一种基于PET图形成像的系统及方法与流程
本发明属于图形成像技术领域,特别是涉及一种基于pet图形成像的系统及方法。
背景技术
一种核成像技术,正电子发射断层扫描(pet)使人体的代谢过程可视化,并越来越多地用于诊所疾病诊断和干预[。通过检测从注入人体的放射性示踪剂间接发射的伽马射线对,pet系统使用软件绘制三角测量发射源,从而重建人体内示踪剂浓度的3dpet图像。通常需要使用全剂量示踪剂来获得诊断质量的pet图像。但是,放射性照射不可避免地引起对潜在健康危害的担忧。对于经历多次pet扫描作为其治疗的一部分的患者积累了风险。为了解决辐射问题,一些研究人员试图在pet扫描期间减少示踪剂剂量。然而,由于pet成像是量子积累过程,因此降低示踪剂剂量不可避免地包含不必要的噪声和伪影,从而在一定程度上降低pet图像质量。低剂量pet(l-pet)图像的质量明显比全剂量pet图像(f-pet)的质量差,涉及更多的噪声和更少的功能细节。这种l-pet图像可能不满足诊断要求。因此,从低剂量的f-pet图像合成高质量的f-pet图像以减少辐射照射,同时保持图像质量,是目前技术需要解决的难题。
目前有一些用于f-pet图像合成的方法。然而,它们大多数是基于体素的估计方法,例如基于随机森林的回归方法,基于映射的稀疏表示方法,半监督的三重字典学习方法以及多层次典型相关分析框架。尽管这些方法在低剂量下对pet图像质量增强具有良好性能,但是有两个主要缺点限制了潜在的临床可用性。第一个是它们都基于小块,并且通过对重叠块进行平均来确定每个体素的最终估计;该策略不可避免地导致过度平滑的图像缺乏典型的f-pet图像的纹理,从而限制了合成图像中小结构的量化;另一个缺点是这些基于体素的评估方法通常需要在线解决大量优化问题,因此在测试新主题时非常耗时;估算程序非常繁琐。
在大多数基于多信道的网络中,以全局方式执行图像卷积,即,对于每种模式,将相同的滤波器应用于所有图像位置,以生成将在更高层中组合的特征图。这不能有效地处理来自不同成像模式的位置变化贡献;要解决这个问题,应该强制实施局部自适应卷积;然而,如果局部自适应卷积只是在多通道框架中进行的,由于包含新的成像方式,必须学习许多附加参数;这对于训练样本数量经常受限的医疗应用不利。
技术实现要素:
为了解决上述问题,本发明提出了一种基于pet图形成像的系统及方法,减少由pet扫描固有的示踪剂辐射引起的潜在健康风险,从低剂量合成高质量pet图像以减少辐射暴露,同时保持图像质量。
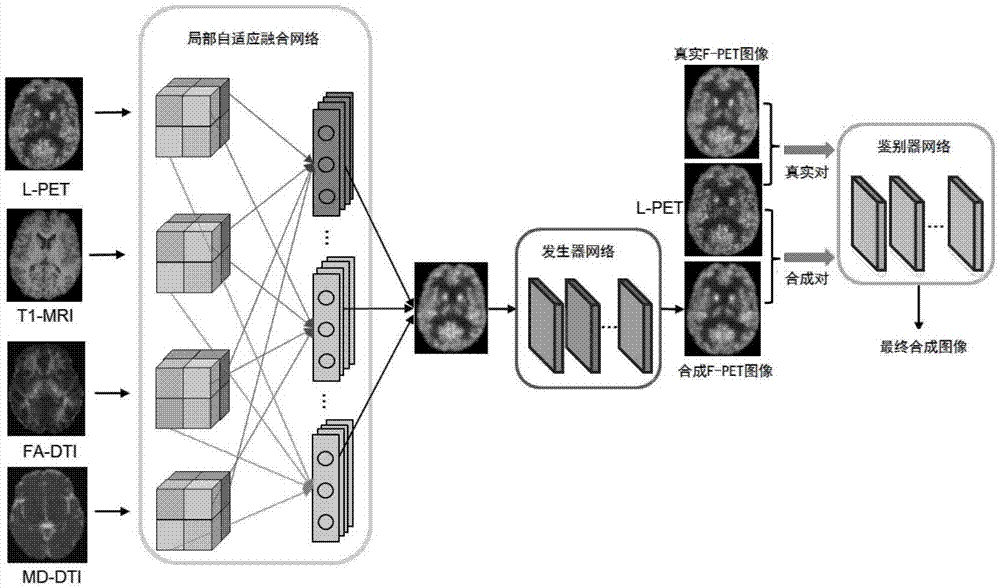
为达到上述目的,本发明采用的技术方案是:一种基于pet图形成像的系统,包括局部自适应融合网络模块、发生器网络模块和鉴别器网络模块;
局部自适应融合网络模块,将原始图像中的l-pet图像和多模态mri图像作为输入,并通过学习不同图像位置处的不同卷积核生成融合图像;
发生器网络模块,将融合图像通过训练生成合成f-pet图像;
鉴别器网络模块,以l-pet图像和真实f-pet图像组成真实对,以l-pet图像和合成f-pet图像组成合成对,将所述真实对和合成对作为输入,瞄准区分真实对和合成对得到最终合成图像。
进一步的是,在所述局部自适应融合网络模块中采用将多模态图像生成融合图像的方式,使模态数量的增加不会引起发生器中参数数量的增加;
在所述局部自适应融合网络模块中利用1×1×1内核进行局部自适应卷积,使在学习过程中的必要参数的数量最小化;
使用多模式(尤其是使其具有局部自适应性)可能会引发许多额外的参数来学习;因此,提出利用1×1×1内核来学习这种局部自适应融合机制,以尽量减少参数数目的增加;融合后的图像作为后续学习阶段的伪输入;
所述局部自适应融合网络模块与发生器网络模块和鉴别器网络模块共同学习,以确保它们相互协商,保证图像合成的最佳性能。
进一步的是,在所述局部自适应融合网络模块中,所述多模态mri图像包括t1-mri图像、fa-dti图像和md-dti图像;
