学科相关性知识点库构建方法及其系统与流程
本申请涉及计算机信息处理领域,特别涉及以计算机自动化构建学科相关性知识点库的技术。
背景技术
现有教育信息化技术中,对大、中、小学等教材的知识点选取和访问方式,既没有统一标准,也没有统一的知识点库,无法为教育信息化领域提供标准化、数字化的知识点库基础。同时教学资料的快速、准确搜索越来越重要,尤其是在老师备课搜索相关资源,因为无法根据知识点的相关性进行搜索,经常会出现很多无用资源,无法达到有效知识点准确、全面的检索效果。
如何构建一个数据库,从而能够根据一个知识点迅速而准确地找到与该知识点相关的所有知识点,并且能够知道这些知识点的相关程度,就成为本领域急需解决的技术问题。该技术问题的解决,可以为基于知识点相关性的各种应用打下坚实的技术基础。
技术实现要素:
本申请的目的在于提供一种学科相关性知识点库构建方法及其系统,能够根据一个知识点迅速而准确地找到与该知识点相关的所有知识点,并且能够知道这些知识点的相关程度。
为了解决上述问题,本申请公开了一种学科相关性知识点库构建方法,包括:
对于多个知识点,计算每个知识点的属性相关知识点集合;
计算该每个知识点的语义相关知识点集合;
根据该属性相关知识点集合和该语义相关性知识点集合,计算该每个知识点的相关性知识点集合。
在一优选例中,该计算每个知识点的属性相关知识点集合之前,还包括:
为该多个知识点中的每个知识点分别设置一个编码。
在一优选例中,每个知识点的编码中包括:学科编码,子学科编码,专题编码,主题编码,和时间性编码。
在一优选例中,该为该多个知识点中的每个知识点分别设置一个编码,进一步包括:
根据知识点的学科名称,获取对应的学科编码;
根据该知识点的学科编码和子学科名称,获取对应的子学科编码;
根据该知识点的学科编码、子学科编码和专题名称,获取对应的专题编码;
根据该知识点的学科编码、子学科编码、专题编码和主题名称,获取对应的主题编码;
如果该知识点为专题知识点,则该知识点的主题编码和时间性编码均设置为0;
如果该知识点为主题知识点,则该知识点的时间性编码设置为0;
如果该知识点为普通知识点,则根据该知识点的知识点名称和主题,生成该知识点的时间性编码。
在一优选例中,该计算每个知识点的属性相关知识点集合,进一步包括:
将要计算属性相关知识点集合的知识点作为目标知识点,计算该目标知识点的直系和旁系知识点,该直系和旁系知识点构成该属性相关知识点集合;
对得到的直系和旁系知识点按与该目标知识点的亲疏度进行排序;
根据该排序的结果计算该属性相关知识点集合中各知识点与目标知识点的属性相关度。
在一优选例中,该计算该目标知识点的直系和旁系知识点,进一步包括:
将该目标知识点分别与其他知识点进行第一逻辑运算,如果逻辑运算结果各位均为0,则判定为直系;若逻辑运算结果有1位不为0,则判定为旁系;
其中,该第一逻辑运算的运算规则为:对于两个知识点编码对应的每一位分别进行比较,若两个知识点编码在该位相同或有一位为0,则该位的运算结果为0;若两个知识点编码在该位不同且不为0,则该位的运算结果为1。
在一优选例中,该对得到的直系和旁系知识点按与该目标知识点的亲疏度进行排序中,该直系、旁系知识点与该目标知识点的亲疏度根据以下方式确定:
