企业的网络新闻实现企业热点事件的挖掘。
技术实现要素:
本发明所要解决的技术问题是提供一种基于增量聚类的企业热点事件挖掘方法,能够为企业或个人提供企业过去发生的热点事件。
本发明解决其技术问题所采用的技术方案是:提供一种基于增量聚类的企业热点事件挖掘方法,包括以下步骤:
(1)通过网络爬虫获取企业网络新闻;
(2)对爬取的企业网络新闻进行降噪并存入数据库;
(3)从数据库读取企业新闻进行预处理;
(4)对预处理后的企业新闻进行聚类分析;
(5)对聚类分析得到的热点事件簇进行质心新闻提取并存入数据库;
(6)从数据库获取所需企业热点事件进行展示。
所述步骤(1)具体包括以下子步骤:
(11)通过关键字搜索获得新闻url,放入待抓取新闻url队列;
(12)从待抓取新闻队列读取url,解析dns,进入到url对应的网页,下载该网页;
(13)解析下载的网页,使用正则匹配获取新闻网页中新闻的标题、时间、来源和内容。
所述步骤(2)具体为:基于后期聚类分析对象是新闻内容和标题,使用编码降噪部分去掉新闻内容缺失,新闻标题缺失的噪声新闻,提高聚类正确率,降噪后存入数据库。
所述步骤(3)包括以下子步骤:
(31)从数据库读取新闻,使用jieba中文分词对新闻进行文本分词,分词时去除对聚类无效的高频词和停用词;
(32)对分词完成的新闻进行词加权,使用tf-idf算法对每篇新闻的特征进行权重计算;
(33)权重计算完成后,进行特征向量化,使用vsm对每篇新闻进行特征向量化,最终形成高维向量矩阵。
所述所述步骤(4)包括以下子步骤:
(41)将新闻以发布时间进行排序,以第一篇新闻文本为第一个簇;
(42)加入新的新闻文本,计算新闻文本与已存在的新闻簇的余弦相似度,取出最大余弦相似度,标记取得最大余弦相似度的簇,将最大余弦相似度与相似度阈值t比较,若大于t,加入标记的簇,重新计算该簇的质心特征向量;若小于t,以新闻文本创建新的簇;
(43)判断是否还有新闻文本需要聚类,若有,返回步骤(42);若没有,进入下一步;
(44)产生k个簇,选取簇新闻数量大于阈值tn的簇,去掉小于阈值tn的簇,结束聚类。
所述步骤(5)中所述质心新闻是一个簇内新闻文本中余弦相似度误差平方和sse最小的新闻,所述质心新闻代表簇核心话题。
有益效果
由于采用了上述的技术方案,本发明与现有技术相比,具有以下的优点和积极效果:本发明能够为企业或个人提供企业过去产生的热点事件,这种基于增量聚类的方法能够更加快速准确的将企业热点事件提取出来,这是一种无监督自动产生企业热点事件的方法,相对于人工查找、排除、选择热点事件更为高效。
附图说明
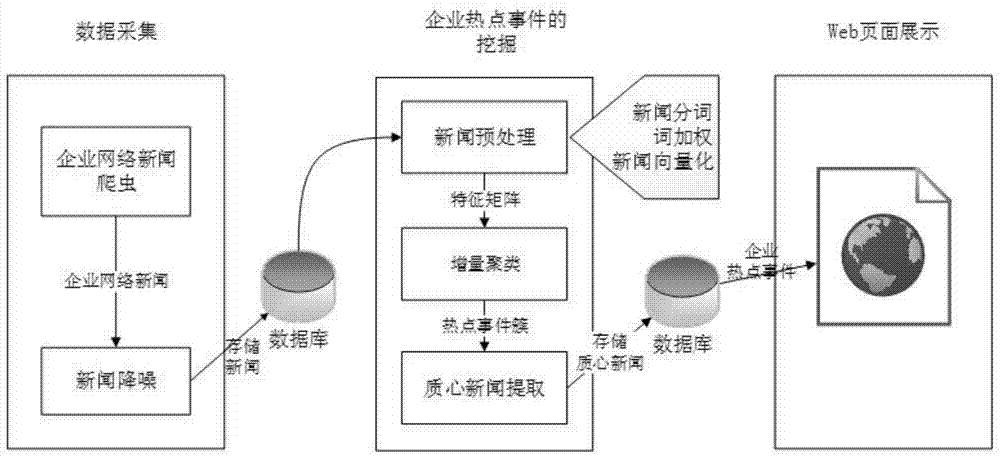
图1是本发明的整体框架图;
图2是本发明中增量聚类分析的流程图。
具体实施方式
