自动挑选画家代表作的方法及装置与流程
本发明属于数字图像处理技术领域,具体涉及一种自动挑选画家代表作的方法及装置。
背景技术:
随着数字图像处理技术的迅速发展,可以很容易地在互联网上找到数以百万计的关于绘画艺术的数字图像,这使得计算机辅助绘画分析更加符合社会需求,也方便了希望了解艺术作品的普通人。在过去几年中,研究人员在针对各种任务的艺术品自动分析方面取得了巨大进步,如识别西方绘画、推断绘画风格、区分真品和赝品、自动生成特定风格的艺术作品等。此外,通过使用图像处理以及深度学习技术,科学家们也提出了很多自动分析图片的方法。
但是,目前的自动图片分析方法中还没有能够解决如何以风格为导向的自动选取画家代表作的问题。作为自动艺术绘画分析的一个特例,以风格为导向的代表作选择侧重于探索一位艺术家的所有绘画,并旨在选择具体的视觉艺术风格。事实上,沉浸在艺术绘画中的艺术家倾向于以自己的风格表达物体或场景。然而,来自艺术家的绘画的外部形式和技术在其所有绘画作品中可能会有所不同。例如用户想要了解更多关于梵高艺术家画作的图像,并使用“梵高”作为关键词搜索。结果页面中会包含梵高的许多著名作品,但风格高度重叠,很难让用户了解梵高在各个不同时期的绘写风格和技巧。因此,在分析数字艺术画时,分析一位艺术家的绘画事业中的偏好演变以及发现多件艺术作品来表现艺术家的创作特征至关重要。
基于此,本发明提供了一种自动挑选画家代表作的方法及装置,通过机器学习方法以及神经网络算法,为用户自动地挑选画家的代表作。
技术实现要素:
为了解决现有技术中的上述问题,即为了解决如何从画家的多个作品中选出最具代表性画作的问题,本发明第一方面,提供了一种自动挑选画家代表作的方法,包括:
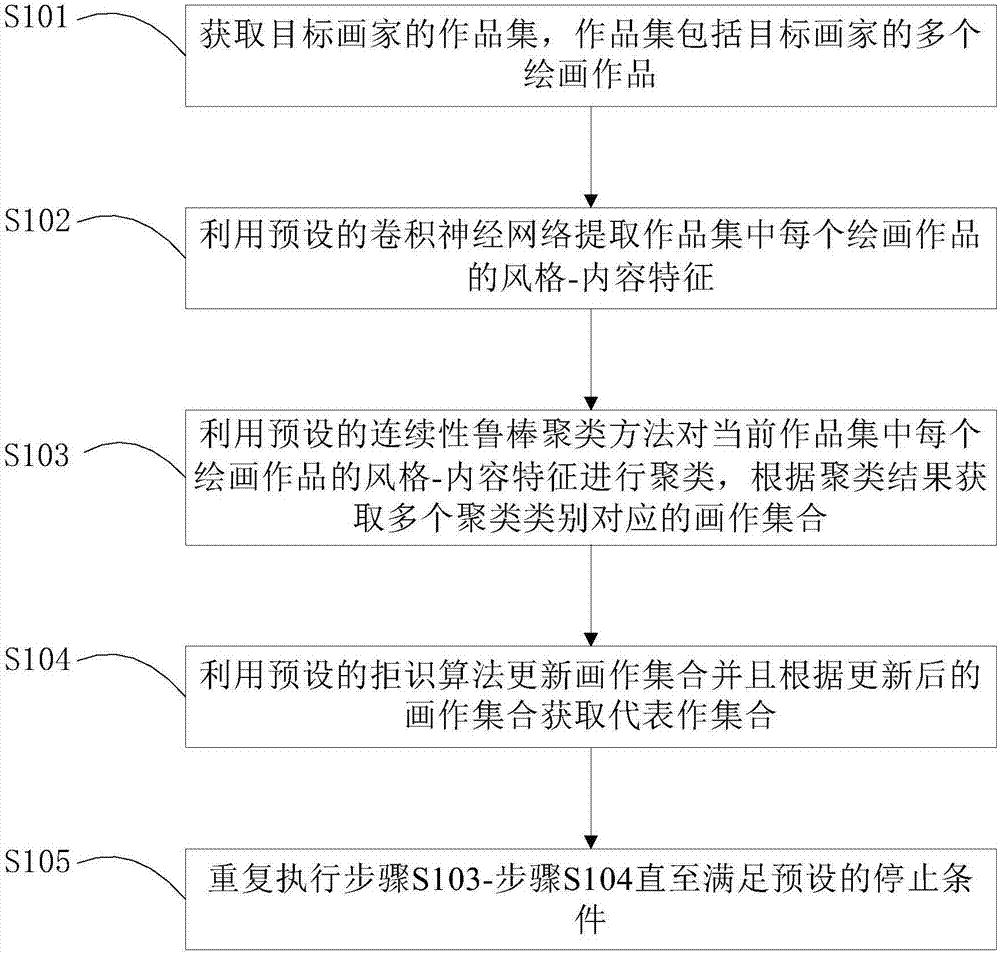
步骤s1:获取目标画家的作品集,所述作品集包括所述目标画家的多个绘画作品;
步骤s2:利用预设的卷积神经网络提取所述作品集中每个绘画作品的风格-内容特征;
步骤s3:利用预设的连续性鲁棒聚类方法对当前作品集中每个绘画作品的风格-内容特征进行聚类,根据聚类结果获取多个聚类类别对应的画作集合;
步骤s4:利用预设的拒识算法更新所述画作集合并且根据更新后的画作集合获取代表作集合;
步骤s5:重复执行步骤s3-步骤s4直至满足预设的停止条件;
其中,所述画作集合包括相应聚类类别对应的多个绘画作品,所述代表作集合包括每个所述画作集合对应的绘画作品代表作。
进一步地,本发明提供的一个优选技术方案为:
所述拒识算法是基于贝叶斯分类算法的画作识别拒识算法;“利用预设的拒识算法更新所述画作集合并且根据更新后的画作集合获取代表作集合”的步骤包括:
利用贝叶斯分类算法计算每个所述画作集合中每个绘画作品属于当前聚类类别的概率;
分别对每个所述绘画作品对应的概率与预设的概率阈值进行比较并且根据比较结果选择性地调整所述每个绘画作品所属的聚类类别;
获取每个所述聚类类别的聚类中心对应的绘画作品并且根据所获取的绘画作品确定所述代表作集合。
进一步地,本发明提供的一个优选技术方案为:
“利用贝叶斯分类算法计算每个所述画作集合中每个绘画作品属于当前聚类类别的概率”的步骤包括:
按下式所示的方法计算所述每个绘画作品属于当前聚类类别的概率:
其中,所述p(ui|m)为第m个聚类类别中第i个绘画作品对应的风格-内容特征ui的概率,所述p(m)为第m个聚类类别的概率,所述p(ui)为第i个绘画作品对应的风格-内容特征ui的概率;