直系、旁系知识点分别与该知识点的属性编码段依次进行第二逻辑运算,若该段编码相同,则该段的运算结果为1,若该段编码不同,则该段的运算结果为0;
目标知识点与直系知识点的亲疏度大于旁系知识点;
根据逻辑运算的结果,分别对直系、旁系知识点进行升序排列;
对逻辑运算结果相同的知识点,根据知识点编码进行升序排列;
对以上知识点进行排序整合,越相近的知识点之间亲疏度越高。
在一优选例中,该根据该排序的结果计算该属性相关知识点集合中各知识点与目标知识点的属性相关度,进一步包括:
计算该直系和旁系知识点总数n;
按亲疏度排列该直系和旁系知识点,计算各直系和旁系知识点到该目标知识点的距离m;
各直系和旁系知识点与该目标知识点的属性相关度为1-m/n。
在一优选例中,该计算该每个知识点的语义相关知识点集合,进一步包括:
基于多个知识点语义资料,获取每个语义资料中的知识点;
根据该每个语义资料中的知识点,计算该每个知识点与其他知识点的语义相关度;
对于该每个知识点,将与该知识点的语义相关度高于预定门限的其他知识点加入该知识点的语义相关知识点集合。
在一优选例中,该计算该每个知识点与其他知识点的语义相关度的步骤中,通过以下方式计算第一知识点和第二知识点的语义相关度:
获取知识点语义资料中包含的知识点集合并将知识点以编码方式保存,其中该第一知识点的语义资料中包含m个知识点,该第二知识点的语义资料中包含n个知识点;
计算该第一知识点与该第二知识点的语义资料中相同的知识点编码,获得p个相同的知识点编码;
该第二知识点相对于该第一知识点的语义相关度为p/m。
在一优选例中,该计算该每个知识点的相关性知识点集合,进一步包括:
对于每一个知识点,计算该知识点的属性相关知识点集合和语义相关知识点集合的并集,保存为该知识点的相关性知识点集合;
对该相关性知识点集合中的知识点按照相关度大小进行排序,如果该相关性知识点集合中的一个知识点存在两个相关度,则以这两个相关度中的较大值作为该知识点的相关度。
在一优选例中,该属性相关知识点集合、该语义相关性知识点集合、和该相关性知识点集合均为知识点的编码集合。
本申请还公开了一种学科相关性知识点库构建系统,包括:
属性相关计算单元,用于对于多个知识点,计算每个知识点的属性相关知识点集合;
语义相关计算单元,用于计算该每个知识点的语义相关知识点集合;
相关性计算单元,用于根据该属性相关知识点集合和该语义相关性知识点集合,计算该每个知识点的相关性知识点集合。
本申请还公开了一种学科相关性知识点库构建系统,包括:
存储器,用于存储计算机可执行指令;以及,
处理器,用于在执行该计算机可执行指令时实现如前文描述的学科相关性知识点库构建方法的步骤。
本申请还公开了一种计算机可读存储介质,该计算机可读存储介质中存储有计算机可执行指令,该计算机可执行指令被处理器执行时实现如前文描述的学科相关性知识点库构建方法的步骤。
本申请实施方式中,可以计算得到每一个知识点的相关性知识点集合,也就是说可以知道每一个知识点与哪些其他的知识点相关,相关的程度有多少,从而为学习、考试出题等各种进一步的应用场景提供有力的支持。学科相关性知识点库中包括了每一个知识点的相关性知识点集合,有了这样一个相关性知识点库后,可以快速查询到与每一个知识点相关的其他知识点,大大节约了相关性知识点的查询时间,节约了查询所占用的计算机资源。
