一种邮件分类方法及系统与流程
本发明涉及人工智能领域,特别是涉及一种邮件分类方法及系统。
背景技术
目前,反垃圾邮件的研究主要分为两类:基于信件源的阻断技术和基于内容的过滤技术。由于垃圾邮件的格式众多(包括html、文本和图片等),使用单一技术已无法满足过滤需求。然而,大多数反垃圾邮件系统的核心技术偏重于使用dns方式的实时黑白名单技术,该技术属于基于信件源的阻断技术,需要大量用户反馈和域名/ip的标记,这种事后防备型的技术对新出现的垃圾邮件过滤存在一定的时间差,而基于内容的过滤技术中的数据挖掘方法则可弥补这一缺陷。基于数据挖掘的过滤可对新出现的垃圾邮件提前预测,这种“事前先知型”的垃圾邮件过滤技术显然更符合当下多变的垃圾邮件过滤需求。
基于内容的垃圾邮件过滤技术中的数据挖掘方法就是文本分类,而在文本分类最常用的朴素贝叶斯方法中,存在条件独立性假设不存在和大规模邮件过滤速度较慢的缺陷,这直接导致邮件过滤效果不佳。
技术实现要素:
本发明的目的是提供一种邮件分类方法及系统,用以快速、准确地对邮件进行分类、过滤。
为实现上述目的,本发明提供了如下方案:
获取训练集邮件;所述训练集邮件包括垃圾邮件以及非垃圾邮件;
通过统计算法提取所述训练集邮件的特征词,得到训练集特征词;
根据所述训练集特征词以及灰狼优化-遗传算法,对贝叶斯网络模型进行训练,得到主分类器;
获取第一测试集邮件;
通过统计算法提取所述第一测试集邮件的特征词,得到第一测试集特征
根据所述第一测试集特征词,通过所述主分类器对所述第一测试集邮件进行分类,得到分类结果;
通过所述分类结果以及所述灰狼优化-遗传算法,对所述贝叶斯网络模型进行训练,得到客分类器;
获取第二测试集邮件;
通过统计算法提取所述第二测试集邮件的特征词,得到第二测试集特征词;
根据所述第二测试集特征词,通过所述主分类器以及所述客分类器对所述第二测试集邮件进行分类。
可选的,所述通过统计算法提取所述训练集邮件的特征词,得到训练集特征词,具体包括:
获取所述训练集邮件的训练文本;
对所述训练文本进行分词、去除停用词,得到多个单词;
对所有单词进行筛选,得到出现次数高于次数阈值的单词,确定为中心词;
通过统计算法计算所有单词的权重;
筛选出权重高于权重阈值的单词,得到训练集扩展词;
根据所述中心词以及所述扩展词确定训练集特征词,所述训练集特征词包括所述中心词和所述扩展词。
可选的,所述根据所述训练集特征词以及灰狼优化-遗传算法对贝叶斯网络模型进行训练,得到主分类器,具体包括:
将所述训练集特征词作为所述贝叶斯网络模型的输入,得到输出结果;
判断所述输出结果是否在误差范围阈值内;
若是,确定所述贝叶斯网络模型为主分类器;
若否,通过灰狼优化-遗传算法优化所述贝叶斯网络模型,使所述输出结果在误差范围阈值内,得到主分类器。
可选的,还包括,对分类后的邮件进行标记。
一种邮件分类系统,所述系统包括:
训练集邮件获取模块,用于获取训练集邮件;所述训练集邮件包括垃圾邮件以及非垃圾邮件;
第一提取模块,用于通过统计算法提取所述训练集邮件的特征词,得到训练集特征词;
第一训练模块,用于根据所述训练集特征词以及灰狼优化-遗传算法,对贝叶斯网络模型进行训练,得到主分类器;
