一种不良资产经营领域下金融知识图谱的构建方法与流程
本发明提供一种不良资产经营领域下金融知识图谱的构建方法,属于金融领域技术。
背景技术
不良资产经营领域包括不良资产包的收购和处置,涉及到对不良资产包的估值定价和多元化处置方法。随着数据时代的到来,在不良资产经营领域中业务人员能更加便利地获取数据信息,然而业务人员从海量的数据信息中获取高质量、高要求、高精准的信息仍然需要花费大量的时间和精力,工作量犹如大海捞针。上述情况不仅降低了业务人员的工作效率,还对有可能因为信息的不完全性使公司承担投资风险。基于这种现状,亟需建立不良资产经营领域内的金融知识图谱,实现对不良资产等金融领域下的知识管理,并结合业务规则高效地辅助业务人员开展信息穿透、风险预警等风险防控措施,并对相关业务进行辅助分析决策,提高工作效率。
知识图谱的建立涉及多个领域,包括自然语言处理、图论、复杂网络、深度学习等。金融领域内的知识图谱不仅仅涉及上述领域内容,还需要借助专家的知识储备,将业务专家的思考逻辑转化成知识图谱中的本体表达逻辑,增加了知识图谱的构建难度。本文借鉴医学领域知识图谱建立的成功经验,提出一种不良资产经营领域内的金融知识图谱构建方法,实现对内部数据的智能化抽取以及对多源异构数据的智能化融合,并基于业务专家的业务规则以及逻辑,实现知识推理、计算、补全,从而将全面、真实、有效的信息可视化的呈现给业务专家,从而解决不良资产经营领域企业和从业人员,在开展业务时缺乏风控决策支持的问题。
技术实现要素:
(一)本发明的目的
本发明的目的在于提供一种不良资产经营领域下金融知识图谱的构建方法,实现对不良资产领域的知识收纳、推理。
(二)本发明的技术方案
本发明一种不良资产经营领域下金融知识图谱的构建方法,其步骤如下:
步骤一、对不良资产经营领域中的结构化数据进行梳理,利用有效信息整理出不良资产经营领域中的本体、本体属性、关系、关系属性,形成金融知识图谱词典,进而利用映射文件将数据库映射成三元组形式的资源描述框架文件,记为rdf文件,为构建的初始本体库;
步骤二、以合同文本为例智能化抽取三元组,对不良资产经营领域中的合同进行分词处理,并利用特定合同模板对分词处理之后的词汇进行字符串识别,将识别之后的词汇内容作为候选实体;利用语义识别模型对候选实体进行筛选,获取实体位置、实体的属性、实体与实体之间的关系,通过实体内容和实体属性构建该实体的特征向量,并利用该向量与本体库进行匹配,确定该实体的所属本体;
步骤三、根据本体内容和时间项并结合金融知识图谱词典,对初始本体库中的本体类和本体属性、本体关系、关系属性进行融合,并将所有信息作为历史数据进行存储,以便进行知识推理、知识计算、知识补全;
步骤四、对于合并后的三元组本体库,对于用户输入的特定信息,使用rdf查询语言,记为sparql,将其转化为关系查询语句查询三元组本体库,并返回相关信息;然后,将查询到的三元组信息进行可视化操作,其中可视化工具利用数据驱动文档的浏览器编程语言框架,记为d3.js,生成动态关系图;
通过以上步骤,本发明提供了不良资产领域下的金融知识图谱构建方法,通过对结构数据的三元组构建、非结构数据的结构化提取、多源异构数据的融合,实现了知识推理、计算、补全,从而将全面、真实、有效的信息可视化的呈现给业务专家,从而解决不良资产经营领域企业和从业人员,在开展业务时缺乏风控决策支持的问题。
其中,在步骤一中所述的“结构化数据”,是指在甲骨文数据库,记为oracle数据库,存储的表结构数据;有效信息,是指构建不良资产领域的金融知识图谱相关信息,包括:公司基本数据、公司关联数据、公司族谱数据、个人任职数据等。