进一步地,根据本申请提出的特定的编码方案和特定的属性相关度计算方法,可以基于编码以很少的计算量计算得到两个知识点是否属于直系或旁系知识点,而且可以快速算出两个知识点的属性相关度。
进一步地,在各种集合中以知识点的编码来代表知识点,可以减少对存储空间的占用,而且可以直接根据编码来进行相关性的运算。
本申请的说明书中记载了大量的技术特征,分布在各个技术方案中,如果要罗列出本申请所有可能的技术特征的组合(即技术方案)的话,会使得说明书过于冗长。为了避免这个问题,本申请上述发明内容中公开的各个技术特征、在下文各个实施方式和例子中公开的各技术特征、以及附图中公开的各个技术特征,都可以自由地互相组合,从而构成各种新的技术方案(这些技术方案均因视为在本说明书中已经记载),除非这种技术特征的组合在技术上是不可行的。例如,在一个例子中公开了特征a+b+c,在另一个例子中公开了特征a+b+d+e,而特征c和d是起到相同作用的等同技术手段,技术上只要择一使用即可,不可能同时采用,特征e技术上可以与特征c相组合,则,a+b+c+d的方案因技术不可行而应当不被视为已经记载,而a+b+c+e的方案应当视为已经被记载。
附图说明
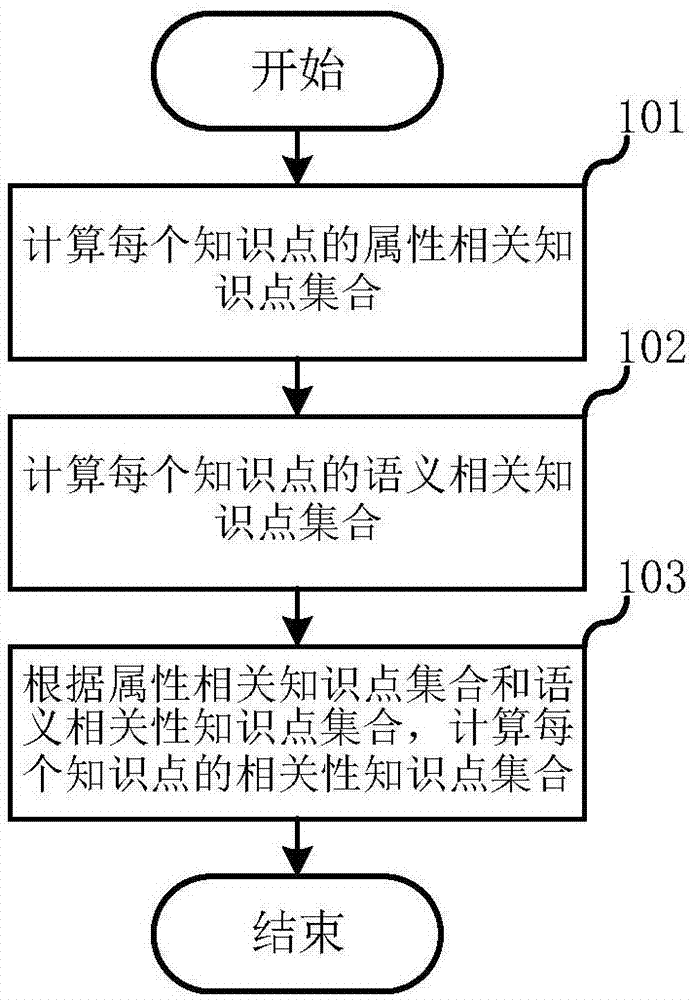
图1是本申请第一实施方式中一种学科相关性知识点库构建方法的流程示意图
图2是本申请一个实施例中知识点的编码方式示意图
图3是本申请一个实施例中自主规划知识点的学习路径
具体实施方式
在以下的叙述中,为了使读者更好地理解本申请而提出了许多技术细节。但是,本领域的普通技术人员可以理解,即使没有这些技术细节和基于以下各实施方式的种种变化和修改,也可以实现本申请所要求保护的技术方案。
部分概念的说明:
知识点:知识点是构成学科知识体系的基本单位。
专题、主题、普通知识点的分类从大到小的三个级别,是基于教学大纲和教材章、节中所包含的学习内容进行分类的,其中:
专题知识点:一个较大的语义范畴,其可以统领多个同类的知识点;
主题知识点:相对于专题知识点来说的,比专题小,但概念相同;
普通知识点:就是主题下的具体知识点。
属性相关:指基于学科分类的相关;
语义相关:指基于语义的相关;
属性相关知识点集合:就是与一个指定的知识点存在属性相关关系的各知识点的集合。
语义相关知识点集合:就是与一个指定的知识点存在语义相关关系的各知识点的集合。
相关性知识点集合:就是与一个指定的知识点相关的各知识点的集合。
为使本申请的目的、技术方案和优点更加清楚,下面将结合附图对本申请的实施方式作进一步地详细描述。
本发明第一实施方式涉及一种学科相关性知识点库构建方法。图1是该学科相关性知识点库构建方法的流程示意图。对于多个知识点中的每一个知识点,执行以下步骤:
在步骤101中,计算每个知识点的属性相关知识点集合。在一个实施例中,步骤101进一步包括:
子步骤a1:将要计算属性相关知识点集合的知识点作为目标知识点,计算该目标知识点的直系和旁系知识点,该直系和旁系知识点构成属性相关知识点集合。其中,子步骤a1进一步包括:
将目标知识点的属性编码分别与其他知识点的属性编码进行第一逻辑运算,如果逻辑运算结果各位均为0,则判定为直系;若逻辑运算结果中,有1位不为0,则判定为旁系。其中,第一逻辑运算的运算规则为:对于两个知识点编码对应的每一位分别进行比较,若两个知识点编码在该位相同或有一位为0,则该位的运算结果为0;若两个知识点编码在该位不同且不为0,则该位的运算结果为1。本申请个实施方式中的0和1只是一个具体的例子,并不一定要是0或者1,也可以是其他的指定值。例如,可以将本申请的所有的0和1互换,也可以实现本申请的技术方案。在一个实施例中,知识点的属性编码由若干段组成(例如学科段,子学科段,主题段等等),每一段包括至少1位,每1位是一个数字。
子步骤a2:对得到的直系和旁系知识点按与目标知识点的亲疏度进行排序。其中,
直系、旁系知识点分别与该知识点的属性编码段依次进行第二逻辑运算,该第二逻辑运算类似于按段进行的“异或”运算,即,若该段编码相同,则输出“1”,若该段编码不同,则输出“0”;
可以理解,直系知识点均比旁系知识点亲疏度更高,或者说直系知识点比所有的旁系知识点更接近目标知识点(直系知识点与目标知识点的距离比旁系知识点与目标知识点的距离更近);
根据逻辑运算的结果,分别对直系、旁系知识点进行升序排列;
对逻辑运算结果相同的知识点,根据知识点编码进行升序排列;
对以上知识点进行排序整合,越相近的知识点之间亲疏度越高。
子步骤a3:根据排序的结果计算属性相关知识点集合中各知识点与目标知识点的属性相关度。子步骤a3进一步包括:
a31:计算直系和旁系知识点总数n。
a32:按亲疏度排列直系和旁系知识点,计算各直系和旁系知识点到目标知识点的距离m。
a33:各直系和旁系知识点与目标知识点的属性相关度为1-m/n。
根据本申请中公开的特定的编码方案和特定的属性相关度计算方法,可以基于编码以很少的计算量计算得到两个知识点是否属于直系或旁系知识点,而且可以快速算出两个知识点的属性相关度。
此后进入步骤102,计算每个知识点的语义相关知识点集合。在一个实施例中,步骤102包括以下子步骤:
子步骤b1:基于多个知识点语义资料,获取每个语义资料中的知识点。
子步骤b2:根据每个语义资料中的知识点,计算每个知识点与其他知识点的语义相关度。可选地,通过以下子步骤计算任意两个知识点(不失一般性,这里将要计算语义相关性的知识点称为第一知识点和第二知识点)的语义相关度。
b21:获取知识点语义资料中包含的知识点集合并将知识点以编码方式保存,其中第一知识点的语义资料中包含m个知识点,第二知识点的语义资料中包含n个知识点。
b22:计算第一知识点与第二知识点的语义资料中相同的知识点编码,获得p个相同的知识点编码。
b23:第二知识点相对于第一知识点的语义相关度为p/m。
子步骤b3:对于每个知识点,将与该知识点的语义相关度高于预定门限的其他知识点加入该知识点的语义相关知识点集合。
此后进入步骤103,根据属性相关知识点集合和语义相关性知识点集合,计算每个知识点的相关性知识点集合。在一个实施例中,该步骤包括以下子步骤:
子步骤c1:对于每一个知识点,计算该知识点的属性相关知识点集合和语义相关知识点集合的并集,保存为该知识点的相关性知识点集合。
子步骤c2:对相关性知识点集合中的知识点按照相关度大小进行排序,如果相关性知识点集合中的一个知识点存在两个相关度(既有属性相关度又有语义相关度),则以这两个相关度中的较大值作为该知识点的相关度。