所述m类类条件概率密度分布如下式所示:
其中,所述μm为第m个聚类类别对应的风格-内容特征的均值,所述∑m为第m个聚类类别对应的风格-内容特征的协方差矩阵,所述d为利用所述风格-内容特征预先构建的特征向量的维度,所述t为转置运算。
进一步地,本发明提供的一个优选技术方案为:
所述概率阈值包括第一概率阈值和第二概率阈值;“分别对每个所述绘画作品对应的概率与预设的概率阈值进行比较并且根据比较结果选择性地调整所述每个绘画作品所属的聚类类别”的步骤包括:
若所述p(m|ui)小于等于所述第一概率阈值,则将所述绘画作品ui从所述作品集中移除;
若所述p(m|ui)与p(m'|ui)之差的绝对值小于等于所述第二概率阈值,则将所述绘画作品ui从所述作品集中移除;
其中,所述p(m'|ui)为第i个绘画作品对应的风格-内容特征ui属于第m'个聚类类别的概率。
进一步地,本发明提供的一个优选技术方案为:
所述卷积神经网络包括多个卷积层“利用预设的卷积神经网络提取所述作品集中每个绘画作品的风格-内容特征”的步骤包括:
获取所述每个绘画作品在特定卷积层对应的所有特征图并且根据所述特征图获取第一特征向量;
获取所述特定卷积层对应的特征图之间的相关性特征并根据所述相关性特征获取第二特征向量;
根据所述第一特征向量和第二特征向量获取所述风格-内容特征。
进一步地,本发明提供的一个优选技术方案为:
“获取所述特定卷积层对应的特征图之间的相关性特征”的步骤包括:
按下式所示的方法计算所述特征图之间的相关性特征:
其中,所述cj为所述卷积神经网络中第j层卷积层对应的卷积核个数,所述hj为所述第j层卷积层对应的特征图高度,所述wj为所述第j层卷积层对应的特征图宽度,所述fj(x)h,w,c为所述第j层卷积层中第c个卷积核对应的特征图中第h行第w列的像素值;所述fj(x)h,w,c'为第j层卷积层中第c'个卷积核对应的特征图中第h行第w列的像素值。
进一步地,本发明提供的一个优选技术方案为:
“利用预设的连续性鲁棒聚类方法对当前作品集中每个绘画作品的风格-内容特征进行聚类”的步骤包括:
按下式所所示的目标函数,对所述作品集进行聚类:
其中,所述
k={k1,k2,...,kn}为代表作集合,所述kn为所述代表作集合中第n个代表作的风格-内容特征,所述ki为所述代表作集合中第i个代表作的风格-内容特征,kp为所述代表作集合中第p个代表作的风格-内容特征,kq为所述代表作集合中第q个代表作的风格-内容特征;所述ε是预设的数据连接图中所有数据连接所构成的连接集合,所述数据连接图是根据所述作品集中每个绘画作品的风格-内容特征所构建的聚类图,所述数据连接表示两个相关绘画作品的风格-内容特征在所述数据连接图上对应的数据关联关系;所述l为利用所述数据连接图中每个数据连接的预设的辅助变量所构建的辅助变量集合,所述(p,q)为所述数据连接图中第p个代表作的风格-内容特征kp与第q个代表作的风格-内容特征kq之间的数据连接,所述lp,q为所述数据连接(p,q)的辅助标量;所述
进一步地,本发明提供的一个优选技术方案为:
所述停止条件包括:重复执行步骤s3-步骤s4的次数达到设定的重复次数,或拒识的绘画作品数量小于设定的数量阈值,或拒识率小于设定的比例阈值;
其中,所述拒识的绘画作品为基于所述拒识算法从所述作品集中移除的绘画作品;所述拒识率为基于所述拒识算法从所述作品集中移除的绘画作品数量除以所述作品集中所有绘画作品数量得到的比值。