其中,在步骤二中所述的“抽取三元组”,其建立的过程如下:首先,合同文本筛选为word文本,对于其他格式的文本类型,需要先利用文件转化工具转化为word文本,若转化不成功,则放弃该文本;其次,利用结巴分词工具对word文本进行分词,分词模式为:全切词+新词发现+自定义词袋;特定的合同模板包括债转股合同、债权转让合同等合同模板类型;所述的“语义识别模型”,是指根据业务规则以及上下文语义进行候选实体判断,获取实体位置、实体属性、实体间的关系。
其中,在步骤三中提到的“融合”,具体是指在得到合同中的本体信息后,为了将合同中的本体和金融知识图谱词典进行逐一对比,若初始本体库中的本体类中不包含合同中的本体,则对初始本体库中的本体类进行更新,添加新的合同本体,其中合同中本体的属性作为更新后本体库的本体属性;若本体库中的本体类包含合同中的本体,则对初始本体库中的本体类进行更新,根据时间属性对本体中相同的属性,选择最近时间内的属性值;若本体对在初始本体库中不存在该关系,则将合同中的本体对关系添加到初始本体库中,合同中本体对关系的属性为初始本体库中关系的属性;若本体对在初始本体库中存在该关系,则根据合同中的本体对关系中时间属性和初始本体库中的时间属性对比,选择最近时间内的属性值,并将另外的属性作为历史属性放入到历史本体库中。
(三)本发明的优点及功效
本发明一种不良资产经营领域内的金融知识图谱构建方法,与现有技术相比,其优点及功效在于:(1)相比于传统的数据库关联查询,本发明利用自然语言处理技术,智能化、高效化地实现了知识推理功能,提高了查询效率,增加了业务人员的办事效率;(2)通过将结构化数据和非结构化数据融合,降低了人员在多个数据源信息搜索效率,降低了业务人员的信息获取不充分的风险;(3)三元组的数据存储格式为知识推理、计算、补全提供了数据基础,实现了数据的全面展示,为业务人员的信息推理提供强有力的数据支持。
附图说明
通过阅读下文优选实施方案的详细描述,各种其他的优点和益处对于本领域普通技术人员将变得清楚明了。附图仅用于显示出优选实施方案,而并不认为是对本发明的限制,而且在整个附图中,用相同的参考符号表示相同的部件。在附图中:
图1是本发明所述的构建方法流程图。
图2是本发明提供的一种具体的金融知识图谱的架构实施例流程图。
图3是本发明提供的本体及本体关系示意图。
图4是本发明提供的一种单体查询实例。
图5是本发明提供的一种关联关系实例。
具体实施方式
下面将结合本发明中的附图,对本发明的技术方案进行清楚完整地描述,显然,所描述的案例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
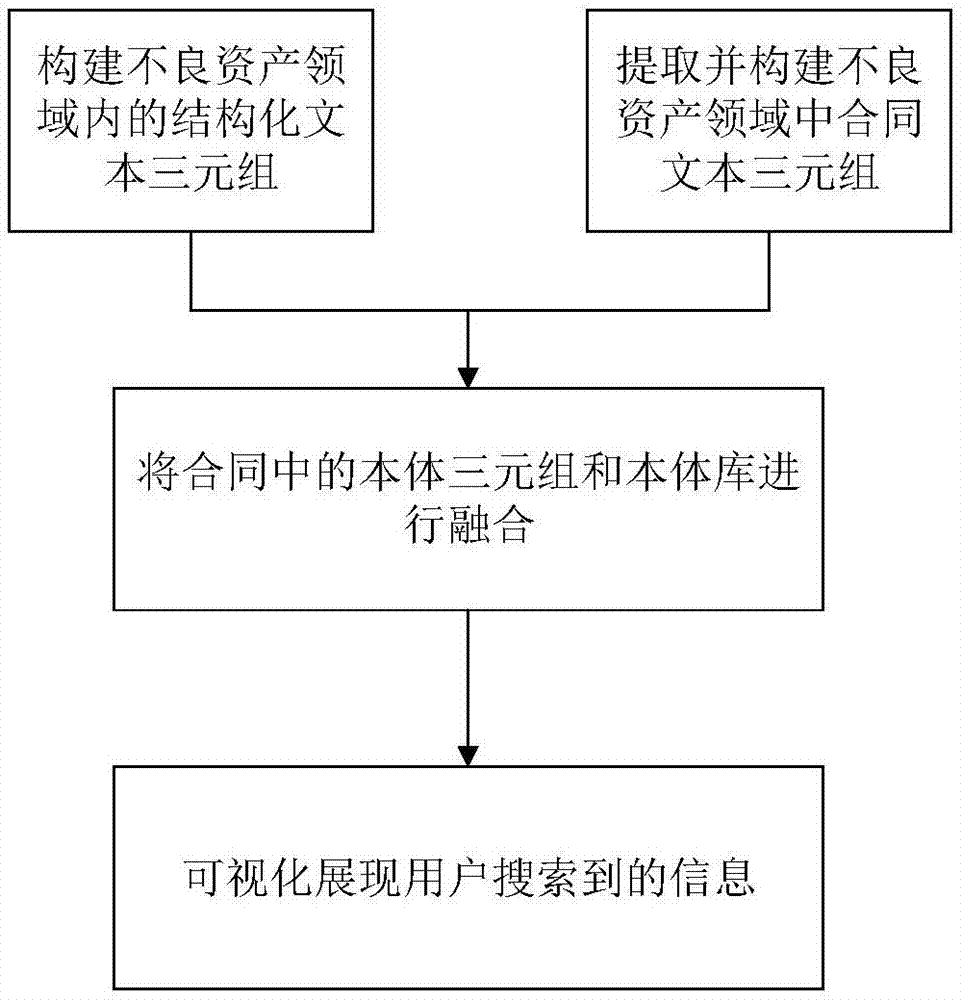
本发明提供了一种不良资产经营领域下金融知识图谱的构建方法,并结合实例详细说明,如图1所示,包括如下步骤:
步骤一、在对不良资产经营领域中结构化数据进行梳理时,先利用有效信息整理出不良资产经营领域中的本体、本体属性、关系、关系属性,形成金融知识图谱词典,进而利用mapping文件将数据库映射成三元组形式的rdf文件,得到构建的初始本体库;
步骤二、以合同文本为例智能化抽取三元组,对不良资产经营领域中的合同进行分词处理,并利用特定合同模板对分词处理之后的词汇进行字符串识别,将识别之后的词汇内容作为候选实体;利用语义识别模型对候选实体进行筛选,获取实体位置、实体的属性、实体与实体之间的关系,通过实体内容和实体属性构建该实体的特征向量,并利用该向量与本体库进行匹配,确定该实体的所属本体;