通过上述技术方案,可以计算得到每一个知识点的相关性知识点集合,也就是说可以知道每一个知识点与哪些其他的知识点相关,相关的程度有多少,从而为学习、考试出题等各种进一步的应用场景提供有力的支持。学科相关性知识点库中包括了每一个知识点的相关性知识点集合,有了这样一个相关性知识点库后,可以快速查询到与每一个知识点相关的其他知识点,大大节约了相关性知识点的查询时间,节约了查询所占用的计算机资源。
在一个实施例中,在步骤101执行之前,还需要预先为多个知识点中的每个知识点分别设置一个编码。
在一个实施例中,每个知识点的编码中包括:学科编码,子学科编码,专题编码,主题编码,和时间性编码。在其他实施例中,编码的项目可以根据学科的分类方式进行增减,和每个编码项目的长度也可以根据实际需要变化。
在一个实施例中,为每个知识点设置编码的方式如下:
根据知识点的学科名称,获取对应的学科编码。
根据该知识点的学科编码和子学科名称,获取对应的子学科编码。
根据该知识点的学科编码、子学科编码和专题名称,获取对应的专题编码。
根据该知识点的学科编码、子学科编码、专题编码和主题名称,获取对应的主题编码。
其中,如果该知识点为专题知识点,则该知识点的主题编码和时间性编码均设置为0。如果该知识点为主题知识点,则该知识点的时间性编码设置为0。如果该知识点为普通知识点,则根据该知识点的知识点名称、主题,生成该知识点的时间性编码。
在本申请的一个优选例中,属性相关知识点集合、语义相关性知识点集合、和相关性知识点集合均为知识点的编码集合。在各种集合中以知识点的编码来代表知识点,可以减少对存储空间的占用,而且可以直接根据编码来进行相关性的运算。当然,在其他某些实施例中,也可以以其他方式来标识各种集合中的知识点,例如使用流水号、唯一的名称等等,但会丧失直接进行属性相关性运算的便利。
下面说明本申请的一个具体例子,该例子用于更好的理解本申请的内容,并不构成对于本申请保护范围的限制。
预先准备:构建数据表及数据整理,包括以下步骤
(1)整理知识点信息,构建数据表:
构建知识点基础属性信息表,包括学科编码表、子学科编码表、专题编码表、主题编码表、学习阶段编码表、基础知识点表(基础知识点表按学科、学习阶段建表,即学科下每个学习阶段建立一张表,如语文学科下有小学、初中、高中三个学习阶段,则语文学科每个学习阶段建一张表,共3张基础知识点表)、相关性知识点表(与基础知识点表一样,按学科、学习阶段建表,学科下有几个学习阶段就有几张相关性知识点表);其中:
学科相关性知识点库构建基础表
(2)数据表之间建立关系:
学科编码表通过学科编码与子学科编码表、专题编码表、主题编码表建立关联;这里的编码就是属性编码;
子学科编码表通过子学科编码与专题编码表、主题编码表建立关联;
专题编码表通过专题编码与主题编码表建立关联;
基础知识点表、相关性知识点表同知识点编码与学科编码表、子学科编码表、专题编码表、主题编码表建立关联;
注:知识点编码中包括学科编码、子学科编码、专题编码、主题编码等,详细参考知识点编码生成流程
知识点的编码方式,如图2所示,知识点编码由9位构成,分为5段(分别为学科编码段、子学科编码段、专题编码段、主题编码段和时间性编码段),每段为1位或多位。
知识点各属性编码表示及编码方式详见下表:
(3)数据整理及录入