首先,将整个l-pet图像和多模态mri图像分别分割成不重叠的小片;
然后,将相同位置处的小片分别使用四个不同的1×1×1滤波器进行卷积;
在局部自适应融合网络模块中,分别在l-pet图像、t1-mri图像、fa-dti图像和md-dti图像的四个块上操作四个滤波器进行卷积以生成其对应的组合块;
组合块中组合小片获得如下:
其中,
最后,将学习用于本地补丁的不同卷积核心组;组装输出的组合块以形成整个融合图像作为发生器网络模块的输入。
进一步的是,在所述发生器网络模块中,采用卷积层和去卷积层来确保输入和输出图像的大小相同;在所述卷积和去卷积层之间遵循u-net生成器网络添加跳过连接,从而实现组合分层特征合成;通过跳过连接策略缓解渐变梯度问题,从而使网络架构可能更深入。
进一步的是,所述发生器网络包括12个卷积层;
前6个卷积层中的编码器使用4×4×4滤波器,使用2步幅的卷积,对于泄漏relu块使用0.2的负斜率;特征映射的数量从第一层的64个增加到第六层的512个;
由于使用1×1×1内核的零填充,编码器部分的每个卷积层的输出减半特征映射的大小;解码器的采样系数为2;
使用跳过连接,来自编码器的特征映射被复制并与解码器的特征映射图连接;在每个卷积层中引入批量归一化,以减轻对深度神经网络的训练;
输出合成的f-pet图像。
进一步的是,所述鉴别器网络包括相同的卷积批量标准化漏泄relu块;鉴别器网络包括4个卷积层组成的典型cnn架构,其中每一个卷积层使用4×4×4滤波器,滤波器步长为2;
第一个卷积层产生64个特征映射,并且在下面的每个卷积层的特征映射数量依次加倍;在卷积层的顶部应用完全连接的层,并随后进行s形激活以确定输入是真实对还是合成对。
另一方面,本发明还提供了一种基于pet图形成像的方法,包括步骤:
s100,将原始图像中的l-pet图像和多模态mri图像输入局部自适应融合网络,在局部自适应融合网络通过学习不同图像位置处的不同卷积核生成融合图像;
s200,融合图像在发生器网络中通过训练学习生成合成f-pet图像;
s300,以l-pet图像和真实f-pet图像组成真实对,以l-pet图像和合成f-pet图像组成合成对,将所述图像对输入鉴别器网络中学习瞄准区分真实对和合成对,得到最终合成图像。
进一步的是,在所述最终合成图像的获取过程中,通过三个函数映射完成学习;能够更好地模拟从mri到ct的非线性映射并产生更逼真的图像;
第一种映射是针对局部自适应融合网络,产生融合图像;
第二种映射是针对生成器网络,将融合图像映射到合成f-pet图像;
第三种映射对应于鉴别器网络,将合成对与真实对区分开。
进一步的是,在所述最终合成图像的获取过程中,通过训练la-gans模型进行学习;训练la-gans模型是将所述局部自适应融合网络与发生器网络和鉴别器网络一起以交替方式进行训练,生成逼真的合成f-pet图像;
首先,使用从损失函数计算出的梯度来修正局部自适应融合网络和发生器网络,以训练鉴别器网络;
然后,修复鉴别器网络来训练局部自适应融合网络和发生器网络,减少局部自适应融合网络和发生器网络损失函数;同时使鉴别器网络最大化,随着训练的不断延续,增强局部自适应融合网络、发生器网络和鉴别器网络;
最后,发生器生成合成f-pet图像;
用于pet图像合成的三维条件gans模型,并以端到端的训练方式与合成过程共同学习了所提出的局部自适应融合;la-gans模型通过采用大尺寸图像补丁和分层特征来生成高质量的pet图像。
进一步的是,通过引入自动上下文策略优化上述网络模型的建立,包括步骤:
首先,使用原始模态包括l-pet图像、t1-mri图像、fa-dti图像和md-dti图像,训练la-gans模型;
然后,对于每个训练主体,使用la-gans模型生成相应的合成f-pet图像;