本发明的第二方面,还提供了一种存储装置,其中存储有多条程序,所述程序适于由处理器加载并执行以实现上述的自动挑选画家代表作的方法。
本发明的第三方面,该提供了一种控制装置,包括:
处理器,适于执行各条程序;
存储设备,适于存储多条程序;
所述程序适于由处理器加载并执行以实现上述的自动挑选画家代表作的方法。
与最接近的现有技术相比,上述技术方案至少具有如下有益效果:
本发明采用拒识算法从聚类类别中移除异样或易混淆的绘画作品实现对聚类作品集的更新,可以在聚类作品集得到更为准确的代表性作品;
本发明基于每个绘画作品的风格-内容特征并且采用连续性鲁棒聚类方法进行聚类,可以快速解开高维特征空间中的大规模数据,算法快捷、易于使用。
附图说明
图1是本发明实施例中一种自动挑选画家代表作方法的主要步骤示意图;
图2是本发明实施例中“梵高”的一个作品集及代表作图像示意图;
图3是本发明实施例中拒识算法原理的坐标示意图;
图4是本发明实施例中基于本发明方法选取的梵高的代表性作品集合示意图;
图5是本发明实施例中基于本发明方法选取的莫奈的代表性作品集合示意图;
图6是本发明实施例中基于梵高不同代表作作为风格图片得到的风格转移的效果对比示意图;
图7是本发明实施例中基于francispicabia绘画作品进行聚类和风格转移的效果对比示意图;
图8是本发明实施例中基于paulcezanne绘画作品进行聚类和风格转移的效果对比示意图;
图9是本发明实施例中基于本发明的聚类算法与kmeans算法聚类效果对比示意图;
图10是本发明实施例中基于k均值聚类的混淆矩阵示意图;
图11是本发明实施例中基于凝聚聚类的混淆矩阵示意图;
图12是本发明实施例中基于谱聚聚类的混淆矩阵示意图;
图13是本发明实施例中基于鲁棒连续聚类的混淆矩阵示意图;
图14是本发明实施例中基于本发明聚类的混淆矩阵示意图;
图15是本发明实施例中第一概率阈值为30%时的混淆矩阵比较示意图;
图16是本发明实施例中第一概率阈值为40%时的混淆矩阵比较示意图;
图17是本发明实施例中第一概率阈值为50%时的混淆矩阵比较示意图。
具体实施方式
下面参照附图来描述本发明的优选实施方式。本领域技术人员应当理解的是,这些实施方式仅仅用于解释本发明的技术原理,并非旨在限制本发明的保护范围。
为了方便用户欣赏一名画家的所有风格的作品,了解画家不同时期的绘画技巧,本发明实施例提供了一种自动挑选画家代表作的方法,该方法主要分为三部分:提取图片特征,通过聚类得到原始结果,通过拒识机制更新代表作集合。提取图片特征时,提取的特征需要能够表示绘画作品内容以及风格信息,即可以根据内容风格特征对某一画家的画作进行聚类;基于连续鲁棒聚类方法,使用可迭代的鲁棒估计器,通过优化一个连续的目标来处理混杂很多的集群来解开它们高维特征空间中的大规模数据,这种方法快速、易于使用;引入基于贝叶斯分类算法的画作识别拒识算法,可以得到更具有代表性的画家代表作品。
下面结合附图,对本发明提供的自动挑选画家代表作的方法进行说明。
参阅附图1,图1示例性示出了本发明实施例中自动挑选画家代表作的方法的主要步骤,如图1所示,本实施例中的自动挑选画家代表作的方法可以包括下述内容:
步骤s101:获取目标画家的作品集,作品集包括目标画家的多个绘画作品。