按照“学科->子学科->专题->主题->知识点”的树形目录结构整理学科名称、学科编码、子学科名称、子学科编码、专题名称、专题编码、主题名称、主题编码、知识点名称、知识点对应的语义资料、学习阶段名称、学习阶段编码数据;
将学科名称、学科编码、子学科名称、子学科编码、专题名称、专题编码、主题名称、主题编码、学习阶段名称、学习阶段编码作为记录分别录入相应的数据表。
下面说明学科相关性知识点库的构建例子
学科相关性知识点库构建包括两个流程:(1)构建学科基础知识点库;(2)构建学科相关性知识点库
(1)构建学科基础知识点库
对整理的所有知识点名称,按照知识点编码生成流程,计算机自动对每个知识点进行编码,并将知识点名称、知识点编码、知识点对应的语义资料录入到相应的基础知识点表,完成学科基础知识点库的构建。
知识点编码生成流程如下:
基于基础信息表,根据整理的知识点信息,按照知识点编码生成规则生成知识点各属性编码;
1、根据知识点信息,从基础信息表中获取学科、子学科、专题、主题、学习阶段各属性对应的编码;
学科编码:根据学科名称,查询“学科编码表”,获取对应学科编码;子学科编码:根据学科编码、子学科名称,查询“子学科编码表”,获取子学科编码;
专题编码:根据学科编码、子学科编码、专题名称,查询“专题编码表”,获取专题编码;
主题编码:根据学科编码、子学科编码、专题编码、主题名称,查询“主题编码表”,获取主题编码;
学习阶段编码:根据学习阶段名称,查询“学习阶段编码表”,获取学习阶段编码;
1)若该知识点为专题知识点,主题、时间性编码均赋值0;
2)若该知识点为主题知识点,时间性编码赋值0;
3)若该知识点为普通知识点,获取属性编码后,继续进行下一步时间性编码;
基于知识点基础表,根据知识点名称、主题,生成时间性编码,具体流程如下:
查询该学科及学习阶段下的“基础知识点表”,获取表中该主题下时间性编码最大值rcodemax,若该主题下没有知识点(即rcodemax没获取到),该知识点时间性编码赋值“01”;反之赋值“rcodemax+1”
2、按编码规则顺序组合编码,生成9位知识点编码,排列顺序如下:
知识点编码(9位)=学科编码(1位)+子学科编码(1位)+专题编码(2位)+主题编码(3位)+时间性编码(2位)
(2)构建学科相关性知识点库
在“基础知识点表”的基础上,计算机自动对每个知识点进行属性相关性计算、语义相关性计算,分别获取属性相关知识点编码集合、语义相关性知识点编码集合,并将知识点名称、知识点编码、属性相关性知识点集合、语义相关性知识点集合录入到相应的相关性知识点表,最终完成学科相关性知识点库的构建。具体步骤如下:
第一步:计算属性相关知识点集合
基于学科基础知识点库,对各知识点与其对应的“基础知识点表”内其他知识点进行属性相关性计算,获取各知识点的属性相关知识点集合(即直系和旁系知识点,各知识点以编码方式存储,其编码按知识点的亲疏度从大到小依次排序)。知识点属性关系计算流程如下:
下面举一个例子:已知以下7个知识点编码,分别为:
知识点a(fg0100000)
知识点b(fg0100100)
知识点c(fg0100200)
知识点d(fg0100300)
知识点e(fg0100101)
知识点f(fg0100102)
知识点g(fg0100103)
求:
(1)求知识点e的直系知识点、旁系知识点?
