一种基于R*树索引的时空轨迹聚集模式挖掘算法的制作方法
本发明涉及数据挖掘领域,主要对时空轨迹聚集模式挖掘算法crowd-tad(crowd-testanddivide)进行改进,以提高聚集模式挖掘算法的准确性和效率,具体涉及一种基于r*树索引的时空轨迹聚集模式挖掘算法。
背景技术:
时空轨迹模式挖掘是指从移动对象的运动轨迹中发现有用的行为规律来获取有价值的信息。其中时空轨迹聚集模式挖掘主要挖掘出在一定空间范围内持续一段时间的密集的移动对象群体,广泛应用于流量预测和交通线路规划等方面。
时空轨迹聚集模式的特点可以根据以下因素进行区分:移动群组的形状或者密度、群组中的对象数以及移动持续的时间。随着研究的深入,时空轨迹聚集模式的定义也越来越符合实际场景。在这些聚集模式中,gathering模式是目前最新定义的聚集模式,该模式定义中的限定比较宽泛,适用于城市计算、流量预测等多种应用场景。
gathering模式的挖掘方法分为三种,分别是基于网格的挖掘算法、基于r树的挖掘算法和基于时空图的挖掘算法。基于网格索引的聚集判断算法原理是在每个时间点建立网格索引遍历聚簇集合,得出需要进行距离计算的聚簇集合,减少计算量,缺点是索引效率受划分粒度影响。基于r树索引的聚集判断算法原理是在计算聚簇间的距离时,在每个时间点建立r树索引存储聚簇最小外包矩形,利用r树的窗口查询进行剪枝,减少聚簇间的距离计算,缺点是r树实现复杂,边界矩形不一定近似聚簇形状。基于时空图的聚集判断算法原理是根据轨迹聚类信息建立时空图,根据时空图进行聚集判断,缺点是时间复杂度高,当数据量增长过快时,时空图规模大,挖掘算法效率降低。
针对时空轨迹聚集模式挖掘的研究还存在以下问题:一是现有的挖掘算法中没有考虑移动对象的运动方向属性,不能准确地反映移动对象的动态特征;二是针对轨迹聚类过程时间复杂度高,运行时间长,目前没有一个最优的聚类方案。针对以上问题,本发明在深入研究时空轨迹聚集模式挖掘算法的基础上,提出一种基于r*树索引的聚集模式挖掘算法,在轨迹预处理阶段,提取轨迹的运动方向、运动速度和偏移信息综合表示轨迹,进行轨迹压缩;在聚类阶段,对轨迹按照时间区间分成轨迹段,使用基于r*树索引的线段dbscan进行轨迹聚类。相关实验表明本方法相比已有算法,在保证挖掘算法准确性的基础上具有更高的挖掘效率。
技术实现要素:
本发明主要采用以下技术手段实现:
一种基于r*树索引的时空轨迹聚集模式挖掘算法,其特征在于,包括:
步骤1、对轨迹进行预处理,包括提取轨迹特征并对提取的轨迹特征进行关键点判断,得到压缩后轨迹;
步骤2、对步骤1得到的压缩后轨迹进行轨迹聚类,首先进行时间片划分,然后对于每个时间片创建一颗r*树,最后对每个时间片内的所有轨迹段进行聚类;
步骤3、对步骤2已经聚类后的轨迹进行聚集判断,首先经过群体判断确定群体数量,并经过聚集判断确定群体中的参与者,完成最终的聚集集合。
在上述的一种基于r*树索引的时空轨迹聚集模式挖掘算法,所述步骤1具体包括:
步骤1.1、轨迹特征提取,具体是采用轨迹的移动方向、移动速度和偏移信息三类特征来描述轨迹;
