一种基于独立向量分析和支持向量机的地质灾害次声信号分类识别方法及装置与流程
本发明涉及地质次声信号识别
技术领域:
,特别涉及一种基于独立分量分析和支持向量机的次声信号分类识别方法。
背景技术:
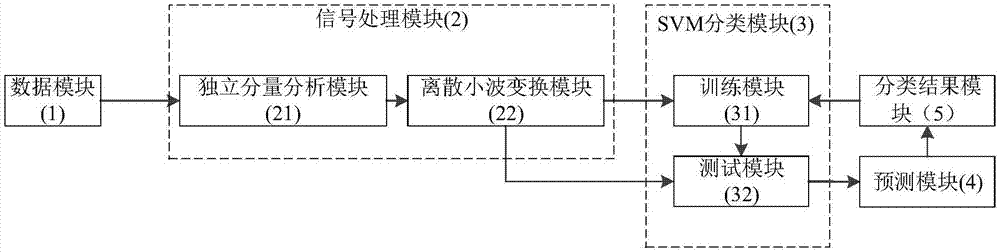
地质灾害具有突发性,一旦发生将产生重大的人员伤亡和财产损失,而成功预测地质灾害有很大的现实意义。研究表明,通过监测地质灾害产生的次声信号可以实现地质灾害预警,通过提高地质灾害预警的准确率,可为相关部门争取时间,保障人们的生命财产安全。但次声站采集到的次声数据中往往混杂着除地质灾害次声之外的多种次声信号,这对后续的地质灾害次声识别有很大影响,所以对次声站采集到的次声数据进行信号处理之后再分类识别是必要的。本发明首次将独立分量分析方法引入到次声信号的分类识别中,将独立分量分析与特征提取方法相结合,可显著提高最终的分类结果,具有很好的发展前景。技术实现要素:本发明提供了一种基于独立分量分析和支持向量机的地质灾害次声信号分类识别方法及装置,其中包括:数据模块(1)、信号处理模块(2)、支持向量机分类模块(3)、预测模块(4)、分类结果模块(5);数据模块(1)与信号处理模块(2)连接,信号处理模块(2)与支持向量机分类模块(3)连接,支持向量机分类模块(3)与预测模块(4)连接、预测模块(4)与分类结果模块(5)连接。优选地,其中所述信号处理模块(2)包括独立分量分析模块(21)和离散小波变换模块(22);所述支持向量机分类模块(3)包括训练模块(31)和测试模块(32);数据模块(1)与独立分量分析模块(21)连接,独立分量分析模块(21)与离散小波变换模块(22)连接,离散小波变换模块(22)分别与训练模块(31)、测试模块(32)连接,训练模块(31)与测试模块(32)连接,测试模块(32)与预测模块(4)连接、预测模块(4)与分类结果模块(5)连接。优选地,数据模块(1)用于保存地质灾害事件的次声信号,其中所有次声信号经截断后信号长度一致;将截断后的次声信号经过独立分量分析模块(21)的处理,采用独立分量分析方法处理信号;经过独立分量分析模块(21)的处理后的信号,通过离散小波变换模块(22)分解出信号的高频系数与低频系数提取该信号的特征向量;将提取的特征向量按照特定比例分别输入到训练模块(31)和测试模块(32)。优选地,将提取的特征向量按训练集:测试集=2:1的比例分别输入到训练模块(31)和测试模块(32);所述训练模块(31)用于对支持向量机分类模块(3)进行训练以获取最优参数,测试模块(32)用于测试支持向量机分类模块(3)的最终分类结果。优选地,测试模块(32)的输出信号被输入到预测模块(4),所述预测模块(4)根据分类结果判断信号为何种地质灾害事件产生的。优选地,根据分类结果模块(5)的分类准确率调整训练模块(31)和测试模块(32)的参数,优化预测结果。附图说明附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。图1为本发明实施例提供的一种地质灾害次声信号分类识别装置结构图;图2为本发明实施例提供的信号训练、测试流程图;图3为本发明实施例提供的一种地质灾害次声信号分类识别流程图。具体实施方式以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。本发明实施例提供一种基于独立分量分析(independentcomponentanalysis,ica)和支持向量机(supportvectormachine,支持向量机)的地质灾害次声信号分类识别装置,如图1所示,包括:数据模块1、信号处理模块2、支持向量机分类模块3、预测模块4、分类结果模块5;数据模块1与信号处理模块2连接,信号处理模块2与支持向量机分类模块3连接,支持向量机分类模块3与预测模块4连接、预测模块4与分类结果模块5连接。