一种基于Stacking集成学习的医疗文本去隐私方法和系统与流程
本发明涉及一种基于stacking集成学习的医疗文本去隐私方法和系统,属于计算机医疗软件技术领域。
背景技术
去除文本中与当事人有关的隐私信息是文本数据向社会公开前的一个重要步骤。例如,法律部门在向社会公开案件信息时,要去除涉案人的隐私信息;nlp研究机构在向社会公开研究语料库时,要去除其中涉及到个人隐私的信息。
在医疗领域,美国于1996年通过了hipaa(healthinsuranceportabilityandaccountabilityact)法案,这项法案定义了18类有关病人以及他的友人,同事和家庭成员的相关隐私信息,规定这些隐私信息在向社会公开时必须从病历中删除。医疗文本去隐私问题可以被定义为一种文本标记问题。研究者需要从叙事性医疗文本中正确并完整地找出受保护的隐私信息(protectedhealthinformation,phi),并确定这些信息所属的phi类别,然后将phi实体和对应的phi类别输出。
技术实现要素:
本发明为了解决现有技术中医疗文本需要去除隐私信息这一问题,提出了一种基于stacking集成学习的医疗文本去隐私方法和系统,所述方法和系统需要从叙事性医疗文本中正确并完整地找出受保护的隐私信息(protectedhealthinformation,phi),并确定这些信息所属的phi类别,然后将phi实体和对应的phi类别输出。
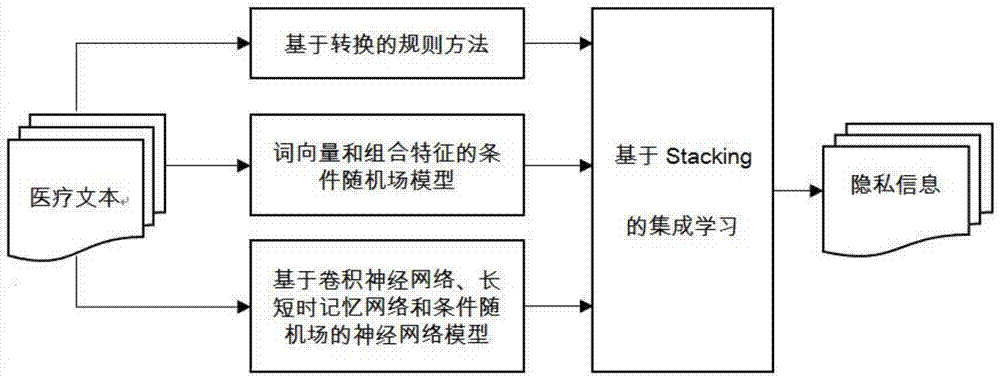
一种基于stacking集成学习的医疗文本去隐私系统,所采取的技术方案如下,所述系统包括:
用于对输入文本进行切分获得处理单元token的文本切分模块;
用于得到每个处理单元token的相关特征的特征提取模块;
用于在训练数据上建立并获得基于转换的规则自动获取的基于规则的phi标记模块;
用于在训练数据上建立并获得基于条件随机场的phi标记模块;
用于在训练数据上建立并获得基于神经网络的phi标记模块;
用于利用所述基于phi标记模块、基于条件随机场的phi标记模块和基于神经网络的phi标记模块对每个处理单元token进行标记,识别每个处理单元token中的phi实体的phi实体识别模块;
用于对不同模型识别后获得的phi实体进行stacking集成学习的stacking集成学习模块。
进一步地,所述基于规则的phi标记模块包括:
用于输入文本,文本中每个token的正确标注、转换规则模板和初始标注器的输入模块;
用于根据所述初始标注器对文本进行初始标注的初始标注模块;
用于识别每个错误标注的token的识别模块;
用于针对所有错误标注的token,根据转换规则模板逐一生成候选规则的候选规则生成模块;
用于对全部候选规则进行性能评分,计算其削减标注错误的数量的计算模块;
用于如果存在削减标注错误数量大于0的候选规则,在削减错误数量最多的候选规则中加入初试标注器的初试标注器加入模块。
进一步地,所述相关特征包括:
长度:当前token所包含的字符数量;
大小写模式:当前token的字母大小写规律,包括:一个大写字母后面跟小写字母、全部都是小写字母和全部都是数字的情况;
词性:当前token的词性
实体信息:实体类型;
是否属于某类地点词:包括国家、州、城市和邮编四类词;
前缀:去除词干后的该词的前缀;
后缀:去除词干后的该词的后缀;
该词所属文本区域:医疗记录文本根据关键词,共划分为29个区域;所述关键词包括recorddate和reasonforvisit等29个关键词;
处理单元token的划分规则为:只将连续的字母或连续的数字划归为同一个token,连续字母中出现的大写字母会被切分为多个token。
词语向量表示:token词向量表示。
