一种基于深度卷积生成对抗网络的场景识别方法与流程
本发明属于模式识别和机器学习领域,具体涉及一种基于深度卷积生成对抗网络的场景识别方法。
背景技术:
闭环检测在slam(同时定位与地图构建)中,被认为是最重要的一个环节,它主要是在给定当前帧图片下,移动机器人是否能够判别该场景是否之前见到过,这就是闭环检测要解决的问题,也就是场景识别。场景识别在计算机视觉领域是一项具有挑战性的工作,其在无人驾驶和移动机器人领域都有这个广泛的应用。
近几年,随着深度学习在人工智能领域的发展,深度卷积神经网络在图像识别、图像检测和图像分割等方向都取得了巨大的成果。和传统的人工设计的特征sift、surf和gist等相比,cnn不仅能够自动提取高质量的图像特征,而且具有很好的泛化能力,因此可以使用预训练好的网络应用于其他的任务上。虽然在场景识别领域,cnn特征已经被证明要优于传统的特征,但是这些深度卷积神经网络都是通过给定的训练集和标签的有监督学习得到,然后提取图像的特征,而在实际生活中,并没有很多的带有标签的数据集,即使利用人工标注,也要花费很多的时间和精力。因此,本发明提出了一种新的基于深度卷积生成对抗网络的场景识别方法,采用无监督的学习方法,来训练网络。首先,我们利用场景数据集place365作为训练集,训练集是大小为256*256的rgb图片。利用该训练集来得到深度卷积生成对抗网络。然后,利用训练好的学习场景数据分布的生成器,再反向训练一个卷积神经网络作为特征提取器,接着利用该卷积神经网络对图片进行特征提取,得到相对应的特征向量。最后,通过计算两张图片特征向量之间的余弦距离,如果其值效于设定的阈值,则认为两张图片的处于同一场景;反之,则认为是不同场景。
技术实现要素:
本发明针对现有技术的不足,提出了一种基于深度卷积生成对抗网络的场景识别方法。
本发明该方法的具体步骤如下:
步骤1、对训练集图片数据进行预处理;
将n张训练集图片像素值进行归一化,利用激励函数tanh,函数形式为f(x)=(1-e-2x)/(1+e-2x),将所有图片的像素值的归一化在[-1,1]的范围之间,x表示图片像素值;
步骤2、构建深度卷积生成对抗网络模型nn1;
首先,输入batch个符合高斯分布的k维随机张量到深度卷积对抗网络模型nn1的生成器g中,得到输出张量;深度卷积生成对抗网络模型nn1的生成器g的网络模型结构为输入层->反卷积层*6->输出层;其中输入节点数为k,输出节点数为256*256*3,反卷积层节点数分别为4*4*1024,8*8*512,16*16*256,32*32*128,64*64*64,128*128*32;此时,生成器g的输出张量的大小为[batch,256,256,3],即batch个样本,每一个样本的维度是[256,256,3],先令这batch个样本的每一组样本的标签为0,即作为假样本;在步骤1中随机抽取batch个预处理后的图片,令这些样本的标签为1,即作为真样本;接着训练深度卷积生成对抗网络中的判别器d,判别器d为有监督的二分类模型;深度卷积生成对抗网络模型nn1的判别器d的网络模型结构为输入层->卷积层*6->输出层;其中判别器d输入节点数为256*256*3;输出节点数为1,卷积层节点数分别为128*128*16,64*64*32,32*32*64,16*16*128,8*8*256,4*4*512;对深度卷积对抗网络模型nn1进行训练获得其判别器d的最优权值矩阵wc1~wc7和偏置向量bc1~bc7,其中wc1的大小为[5,5,3,16],bc1为[16,1],wc