最后,将la-gan模型生成的所有训练样本的合成f-pet图像与原始模态一起用作上下文信息以训练新的自动背景la-gans模型,通过新的自动背景la-gans模型能够进一步细化合成的f-pet图像;
提出自动上下文la-gans模型,利用高级自动上下文信息和低级图像外观的整合;可以实现更好的性能,同时减少附加参数的数量;来进一步改进合成图像的质量。
采用本技术方案的有益效果:
本发明能够有效减少由pet扫描固有的示踪剂辐射引起的潜在健康风险,从低剂量合成高质量pet图像以减少辐射暴露,同时保持图像质量;
本发明提出了一种多模式融合的局部自适应策略,是一种融合深度神经网络中多模态信息的新机制;解决了不同图像位置的不同模态的作用存在不同使得整个统一内核图像不是最佳的问题;每种成像方式的重量因图像位置而异,以更好地服务于f-pet的合成;
本发明利用内核学习这种局部自适应融合,以使所产生的附加参数数量保持最小;本发明提出的局部自适应融合机制与pet图像合成在三维条件gans模型中共同学习,该模型通过采用大尺寸图像块和分层特征来生成高质量的pet图像。
附图说明
图1为本发明的一种基于pet图形成像系统的结构示意图;
图2为本发明的一种基于pet图形成像方法的流程示意图;
图3为本发明实施例中网络模型建立的流程示意图。
具体实施方式
为了使本发明的目的、技术方案和优点更加清楚,下面结合附图对本发明作进一步阐述。
在本实施例中,参见图1所示,本发明提出了,一种基于pet图形成像的系统,包括局部自适应融合网络模块、发生器网络模块和鉴别器网络模块;
局部自适应融合网络模块,将原始图像中的l-pet图像和多模态mri图像作为输入,并通过学习不同图像位置处的不同卷积核生成融合图像;
发生器网络模块,将融合图像通过训练生成合成f-pet图像;
鉴别器网络模块,以l-pet图像和真实f-pet图像组成真实对,以l-pet图像和合成f-pet图像组成合成对,将所述真实对和合成对作为输入,瞄准区分真实对和合成对得到最终合成图像。
作为上述实施例的优化方案,在所述局部自适应融合网络模块中采用将多模态图像生成融合图像的方式,使模态数量的增加不会引起发生器中参数数量的增加;
在所述局部自适应融合网络模块中利用1×1×1内核进行局部自适应卷积,使在学习过程中的必要参数的数量最小化;
使用多模式(尤其是使其具有局部自适应性)可能会引发许多额外的参数来学习;因此,提出利用1×1×1内核来学习这种局部自适应融合机制,以尽量减少参数数目的增加;融合后的图像作为后续学习阶段的伪输入;
所述局部自适应融合网络模块与发生器网络模块和鉴别器网络模块共同学习,以确保它们相互协商,保证图像合成的最佳性能。
作为上述实施例的优化方案,在所述局部自适应融合网络模块中,所述多模态mri图像包括t1-mri图像、fa-dti图像和md-dti图像;
首先,将整个l-pet图像和多模态mri图像分别分割成不重叠的小片;
然后,将相同位置处的小片分别使用四个不同的1×1×1滤波器进行卷积;
在局部自适应融合网络模块中,分别在l-pet图像、t1-mri图像、fa-dti图像和md-dti图像的四个块上操作四个滤波器进行卷积以生成其对应的组合块;
组合块中组合小片获得如下:
其中,
最后,将学习用于本地补丁的不同卷积核心组;组装输出的组合块以形成整个融合图像作为发生器网络模块的输入。
作为上述实施例的优化方案,在所述发生器网络模块中,采用卷积层和去卷积层来确保输入和输出图像的大小相同;在所述卷积和去卷积层之间遵循u-net生成器网络添加跳过连接,从而实现组合分层特征合成;通过跳过连接策略缓解渐变梯度问题,从而使网络架构可能更深入。
所述发生器网络包括12个卷积层;
前6个卷积层中的编码器使用4×4×4滤波器,使用2步幅的卷积,对于泄漏relu块使用0.2的负斜率;特征映射的数量从第一层的64个增加到第六层的512个;
由于使用1×1×1内核的零填充,编码器部分的每个卷积层的输出减半特征映射的大小;解码器的采样系数为2;