进一步地,所述基于条件随机场学习器模块中的特征函数为:
其中,skl(yi,x,i)表示状态特征函数,ya和xb分别表示xi和yi的某个取值,
进一步地,,所述基于神经网络学习器模块包括:
用于使用卷积神经网(convolutionneuralnetwork,cnn)提取字符级向量的字符级向量提取模块;
用于将相关特征与处理单元token中每个字符额向量和处理单元token中每个词的向量连接起来一起输入至bilstm层的输入模块;
用于利用条件随机场获得标记结果的标记结果获得模块。
进一步地,所述stacking集成学习模块包括:
用于判断所述phi实体是否正确的基于二分类支持向量机(supportingvectormachine,svm)的实体判断模块;
用于输出正确的phi实体的实体输出模块;所述正确的phi实体即为所述医疗文本去隐私系统的最终输出结果。
一种基于stacking集成学习的医疗文本去隐私方法,所采取的技术方案如下,所述方法包括:
用于对输入文本进行切分获得处理单元token的文本切分步骤;
用于得到每个处理单元token的相关特征的特征提取步骤;
用于在训练数据上建立并获得基于转换的规则自动获取模型的基于转换规则自动获取步骤;
用于在训练数据上建立并获得基于条件随机场的学习器模型的基于条件随机场学习器步骤;
用于在训练数据上建立并获得基于神经网络的学习器模型基于神经网络学习器步骤;
用于利用所述基于转换的规则自动获取模型、基于条件随机场的学习器模型和基于神经网络的学习器模型对每个处理单元token进行bio标记,从而识别每个处理单元token中的phi实体的phi实体识别步骤;
用于对不同模型识别后获得的phi实体进行stacking集成学习的stacking集成学习步骤。
所述基于规则的phi标记步骤包括:
用于输入文本,文本中每个token的正确标注、转换规则模板和初始标注器的输入步骤;
用于根据所述初始标注器对文本进行初始标注的初始标注步骤;
用于识别每个错误标注的token的识别步骤;
用于针对所有错误标注的token,根据转换规则模板逐一生成候选规则的候选规则生成步骤;
用于对全部候选规则进行性能评分,计算其削减标注错误的数量的计算步骤;
用于如果存在削减标注错误数量大于0的候选规则,在削减错误数量最多的候选规则中加入初试标注器的初试标注器加入步骤。
进一步地,所述相关特征包括:
长度:当前token所包含的字符数量;
大小写模式:当前token的字母大小写规律,包括:一个大写字母后面跟小写字母、全部都是小写字母和全部都是数字的情况;
词性:当前token的词性
实体信息:实体类型;
是否属于某类地点词:包括国家、州、城市和邮编四类词;
前缀:去除词干后的该词的前缀;
后缀:去除词干后的该词的后缀;
该词所属文本区域:医疗记录文本根据关键词,共划分为29个区域;所述关键词包括recorddate和reasonforvisit等29个关键词;
处理单元token的划分规则为:只将连续的字母或连续的数字划归为同一个token,连续字母中出现的大写字母会被切分为多个token。
词语向量表示:token词向量表示。
进一步地,所述基于条件随机场学习器步骤中的特征函数为:
其中,skl(yi,x,i)表示状态特征函数,ya和xb分别表示xi和yi的某个取值,
进一步地,所述基于神经网络学习器步骤包括:
用于使用cnn提取字符级向量的字符级向量提取步骤;
用于将相关特征与处理单元token中每个字符额向量和处理单元token中每个词的向量连接起来一起输入至bilstm层的输入步骤;
用于利用crf层获得标记结果的标记结果获得步骤。
进一步地,所述stacking集成学习步骤包括:
用于判断所述phi实体是否正确的基于二分类svm的实体判断步骤;