根据本发明的一个具体实施方式,其中所述信号处理模块2包括独立分量分析模块21和离散小波变换模块22;所述支持向量机分类模块3包括训练模块31和测试模块32;数据模块1与独立分量分析模块21连接,独立分量分析模块21与离散小波变换模块22连接,离散小波变换模块22分别与训练模块31、测试模块32连接,训练模块31与测试模块32连接,测试模块32与预测模块4连接、预测模块4与分类结果模块5连接。数据模块1用于保存地质灾害事件的次声信号,根据本发明的一个优选实施方式,可以是混合包含有地震、海啸和火山等三种不同地质灾害事件的次声信号,每个次声信号记录的采样频率为20hz;根据本发明的一个优选实施方式,由于各次声站获取的次声信号长度不同,因此需对所有信号进行截断使其信号长度一致。根据发明的一个优选实施方式,截断使得所有输出信号s的维度(采样点数)一致,例如为1024个点,根据发明的一个优选实施方式,地质灾害事件的次声信号可从全面禁止核试验条约北京国家数据中心申请获得。将截断后的次声信号经过独立分量分析模块21的处理,采用独立分量分析方法处理信号可根据高阶统计量找出混合信号中相互独立的部分,保留信号的随机统计特征,抑制其中存在的高斯噪声,因此,可分离出混合地质灾害次声信号中各类地质灾害次声信号的独立分量信号,减少噪声的干扰。经过独立分量分析模块21的处理后的信号,进一步通过离散小波变换模块22分解出信号的高频系数与低频系数,一个信号的所有分解系数可作为该信号的特征向量;将提取的特征向量按照特定比例分别输入到训练模块31和测试模块32。根据本发明的一个优选实施方式,将提取的特征向量按训练集:测试集=2:1的比例分别输入到训练模块31和测试模块32。所述训练模块31用于对支持向量机分类模块3进行训练以获取最优参数,测试模块32用于测试支持向量机分类模块3的最终分类结果。测试模块32的输出信号被输入到预测模块4,所述预测模块4根据分类结果判断信号为何种地质灾害事件产生的,例如是否为地震、海啸、火山产生的次声信号。进一步地,可根据分类结果模块5的分类准确率调整训练模块31和测试模块32的参数,优化预测结果。如图2所示,独立分量分析模块21进行信号分离的过程具体如下:将数据模块1中截断后的信号作为输入信号s,其通过混合矩阵a进行随机线性组合,得到观测信号x,其表达式为:根据本发明的一个具体实施方式,其中s=(s1,s2,l,sm)t为m维输入信号,si为独立分量;x=(x1,x2,l,xn)t表示n维随机观测向量;混合矩阵a=[a1,a2,l,an]是一个满秩的n×m维矩阵,ai是混合矩阵a的基向量。因此,各观测数据xi是由独立分量si经过不同的aij线性加权得到的,但独立分量si是不能被直接测量的隐含变量,而混合矩阵a也是未知矩阵,唯一已知只有随机观测向量x,若没有任何限制条件,仅由x估计出s和a,该式的解必为多解,因此只有假设未知源信号间相互独立的才能得到唯一解,从而实现独立分量提取。在具体的分析过程中,由于独立分量分析的混合矩阵a和源信号s均未知,可能会存在以下问题:第一,分离出的信号幅度存在不确定性,在式中,如果将s中任一独立分量si扩大a倍,将a中相应的混合系数ai乘以1/a,等式依然成立。所以在观测信号幅度不变的前提下,源信号的幅度存在不确定性。根据本发明的一个具体实施方式,在求解独立分量时,事先假设s具有单位方差e{si2}=1,且各分量均值为零。第二,分离出的信号排列顺序存在不确定性,在式y=wx=was中,独立分量si的顺序很容易改变,在x=as中插入一个置换矩阵p及其逆矩阵p-1,则有x=ap·p-1s,将ap-1看成新的混合矩阵,则p、s中的各分量便成为顺序改变的新独立分量si,这表明ica分离结果存在排序上的不确定性。根据实验数据测得,幅度和排序的不确定性不会对算法的分离过程产生影响。