对于轨迹点序列t={(x1,y1),(x2,y2),...,(xn,yn)},(xi,yi)为轨迹点的坐标,t中元素个数为轨迹数据所包含的轨迹点个数;
第i次采样时移动对象的运动方向计算如下:
第i次采样时移动对象运动方向的变化值的计算如下:
δ(θi-θi-1)=min{|θi-θi-1|,2π-|θi-θi-1|}
第i次采样时移动对象的运动速度为相邻两轨迹点的连线长度与时间间隔的比值,其速度变化值的计算为相邻点的速度之差;
pi-1(xi-1,yi-1),pi(xi,yi),pi+1(xi+1,yi+1)为原始轨迹上3个连续的轨迹点,若压缩后的轨迹为pi-1pi+1的连线,轨迹点pi(xi,yi)在该线段上按时间比例的投影位置为p′i(x′i,y′i),则第i次采样时移动对象的偏移距离即pi(xi,yi)到p′i(x′i,y′i)的sed距离计算如下:
其中
步骤1.2、关键点判断,得到压缩后轨迹,定义轨迹集合tr={p1,p2,…,pt},方向改变阈值θα,速度改变阈值θν,偏移距离阈值θd,
针对轨迹集合tr中的每一个轨迹点,依次计算δdir、δsp、δd,并进行判断:
若δdir、δsp、δd满足任意条件:δdir>θα或者δsp>θν或者δd>θd,
将pi加入压缩后轨迹str,判断tr中的下一个轨迹点;否则,直接判断tr中的下一个轨迹点。
在上述的一种基于r*树索引的时空轨迹聚集模式挖掘算法,所述步骤2具体包括:
步骤2.1、进行时间片划分,具体是将时间域表示为t=<t1,t2,…,tn>,然后设置时间间隔长度λ值,将整个时间域划分成相同时间间隔的时间区间s=<τ1,τ2,...,τt>;
步骤2.2、创建r*树,具体是对于每个时间片创建一颗r*树,叶子节点存储轨迹段的最小外包矩形信息,非叶子节点含有指向下一级节点的指针,包含到下一级节点的最小外包矩形的条目信息;
步骤2.3、聚类轨迹段,对每个时间片内的所有轨迹段进行聚类操作,具体是遍历所有轨迹段,判断当前轨迹段oi是否为核心轨迹段;通过r*树的窗口查询,找出当前轨迹段的所有近邻轨迹段;r*树的窗口指的是轨迹段oi的扩大到聚簇半径距离阈值∈的最小外包矩形;如果叶子节点中的轨迹段与窗口相交,则与窗口相交的轨迹段是轨迹段oi的近邻,判断这些轨迹段的密度,若其密度超过邻域密度阈值,说明轨迹段oi是核心轨迹段,将该轨迹段加入候选聚簇;对轨迹段oi的邻域内的轨迹段依次判断是否为核心对象,直到所有轨迹段均已被访问,最终获得带有类别标签的聚簇集合。
在上述的一种基于r*树索引的时空轨迹聚集模式挖掘算法,所述步骤3具体包括:
步骤3.1、群体判断:在每个时间点从当前聚簇集合中检测最后一个聚簇,判断能否通过继续增加聚簇来扩展成更大的群体,具体是将前一时刻的群体中最后一个簇与当前时刻所有聚簇进行距离判断,并根据判断结果执行:
执行一、若当前时刻聚簇中有一个距离小于阈值δ的聚簇,将其加入群体;
执行二、若有多个距离小于阈值δ的聚簇,复制前一时刻群体为多个,将这些符合条件的聚簇分别加入每个群体;
执行三、若说明没有距离小于阈值δ的聚簇,说明前一时刻的群体已经闭合,不能再扩展;
步骤3.2、聚集判断:计算群体中每个对象出现次数,
