基于多区域特征提取和融合的行人再识别方法与流程
本发明属于计算机视觉行人再识别技术领域,尤其是一种基于多区域特征提取和融合的行人再识别方法。
背景技术
随着视频采集技术不断进步以及大规模数据存储技术快速发展,使得大量的监控摄像系统应用在公共场所成为可能。对海量监控视频中的行人进行识别和处理呈现快速发展的趋势,仅依靠人眼识别监控画面中的行人身份显然十分低效,行人再识别技术的任务便是依靠计算机视觉技术解决不重叠监控视野中行人身份匹配的问题。
传统的解决方法主要有两大类:一是特征提取,即根据监控视频里的行人提取鲁棒性的特征表示;二是距离度量,即学习一个更具判别力的特征度量方法,使得同一行人的特征间距离更近。近年来,随着深度学习技术的兴起,卷积神经网络被广泛运用在行人检测、目标跟踪等视觉任务中,并表现出了出色的性能,因此,基于深度学习的行人再识别也成为了当前的一大趋势。
然而,现有的卷积神经网络大多提取整张图片的特征,没有充分利用图片的局部特征,这些局部特征对于不同视角下行人的姿势变化具有较好的鲁棒性,对于区分不同行人更加有效,因此,现有的行人再识别方法整体匹配准确率不高。
技术实现要素:
本发明的目的在于克服现有技术的不足,提出一种设计合理且匹配准确率高的基于多区域特征提取和融合的行人再识别方法。
本发明解决其技术问题是采取以下技术方案实现的:
一种基于多区域特征提取和融合的行人再识别方法,包括以下步骤:
步骤1、利用残差网络提取全局特征,并在训练阶段增加一个用于全局特征提取和优化的行人身份分类模块;
步骤2、构造用于局部特征提取的多区域特征提取子网络,并将各局部特征进行加权融合;
步骤3、设置包括分类模块损失和特征融合模块损失的损失函数;
步骤4、对网络进行训练,得到模型提取查询集和测试集的特征向量;
步骤5、在度量阶段,利用交叉近邻方法对特征距离进行重新度量。
进一步,所述步骤1的分类模块利用1×1卷积实现特征映射,所有神经元共享权重参数,将输出通道数设置为行人类别数,通过训练得到每个行人身份对应的特征图;所述分类模块的结构为:
卷积层(1×1×n)→全局平均池化层→softmax损失层其中,n为训练集中行人类别数。
进一步,所述步骤2的具体实现方法为:
⑴假设残差网络的输出特征图为m∈rk×h×w,其中k洀愀渀倀匀为特征通道数,h和w分别为特征图的高度和宽度,对m进行两项操作分别得到全局和局部特征表示:一是对m进行全局平均池化,得到全局特征fg∈r1024×1×1;二是将m水平分割为不重叠的4个条块,分别对应行人的头部、上身、下身、双脚,每个分块进行全局平均池化,得到局部特征表示:
⑵设置一个特征加权层,对各局部特征的权重参数进行学习,并通过反向传播算法进行优化,其计算过程为:
其中⊙表示元素间操作,w和b分别为权重和偏置矩阵,是特征加权层的参数;
⑶将加权的局部特征与全局特征相连即可得到最终的行人特征:
其中[·]表示特征融合操作,f∈r5120×1×1表示多区域特征向量。
进一步,所述步骤3的具体实现方法为:
⑴softmax损失将训练集的每个行人身份视为一类,计算输入样本x属于类别n的概率p(n|x):
其中n=[1,2,...n],n表示训练集中行人身份数,wi和bi分别为卷积层的权重和偏置参数;
⑵根据输入样本的标签y计算最终softmax损失:
其中q(n|x)表示预测标签n与真实标签y的关系,即:
⑶将softmax损失应用于分类模块和特征融合模块,则系统总体的损失函数为:l洀lc+lw,其中lc和lw分别对应于分类模块和特征融合模块的softmax损失。