用于输出正确的phi实体的实体输出步骤;所述正确的phi实体即为所述医疗文本去隐私方法的最终输出结果;
其中,所述实体判断模块判断phi实体是采用的phi特征如下:
phi的标记模型;
phi的某一类型的标记次数;
phi的类别;
phi的标记次数;
phi起始位置的被模型一致标记的次数;
phi终止位置的被模型一致标记的次数;
phi起始位置和类型均被模型一致标记的次数;
phi终止位置和类型均被模型一致标记的次数。
本发明有益效果:
本发明提出的一种基于stacking集成学习的医疗文本去隐私方法和系统,具有目前已知最好的隐私文字识别性能,能够最大限度的保护按制度要求所公开的医疗文本中的个人隐私信息。整体系统框架清晰简洁,所用特征容易获得,整体系统运行效率高,所需的开发周期短。
附图说明
图1为本发明所述医疗文本去隐私方法的框架图。
图2为本发明所述基于神经网络学习器模型的结构示意图。
图3为本发明所述stacking集成学习步骤的过程示意图。
具体实施方式
下面结合具体实施例对本发明做进一步说明,但本发明不受实施例的限制。
实施例1:
一种基于stacking集成学习的医疗文本去隐私系统,所采取的技术方案如下,所述系统包括:
用于对输入文本进行切分获得处理单元token的文本切分模块;
用于得到每个处理单元token的相关特征的特征提取模块;
用于在训练数据上建立并获得基于转换的规则自动获取的基于规则的phi标记模块;
用于在训练数据上建立并获得基于条件随机场的phi标记模块;
用于在训练数据上建立并获得基于神经网络的phi标记模块;
用于利用所述基于phi标记模块、基于条件随机场的phi标记模块和基于神经网络的phi标记模块对每个处理单元token进行标记,识别每个处理单元token中的phi实体的phi实体识别模块;
用于对不同模型识别后获得的phi实体进行stacking集成学习的stacking集成学习模块。
其中,所述相关特征包括:
长度:当前token所包含的字符数量;
大小写模式:当前token的字母大小写规律,包括:一个大写字母后面跟小写字母、全部都是小写字母和全部都是数字的情况;
词性:当前token的词性
实体信息:实体类型;
是否属于某类地点词:包括国家、州、城市和邮编四类词;
前缀:去除词干后的该词的前缀;
后缀:去除词干后的该词的后缀;
该词所属文本区域:医疗记录文本根据关键词,共划分为29个区域;所述关键词包括recorddate和reasonforvisit;
词语向量表示:token词向量表示。
其中,所述基于转换规则自动获取模块通过基于转换的自动获取模型能够完全取代人工编写规则,节省了人力编写时间,有效避免耗时费力;并且所述基于转换规则自动获取模块能够有效把词语数据集中所有的规则全部找出,有效提高规则找出过程中的准确性,避免遗漏。所述基于规则的phi标记模块包括:
用于输入文本,文本中每个token的正确标注、转换规则模板和初始标注器的输入模块;
用于根据所述初始标注器对文本进行初始标注的初始标注模块;
用于识别每个错误标注的token的识别模块;
用于针对所有错误标注的token,根据转换规则模板逐一生成候选规则的候选规则生成模块;
用于对全部候选规则进行性能评分,计算其削减标注错误的数量的计算模块;
用于如果存在削减标注错误数量大于0的候选规则,在削减错误数量最多的候选规则中加入初试标注器的初试标注器加入模块。
所述基于转换规则自动获取模块处理过程如下:
步骤1:输入:文本,文本中每个token的正确标注、转换规则模板、初始标注器
步骤2:根据初始标注器,对文本进行初始标注
步骤3:识别每个错误标注的token;
步骤4:对所有错误标注的token,根据转换规则模板,逐一生成候选规则;
步骤5:对全部候选规则进行性能评分,计算其削减标注错误的数量;