参阅附图2,图2示例性示出了“梵高”的一个作品集及代表作,如图2所示,左数第一个虚线方框内示出的是“梵高”的一个作品集,该作品集包含梵高的多不同风格及内容的绘画作品;左数第二个虚线方框内示出的是“梵高”的一个代表作图像。可以看出梵高不同时期的绘画风格及内容具有高度的重叠性,很难从一个作品集中了解梵高在各个不同时期的绘写风格和技巧,并且与其他作品相比,代表作的风格特征鲜明,易于区分,所以本发明基于绘画作品的风格-内容特征进行作品集的聚类。
步骤s102:利用预设的卷积神经网络提取作品集中每个绘画作品的风格-内容特征。
具体地,获取每个绘画作品在特定卷积层对应的所有特征图并且根据特征图获取第一特征向量;
获取特定卷积层对应的特征图之间的相关性特征并根据相关性特征获取第二特征向量;
根据第一特征向量和第二特征向量获取风格-内容特征。
本实施例中,为了保证提取的特征更好的表达绘画作品信息,应该提取图片深层的特征。当表达不同内容的场景时,艺术家的绘画风格在使用不同的笔画和着色时通常会有所不同,使用在imagenet数据库上预训练过的卷积神经网络vgg-19计算图片特征图。对于一张输入图像x而言,fj(x)是vgg19网络卷积层j层的特征图,其大小为cj×hj×wj。其中cj是卷积核的个数,hj是特征图像高度,wj是特征图像的宽度。通过矩阵拉伸运算,将特征图转化为一维向量fc,其包含cj×hj×wj个元素,用它作为图像的基于对象的表示,fc包含图像内容信息,以fc为第一特征向量。
一张绘画图像的风格信息包含其纹理,颜色,笔触特征,而在基于深度卷积神经网络的特征图中,每一个数字都来自于一个特定滤波器在特定位置的卷积,因此每个数字就代表一个特征的强度,g(·)是特征图之间的内积,而g(·)计算的实际上是两两特征之间的相关性,特征是同时出现的,相互加强或者相互减弱等等,同时,g(·)的对角线元素,还体现了每个特征在图像中出现的数量,因此,g(·)有助于把握整个图像的大体风格。在此基础上,要度量两个图像风格的差异,只需比较它们风格特征的差异即可。对g(·)进行拉伸变化,得到包含cj×cj个元素的一维向量作为风格特征向量fs,以fs为第二特征向量。故此,本发明通过公式(1)所示的方法得到图片深层的风格特征:
其中,cj为第j层卷积层对应的卷积核个数,hj为第j层卷积层对应的特征图高度,wj为第j层卷积层对应的特征图宽度,fj(x)h,w,c为第j层卷积层中第c个卷积核对应的特征图中第h行第w列的像素值;fj(x)h,w,c'为第j层卷积层中第c'个卷积核对应的特征图中第h行第w列的像素值。
获得绘画图像的第一特征向量fc和第二特征向量fs后,将第一特征向量fc和第二特征向量fs进行拼接得到绘画作品的风格-内容特征fcs=[fs,fc]。
步骤s103:利用预设的连续性鲁棒聚类方法对当前作品集中每个绘画作品的风格-内容特征进行聚类,根据聚类结果获取多个聚类类别对应的画作集合。
本实施例中,连续性鲁棒聚类方法是基于(shah,s.a.,koltun,v.:robustcontinuousclustering.proceedingsofthenationalacademyofsciences114(37),9814–9819)中描述的聚类算法,使用一种可迭代的鲁棒估计器,通过优化一个连续的目标来处理混杂很多的集群来解开它们高维特征空间中的大规模数据。该鲁棒估计器的输入是以风格-内容特征为表示的n个绘画图像,它使用相互最近邻连接(mutualk-nearestneighbors)将所有输入的风格-内容特征数据点连接成图,并且使用公式(2)所示的目标函数来揭示数据中潜在的聚类结构,然后找到以风格-内容特征为表示的代表作集合。