使用跳过连接,来自编码器的特征映射被复制并与解码器的特征映射图连接;在每个卷积层中引入批量归一化,以减轻对深度神经网络的训练;
输出合成的f-pet图像。
作为上述实施例的优化方案,所述鉴别器网络包括相同的卷积批量标准化漏泄relu块;鉴别器网络包括4个卷积层组成的典型cnn架构,其中每一个卷积层使用4×4×4滤波器,滤波器步长为2;
第一个卷积层产生64个特征映射,并且在下面的每个卷积层的特征映射数量依次加倍;在卷积层的顶部应用完全连接的层,并随后进行s形激活以确定输入是真实对还是合成对。
为配合本发明方法的实现,基于相同的发明构思,如图2所示,本发明还提供了一种基于pet图形成像的方法,包括步骤:
s100,将原始图像中的l-pet图像和多模态mri图像输入局部自适应融合网络,在局部自适应融合网络通过学习不同图像位置处的不同卷积核生成融合图像;
s200,融合图像在发生器网络中通过训练学习生成合成f-pet图像;
s300,以l-pet图像和真实f-pet图像组成真实对,以l-pet图像和合成f-pet图像组成合成对,将所述图像对输入鉴别器网络中学习瞄准区分真实对和合成对,得到最终合成图像。
作为上述实施例的优化方案,在所述最终合成图像的获取过程中,通过三个函数映射完成学习;能够更好地模拟从mri到ct的非线性映射并产生更逼真的图像;
第一种映射是针对局部自适应融合网络,产生融合图像;
第二种映射是针对生成器网络,将融合图像映射到合成f-pet图像;
第三种映射对应于鉴别器网络,将合成对与真实对区分开。
作为上述实施例的优化方案,在所述最终合成图像的获取过程中,通过训练la-gans模型进行学习;训练la-gans模型是将所述局部自适应融合网络与发生器网络和鉴别器网络一起以交替方式进行训练,生成逼真的合成f-pet图像;
首先,使用从损失函数计算出的梯度来修正局部自适应融合网络和发生器网络,以训练鉴别器网络;
然后,修复鉴别器网络来训练局部自适应融合网络和发生器网络,减少局部自适应融合网络和发生器网络损失函数;同时使鉴别器网络最大化,随着训练的不断延续,增强局部自适应融合网络、发生器网络和鉴别器网络;
最后,发生器生成合成f-pet图像;
用于pet图像合成的三维条件gans模型,并以端到端的训练方式与合成过程共同学习了所提出的局部自适应融合;la-gans模型通过采用大尺寸图像补丁和分层特征来生成高质量的pet图像。
作为上述实施例的优化方案,如图3所示,通过引入自动上下文策略优化上述网络模型的建立,包括步骤:
首先,使用原始模态包括l-pet图像、t1-mri图像、fa-dti图像和md-dti图像,训练la-gans模型;
然后,对于每个训练主体,使用la-gans模型生成相应的合成f-pet图像;
最后,将la-gan模型生成的所有训练样本的合成f-pet图像与原始模态一起用作上下文信息以训练新的自动背景la-gans模型,通过新的自动背景la-gans模型能够进一步细化合成的f-pet图像;
提出自动上下文la-gans模型,利用高级自动上下文信息和低级图像外观的整合;可以实现更好的性能,同时减少附加参数的数量;来进一步改进合成图像的质量。
在具体实施例的网络模型中实现过程:
1.输入:一组训练低剂量的l-pet图像
2.在il、it1、ifa、imd和is之间执行la-gan网络模型,以获得融合网络f,发生器网络g和鉴别器网络d;
3.对于每个训练样本i(i=1,2,...,n),使用上述训练的融合网络f和发生器网络g来生成合成全剂量f-pet图像
4.训练对象的合成f-pet图像
5:输出:la-gan和自动上下文la-gan的训练融合网络f和f′,以及训练的发生器网络g和g′。
以上显示和描述了本发明的基本原理和主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
- 还没有人留言评论。精彩留言会获得点赞!