根据本发明的一个具体实施方式,独立分量分析的前提假设以下条件:第一,各源信号si均为0均值的随机变量,且各源信号之间统计独立;第二,源信号数m与观测信号数n相同,即m=n,这时混合阵a是一个确定且未知的n×n维方阵;第三,各个si的概率密度函数中只允许有一个具有高斯分布,如果具有高斯分布的源信号个数超过一个,则各源信号是不可分的。xy为简化模型,假设未知混合矩阵a是方阵,即m=n,那么独立分量分析的目的就是寻找一个变换矩阵w对x进行线性变换,得到n维输出向量y,且y=wx=was。当允许存在比例不定性和顺序不定性的前提下,y成为对独立分量si的近似估计这样就求出了源信号的近似信号y,其中w为解混矩阵,是近似于混合矩阵a的逆矩阵。y中各分量的独立性越好,y越接近s,此时w越好。将独立分量分析模块21进行信号分离后将得到信号y输出至离散小波变换模块22。根据本发明的一个具体实施方式,离散小波变换模块22根据离散小波变换的公式计算出小波分量y,其中a的尺度因子,控制小波函数的伸缩,对应于频率(反比);τ为平移量,控制小波函数的平移,对应于时间;为小波函数。由于小波变换能对时间(空间)频率的局部化分析,通过伸缩平移运算对信号逐步进行多尺度细化,最终达到高频处时间细分,低频处频率细分,从而自动适应时频信号分析的要求,从而可聚焦到信号的任意细节。小波变化将傅里叶变换中的无限长三角函数基换成了有限长、会衰减的小波基:该式为y(t)的连续小波变换,其中尺度变量a控制小波函数的伸缩,对应于频率(反比),平移变量τ控制小波函数的平移,对应于时间,这样就既可以获得信号的频率,又可以定位时间了。但式将一维信号y(t)变为二维的wty(a,τ),产生了信息冗余,因此,从数据压缩以及节约计算的角度上看,可以对尺度因子a和平移因子τ进行离散化处理,以减少冗余。离散小波变换的离散化首先是尺度因子a的离散化,根据本发明的一个优选实施方式,对a按照幂级数作离散化,即令a取l,此时对应的小波函数为然后是平移因子τ的离散化,当时,τ是以某一个基本的间隔τ0作均匀采样;当时,由于的宽度是ψ(t)的倍,故采样间隔也扩大倍。也就是说,在某一个j值下沿τ轴以为间隔的均匀采样可以保证信息不丢失,这样在计算中小波函数ψaτ(t)将被改写为将代入式中,得到的离散小波变换为根据本发明的一个具体实施方式,可根据信号长度选择合适的分解层数,根据本发明的一个优选实施方式,由于所截取的次声信号长度为1024个采样点,而1024=210,所以经离散小波变换后信号被分解为10层,即离散小波变换提取的特征维度为10。离散小波变换模块22输出信号为小波分量y;其中wty表示y为小波分量。支持向量机分类模块3将所有次声信号的小波分量y按特定比例分别送往训练模块31,以及测试模块32。根据本发明的一个优选实施方式,将所有次声信号的小波分量y按照训练集信号个数:测试集信号个数=2:1分为两组,分组后的数据被分别送往训练模块31,以及测试模块32。在二维空间中,对于一个二分类模型,设样本c1为正样本,其样本类别标签为1,样本c2为负样本,其样本类别标签为-1。令yi表示样本,zi表示第i个样本的类别标签,可通过线性函数g(yi)=<wt,yi>+b将c1与c2分开,该函数使得所有属于正样本的点y+代入以后有g(y+)≥1,而所有属于负样本的点y-代入后有g(y-)≤-1。在三维空间中,要将c1与c2分开则需要一个面,而在n维空间中则需要n-1维的超平面才可以将c1与c2分开。因此,可将分隔超平面h表示为g(yi)=<wt,yi>+b=0。若h1和h2是平行于h,且距离h最近的两类样本的直线,则h1与h、h2与h间的间隔可表示为di=zi·(<wt,yi>+b)。该式代表一种理想情况,即c1与c2的样本都不重叠,但在实际中,c1与c2的样本会有少数样本存在混叠,这种受极少样本影响的情况叫做“近似线性可分”,而这种样本点叫做离群点。