其中,
使用线性最小二乘系统的迭代优化算法实现对公式(2)的高效和可扩展的优化。可以通过分别固定公式(2)中的u和lp,q来依次优化,在迭代过程中,对ωp,q进行预先计算,μ自动减小,逐渐将非凸性引入到目标中,并且在每次更新μ后,根据公式(2)自动更新λ的值。然后得到最终的连接关系,有连接的两点属于同一类别,通过惩罚项的正则化作用,将潜在同一类别的样本所属的代表作合并成一个点,最终得到输入数据的代表作集合。
步骤s104:利用预设的拒识算法更新画作集合并且根据更新后的画作集合获取代表作集合。
具体地,利用贝叶斯分类算法计算每个画作集合中每个绘画作品属于当前聚类类别的概率;分别对每个绘画作品对应的概率与预设的概率阈值进行比较并且根据比较结果选择性地调整每个绘画作品所属的聚类类别;获取每个聚类类别的聚类中心对应的绘画作品并且根据所获取的绘画作品确定代表作集合。其中,画作集合包括相应聚类类别对应的多个绘画作品,代表作集合包括每个画作集合对应的绘画作品代表作。
基于质心的聚类方法特别容易受到混淆样本的影响,这将影响代表作品提取的准确性。基于这个现象,采用拒识算法来识别并移除在每个类别中不能被准确分类的图片,以生成更可靠和具有代表性的类别。将这个过程形式化为一个贝叶斯优化过程,其中将聚类生成的每个类别视为类先验条件概率密度分布,寻找被拒识的绘画图像。
本实施例中,将所有画作的特征集表示为u={ui|1≤i≤n},其中属于类别m的集合um中的元素是独立的,符合贝叶斯分布,那么利用公式(3)计算类别m类包含ui的类条件概率密度分布:
其中,μm为第m个聚类类别对应的风格-内容特征的均值,∑m为第m个聚类类别对应的风格-内容特征的协方差矩阵,t为转置运算,d为利用风格-内容特征预先构建的特征向量的维度,本实施中d为fcs=[fs,fc]的向量维度。
计算绘画作品ui属于类别m的概率的公式如公式(4)所示
其中,p(ui|m)为第m个聚类类别中第i个绘画作品对应的风格-内容特征ui的概率,p(m)为第m个聚类类别的概率,p(ui)为第i个绘画作品对应的风格-内容特征ui的概率。
计算得到的p(ui|m)会受到难以辨识风格的绘画的影响。为了提高有代表性的绘画选择的效果,采用拒识算法移除满足以下条件的图像:
参阅附图3,图3示例性示出了拒识算法原理的坐标图,如图3所示,从上往下数第一个坐标图中可以看出,如果p(m|ui)小于或等于第一概率阈值tr1,这意味着ui更可能是类别m的离群点,所以将ui对应的绘画作品从作品集中移除;从上往下数第二个坐标图中可以看出,如果ui属于类别m和类别m'的概率之差的绝对值小于或等于第二概率阈值tr2,这意味着ui很容易被类别m和类别m'混淆,所以将ui对应的绘画作品从作品集中移除。
步骤s105:重复执行步骤s103-步骤s104直至满足预设的停止条件。
具体地,一旦这种拒绝完成,我们再次聚集剩余数据,修改每个群集的概率分布,重复群集拒绝过程直到满足停止条件为止。停止条件包括:重复执行步骤s103-步骤s104达到设定的重复次数或拒识绘画作品的数量小于设定的数量阈值或拒识率小于设定的比例阈值;其中,拒识的绘画作品为基于拒识算法从作品集中移除的绘画作品;拒识率为基于拒识算法从作品集中移除的绘画作品数量除以作品集中所有绘画作品数量得到的比值;最后,在每个聚类中选取p(m|ui)值最高的图像作为该类别的代表图像。