(2)求e与各知识点间的亲疏关系?
(3)求各知识点与e的相关度?
解:
(1)求直系、旁系关系
e与b=000000000(直系关系)
e与a=000000000(直系关系)
e与c=000000100(旁系关系)
e与f=000000001(旁系关系)
e与d=000000100(旁系关系)
e与g=000000001(旁系关系)
(2)求e与各知识点间的亲疏关系
第1步:按各属性编码段依次进行类似按段进行的“异或”运算,其中以
第2步:根据目标知识点与直系知识点的亲疏度大于旁系知识点进行排序,排序结果为:e>(a、b)>(c、d、f、g)
第3步:根据“异或”运算的结果,分别对直系、旁系知识点进行升序排列:
直系知识点排序结果:b>a
旁系知识点排序结果:(f,g)>(c,d)
第4步:对逻辑运算结果相同的知识点,根据知识点编码进行升序排列:f>g,c>d;
第5步:对e与所有知识点根据亲疏度进行排序整合,则最终排序结果为:ebafgcd;
(3)求e与各知识点的相关度
第1步:相关知识点的总数n=7
第2步:按亲疏度排序,计算相关知识点到e的距离
排序:ebafgcd
各知识点到e的距离m为:m(b)=1;m(a)=2;m(f)=3;m(g)=4;m(c)=5;m(d)=6
第3步:计算各知识点与e的相关度
各知识点与e的相关度:
x(b)=1-1/7=6/7;
x(a)=1-2/7=5/7;
x(f)=1-3/7=4/7;
x(g)=1-4/7=3/7;
x(c)=1-5/7=2/7;
x(d)=1-6/7=1/7;
第二步:计算语义相关知识点集合
基于知识点语义资料,进行语义相关度计算,获取语义相关知识点集合。
1)基于知识点语义资料,获取语义资料中的知识点,并以编码方式保存;
2)对各知识点,与其对应的基础知识点表(c+学科编码+学习阶段编码)中其他知识点进行语义相关计算,获取语义相关知识点编码集合(按语义相关度排序)。
语义相关计算原理如下:
第1步:获取知识点语义资料中包含的知识点集合;
例如:知识点a的语义资料中包含m个知识点,知识点b的语义资料中包含n个知识点,并将知识点以编码方式保存;
第2步:计算a与b的语义资料中相同的知识点编码,即取a与b的交集;
例如:a的语义知识点编码集合与b语义知识点编码集合的交集包含p个相同的知识点编码;
第3步:计算b与a的语义相关度x=p/m,若x≥0.5,则判定b为a的语义相关知识点,且x值越大,两个知识点的语义相关度越高。
第三步:计算相关性知识点编码集合
根据该知识点的属性相关知识点编码集合、语义相关知识点编码集合,计算该知识点的相关性知识点编码集合,具体流程如下:
1)获取属性相关知识点编码集合与语义相关知识点编码集合的并集,保存为该知识点的“相关性知识点集合”;
2)对相关性知识点集合进行排序,按知识点相关度值的大小,“降序”排列集合中的所有相关知识点编码,若知识点存在两个相关度(即属性相关度和语义相关度),则取较大值的相关度统一作为该知识点的相关度。第四步:构建学科相关性知识点库
根据知识点当前所处的学科、学习阶段,将“知识点信息(知识点名称、知识点编码)”及相关性知识点信息(属性相关知识点集合、语义相关知识点集合、相关知识点集合)存储到对应学科、学习阶段的相关性知识点表,所有知识点均以编码方式存储,完成学科相关性知识点库的构建。
下面说明学科相关性知识点库应用的例子
在学生自学过程中,根据学生当前掌握的知识水平,以相关性知识点库为基础,帮助学生制定当前阶段的学习路线,确定本阶段知识点的学习顺序,使学生完全掌握大纲内所有知识点。
第一步:结合学生当前学习水平,确定需要初步学习的知识点,即当前学习阶段的第一个知识点。
第二步:根据已经明确的第一个知识点,查询相关性知识点表(r+学科编码+学习阶段编码),获取该知识点的属性相关性知识点集合,并以该集合中的知识点的排列顺序为用户规划学习路线,完成教学大纲内主要知识点学习顺序的制定;