下面结合具体实施例,进一步阐述本发明。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。此外应理解,在阅读了本发明讲授的内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本申请所附权利要求书所限定的范围。
本发明的实施方式涉及一种基于增量聚类的企业热点事件的挖掘方法,如图1所示,包括以下步骤:a通过网络爬虫获取企业网络新闻;b对爬取的企业网络新闻进行降噪并存入数据库;c从数据库读取企业新闻进行预处理,预处理包括文本分词、词加权以及特征向量化;d对预处理后的企业新闻进行聚类分析;e对聚类分析得到的热点事件簇进行质心新闻提取并存入数据库;f从数据库获取所需企业热点事件并以时间为序在web页面展示。
其中,步骤a具体包括:
a1.百度新闻关键字搜索所需企业,获得该企业新闻url,然后放入待抓取新闻url队列;
a2.从待抓取新闻队列读取url,解析dns,进入到url对应的网页,下载该网页;
a3.解析下载的网页,使用正则匹配获取新闻网页中新闻的标题、时间、来源和内容。
步骤b具体包括:基于后期聚类分析对象是是新闻内容和标题,使用编码降噪部分去掉新闻内容缺失,新闻标题缺失的噪声新闻。
步骤c具体包括:
c1.从数据库读取所需企业的新闻,使用jieba中文分词对新闻进行文本分词,分词时去除对聚类无效的高频词和停用词;
c2.对分词完成的新闻进行词加权,使用tf-idf算法对每篇新闻的特征进行权重计算;
c3.权重计算完成后,进行特征向量化,使用vsm(vectorspacemodel,向量空间模型)对每篇新闻进行特征向量化,最终形成高维向量矩阵。
如图2所示,步骤d具体包括:
d1.将该企业的新闻以发布时间进行排序,以第一篇新闻文本d1为第一个簇c1;
d2.加入新的新闻文本di,计算新闻文本di与已存在的新闻簇的余弦相似度,取出最大余弦相似度,标记取得最大余弦相似度sim的簇cj,将sim与相似度阈值t比较,若大于t,加入标记的簇cj,重新计算该簇的质心特征向量;若小于t,以新闻文本di创建新的簇。簇的质心特征向量计算方法:
上式中,n代表该簇中总新闻文本数,vj代表簇中第j个新闻文本的特征向量,
d3.判断是否还有新闻文本需要聚类,若有,继续第d2步;若没有,转到第d4步。
d4.产生k个簇,选取簇新闻数量大于阈值tn的簇,去掉小于阈值tn的簇,结束聚类。
步骤e具体包括:对聚类分析产生热点事件簇提取质心新闻(质心新闻是一个簇内新闻文本中余弦相似度误差平方和sse最小的新闻),质心新闻代表簇核心话题,将质心新闻存入数据库。
在本发明中,利用数据挖掘技术,在企业网络新闻数据基础上,可以快速为企业或个人提供企业过去的发生的热点事件。本发明具有快速高效,贴合需求等优点,可在企业或个人中进行推广和应用,具有较强的社会及商业价值。
- 还没有人留言评论。精彩留言会获得点赞!