步骤6:如果存在削减标注错误数量大于0的候选规则:
步骤7:削减错误数量最多的候选规则,加入初试标注器;
步骤8:否则,结束。
同时,条件随机场学习器是一种判别式无向图模型,在解决命名实体识别问题时经常得到应用。为了使用条件随机场学习器模型,需要定义合适的特征函数。但常规条件下,所述条件随机场学习器模型适用处理的特征都为离散特征,但是词语的向量表示是连续特征,为了充分利用词语的向量表示信息,同时避免避免离散化带来的损失,本实施例对特征函数进行改进优化,具体的,所述基于条件随机场学习器模块中的特征函数为:
其中,skl(yi,x,i)表示状态特征函数,ya和xb分别表示xi和yi的某个取值,
所述基于神经网络学习器模块包括:
用于使用cnn提取字符级向量的字符级向量提取模块;
用于将相关特征与处理单元token中每个字符额向量和处理单元token中每个词的向量连接起来一起输入至bilstm层的输入模块;
用于利用crf层获得标记结果的标记结果获得模块。
本实施例所述基于神经网络学习器模块使用cnn提取字符级向量表示,将人工特征与字符向量和词向量连接起来一起输入到bilstm层,然后使用crf层得到标记结果。
完整的神经网络学习器模块的结构如图2所示,其中,yt表示序列中第t个token的标记结果,c是token中每个字符的向量表示,n代表token的最大长度,对于长度小于n的token,会进行添0操作补充为n。c通过一个卷积层和一个最大池化层得到字符特征fc。ft表示序列中第t个token的特征,由cnn得到的字符特征fc,t、人工特征fk,t和token的向量表示tt三个向量连接得到,然后输入到lstm中。lstm接受特征序列f=(f1,f2,...,fm)t和词向量序列t=(t1,t2,...,tm)t作为输入,输出编码了上下文信息的向量h=(h1,h2,...,hm)t。
h实际上还是token的一种向量表示,为了得到标记序列y=(y1,y2,...,ym),使用了一个crf层。对于命名实体识别问题,当使用bio标记法时,输出序列中的各个标记并不是互相独立的,比如o后不可能立刻接i。如果简单使用softmax获取分类结果,模型就很难处理这样的信息。而crf通过引入转移特征函数,对不同标签之间的转移进行了建模,可以大大提升y的准确度。具体来讲,对于给定的输入序列x,标记序列y的条件概率定义如下:
其中,z是归一化因子,a表示转移矩阵,ai,j表示从状态i转换为状态j的得分;p是标记矩阵,pi,j表示第i个token被标记为j的得分,由lstm的输出h经过一个softmax分类器得到。
本实施例提出的stacking集成学习模块对上述三个学习器模型的输出结果进行集成达到模型融合,提高性能的目的。如图3所示,所述stacking集成学习模块包括:
用于判断所述phi实体是否正确的基于二分类svm的实体判断模块;
用于输出正确的phi实体的实体输出模块;所述正确的phi实体即为所述医疗文本去隐私系统的最终输出结果。
所述stacking集成学习模块的代码如表2所示:
表2
其中,用于训练元学习器h的次级训练集d′是使用初级学习器ht标记得到的,而ht同样是使用这一训练集训练得到的,这样的方法很容易因ht过拟合导致h不能正确度量不同个体学习器的泛化能力,从而使最终结果下降。为了防止这一损失,在上述过程中使用交叉验证的方法对训练集进行标记。这一过程如图3所示,其中白色矩形表示用来训练的样本,灰色矩形表示用于标记的样本。
在实体判断模块中,所述实体判断模块判断phi实体是采用的phi特征如下:
phi的标记模型;
phi的某一类型的标记次数;
phi的类别;
phi的标记次数(忽略类型);
phi起始位置的被模型一致标记的次数;