第三步:基于第二步中已经确定的教学大纲内主要知识点,查询相关性知识点表(r+学科编码+学习阶段编码),分别获取学习路线中主要知识点的语义相关知识点,对主要知识点进行拓展学习推荐,丰富学生的知识体系。
学习路线详细规划如图3所示,以“知识点a、b、c、……n”为主要路线,并以各主要知识点的语义相关知识点(如a1、a2、……an)对主要知识点进行拓展学习。
除了上面的应用例子之外,学科相关性知识点库还有很多其他的应用的方式。例如,在进行测试时,如果发现学生的一个题目做错了,可以从这个题目所涉及的知识点,根据学科相关性知识点库找到最相关的其他知识点,在这些知识点中出题,以便能够使得试题更有针对性,提高测试的效率。又如,在教师准备课件时,可以针对一个特定的知识点,查询学科相关性知识点库找到相关的其他知识点,进一步查询到这些相关知识点的素材,这样可以大大提高课件制作的效率。
本发明第二实施方式涉及一种学科相关性知识点库构建系统。该学科相关性知识点库构建系统包括:
属性相关计算单元,用于对于多个知识点,计算每个知识点的属性相关知识点集合。
语义相关计算单元,用于计算每个知识点的语义相关知识点集合。
相关性计算单元,用于根据属性相关知识点集合和语义相关性知识点集合,计算每个知识点的相关性知识点集合。
第一实施方式是与本实施方式相对应的方法实施方式,本实施方式可与第一实施方式互相配合实施。第一实施方式中提到的相关技术细节在本实施方式中依然有效,为了减少重复,这里不再赘述。相应地,本实施方式中提到的相关技术细节也可应用在第一实施方式中。
需要说明的是,本领域技术人员应当理解,上述学科相关性知识点库构建系统的实施方式中所示的各模块的实现功能可参照前述学科相关性知识点库构建方法的相关描述而理解。上述学科相关性知识点库构建系统的实施方式中所示的各模块的功能可通过运行于处理器上的程序(可执行指令)而实现,也可通过具体的逻辑电路而实现。本发明实施方式上述学科相关性知识点库构建系统如果以软件功能模块的形式实现并作为独立的产品销售或使用时,也可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明实施方式的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机、服务器、或者网络设备等)执行本发明各个实施方式所述方法的全部或部分。而前述的存储介质包括:u盘、移动硬盘、只读存储器(rom,readonlymemory)、磁碟或者光盘等各种可以存储程序代码的介质。这样,本发明实施方式不限制于任何特定的硬件和软件结合。
相应地,本发明实施方式还提供一种计算机存储介质,其中存储有计算机可执行指令,该计算机可执行指令被处理器执行时实现本发明的各方法实施方式。
此外,本发明实施方式还提供一种学科相关性知识点库构建系统,其中包括用于存储计算机可执行指令的存储器,以及,处理器;该处理器用于在执行该存储器中的计算机可执行指令时实现上述各方法实施方式中的步骤。
需要说明的是,在本专利的申请文件中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。本专利的申请文件中,如果提到根据某要素执行某行为,则是指至少根据该要素执行该行为的意思,其中包括了两种情况:仅根据该要素执行该行为、和根据该要素和其它要素执行该行为。多个、多次、多种等表达包括2个、2次、2种以及2个以上、2次以上、2种以上。
在本申请提及的所有文献都在本申请中引用作为参考,就如同每一篇文献被单独引用作为参考那样。此外应理解,在阅读了本申请的上述讲授内容之后,本领域技术人员可以对本申请作各种改动或修改,这些等价形式同样落于本申请所要求保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!