1a)、判断每个对象是否为一个参与者,若是,则标记,否则不标记;
2a)、统计群体中每个聚簇包含的参与者个数,
3a)、判断是否满足设定参与者数目阈值,若符合阈值条件则执行步骤4a),否则到5a)
4a)、判断群体生存周期是否满足设定阈值;
5a)、对于没有足够参与者的聚簇,删除这些聚簇,并以这些聚簇为界将群体分成多个子序列,对于每个仍然为群体的子序列,重复对这些群体进行聚集判断,直到所有群体都被遍历完成。
因此,本发明具有如下优点:本发明综合利用轨迹数据的运动方向、运动速度和偏移信息来压缩轨迹,提高算法压缩的效果;使用基于r*树索引的线段dbscan对轨迹段聚类,提高算法聚类的效率。相关实验表明该算法相比同类算法挖掘效果有所提高。接下来的工作就是将此算法运用于实际的轨迹数据聚集模式挖掘任务中,提高数据挖掘的效果。
附图说明
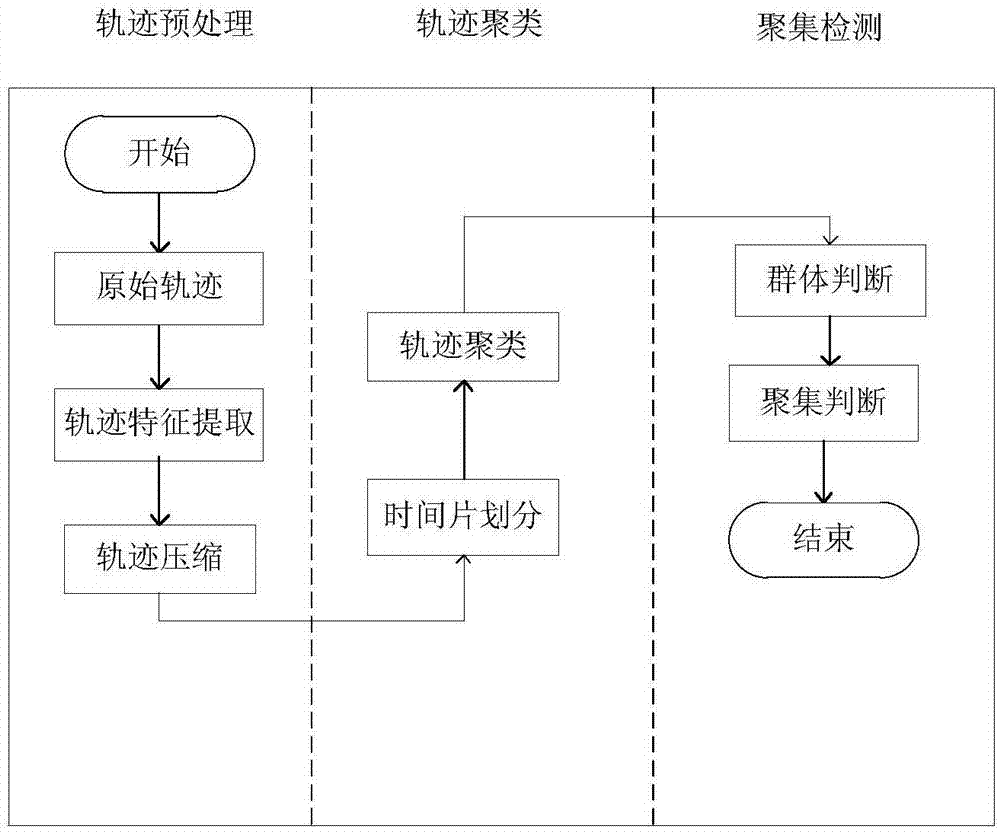
图1是本发明的聚集模式挖掘算法流程示意图。
图2a是本发明的dccr与crowd-tad算法进行比较后两种算法的准确性对比结果示意图(一天内不同时间段聚集数)。
图2b是本发明的dccr与crowd-tad算法进行比较后两种算法的准确性对比结果示意图(典型区域的聚集结果数量)。
图2c是本发明的dccr与crowd-tad算法进行比较后两种算法的准确性对比结果示意图(dccr挖掘出的典型区域的聚集结果数量)。
图2d是本发明的dccr与crowd-tad算法进行比较后两种算法的准确性对比结果示意图(dccr与crowd-tad挖掘出的聚集结果的相似度对比)。
图3a是本发明的dccr与brute-force、crowd-tad算法的效率对比结果示意图(三种算法在群体阈值个数上的效率对比)。
图3b本发明的dccr与brute-force、crowd-tad算法的效率对比结果示意图(三种算法在相邻时刻簇间距阈值上的效率对比)。
图3c是本发明的三种算法的效率对比结果示意图(相邻时刻簇间距阈值上的)。
图4是不同数据量的各个算法各阶段运行时间示意图。
具体实施方式
一、首先介绍下本发明的方法原理。
基于r*树索引的时空轨迹聚集模式挖掘算法,包括:
步骤1:轨迹特征提取。本发明考虑采用轨迹的移动方向、移动速度和偏移信息这三类特征来描述轨迹。
对于轨迹点序列t={(x1,y1),(x2,y2),...,(xn,yn)},(xi,yi)为轨迹点的坐标,t中元素个数为轨迹数据所包含的轨迹点个数。
第i次采样时移动对象的运动方向计算如下:
第i次采样时移动对象运动方向的变化值的计算如下:
δ(θi-θi-1)=min{|θi-θi-1|,2π-|θi-θi-1|}
第i次采样时移动对象的运动速度为相邻两轨迹点的连线长度与时间间隔的比值,其速度变化值的计算为相邻点的速度之差。
pi-1(xi-1,yi-1),pi(xi,yi),pi+1(xi+1,yi+1)为原始轨迹上3个连续的轨迹点,若压缩后的轨迹为pi-1pi+1的连线,轨迹点pi(xi,yi)在该线段上按时间比例的投影位置为p′i(x′i,y′i),则第i次采样时移动对象的偏移距离即pi(xi,yi)到p′i(x′i,y′i)的sed距离计算如下:
其中
步骤2:关键点判断,得到压缩后轨迹。
步骤3:时间片划分。将时间域表示为t=<t1,t2,...,tn>,然后设置时间间隔长度λ值,将整个时间域划分成相同时间间隔的时间区间s=<τ1,τ2,…,τt>。
步骤4:r*树创建。对于每个时间片创建一颗r*树,其叶子节点存储轨迹段的最小外包矩形信息,非叶子节点含有指向下一级节点的指针,包含到下一级节点的最小外包矩形的条目信息。图3-4反映了轨迹段在r*树中的存储结构。
步骤5:轨迹段聚类。对每个时间片内的所有轨迹段进行聚类操作。遍历所有轨迹段,判断当前轨迹段oi是否为核心轨迹段。通过r*树的窗口查询,找出当前轨迹段的所有近邻轨迹段。r*树的窗口指的是轨迹段oi的扩大到聚簇半径距离阈值∈的最小外包矩形。如果叶子节点中的轨迹段与窗口相交,说明这些轨迹段是轨迹段oi的近邻,判断这些轨迹段的密度,若其密度超过邻域密度阈值,说明轨迹段oi是核心轨迹段,将该轨迹段加入候选聚簇。对轨迹段oi的邻域内的轨迹段依次判断是否为核心对象,直到所有轨迹段均已被访问,最终获得带有类别标签的聚簇集合。
步骤6:。
在每个时间点从当前聚簇集合中检测最后一个聚簇,判断能否通过继续增加聚簇来扩展成更大的群体;
然后计算群体中每个对象出现次数,判断该对象是否为一个参与者,统计群体中每个聚簇包含的参与者个数,判断是否满足参与者数目阈值,若符合阈值条件则继续判断群体生存周期是否满足阈值条件,若符合阈值条件则该群体是一个聚集,否则找出没有足够参与者的聚簇,删除这些聚簇,并以这些聚簇为界将群体分成多个子序列,对于每个仍然为群体的子序列,重复以上步骤,直到所有群体都被发现。
二、以下是采用上述方法的具体案例。
实验所使用的轨迹数据集是从北京10357辆出租车采集到的一周的时空轨迹数据,数据集共有752mb大小。实验环境配置为:cpu为intel(r)core(tm)cpu(2.50ghz),内存8g,操作系统采用windows,实验采用java语言编写完成。
与本发明的研究工作最接近的是聚集模式挖掘算法crowd-tad,因此主要将本发明算法dccr与基于r树的crowd-tad算法进行实验对比。准确性通过挖掘出的聚集模式数量和聚集结果相似性两方面进行比较,效率通过算法的运行时间进行比较,算法的运行时间越短,表明算法越高效。
通过计算某个时间段的移动对象聚集数量将本发明的dccr与crowd-tad算法进行比较,验证dccr的准确性。图2显示了两种算法的准确性对比结果。
为验证本发明算法的效率,选择三种算法进行实验对比,分别是brute-force、crowd-tad和本发明算法dccr。brute-force算法是从轨迹数据库中取出所有符合时空约束的轨迹数据,依次遍历每一时刻的轨迹集合,对其进行扩展,最后发现聚集。crowd-tad算法是取出所有轨迹,对每一时间点的轨迹聚类,用crowd-tad算法挖掘出所有聚集。dccr算法是取出给定时间和空间范围的轨迹,对给定时间范围的轨迹进行聚类,按时间增量挖掘出所有聚集。
