一种基于RSS订阅的新闻推荐方法与流程
本发明涉及一种基于rss订阅的新闻推荐方法,属于数据挖掘技术领域。
背景技术:
随着信息技术和互联网的发展,人们进入了全民网络时代,每天的信息都是呈现爆炸性的增长,人们每天都要接受大量的信息,新闻是信息的重要载体之一,浏览网络上及时发布的新闻是人们获取信息的主要手段之一。面对海量的新闻,用户需要时间与精力才能找到自己感兴趣的新闻,传统的推荐方法不仅推荐效率低,而且不能实时的进行个性化的推荐,体现不了不同用户之间的差别。
技术实现要素:
本发明要解决的技术问题是提供一种基于rss订阅的新闻推荐方法,用以解决上述问题。
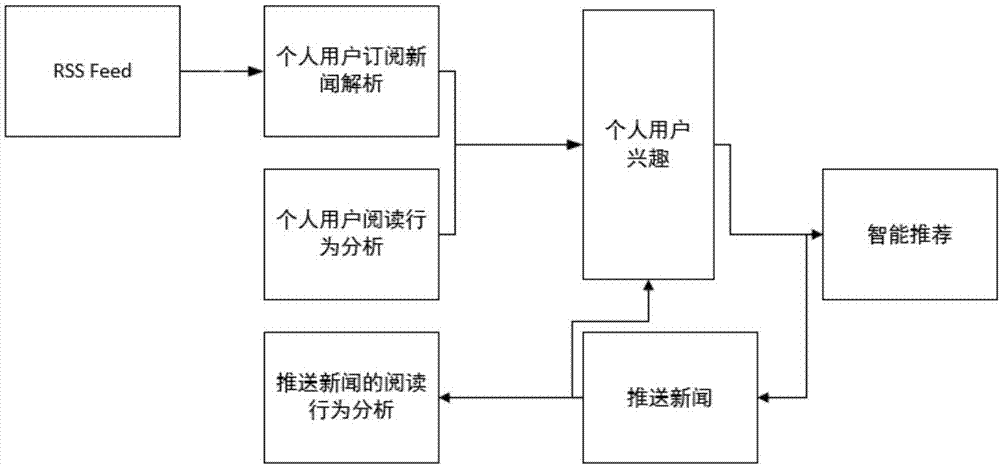
本发明的技术方案是:一种基于rss(简易信息聚合)订阅的新闻推荐方法,首先,通过用户的rss订阅信息,建立用户订阅信息数据库;其次,通过个人用户的rssfeed订阅下采集的新闻信息构建反映用户兴趣偏好的特征向量;然后,结合个人用户的订阅行为和浏览自主订阅的兴趣度分析,建立个人用户的综合兴趣模型;最后,进行基于内容和协同过滤相结合的主动推荐过程。
具体步骤为:
步骤1:通过用户的rss订阅,建立用户订阅信息数据库:根据订阅信息,栏目,栏目网站,内容,标题,url链接,变更时间,变更类型,正文条目,订阅时间,建立用户订阅信息数据库。
步骤2:通过个人用户的rssfeed订阅下采集的新闻信息构建反映用户兴趣偏好的特征向量:提供订阅机制的网站设置有rssfeed接口,rss文件中包括步骤1中数据库的所有内容。当页面更新时,接口模块自动生成rssfeed文件,定期扫描各网站的rssfeed文件,并根据解析出来的url链接网页内容聚合后发送给用户,用户可以通过rss阅读器进行订阅新闻信息的浏览。首先抽取用户订阅的rssfeed列表,获取每个rssfeed的类别信息,构建用户订阅的兴趣偏好特征向量集uv。取一段时间内所有订阅类(m个)中用户停留时间大于时间阈值t的n个类,则用户对feed(i)类订阅兴趣度可以表示为:
feed(i)表示个人用户订阅的其中一种新闻的类别。其中sum(feed(i))表示feed(i)类新闻的数量。
步骤3:阅读兴趣分析
步骤3.1:个人用户阅读行为分析:对于使用rss信息源的用户web中的服务器保留了用户访问日志等记录,保存了相关用户访问类别,访问时间和次数等信息,订阅rss的新闻信息说明用户兴趣偏好,抽取用户浏览行为日志,利用聚类,关联分析等方法,获取用户个性化兴趣与喜好。用户对feed(i)类兴趣由用户对它的访问次数与时长,以及浏览feed(i)类别所有feed数量n和没有浏览的数量m比决定,定义用户对feed(i)类的阅读兴趣度为:
其中time(feed(i))为访问feed(i)类中所有新闻的次数之和,tfeed(i)(j)为访问feed(i)类新闻第j次的访问时间。
步骤3.2:潜在阅读兴趣分析:用户的订阅行为是动态变化的,对订阅的某些新闻在一个时间段tp内没有阅读,这些新闻就具有潜在的阅读兴趣,定义ω为feed(i)类中订阅但没有浏览的新闻具有潜在兴趣时间阀值,dnfeed(i)(j)表示从订阅到目前的时间段(订阅了但是没有浏览的feed(i)类),则feed(i)类中没有浏览过的新闻的潜在阅读兴趣为:
其中n为满足阀值ω的feed(i)类中新闻的个数。则用户对feed(i)类的阅读兴趣度为:
fl(feed(i))=i(feed(i))+p(feed(i))
步骤4:个人用户协同推送的新闻阅读行为分析:利用协同过滤推荐算法构建相似兴趣用户群并聚类得到需要推荐的新闻;然后,反馈到用户兴趣模型的构建,实现正反馈;则定义用户阅读协同推荐新闻的兴趣度为:fm(feed(i))
协同过滤推荐算法步骤为:
(1)收集用户偏好:建立一个用户-项目评价矩阵描述用户对项目的评价,用户的判断和偏好表示为一个m*n的用户项目评价矩阵r,m是用户数,n是项目数,r=(rij),元素rij表示用户i对j的评价。
(2)生成“邻居”:计算所有用户对之间的相似度形成“邻居”。
(3)计算并推荐:通过目标用户对邻居项目的评价产生推荐。
步骤5:个人用户综合兴趣模型建立:个人用户综合兴趣模型由个人用户的订阅兴趣爱好特征向量集,个人用户订阅兴趣偏好,个人用户对feed(i)类的阅读兴趣度,个人用户阅读协同推荐新闻的兴趣度四个方面的特征共同组成,其个人用户综合兴趣模型可以表示为:
u={uv,dl(feed(i)),fl(feed(i)),fm(feed(i))}
步骤6:智能推荐:通过步骤5得到的个人综合兴趣模型,在包含所有用户的兴趣模型数据中,通过相似度计算找出和被推荐个人用户综合兴趣模型相似度最大的top—n邻居集合,然后进行排序,进行主动推荐。
本发明的有益效果是:本发明引入rss技术。将它与同协同推荐算法相结合。通过用户的rssfeed订阅下的新闻信息构建反映用户兴趣偏好的特征向量。结合用户的订阅行为和浏览自主订阅的兴趣度分析,建立用户的综合兴趣模型。进行基于内容和协同过滤相结合的主动推荐过程。保障了个人兴趣的独立性,同时提高了推荐新闻的精度与准确性。实现了精准,多样,新颖的个性化新闻推荐。
附图说明
图1是本发明步骤流程图;
图2是本发明推荐步骤的流程图。
具体实施方式
下面结合附图和具体实施方式,对本发明作进一步说明。
实施例1:如图1-2所示,一种基于rss(简易信息聚合)订阅的新闻推荐方法,首先,通过用户的rss订阅信息,建立用户订阅信息数据库;其次,通过个人用户的rssfeed订阅下采集的新闻信息构建反映用户兴趣偏好的特征向量;然后,结合个人用户的订阅行为和浏览自主订阅的兴趣度分析,建立个人用户的综合兴趣模型;最后,进行基于内容和协同过滤相结合的主动推荐过程。
具体步骤为:
步骤1:通过用户的rss订阅,建立用户订阅信息数据库:根据订阅信息,栏目,栏目网站,内容,标题,url链接,变更时间,变更类型,正文条目,订阅时间,建立用户订阅信息数据库。
步骤2:通过个人用户的rssfeed订阅下采集的新闻信息构建反映用户兴趣偏好的特征向量:提供订阅机制的网站设置有rssfeed接口,rss文件中包括步骤1中数据库的所有内容。当页面更新时,接口模块自动生成rssfeed文件,定期扫描各网站的rssfeed文件,并根据解析出来的url链接网页内容聚合后发送给用户,用户可以通过rss阅读器进行订阅新闻信息的浏览。首先抽取用户订阅的rssfeed列表,获取每个rssfeed的类别信息,构建用户订阅的兴趣偏好特征向量集uv。取一段时间内所有订阅类(m个)中用户停留时间大于时间阈值t的n个类,则用户对feed(i)类订阅兴趣度可以表示为:
feed(i)表示个人用户订阅的其中一种新闻的类别。其中sum(feed(i))表示feed(i)类新闻的数量。
步骤3:阅读兴趣分析
步骤3.1:个人用户阅读行为分析:对于使用rss信息源的用户web中的服务器保留了用户访问日志等记录,保存了相关用户访问类别,访问时间和次数等信息,订阅rss的新闻信息说明用户兴趣偏好,抽取用户浏览行为日志,利用聚类,关联分析等方法,获取用户个性化兴趣与喜好。用户对feed(i)类兴趣由用户对它的访问次数与时长,以及浏览feed(i)类别所有feed数量n和没有浏览的数量m比决定,定义用户对feed(i)类的阅读兴趣度为:
其中time(feed(i))为访问feed(i)类中所有新闻的次数之和,tfeed(i)(j)为访问feed(i)类新闻第j次的访问时间。
步骤3.2:潜在阅读兴趣分析:用户的订阅行为是动态变化的,对订阅的某些新闻在一个时间段tp内没有阅读,这些新闻就具有潜在的阅读兴趣,定义ω为feed(i)类中订阅但没有浏览的新闻具有潜在兴趣时间阀值,dnfeed(i)(j)表示从订阅到目前的时间段(订阅了但是没有浏览的feed(i)类),则feed(i)类中没有浏览过的新闻的潜在阅读兴趣为:
其中n为满足阀值ω的feed(i)类中新闻的个数。则用户对feed(i)类的阅读兴趣度为:
fl(feed(i))=i(feed(i))+p(feed(i))
步骤4:个人用户协同推送的新闻阅读行为分析:利用协同过滤推荐算法构建相似兴趣用户群并聚类得到需要推荐的新闻;然后,反馈到用户兴趣模型的构建,实现正反馈;则定义用户阅读协同推荐新闻的兴趣度为:fm(feed(i))
协同过滤推荐算法步骤为:
(1)收集用户偏好:建立一个用户-项目评价矩阵描述用户对项目的评价,用户的判断和偏好表示为一个m*n的用户项目评价矩阵r,m是用户数,n是项目数,r=(rij),元素rij表示用户i对j的评价。
(2)生成“邻居”:计算所有用户对之间的相似度形成“邻居”。
(3)计算并推荐:通过目标用户对邻居项目的评价产生推荐。
步骤5:个人用户综合兴趣模型建立:个人用户综合兴趣模型由个人用户的订阅兴趣爱好特征向量集,个人用户订阅兴趣偏好,个人用户对feed(i)类的阅读兴趣度,个人用户阅读协同推荐新闻的兴趣度四个方面的特征共同组成,其个人用户综合兴趣模型可以表示为:
u={uv,dl(feed(i)),fl(feed(i)),fm(feed(i))}
步骤6:智能推荐:通过步骤5得到的个人综合兴趣模型,在包含所有用户的兴趣模型数据中,通过相似度计算找出和被推荐个人用户综合兴趣模型相似度最大的top—n邻居集合,然后进行排序,进行主动推荐。
以上结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。
- 还没有人留言评论。精彩留言会获得点赞!