第一测试集邮件获取模块,用于获取第一测试集邮件;
第二提取模块,用于通过统计算法提取所述第一测试集邮件的特征词,得到第一测试集特征词;
第一分类模块,用于根据所述第一测试集特征词,通过所述主分类器对所述第一测试集邮件进行分类,得到分类结果;
第二训练模块,用于通过所述分类结果以及所述灰狼优化-遗传算法,对所述贝叶斯网络模型进行训练,得到客分类器;
第二测试集邮件获取模块,用于获取第二测试集邮件;
第三提取模块,用于通过统计算法提取所述第二测试集邮件的特征词,得到第二测试集特征词;
第二分类模块,用于根据所述第二测试集特征词,通过所述主分类器以及所述客分类器对所述第二测试集邮件进行分类。
可选的,所述第一提取模块包括:
训练文本获取单元,用于获取所述训练集邮件的训练文本;
文本处理单元,用于对所述训练文本进行分词、去除停用词,得到多个单词;
中心词确定单元,用于对所有单词进行筛选,得到出现次数高于次数阈值的单词,确定为中心词;
计算单元,用于通过统计算法计算所有单词的权重;
筛选单元,用于筛选出权重高于权重阈值的单词,得到训练集扩展词;
训练集特征词确定单元,用于根据所述中心词以及所述扩展词确定训练集特征词,所述训练集特征词包括所述中心词和所述扩展词。
可选的,所述第一训练模块包括:
输入单元,用于将所述训练集特征词作为所述贝叶斯网络模型的输入,得到输出结果;
判断单元,用于判断所述输出结果是否在误差范围阈值内;
确定单元,用于当所述输出结果在误差范围阈值内时,确定所述贝叶斯网络模型为主分类器;
优化单元,用于当所述输出结果不在误差范围阈值内时,通过灰狼优化-遗传算法优化所述贝叶斯网络模型,使所述输出结果在误差范围阈值内,得到主分类器。
可选的,所述系统还包括:
标记模块,用于对分类后的邮件进行标记。
与现有技术相比,本发明具有以下技术效果:
贝叶斯网络(bayesiannetwork,bn)是一种基于概率推理的数学网络模型,在解决不确定性和不完整性问题上具有相当的优势。训练贝叶斯网络建立主分类器和客分类器,对待测邮件进行分类。一方面,能够避免dns方式中的过滤时间差,达到事前预测、事前防御的目的;另一方面,能够避免朴素贝叶斯方法中条件独立性假设不存在和过滤速度慢的缺陷,达到提高邮件过滤效果的目的。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
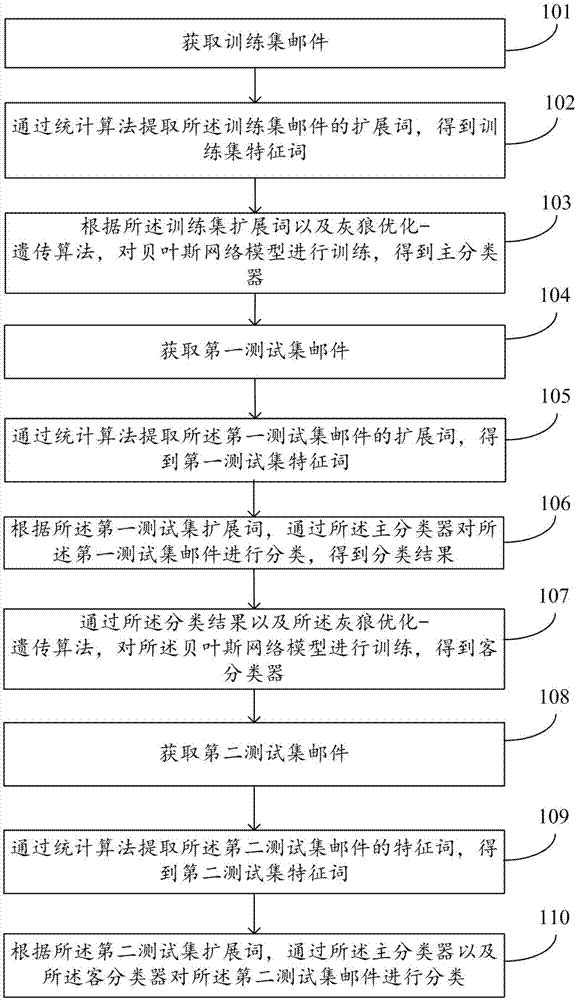
图1为本发明实施例邮件分类方法的流程图;
图2为三层贝叶斯网络结构图;
图3为轮盘赌选择图;
图4为行交换交叉操作图;
图5为本发明实施例邮件分类系统的结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
图1为本发明实施例邮件分类方法的流程图;图2为三层贝叶斯网络结构图;图3为轮盘赌选择图;图4为行交换交叉操作图。
如图1所示,一种邮件分类方法包括:
步骤101:获取训练集邮件;所述训练集邮件包括垃圾邮件以及非垃圾邮件。通过统计算法提取所述训练集邮件的特征词,得到训练集特征词。使用tf-idf算法给特征词赋予权值,选择高频特征词作为特征词,设置权重阈值,将权值高于阈值的特征词作为特征词的特征特征词存放到同一词袋中。