离群点通常被认为是噪声,在计算时应该忽略掉,但是程序本身没有这种“容错”思维,它会在此基础上寻找样本间的最大几何间隔,这种离群点的存在会使得整个问题无解。若要全部样本点距超平面的距离均大于某一阈值,这种情况可叫做“硬间隔”分类法,该方法很容易被少数的点影响,造成算法的不稳定。为解决上述问题,可以允许少数样本点不符合距离阈值的要求。由于不同的训练集各点的间距尺度不同,因此可令di>1,并给硬性阈值1增加松弛变量ξi引入容错机制,ξi的值影响离群点与超平面的最大距离。则h1与h、h2与h间的间隔可改写为:di=zi·(w,yi>+b)≥1-ξi(ξi≥0,i=1,2,l,n),式中松弛变量ξi是非负的,表示当有离群点出现时最终的间隔要求可以小于1,这也意味着放弃了对离群点的精确分类,对分类器是一种损失;但该损失会减少离群点的影响,增大di,使得超平面更加光滑。对w、b分别作归一化后几何间隔变为上式中,zi(<wt,yi>+b)di与||w||为反比关系,则maxdi与min||w||等同,所以要求出di的最大值,需要找出样本中离超平面最近的样本点,这种样本点称为支持向量,然后优化w和b求出maxdi。而||w||又受到离群点影响,所以可将代表损失的离群因子c加入到目标函数中,这就变为了一个带约束条件的最小值问题,也是一个二次规划问题:subjecttoyi[<w,xi>+b]≥1-ξi(ξi≥0,i=1,2,l,n),式中的c表征对离群点的重视程度,当ξi一定时,c越大表明这些离群点越重要,产生的损失也就越大。求解g(y)的过程就变为了求w(n维向量)和b(实数)两个参数的过程,一旦求出变量w,那么实数b、超平面h、样本直线h1和h2就都可以求出了。因为当样本给出时,超平面h与样本直线h1、h2就已经唯一确定了,所以w就是由样本点和样本类别决定的,则w可表示为:式子中的αi为拉格朗日乘子,yi为样本点,zi为第i个样本的类别标签,n为样本个数,在该式中,只有落在h1和h2上的样本点(支持向量)不等于0,正是这部样本点唯一确定了分类函数,将式w代入式g(xi)=<wt,yi>+b中可得到:此时,优化问题的约束条件可去掉,使得计算简化。其中<yi,y>就是支持向量机的核函数k<yi,y>,核函数可以将样本由低维空间向高维空间转化,使其变得线性可分。在选择核函数时可通过三种方式,第一种是利用原有的经验和先验知识预先选择核函数;第二种是通过交叉验证的方法试用不同的核函数,从中选出分类误差最小的核函数;第三种是混合核函数方法,将不同的核函数结合后使用以获得更好的特性。如果特征的数量大到和样本数量相当,则可选用逻辑回归或者线性核函数的支持向量机;如果特征的数量小,样本的数量正常,则可选用高斯核函数的支持向量机;如果特征的数量小,而样本的数量很大,则需要手工添加一些特征从而变成第一种情况。本方法中采用的核函数为高斯核函数。根据本发明的一个优选实施方式,训练模块(31)在训练过程中,需要根据训练数据确定离群因子c、高斯核函数的半径g的值,其中再用测试数据验证该参数下分类器的预测类别,计算出其分类准确率,若分类准确率低,需要更改c与g的值得到新的分类器,再测试分类结果,直到支持向量机的分类准确率最高,此时找到核函数参数g与离群因子c就是最优参数。将测试集testdata、训练过程中找到的核函数参数g与离群因子c输入至测试模块(32),则可根据训练过程中找到的核函数参数g、离群因子c、超平面公式根据本发明的一个优选实施方式,由于需要分类的次声信号分别对应地震、海啸和火山,因此,需计算出将测试集分为三类的分类超平面,然后输出对测试集中各个样本的预测类别标签。即,预测的测试集数据所属的次声类别(地震、海啸、火山)。预测模块(4),用于根据测试模块计算出的分类超平面,输出对测试集数据的预测类别标签预测数据所属的类别;分类结果模块(5),输出最终的分类结果。