进一步,所述步骤4对网络进行训练时,输入图像首先被统一为224×224×3像素尺寸,然后以批量大小为16输入网络进行训练,迭代50000次。
进一步,所述步骤5的具体实现方法为:根据步骤4训练得到的模型提取查询集和测试集的特征向量,设查询样本为p,测试集为g={gi|i=1,2,...,i},首先计算它们的马氏距离d(p,gi),得到p的k-最近邻,记为n(p,k),同理gi的k-最近邻记为n(gi,k),则p的交叉近邻定义为:c(p,k)={gi|gi∈n(p,k)∧p∈n(gi,k)},采用上述相同方法得到gi的交叉近邻c(gi,k);得到如下最终距离:
d(p,gi)=λd(p,gi)+(1-λ)dj(p,gi)
其中λ为平衡参数,设置λ=0.3。
本发明的优点和积极效果是:
本发明设计合理,其采用多区域特征提取和融合的模型,并在特征融合阶段对各局部特征的权重进行学习,提取到更具鲁棒性和判别力的特征向量,并且在距离度量阶段,采用“交叉近邻”产生一种新的距离度量,进而与原始距离相权衡产生了最终的特征度量,优化了距离度量方法,获得了很好的行人再识别结果。本发明在公开的数据集上进行了测试,本发明优于目前其他的行人再识别算法,使得系统整体匹配准确率大大提升。
附图说明
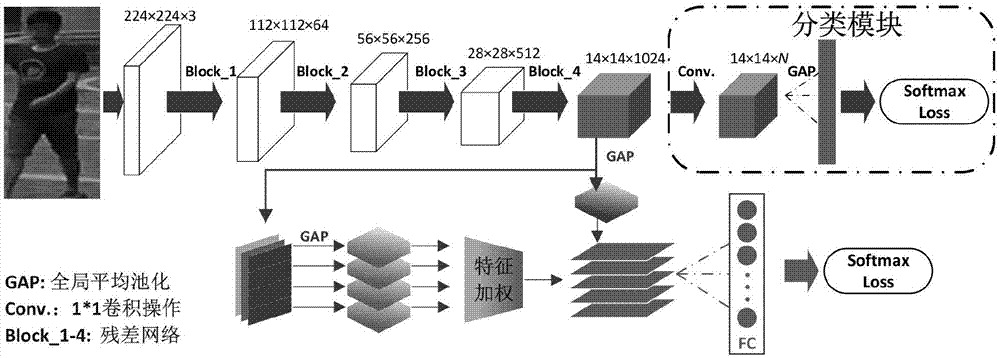
图1是本发明的行人再识别方法原理图;
图2a至图2d是本发明采用交叉近邻度量方法对整体匹配准确率的影响。
具体实施方式
以下结合附图对本发明实施例做进一步详述。
一种基于多区域特征提取和融合的行人再识别方法,包括以下步骤:
步骤1、利用残差网络提取全局特征,在训练阶段增加一个行人身份分类模块,用于全局特征的提取和优化。
传统的卷积神经网络利用全连接层将卷积特征映射到一个特征向量,其维度等于行人类别数,由于全连接层的所有节点都与前一层的所有节点相连,参数数量较大。如图1所示,本发明中的分类模块(classificationstructure)利用1×1卷积实现特征映射,所有神经元共享权重参数,减小计算量。将输出通道数设置为行人类别数,通过训练可以得到每个行人身份对应的特征图,从而实现行人身份分类。该分类模块的结构为:
卷积层(1×1×n)→全局平均池化层→softmax损失层
其中,n为训练集中行人类别数。
步骤2、构造多区域特征提取子网络,用于局部特征提取,并将各局部特征进行加权融合。
本步骤的具体实施方法如下:
假设残差网络的输出特征图为m∈rk×h×w,其中k洀愀渀倀匀为特征通道数,h和w分别为特征图的高度和宽度,下面对m进行两项操作分别得到全局和局部特征表示:一是对m进行全局平均池化,得到全局特征fg∈r1024×1×1;二是将m水平分割为不重叠的4个条块,分别对应行人的头部、上身、下身、双脚,每个分块进行全局平均池化,即可得到局部特征表示:
考虑到各局部信息具有不同的重要性,本发明设置了一个特征加权层,对各局部特征的权重参数进行学习,并通过反向传播算法进行优化,计算过程为:
其中⊙表示元素间操作,w和b分别为权重和偏置矩阵,是特征加权层的参数。
得到加权的局部特征后,与全局特征相连即可得到最终的行人特征:
其中[·]表示特征融合操作,f∈r5120×1×1表示多区域特征向量。
步骤3、设置损失函数,该损失函数包括两部分:分类模块损失和特征融合模块损失。
本步骤的具体实施方法如下:
将行人再识别问题归于多分类问题,使用softmax损失函数对网络进行训练。softmax损失将训练集的每个行人身份视为一类,首先计算输入样本x属于类别n的概率p(n|x):
其中n=[1,2,...n],n表示训练集中行人身份数,wi和bi分别为卷积层的权重和偏置参数。
得到每个类别的概率后,根据输入样本的标签y计算最终softmax损失:
其中q(n|x)表示预测标签n与真实标签y的关系,即:
将softmax损失应用于分类模块和特征融合模块,则系统总体的损失函数为:
l=lc+lw
其中lc和lw分别对应于分类模块和特征融合模块的softmax损失。
步骤4、对网络进行训练,得到模型提取查询集和测试集的特征向量。
本步骤的具体实施方法如下:
输入图像首先被统一为224×224×3像素尺寸,然后以批量大小为16输入网络进行训练,迭代50000次。
步骤5、在度量阶段,利用交叉近邻方法对特征距离进行重新度量,该度量结合了马氏距离和交叉近邻距离。
本步骤的具体实施方法如下:
使用步骤4训练得到的模型提取查询集和测试集的特征向量,设查询样本为p,测试集为g={gi|i=1,2,...,i},首先计算它们的马氏距离d(p,gi),得到p的k-最近邻,记为n(p,k),同理gi的k-最近邻记为n(gi,k),则p的交叉近邻定义为:c(p,k)={gi|gi∈n(p,k)∧p∈n(gi,k)},同理可得到gi的交叉近邻c(gi,k)。考虑到两个样本相似度越大,它们的交叉近邻集合的交集越大,因此引入了一种新的距离度量方式:
其中|·|表示集合中元素个数。最终距离表示为:
d(p,gi)=λd(p,gi)+(1-λ)dj(p,gi)
其中λ为平衡参数,通过多次实验验证,我们设置λ=0.3。
下面按照本发明方法进行实验,说明本发明的效果。
测试环境:ubuntu14.04、matlabr2016a
测试数据:用于行人再识别的公共数据集market1501、cuhk03(labeled和detected)和cuhk01。
测试指标:
本发明使用了两种评价指标:cmc(cumulatedmatchingcharacteristics)曲线和map(meanaverageprecision)。cmc曲线是一种top-k击中概率,该指标表示相似度排名前k的样本中,正确匹配的概率累积和。曲线越接近100%性能越好;map是对每个类别上的准确率进行平均得到的,适用于多摄像头的情况,如本发明实验中的market1501数据集来自6个不同摄像头,其评价指标有cmc和map。
试验结果如下:
表1分类模块和特征加权模块对系统性能的影响
上表中,no_cs:去掉分类模块;no_fws:去掉特征加权层;gpn:本发明提出的模型。实验结果表明:分类模块和特征加权层的设计,能够显著提高系统性能。
实验采用了三种距离度量方法:欧式距离(euclidean)、xqda和kissme,以此三种方法计算原始距离,分别运用“交叉近邻”进行重排序(re-ranking),结果表明重排序后识别准确率得到提升,证明了重排序方法的有效性。表2、表3和表4是本发明算法与现有算法的性能比较。
表2
表3
表4
需要强调的是,本发明所述的实施例是说明性的,而不是限定性的,因此本发明包括并不限于具体实施方式中所述的实施例,凡是由本领域技术人员根据本发明的技术方案得出的其他实施方式,同样属于本发明保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!