获取所述训练集邮件的训练文本;
对所述训练文本进行分词、去除停用词,得到多个单词;
对所有单词进行筛选,得到出现次数高于次数阈值的单词,确定为中心词;
通过统计算法计算所有单词的权重;
筛选出权重高于权重阈值的单词,得到训练集扩展词;
根据所述中心词以及所述扩展词确定训练集特征词,所述训练集特征词包括所述中心词和所述扩展词。
步骤103:根据所述训练集特征词以及灰狼优化-遗传算法,对贝叶斯网络模型进行训练,得到主分类器。
将所述训练集特征词作为所述贝叶斯网络模型的输入,得到输出结果;
判断所述输出结果是否在误差范围阈值内;
若是,确定所述贝叶斯网络模型为主分类器;
若否,通过灰狼优化-遗传算法优化所述贝叶斯网络模型,使所述输出结果在误差范围阈值内,得到主分类器。
图2为邮件过滤分类器的三层贝叶斯网络结构图。图中,将结构层分为三层,第一层为邮件层,第二层为细分类层,第三层为,特征层。其中,邮件层为一个节点,代表是否为垃圾邮件;细分类层为三个节点,包括邮件下的三个细分类(如广告类、工作类、财务类);特征层可包含有限个特征节点,根据所提取到的特征量选定。
基于gwo_ga(过灰狼优化-遗传算法)的三层贝叶斯网络结构学习分为如下七步:
a)通过计算分类器细分类(第二层)与特征节点(第三层)间的互信息构建最大支撑树;
b)将节点轮流当父子节点做bic评分,评分高的作为分类网络中边的方向初始化结构;
c)通过随机加边、减边和转边的方式获得分类器的初始结构,并对其bic评分;
d)采用转盘赌选择,从初始结构中选出10个(依据为gwo算法的狼群数量)作为父代结构;图3为轮盘赌选择图。图中,分为结构ga评分、结构gb评分和结构gc评分三块区域,评分越高的结构轮盘中所占面积越大,被选中的几率也越大,不过,评分低的结构仍有选中的机会,因此,在优的结构得以保留的同时又增加了结构的多样性,避免了搜索陷入局部最优。
e)两两结构间进行行交换交叉操作产生子代结构;图4为行交换交叉操作图。图中,两个矩阵分别表示结构ga和gb,将两个父代结构ga和gb的同行进行交换(如ga的第一行和第四行与gb的第一行和第四行交换)后获得子代结构。
f)对子结构中互信息值大的进行加边操作,互信息值小的进行减边操作,并对新结构bic评分;
g)对新结构中最优的前3个结构求交集,将3个最优结构的共同边作为下次迭代的初始结构。
在不满足迭代停止条件前,重复以上c)至g)的迭代过程,多次迭代直至搜索到最优结构,并将评分最优的结构作为最终分类器结构。
步骤104:获取第一测试集邮件。
步骤105:通过统计算法提取所述第一测试集邮件的特征词,得到第一测试集特征词。
步骤106:根据所述第一测试集特征词,通过所述主分类器对所述第一测试集邮件进行分类,得到分类结果;对分类后的邮件进行标记。
步骤107:通过所述分类结果以及所述灰狼优化-遗传算法,对所述贝叶斯网络模型进行训练,得到客分类器。
步骤108:获取第二测试集邮件。
步骤109:通过统计算法提取所述第二测试集邮件的特征词,得到第二测试集特征词。
步骤110:根据所述第二测试集特征词,通过所述主分类器以及所述客分类器对所述第二测试集邮件进行分类,对分类后的邮件进行标记。