训练模块、测试模块、预测模块以及分类结果模块的流程可视为一个迭代的过程,可具体包括以下各步骤:201读取数据:读取训练数据、测试数据和相应的类别标签;202数据归一化:对读取的数据进行归一化处理;203参数寻优:找出支持向量机的最优参数c和g;根据本发明的一个优选实施方式,可根据交叉验证等方法进行选取;204训练支持向量机:根据训练数据、训练数据类别标签、最优参数c和g训练支持向量机,根据支持向量机性能选择是否继续进行测试;205测试支持向量机:将测试数据输入步骤204中获得的支持向量机模型中,得到支持向量机对测试数据的预测类别;206结果分析:对比测试数据的实际类别标签与预测类别标签,计算出正确分类的准确率,验证支持向量机的可靠性。根据本发明的一个具体实施方式,地址灾害次声信号分类识别处理流程如下:301输入次声信号:为方便次声信号作离散小波变换,对获取的次声信号进行截断处理,使其均为1024个采样点,即210个采样点,得到输入信号s;302零均值:对输入信号s进行零均值处理,即求出输入信号s的均值后,再由输入信号s减去该均值;303球化:令输入信号s与混合矩阵a相乘,计算出输入信号s的线性组合矩阵x,其中且x各行正交;304解混:求解混矩阵w计算出输入信号s的近似信号y,其中y=wx=was;305小波分解:对信号y作离散小波变换,不断将其分解为高频信号与低频信号,直到低频信号不可再分,这些高频信号与低频信号共同组成信号y的小波分量y,由于输入的次声信号为1024=210个采样点,小波分量y的维数为10;将小波分量y按训练集数据个数:测试集数据个数=2:1的比例分为两组,一组用于306生成训练集数据、一组用于307生成测试集数据;308训练支持向量机:将训练集数据及其所属次声事件的类别标签输入支持向量机中,根据公式及其约束条件subjecttoyi[<w,xi>+b]≥1-ξi(ξi≥0,i=1,2,l,n),计算出该支持向量机分类模型的离群因子c与高斯核函数的半径g的值,其中309测试支持向量机:根据测试集数据及该支持向量机分类模型的离群因子c与核函数参数g,计算出公式的值,即测试集数据的分类超平面,对其进行分类;310预测类别:根据步骤309中计算出的分类超平面,输出对测试集数据的预测类别标签。根据本发明的一个优选实施方式,在实验阶段,由于样本数据所属的地质灾害属性已知,因此可进一步增加分类准确率判断步骤,即j01分类准确率:将步骤310中获得的预测类别标签与测试集数据的实际类别标签进行对比,计算出该支持向量机分类模型的分类准确率,其中分类准确率=测试集数据中正确预测的类别标签个数/测试集数据总个数。若该分类准确率符合预期要求,则进行步骤711输出其最终的分类结果;若该分类准确率过低,则重复步骤308~310直到得到符合预期的分类准确率。如在系统正式运行阶段,由于实时监测过程中无法知晓数据的实际属性,因此可略过该步骤,直接跳至步骤310分类结果输出。根据本发明的一个优选实施方式,分类准确率判断根据如下方式实现:如:测试集共有10个数据,其实际类别标签与预测类别标签如下:表1分类准确率对比表测试集数据12345678910实际标签1111222333预测标签1221122333比较相同不同不同相同不同相同相同相同相同相同由上表可以看出实际类别标签与预测类别标签相同的有7个,那这7个就是正确预测的类别标签,则有:正确预测测试集类别的数据个数/测试集数据的总个数=7/10=70%即分类准确率为70%。本发明与现有技术相比的优点在于,首次将独立分量分析方法引入到次声信号分类识别中。将独立分量分析与离散小波变换共同处理次声信号后,其次声信号的分类准确率比直接进行离散小波变换的分类准确率提高40%以上,为次声信号的监测和分析提供了一种可行的方法。