2的大小为[5,5,16,32],bc2为[32,1],wc3的大小为[5,5,32,64],bc3为[64,1],wc4的大小为[5,5,64,128],bc4为[128,1],wc5的大小为[5,5,128,256],bc5为[256,1],wc6的大小为[5,5,256,512],bc6为[512,1],wc7的大小为[8192,1],b7为[1,1];其中,深度卷积对抗网络模型nn1的生成器g中的所有层都是用relu激活函数,函数形式为f(m)=max(0,m),其中m表示当前层的输出值;除了输出层使用tanh激活函数,输入层不需要激活层;深度卷积生成对抗网络模型nn1的判别器d的所有层使用leakyrelu激活函数,函数形式为f(n)=max(0,0.2n),其中n表示当前层的输出值;除了输出层采用sigmoid作为激活函数,函数形式为
步骤3、构建卷积神经网络模型nn2;
先随机生成batch个符合高斯分布的k维随机张量输入步骤2中训练好的生成对抗网络的生成器g中,得到大小为[batch,256,256,3]的输出张量;把该输出张量作为的卷积神经网络模型nn2的输入数据,将生成器大小为[batch,k]的输入张量作为卷积神经网络模型nn2所对应的标签;卷积神经网络模型nn2网络模型结构为输入层->卷积层*6->输出层;其中输入节点数为256*256*3,输出节点数为k,中间卷积层节点数分别为128*128*8,64*64*16,32*32*32,16*16*64,8*8*128,4*4*25;因此,对模型进行训练获得其生成器的最优权值矩阵wc1’~wc7’和偏置向量bc1’~bc7’;其中wc1’的大小为[256,256,3,8],bc1’为[8,1],wc2’的大小为[64,64,8,16],bc2’为[16,1],wc3’的大小为[32,32,16,32],bc3’为[32,1],wc4’的大小为[16,16,32,64],bc4’为[64,1],wc5’的大小为[8,8,64,128],bc5’为[128,1],wc6’的大小为[4,4,128,256],bc6’为[256,1],wc7’的大小为[4096,k],bc7’的大小为[k,1];其中卷积神经网络模型nn2的所有层使用leakyrelu激活函数,除了输出层采用sigmoid作为激活函数,并且在每一层卷积层后面加上归一化层;
步骤4、根据步骤3中得到的卷积神经网络模型nn2,先对需要待判别的图像对进行预处理,即先将图片大小拉伸为[256,256,3],接着利用tanh函数对像素值进行归一化处理,然后用卷积神经网络模型nn2对其进行特征提取,得到相对应的特征向量,向量维度为[k,1];
步骤5、对上述步骤4中得到的两个向量求余弦距离,然后和给定的阈值进行比较;若小于阈值,则判定为相同场景,反之则判定为不同场景。
基于本方法的场景识别方法,和之前基于深度学习的场景识别相比,能够在给定无标签的数据集情境下,对网络进行训练,并且能够在学习到场景数据分布后,再对场景图片进行特征提取。不仅能够降低一些数据集制作的成本,而且提取出的特征向量能够更好的表征图片,能够提高场景识别任务中的识别准确性。
附图说明
图1为本发明方法中深度卷积生成对抗网络模型nn1的结构图;
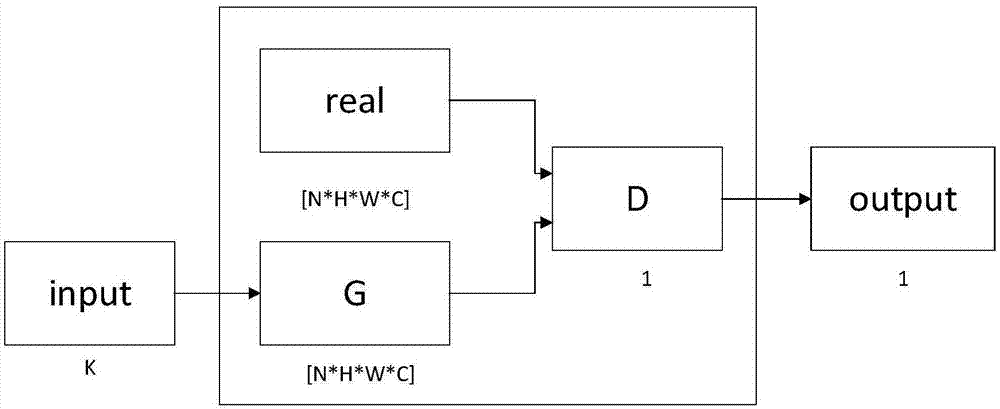
图2为本发明方法中的整体结构框图;
图3为本发明中生成器g的内部结构图;
图4为本发明中判别器d的内部结构图;
图5为本发明中卷积神经网络模型nn2的内部结构图。