phi终止位置的被模型一致标记的次数;
phi起始位置和类型均被模型一致标记的次数;
phi终止位置和类型均被模型一致标记的次数。
实施例2
一种基于stacking集成学习的医疗文本去隐私方法,所采取的技术方案如下,所述方法包括:
用于对输入文本进行切分获得处理单元token的文本切分步骤;
用于得到每个处理单元token的相关特征的特征提取步骤;
用于在训练数据上建立并获得基于转换的规则自动获取模型的基于转换规则自动获取步骤;
用于在训练数据上建立并获得基于条件随机场的学习器模型的基于条件随机场学习器步骤;
用于在训练数据上建立并获得基于神经网络的学习器模型基于神经网络学习器步骤;
用于利用所述基于转换的规则自动获取模型、基于条件随机场的学习器模型和基于神经网络的学习器模型对每个处理单元token进行标记,从而识别每个处理单元token中的phi实体的phi实体识别步骤;
用于对不同模型识别后获得的phi实体进行stacking集成学习的stacking集成学习步骤。
所述相关特征包括:
长度:当前token所包含的字符数量;
大小写模式:当前token的字母大小写规律,包括:一个大写字母后面跟小写字母、全部都是小写字母和全部都是数字的情况;
词性:当前token的词性
实体信息:实体类型;
是否属于某类地点词:包括国家、州、城市和邮编四类词;
前缀:去除词干后的该词的前缀;
后缀:去除词干后的该词的后缀;
该词所属文本区域:医疗记录文本根据关键词,共划分为29个区域;所述关键词包括recorddate和reasonforvisit;
词语向量表示:token词向量表示。
其中,所述基于条件随机场学习器步骤中的特征函数为:
其中,skl(yi,x,i)表示状态特征函数,ya和xb分别表示xi和yi的某个取值,
所述基于规则的phi标记步骤包括:
用于输入文本,文本中每个token的正确标注、转换规则模板和初始标注器的输入步骤;
用于根据所述初始标注器对文本进行初始标注的初始标注步骤;
用于识别每个错误标注的token的识别步骤;
用于针对所有错误标注的token,根据转换规则模板逐一生成候选规则的候选规则生成步骤;
用于对全部候选规则进行性能评分,计算其削减标注错误的数量的计算步骤;
用于如果存在削减标注错误数量大于0的候选规则,在削减错误数量最多的候选规则中加入初试标注器的初试标注器加入步骤。
所述基于神经网络学习器步骤包括:
用于使用cnn提取字符级向量的字符级向量提取步骤;
用于将相关特征与处理单元token中每个字符额向量和处理单元token中每个词的向量连接起来一起输入至bilstm层的输入步骤;
用于利用crf层获得标记结果的标记结果获得步骤。
所述stacking集成学习步骤包括:
用于判断所述phi实体是否正确的基于二分类svm的实体判断步骤;
用于输出正确的phi实体的实体输出步骤;所述正确的phi实体即为所述医疗文本去隐私方法的最终输出结果。
所述实体判断模块判断phi实体是采用的phi特征如下:
phi的标记模型;
phi的某一类型的标记次数;
phi的类别;
phi的标记次数(忽略类型);
phi起始位置的被模型一致标记的次数;
phi终止位置的被模型一致标记的次数;
phi起始位置和类型均被模型一致标记的次数;
phi终止位置和类型均被模型一致标记的次数。
对本发明所述一种基于stacking集成学习的医疗文本去隐私方法和系统的实验结果如下:
表5对本文提出的系统和现有技术中的最好系统进行了对比。
表5各标记器性能对比
虽然本发明已以较佳的实施例公开如上,但其并非用以限定本发明,任何熟悉此技术的人,在不脱离本发明的精神和范围内,都可以做各种改动和修饰,因此本发明的保护范围应该以权利要求书所界定的为准。
- 还没有人留言评论。精彩留言会获得点赞!