根据本发明的一个优选实施方式,使用的次声数据由全面禁止核试验条约北京国家数据中心提供,来自全球7个次声站,共611个次声信号,包含地震、海啸、火山三种次声事件,采样频率为20hz。由于在各次声站获取的次声信号长度不同,且方便次声信号作离散小波变换,需对所有信号进行截断,使得所有试验使用的数据长度为1024点。由于申请的次声数据均为地灾发生时采集到的,在进行截断时选择波动明显的、连续的1024个采样点即可。如表1所示,为本发明次声数据的来源与数据个数。611个次声数据的取值详见表2,其中地震次声信号203个,海啸次声信号218个,火山次声信号189个。表2次声数据本发明所用的支持向量机为分类算法,是一种有监督的分类算法,即需要用训练集数据进行训练,建立相应的数学模型,然后用测试集数据验证分类结果。表2所示,为本发明用于训练与测试的次声信号数量及类别标签。在本发明中,令训练集信号数量:测试集信号数量=2:1。本发明所用的支持向量机在训练、测试过程中,需要给数据集赋予类别标签,使其能学习到各类别的主要特征,实现对测试集数据的类别进行预测,将预测出的测试集类别与实际测试集类别进行对比,计算出该支持向量机的分类准确率,即分类准确率=测试集数据中正确预测的类别标签个数/测试集数据总个数。在本发明中,令地震次声信号的类别标签为“1”,海啸次声信号的类别标签为“2”,火山次声信号的类别标签为“3”。表3用于训练和测试的次声信号及类别标签在本发明中,次声信号分类准确率对比如表4所示。表4次声信号分类准确率对比由表4的第一行可以知,若次声信号不经过信号处理模块2直接输入支持向量机分类模块3,其分类准确率为37.93%;若次声信号仅经过离散小波变换模块22后输入支持向量机分类模块3,其分类准确率为33.01%。可见,次声信号不经过处理直接进行分类识别或者仅进行离散小波变换后作分类识别的结果均不理想,其原因可能为次声信号中含有的噪声太多,影响了最终的分类结果。由表4的第二行可以知,若次声信号仅经过独立分量分析模块21后输入支持向量机分类模块3,其分类准确率为32.51%;若次声信号经过信号处理模块2后输入支持向量机分类模块3,其分类准确率为78.33%。可见,次声信号由独立分量分析与离散小波变换共同处理后的分类准确率有显著提升,次声信号由独立分量分析处理后可抑制高斯噪声,计算出次声信号的独立分量,再经过离散小波变换后提取出独立分量的高频、低频信号作为其特征向量,而特征向量的有效性决定了最终的分类结果。由表4的第三行可知,若次声信号仅经过主成分分析后输入支持向量机分类模块3,其分类准确率为66.50%;若次声信号经过主成分分析与离散小波变换模块22后输入支持向量机分类模块3,其分类准确率为62.07%。可见,次声信号的分类结果并不理想,其原因可能是主成分分析更在意数据的能量或方差,适合噪声较微弱的情况,而本发明所用的地质灾害次声信号的最高频率是20hz,在混合的次声信号中,噪声与感兴趣的信号的能量差别不大,不适合使用主成分分析法。独立分量分析不在意信号的能量或方差,输入的混合信号不论通过何种线性变换都不影响最终的输出结果。所以在次声信号的分类识别中,独立分量分析比主成分分析更为适合。综上所述,次声信号经过独立分量分析与离散小波变换后,分类准确率最高,且分类准确率提高显著。以上所述,仅是本发明的较佳实施例而已,并非对本发明作任何形式上的限制,虽然本发明已以较佳实施例揭露如上,然而并非用以限定本发明,任何熟悉本专业的技术人员,在不脱离本发明技术方案范围内,当可利用上述揭示的技术内容作出些许更动或修饰为等同变化的等效实施例,但凡是未脱离本发明技术方案的内容,依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化与修饰,均仍属于本发明技术方案的范围内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1