图1-5中input表示输入、output表示输出、g表示生成器、d表示判别器,real是真实训练样本数据集,即place365数据集、n表示一次训练网络所需的训练集图片的数量,即batch,h表示训练集图片的高度,w表示训练集图片的宽度,c表示训练集图片的通道数,nn2表示卷积神经网络、inputvector为输入随机向量,outputvector为输出向量,deconv1~deconv6为反卷积层,conv1~conv7和conv1’~conv7’为卷积层。
具体实施方式
本发明通过利用无监督学习,即先训练一个深度卷积生成对抗网络,其结构图如图1所示,再利用已经学习到场景数据集分布的生成器,反向训练得到一个卷积神经网络来提取图像的特征,解决了图像数据集需要标签的问题,并且提取出比传统特征更能表征图像的特征向量。整个网络结构图如图2所示。
一种基于深度卷积生成对抗网络的场景识别方法,具体步骤是:
步骤1、对训练集图片数据进行预处理;
将n张训练集图片像素值进行归一化,利用激励函数tanh,函数形式为f(x)=(1-e-2x)/(1+e-2x),将所有图片的像素值的归一化在[-1,1]的范围之间,x表示图片像素值;
步骤2、构建深度卷积生成对抗网络模型nn1;
首先,输入batch个符合高斯分布的k维随机张量到深度卷积对抗网络模型nn1的生成器g中,生成器g的内部结构图如图3所示,得到输出张量。深度卷积生成对抗网络模型nn1的生成器g的网络模型结构为输入层->反卷积层*6->输出层;其中输入节点数为k,输出节点数为256*256*3,反卷积层节点数分别为4*4*1024,8*8*512,16*16*256,32*32*128,64*64*64,128*128*32;此时,生成器g的输出张量的大小为[batch,256,256,3],即batch个样本,每一个样本的维度是[256,256,3],先令这batch个样本的每一组样本的标签为0,即作为假样本;在步骤1中随机抽取batch个预处理后的图片,令这些样本的标签为1,即作为真样本;接着训练深度卷积生成对抗网络中的判别器d,判别器d为有监督的二分类模型,判别器d的内部结构图如图4所示;深度卷积生成对抗网络模型nn1的判别器d的网络模型结构为输入层->卷积层*6->输出层;其中判别器d输入节点数为256*256*3;输出节点数为1,卷积层节点数分别为128*128*16,64*64*32,32*32*64,16*16*128,8*8*256,4*4*512;对深度卷积对抗网络模型nn1进行训练获得其判别器d的最优权值矩阵wc1~wc7和偏置向量bc1~bc7,其中wc1的大小为[5,5,3,16],bc1为[16,1],wc2的大小为[5,5,16,32],bc2为[32,1],wc3的大小为[5,5,32,64],bc3为[64,1],wc4的大小为[5,5,64,128],bc4为[128,1],wc5的大小为[5,5,128,256],bc5为[256,1],wc6的大小为[5,5,256,512],bc6为[512,1],wc7的大小为[8192,1],b7为[1,1]。其中,深度卷积对抗网络模型nn1的生成器g中的所有层都是用relu激活函数,函数形式为f(m)=max(0,m),其中m表示当前层的输出值。除了输出层使用tanh激活函数,输入层不需要激活层。深度卷积生成对抗网络模型nn1的判别器d的所有层使用leakyrelu激活函数,函数形式为f(n)=max(0,0.2n),其中n表示当前层的输出值。除了输出层采用sigmoid作为激活函数,函数形式为
