一种基于字典的位片索引压缩方法与流程
本发明属于搜索引擎中的以bitfunnel为代表的位片索引的压缩技术领域,特别涉及对于位片索引的一种基于字典的压缩方法和部分压缩、文档重排等的优化策略。本发明同样适用于信息检索领域其他类似位图的位片索引结构压缩。
【背景技术】
在如今科技高速发展的时代,互联网已成为人们生活中必不可少的一部分。而搜索引擎也成为最重要的互联网入口。它使用网络爬虫等工具,定期扒取互联网的网页内容,在重新组织、存储后,为用户提供检索服务。现代商用搜索引擎系统主要包括网络服务器、索引服务器、文档服务器三大部分。网络服务器用于接收用户的查询,并将查询提交给索引服务器。索引服务器在接收到查询后,对查询词涉及到的索引进行访问、缓存、求交等操作来得到包含查询词的文档编号,然后对其按查询相关度进行排序并将k个最高分文档(topk)的编号返回网络服务器。接下来网络服务器将文档编号和查询交由文档服务器生成包含查询词的摘要返回给用户。
在现有的搜索引擎系统中,索引的压缩解压求交是最为重要的部分之一,直接影响着查询效率和用户体验。对索引进行压缩不仅可以节约存储空间,减少存储设备的开销,在查询过程中由于同等大小文件包含更多的压缩信息,所以索引压缩还可增加磁盘到内存的吞吐率以及增加cache命中率,从而提升查询效率。索引压缩方案有两个主要的评价指标,一方面是压缩率,直接体现压缩效果;另一方面是解压时间,关乎查询效率。搜索引擎会根据实际需求选择合适的压缩方案平衡压缩率和解压时间。
2017年微软提出了一种新的索引位片结构——bitfunnel。其索引是一种基于bloomfilter的类似于位图的位片索引结构。其中每一列代表一篇文档,每一行代表一个或多个词在文档上的映射,词出现在文档中置1,否则置0。由于其应用了bloomfilter,查询处理可能得到真实解之外的解——误称(falsepositive)。由于其采用按位运算替代传统倒排索引的比较判断,减少了分支预测失败的可能性,所以有着很高的查询效率,在未来应用空间巨大。具体的索引结构如图2所示。然而,类似于位图的结构导致存储开销相比于倒排索引大很多。
针对上述应用场景,目前存在两种解决方案——算术编码和位图压缩。现有的针对倒排索引的算术编码压缩方案更偏重于整数压缩,希望被压缩的序列单调或者数值很小,所以不适用于bitfunnel索引结构。而传统的针对位图的压缩方法主要采用run-length编码,这需要数据中有大规模连续0或连续1,而bitfunnel结构也难以保证满足这一条件。
技术实现要素:
为解决上述问题,区别于传统的利用run-length的压缩方法,本发明提出了一种基于字典的位片索引压缩方法,无需较多连续的0/1序列即可达到较好的压缩效果,更适合bitfunnel索引。具体的将bitfunnel索引中重复度较高的块用更少比特位的编号替代从而实现压缩的目的,字典保存重复块到编号的映射。
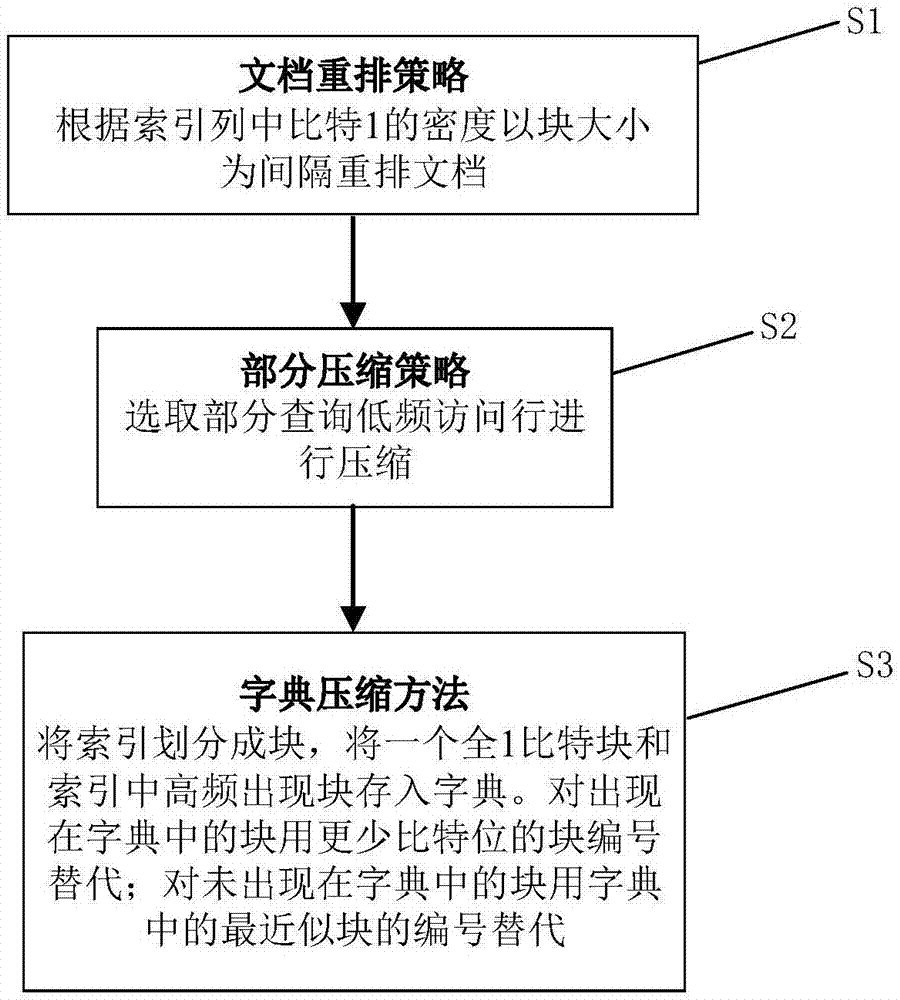
本发明提供的基于字典的位片索引压缩方法(和对压缩的优化策略),参照图1,其主要方法包括:
步骤1(s1),以块大小为间隔根据索引中比特1的列密度重排文档;
步骤2(s2),根据查询数据集特征自定义阈值选定一部分查询访问低频行进行压缩;
步骤3(s3),对s2选定的压缩行进行字典压缩。