针对本实施例的自动挑选画家代表作的方法,使用大量样例图像进行了实验验证,具有良好的效果,下面结合附图进行说明。
参阅附图4,附图4示例示出了基于本发明方法选取的梵高的代表性作品集合。
继续参与附图5,附图5示例性示出了基于本发明方法选取的莫奈的代表性作品集合,结合附图4和附图5可以看出,基于本发明的方法可以较好的区分一个画家作品的风格和内容特征,能够从一个画家的大量的作品中精确的选取出不同风格和内容信息的代表性作品集合。
参与附图6,图6示例性示出了基于梵高不同代表作作为风格图片得到的风格转移的效果对比,如图6所示,基于本发明方法选取的梵高的代表性绘画作品,提取其风格特征作用于其它作品中,得到的风格转移效果,图6中左数第一幅图为原图,左数第二幅、第三幅、第四幅、第五幅分别为基于梵高不同代表性作品的风格特征作用于左数第一幅的原图上得到风格转移效果,可以看出当风格转移后原图会有较大的风格变化,从侧面反映基于本发明的方法可以较好地发现一副绘画作品的风格特征,从而解决了选取的画家代表作集中风格高度重叠的问题,得到代表作集合中风格更加多样化,并且包含了梵高著名的画作。
参阅附图7,图7示例性示出了基于francispicabia的绘画作品进行聚类和风格转移的效果对比图。
继续参阅附图8,图8示例性示出了基于paulcezanne的绘画作品进行聚类和风格转移的效果对比图。图7和图8中每一行中左数第一列分别是其对应的左数最后一列图像的风格转移后的效果对比图,每一行中除了最后一列和最后一列,其它为基于本发明方法中聚类的结果,从图7和图8中可以看出本发明方法可以将基于图像的内容和风格信息进行聚类,将内容相似,风格相近的图像划分为一类。
参阅附图9,图9示例性示出了基于本发明聚类算法与kmeans聚类算法聚类效果对比图。本发明在小画集上直观地显示定性分析,如图9所示,从上到下数第一个方框内示出的是基于本发明方法的聚类效果;从上到下数第二个方框内示出的是基于kmeans聚类算法的聚类效果;其中,每个方框中从上到下数第一行的绘画风格为“辐射主义”,第二行的绘画风格为“哥特式”,第三行的绘画风格为“工笔”,每类中随机选择了10幅图像,在这30幅图像进行比较。基于标准质心的k均值通常用于生成有意义的聚类,聚类质心是每个聚类最具代表性的样本。但是,对于k均值聚类,类别的数量手动设置为3,与标准的k-means相比,本发明的方法能够自动检测“混淆主义”和“哥特式”风格的混淆“工笔”的失败案例,并拒绝这些混淆的样本。
参阅附图10至附图14,附图10至附图14分别示例性示出了不同聚类方法的混淆矩阵的比较,图10为基于k均值聚类的混淆矩阵;图11为基于凝聚聚类的混淆矩阵;图12为基于谱聚聚类的混淆矩阵;图13为基于鲁棒连续聚类的混淆矩阵;图14为基于本发明聚类的混淆矩阵。混淆矩阵的每一列表示鲁棒估计器对于绘画作品的类别预测;混淆矩阵的每一行表示绘画作品所属的真实类别;以颜色的深浅表示对绘画作品划分类别的准确性,颜色越深表示准确率越高,颜色越浅表示准确率越低。准确率从0至100%对应于颜色从白到黑的渐变。本实施例是在大规模数据集上进行的测试,在维基艺术网站上选择了7位艺术家的作品:“徐悲鸿”(共97幅),“kindinsky”(共218幅),“pierrealechinsky”(共220幅),“edouradmanet”(共232幅),“albrechtdurer”(随机抽取838幅中的300幅),“monet”(随机抽取1339幅中的300幅),“vincentvangogh”(随机抽取1928幅中的300幅),需要说明的是,本实施中的附图中“徐悲鸿”均用“xu-beihong”表示。