分两组实验,第一组实验,通过改变群体对象阈值mc、相邻时刻簇间距阈值δ和移动对象个数|odb|这三个参数进行三种算法的效率对比。其中,默认参数为:时间数据库tdb划分为7*24*15个时间片,每个时间片λ=4(分钟),移动对象数据库|odb|=3000,群体生存时间阈值kc=20(分钟),参与者生存时间阈值kp=15(分钟),参与者数目阈值mp=10,群体对象阈值mc=15,相邻时刻聚簇间的距离阈值δ=300(米)。
图3显示了三种算法的效率对比结果。
可以得出以下结论:
1)当mc增加时,所有算法运行时间都有所减少,这是因为当群体中所要求的对象阈值增加时,对于每一个时间片满足阈值条件的聚簇就会减少,因此符合条件的候选群体就会相应减少。另一方面,由于本文的算法dccr使用r*树索引加快了聚类中的查询过程,减少了计算量,使得dccr算法效率比crowd-tad和brute-force算法均有所提高。
2)当δ增加时,所有算法运行时间都有所增加,这是因为在查询下一时间片的候选聚类时,遍历区域增大了,显然这一过程需要花更多时间。同时因为本文的dccr算法采用索引剪枝策略和聚簇中心间距离判断,相比crowd-tad采用豪斯多夫距离计算聚簇中心距离和brute-force算法循环遍历移动群组的方式,减少了计算量,因此比这两种算法更加高效。
3)当增加移动对象个数|odb|时,所有算法都需运行更长时间,因为在每一时间片有更多的聚簇在形成。值得注意的是,当数据量增加到一定程度时,本文算法dccr反而会比crowd-tad算法更耗时,这是因为随着数据量增加,算法使用的r*树索引的创建和维护成本很高,这反而会使得改进算法失去使用r*树索引加快查询速度的优势。而随着数据量的增加,brute-force算法运行时间显著增长,大量轨迹段距离计算和聚簇间距离计算使得算法效率显著降低。总体来说,本文算法的效率优于crowd-tad和brute-force算法。
第二组实验,为进一步分析三种算法效率不同的原因,记录三种算法在不同数据量下的轨迹聚类和聚集判断阶段的运行时间,结果如图4所示。
从运行时间对比结果来看,三种算法都是在聚类阶段耗时巨大,因为聚类是从大量轨迹数据中发现密集聚簇,而聚集检测是从少量聚簇中检测gathering聚集,该部分运行时间相对较短。但也可以看出brute-force算法在两个阶段运行时间均最长,因为包含大量轨迹段距离计算和聚簇间距离计算。在轨迹聚类阶段,dccr算法使用基于r*树索引的聚类算法,利用r*树的窗口查询,减小计算量,而crowd-tad算法使用最小外包矩形进行轨迹段剪枝,仍然需要计算大量轨迹段的最小外包矩形间的距离,因此crowd-tad算法聚类效率不如dccr算法。在聚集检测阶段,crowd-tad算法由于使用豪斯多夫距离计算聚簇间距离,计算复杂,计算量大,虽使用r树索引检索聚簇,聚集检测阶段算法效率依然高于本文的dccr算法,因为dccr算法采用基于聚簇中心的聚簇间距离计算,大大减少了由豪斯多夫距离带来的计算量。
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
- 还没有人留言评论。精彩留言会获得点赞!