s1,一种以块大小为间隔根据索引列中比特1的密度重排文档策略。具体地:
假设索引列数为d,块大小为k个比特;
步骤1.1,统计索引每列中1的密度,将列按密度降序排列;
步骤1.2,初始化一个空索引,将比特1的密度最高的
s2,一种根据查询数据集特征自定义阈值选定一部分查询访问低频行进行压缩的部分压缩策略。具体地:
步骤2.1,自定义查询过程中高频访问行访问频率的阈值α∈[0,1]。
步骤2.2,将矩阵中行按查询访问频率从高到低排序,选定最高频访问的最少q行为高频访问行,保证
步骤2.3,建立行压缩标志位文件,判断每一行是否为低频访问行,也就是需要压缩行。
s3,对s2选定的压缩行进行字典压缩,具体地:
步骤3.1,将重排后bitfunnel位片索引以行为单位划分成块,建立字典保存一个全1块高频出现在s2中选定的压缩行的块,记录高频块和块编号的映射关系;
步骤3.2,遍历索引,对出现在字典中的块,用更少比特的块编号替代;对未出现在字典中的块,用字典中最近似块的编号替代,这样虽然会导致查询请求误称但保证不丢解。
为方便描述,我们假设块大小k个比特,块编号大小b个比特且b<k。
在进行完步骤s1,s2,后,对选定的需要压缩行,将每行都划分为对齐的k比特定长块,以此为单位挖掘重复块。从第一行开始,逐个扫描k比特块,查找重复块并记录其出现频率,直至处理完最后一行。对发掘出的重复块按频率降序排列。将出现频率最高的2b-1种块和一个全1块存入字典。再次遍历矩阵。
a.如果某一块在字典中存在,用b比特的块编号代替。
b.如果块x在字典中不存在,在字典中寻找包含它(xandy=x)且1的个数最少的最近似块y(由于字典中保存了全1块,所以总能找到这样的y),用y的编号代替x。
基于字典的压缩方法利用了矩阵稀疏且1出现不均匀的特性。由于整体1的密度较低,高密度1的块出现较少,导致重复块比例升高,近似块差距不大,这些特征有利于本发明基于字典的压缩不会大幅度增大误称率。
本发明的优点和有益效果:
通过文档重排增加了bitfunnel索引的块重复度,通过部分压缩将压缩导致的误称率控制在10%左右,最后利用基于字典的压缩对位片索引进行压缩,提高bitfunnel索引的压缩效果。本发明能够广泛适用于搜索引擎性能优化和索引压缩领域。
【附图说明】
图1是本发明的基于字典的位片索引压缩方法流程图;
图2是bitfunnel索引结构示意图;
图3是以块大小为间隔根据索引列中比特1的密度重排文档过程及结果示例图;
图4是字典压缩过程及结果示例图;
【具体实施方式】
为便于理解本发明的上述目的、特征和优点,下面结合附图和具体实施方式对本发明作进一步的详细说明。
实施例1文档重排
由于bitfunnel的映射矩阵由哈希函数(bloomfilter)和文档内容决定,我们可以通过调节词到行的映射和矩阵行数来改变矩阵中1的密度。虽然0/1矩阵重复度很高,然而由于文档分布的集聚性等特征导致矩阵中1的分布很不均匀(bitfunnel只保证全局1的密度),因此我们提出了一种基于密度的文档重排方案,增大矩阵中块之间的相似性,从而提升压缩效果。显然,块重复度越高,对于字典压缩越有利。具体表现在两方面:每一块在字典中出现的可能性变大;不在字典中块压缩多置1的比例变小,从而大大降低了字典压缩导致的误称率。