将本发明的聚类方法与三种传统的聚类方法进行了比较,标准k均值聚类(kmeans),凝聚聚类(a-cluster)和谱聚类(s-cluster)。绘画都是由内容风格的特征表示,采用欧几里德距离来衡量特征之间的相似性。
参阅表1,表1为本发明的聚类方法与三种传统的聚类方法的平均召回率和平均准确率对比表
表1
从表1可以看到,与其他方法相比,本发明具有更高的平均精确度,而平均召回率更低。通过拒绝混淆样本来实现选择性聚类,提高聚类精度,同时略微减少召回率,可以为代表性绘画选择生成更可靠的聚类。
参阅附图15至附图17,附图15至附图17分别示出了设置不同拒识阈值的混淆矩阵比较。在拒识过程中,使用不同的第一概率阈值来检测拒识算法的效果。图15为设置第一概率阈值tr1为30%的混淆矩阵;图16为设置第一概率阈值tr1为40%的混淆矩阵;图17为设置第一概率阈值tr1为50%的混淆矩阵。混淆矩阵的每一列表示鲁棒估计器对于绘画作品的类别预测;混淆矩阵的每一行表示绘画作品所属的真实类别;本实施例以颜色的深浅表示对绘画作品划分类别的准确性,颜色越深表示准确率越高,颜色越浅表示准确率越低。准确率从0至100%对应于颜色从白到黑的渐变。从图15-图17中可以看到,当阈值处于较低水平时,较多的绘画作品被分类错误,随着阈值的增加,拒识率上升而分类错误概率下降。
进一步地,基于上述自动挑选画家代表作的方法实施例,本发明还提供了一种处理装置,该处理装置可以包括处理器、存储设备;处理器,适于执行各条程序;存储设备,适于存储多条程序;程序适于由处理器加载并执行如上述的自动挑选画家代表作的方法。
所属技术领域的技术人员可以清楚地了解到,为了描述的方便和简洁,本发明实施例的装置的具体工作过程以及相关说明,可以参考前述实施例方法中的对应过程,且与上述方法具有相同的有益效果,在此不再赘述。
本领域技术人员应该能够意识到,结合本文中所公开的实施例描述的各示例的方法步骤及装置,能够以电子硬件、计算机软件或者二者的结合来实现,为了清楚地说明电子硬件和软件的可互换性,在上述说明中已经按照功能一般性地描述了各示例的组成及步骤。这些功能究竟以电子硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。本领域技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本发明的范围。
术语“第一”、“第二”等是用于区别类似的对象,而不是用于描述或表示特定的顺序或先后次序。
术语“包括”或者任何其它类似用语旨在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备/装置不仅包括那些要素,而且还包括没有明确列出的其它要素,或者还包括这些过程、方法、物品或者设备/装置所固有的要素。
至此,已经结合附图所示的优选实施方式描述了本发明的技术方案,但是,本领域技术人员容易理解的是,本发明的保护范围显然不局限于这些具体实施方式。在不偏离本发明的原理的前提下,本领域技术人员可以对相关技术特征作出等同的更改或替换,这些更改或替换之后的技术方案都将落入本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!