在本发明的一个具体实例中,k=128,采用欧式距离度量下的约束作为生成器g和判别器d中的损失函数,生成器g中的反卷积层采用relu函数作为非线性映射激活函数,输出层采用tanh作为非线性映射激活函数。判别器d中的卷积层中采用leakyrelu函数作为非线性映射激活函数,输出层采用sigmoid作为非线性映射激活函数,并在每一层反卷积层和卷积层后添加一层归一化层。采用随机梯度下降法迭代训练得到深度卷积生成对抗网络模型nn1中的最优参数。在本发明方法中,采用单独交替迭代训练的方式来对生成器g和判别器d进行训练,即对判别器g的参数更新2次,再对生成器d的参数更新1次,直到判别器d针对所有样本输入的输出值近似为0.5。
步骤3、构建卷积神经网络模型nn2;
先随机生成batch个符合高斯分布的k维随机张量输入步骤2中训练好的生成对抗网络的生成器g中,得到大小为[batch,256,256,3]的输出张量;把该输出张量作为的卷积神经网络模型nn2的输入数据,将生成器大小为[batch,k]的输入张量作为卷积神经网络模型nn2所对应的标签,卷积神经网络模型nn2的内部结构图如图5所示;卷积神经网络模型nn2网络模型结构为输入层->卷积层*6->输出层;其中输入节点数为256*256*3,输出节点数为k,中间卷积层节点数分别为128*128*8,64*64*16,32*32*32,16*16*64,8*8*128,4*4*25;因此,对模型进行训练获得其生成器的最优权值矩阵wc1’~wc7’和偏置向量bc1’~bc7’。其中wc1’的大小为[256,256,3,8],bc1’为[8,1],wc2’的大小为[64,64,8,16],bc2’为[16,1],wc3’的大小为[32,32,16,32],bc3’为[32,1],wc4’的大小为[16,16,32,64],bc4’为[64,1],wc5’的大小为[8,8,64,128],bc5’为[128,1],wc6’的大小为[4,4,128,256],bc6’为[256,1],wc7’的大小为[4096,k],bc7’的大小为[k,1]。其中卷积神经网络模型nn2的所有层使用leakyrelu激活函数,除了输出层采用sigmoid作为激活函数,并且在每一层卷积层后面加上归一化层;
在本发明的一个具体实例中,采用欧式距离度量下的约束作为卷积神经网络模型nn2中的损失函数,并在卷积神经网络模型nn2中的卷积层中采用leakyrelu函数作为非线性映射激活函数,并在每一层卷积层后面加入归一化层,输出层采用sigmoid作为非线性映射激活函数采用随机梯度下降法迭代训练得到神经网络模型nn2中的最优参数。
步骤4、根据步骤3中得到的卷积神经网络模型nn2,先对需要待判别的图像对进行预处理,即先将图片大小拉伸为[256,256,3],接着利用tanh函数对像素值进行归一化处理,然后用卷积神经网络模型nn2对其进行特征提取,得到相对应的特征向量,向量维度为[k,1];
步骤5、对上述步骤4中得到的两个向量求余弦距离,然后和给定的阈值进行比较。若小于阈值,则判定为相同场景,反之则判定为不同场景;
基于本方法的场景识别方法,和之前基于深度学习的场景识别相比,能够在给定无标签的数据集情境下,对网络进行训练,并且能够在学习到场景数据分布后,再对场景图片进行特征提取。不仅能够降低一些数据集制作的成本,而且提取出的特征向量能够更好的表征图片,能够提高场景识别任务中的识别准确性。
- 还没有人留言评论。精彩留言会获得点赞!