为方便描述,我们假设映射矩阵共d列,每块含有k个比特。图3以d=16,k=4为例描述了文档重排的过程,首先统计每列1的密度并按从大至小的顺序排列,为了方便展示,这里每d/k个比特一组用不同背景标记。首先将密度最高的o、j、m和g列重排至第1,5,9,13列(斜线阴影),然后依此类推,最后将密度最低的k、l、p和f文档重排至第4,8,12,16列(无阴影)。这样按列密度进行重排后,我们发现每k列密度均从第1列到第k列递减,块之间重复度增大,更利于字典压缩。
实施例2部分压缩
通过对实际数据集进行分析我们发现,在查询过程中,只有少部分行被高频访问,大部分行访问频率较低。而对于高频访问行进行压缩会导致较高的误称率,而对于低频访问行的压缩对误称率影响较小。基于这个发现,我们考虑一种部分压缩的方案,即压缩低频访问行,而对于误称率影响较大的高频访问行不进行压缩。
将矩阵中行按频率从高到低排序,选定最高频访问的最小q行为高频访问行,保证
为方便描述,我们假设矩阵共100行,每一行的访问频率和行号相等,即f(i)=i。首先我们将矩阵中行按频率从高到低排序,每行的访问频率依次递减,具体为100,99,98,…,1。其中n=(100+99+98+…+1)=5050。如果我们自定义阈值为α=0.9,那么我们选定最高频访问的最少69行(行号100至32)保证
对于行的选取,我们将整个查询数据集随机分成相等的两份,一份作为训练集,由训练集得到的行访问频率f(i)和阈值α决定每一行是否被压缩。另一半查询集作为测试集,测试查询时间、误称率等性能。可见,我们不是简单地选取固定的参数进行压缩,而是利用同一来源的查询请求具有相似性这一特点,从查询历史中学习出适合的参数,以期由此得到的压缩结果在未来的查询请求上获得更好的性能。具体自定义阈值α的取值和索引的原始误称率和块重复度有关。
实施例3字典压缩
为方便描述,我们假设块大小k个比特,块编号大小b个比特且b<k。
图4以k=4,b=2为例描述了字典压缩的过程及压缩后的结果。首先将原始字典中每块的出现频率记录下来,选取频率最高的22-1=3个块和一个全1块生成字典(图4左下);图4的第四行第一块1100,因为其在字典中出现,所以利用编号10替代;第一行的第二块0010(虚线框内),由于其在字典中未出现,且第三个比特位置置1。字典中块1111、1110、1010第三个比特位均为1,均包含块0010满足相似条件,我们选择其中1个数最少的1010。这一策略保证查询请求不会丢解,且可能增加的误称尽量少。图4中阴影部分表示块不在字典中,用近似块代替的情况。压缩后的数据分为两部分:字典、压缩的索引。
假设矩阵m行d列,采用上述字典压缩方式的压缩率为:
这里字典大小为k*2b,压缩后映射矩阵大小为mdb/k,实际中字典较小可以忽略,所以压缩率近似等于
在求交过程中,我们只需简单地将b个比特的块编号作为索引从字典中提取出原始块定义进行与运算即可。由于字典规模一般较小且在求交(解压)过程中频繁访问,大部分字典数据会驻留在cpu的cache中,减少访存开销,提高求交性能。
实施例4实验结果
我们在trecgov2数据集上测试本发明基于字典的位片索引压缩方法的效果。其中pri,opt为bitfunnel的两种策略privatesharedrank0和optimal下生成的索引。实验中的块大小设置为32比特,块编号大小设置为16比特。
对所用倒排索引数据集做如下说明:
(1)我们使用trecgov2为2004年从.gov域名抓取下来的数据集,共包含2500多万个网页作为生成索引的文档集合,其中所有文档内容均已剔除html标签,提取标题和正文部分后建立索引;
(2)我们使用millionset作为查询集合1,包含2007,2008,and2009trecmillionquerytrack共6万条查询;
(3)我们使用terabyteset作为查询集合2,包含2006trecterabytetrack共10万条查询。
表1
表1描述了基于字典的位片索引压缩方法的压缩率。根据表1我们可知,pri方式下millionset、terabyteset两种查询集对应的总体压缩率分别为0.73、0.72;opt方式下millionset,terabyteset两种查询集对应的总体压缩率分别为0.71、0.70。millionset稍好于terabyteset,但区别很小只有0.02-0.01,说明查询集对压缩率影响不大,我们的部分压缩方式对不同的查询数据集具有通用性。
我们还尝试将每32个比特看作一个无符号整数(unsignedint类型),利用算术编码和位图压缩方法进行压缩。我们发现,利用pfor、vbyte、ewah进行压缩,文件大小分别只减少了-1%、11.3%、4.35%。这是由于bitfunnel矩阵中1的分布无规律且不均匀,因此整数序列中的数值都很大,不利于做d-gap等数值转换,从而导致算术编码压缩效果较差。而针对位图的压缩方案由于其利用run-length需要较多的连续0,连续1,bitfunnel索引构建完全依赖于文档特征所以也无法满足条件。综上,传统的压缩算法对bitfunnel索引压缩效果较差,而本发明采用的基于字典的压缩方案可以有效地提升压缩率。
表2
表2给出了两种策略下每条查询平均求交时间和误称率。由表2我们可以看出利用pri策略生成矩阵在millionset和terabyteset数据集上解压使得求交时间分别增加了21%、16%。利用opt策略生成矩阵在millionset和terabyteset数据集上解压使得求交时间分别增加了48%、37%。这部分求交时间的增加一方面是由于采用部分压缩使得一部分高频访问行不进行压缩,求交时需判断每一行是否被压缩,另一方面是由于压缩导致的访问字典的访存延迟。同时我们也可发现,字典压缩使得误称率增加了约7到10个百分点。
在求交方面,由于索引需要解压,压缩的索引在查询上需多花费16%-48%的时间,然而由于bitfunnel本身特性,只需简单按位运算即可得到相关文档,所以本身的求交时间很少,占整个查询时间的比例很小(完整查询包括求交、计算topk文档、生成摘要等过程),所以5毫秒左右的求交时间对用户影响不大。另外压缩将会引入额外的误称率,这部分误称率我们利用阈值α控制在一定的范围7到10个百分点内。由于搜索引擎会对求交得到的文档进行相关性排序,选择分数最高的前k篇返回,压缩导致的误称文档由于分数较低可以很快被筛选掉。由此,我们预测在实际搜索引擎系统中,这部分误称文档不会造成较大影响。
综合压缩率、求交时间和误称率三方面考虑,本发明提出的压缩方案对于压缩bitfunnel位片索引有较好效果。
以上对本发明的基于字典的压缩方法进行了详细介绍,本文中应用了具体个例对本发明的原理及实施方式进行阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!