主分类器训练随着收集到已有公开邮件数据库的更新而不间断更新训练,客分类器训练随着过滤结果和用户反馈邮件的出现而不间断更新训练。
根据本发明提供的具体实施例,本发明公开了以下技术效果:贝叶斯网络(bayesiannetwork,bn)是一种基于概率推理的数学网络模型,在解决不确定性和不完整性问题上具有相当的优势。训练贝叶斯网络建立主分类器和客分类器,对待测邮件进行分类。一方面,能够避免dns方式中的过滤时间差,达到事前预测、事前防御的目的;另一方面,能够避免朴素贝叶斯方法中条件独立性假设不存在和过滤速度慢的缺陷,达到提高邮件过滤效果的目的。
图5为本发明实施例邮件分类方法的结构示意图。如图5所示,本发一种邮件分类系统包括:
训练集邮件获取模块501,用于获取训练集邮件;所述训练集邮件包括垃圾邮件以及非垃圾邮件。
第一提取模块502,用于通过统计算法提取所述训练集邮件的特征词,得到训练集特征词。
所述第一提取模块502包括:
训练文本获取单元,用于获取所述训练集邮件的训练文本;
文本处理单元,用于对所述训练文本进行分词、去除停用词,得到多个单词;
中心词确定单元,用于对所有单词进行筛选,得到出现次数高于次数阈值的单词,确定为中心词;
计算单元,用于通过统计算法计算所有单词的权重;
筛选单元,用于筛选出权重高于权重阈值的单词,得到训练集扩展词;
训练集特征词确定单元,用于根据所述中心词以及所述扩展词确定训练集特征词,所述训练集特征词包括所述中心词和所述扩展词。
第一训练模块503,用于根据所述训练集特征词以及灰狼优化-遗传算法,对贝叶斯网络模型进行训练,得到主分类器。
所述第一训练模块503包括:
输入单元,用于将所述训练集特征词作为所述贝叶斯网络模型的输入,得到输出结果;
判断单元,用于判断所述输出结果是否在误差范围阈值内;
确定单元,用于当所述输出结果在误差范围阈值内时,确定所述贝叶斯网络模型为主分类器;
优化单元,用于当所述输出结果不在误差范围阈值内时,通过灰狼优化-遗传算法优化所述贝叶斯网络模型,使所述输出结果在误差范围阈值内,得到主分类器。
第一测试集邮件获取模块504,用于获取第一测试集邮件。
第二提取模块505,用于通过统计算法提取所述第一测试集邮件的特征词,得到第一测试集特征词。
第一分类506,用于根据所述第一测试集特征词,通过所述主分类器对所述第一测试集邮件进行分类,得到分类结果。
第二训练模块507,用于通过所述分类结果以及所述灰狼优化-遗传算法,对所述贝叶斯网络模型进行训练,得到客分类器。
第二测试集邮件获取模块508,用于获取第二测试集邮件。
第三提取模块509,用于通过统计算法提取所述第二测试集邮件的特征词,得到第二测试集特征词。
第二分类模块510,用于根据所述第二测试集特征词,通过所述主分类器以及所述客分类器对所述第二测试集邮件进行分类。
所述系统还包括:标记模块,用于对分类后的邮件进行标记。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的系统而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!