步骤三、根据本体内容和时间项并结合金融知识图谱词典,对初始本体库中的本体类和本体属性、本体关系、关系属性进行融合,并将所有信息作为历史数据进行存储,以便进行知识推理、知识计算、知识补全;
步骤四、对于合并后的三元组本体库,对于用户输入的特定信息,使用sparql将其转化为关系查询语句查询三元组本体库,并返回相关信息。然后,将查询到的三元组信息进行可视化操作,其中可视化工具利用d3.js生成动态展示图以及动态关系图。
本发明提供的不良资产经营领域中金融知识图谱构建方法中,首先对于结构化文本构建初始本体库,然后对合同数据源进行词汇抽取以及实体识别,通过构建实体的特征向量确定实体所属的本体,特征向量中包含实体的信息以及实体的属性。进而,将合同中的三元组信息与初始本体库信息进行信息融合,更新本体库并存储历史数据,最后将合并后的三元组本体库,利用关系查询语句进行查询,并返回特定的信息,自动生成金融知识图谱,从而能够为不良资产经营领域中的业务专家提供较为详实有效的参考方案。
为了便于理解,下面对上述方法实施例中的各个步骤进行详细说明,以及详细介绍本发明中的实施方法,如图2所示,本发明实施例以分层形式进行介绍。
在对不良资产经营领域中结构化数据进行梳理时,先利用有效信息整理出不良资产经营领域中的本体、本体属性、关系、关系属性,形成金融知识图谱词典,进而利用mapping文件将数据库映射成三元组形式的rdf文件,得到构建的初始本体库。
其中,结构化文本信息以oracle数据库表的形式存储,梳理得到的本体库信息包括:本体类、本体属性类、关系类、关系属性类。在本体类中,本发明实施例共包括企业、人、机构三类;在本体属性类中,每个本体类的属性均不相同,企业类属性包括许可经营项目、统一信用代码、住址、企业名称、经营状态、企业类型、成立日期、核准日期、法定代表人/负责人/执行事务合伙人、经营期限自、经营期限至、实收资本(万元)、注册资本(万元)、注册资本币种、注册号、登记机关、经营业务范围、国民经济行业代码、组织结构代码、注册资本币种代码、省市信息等,人的属性类包括姓名、职位、性别、身份证号码等,机构属性类包括机构名称、机构类型、行政区划、机构地址等;本体关系包括:投资、分支、法人、涉案等,在关系属性类中,投资关系属性包括企业总数量、注销日期、出资方式、认缴出资币种、统一社会信用代码、企业机构名称、企业状态、企业(机构)类型、开业日期、投资比例、法定代表人姓名等,分支关系属性包括分支机构地址、分支机构名称、分支机构负责人、分支机构企业注册号、一般经营项目等,法人关系属性包括法人名称、企业名称、任职时间等;涉案关系属性包括:身份证号码/企业注册号、案号、案件状态、执行法院、执行标的(元)、被执行人姓名/名称、立案时间、被执行人类型、创建时间、结案时间、执行法院区域代码等。将上述的数据类别梳理形成金融知识图谱词典。
对于oracle中具体的表结构,利用mapping文件生成三元组的rdf文件。下述以表1和表2为例,
表1.控制路径-关系数组表
表2.控制路径节点数组表
利用表1和表2对应的mapping文件得到rdf文件,其中,mapping文件各种包括:nodes类和links类,其均将关系数据库中的一个表映射为rdf的类,表1中的name对应nodes类的name;id对应nodes类的nodes_id;node_type对应nodes类的node_type;表2中的icl_from对应links类的company_from;icl_to对应links类的company_to;type对应links类的link_type。rdf文件的格式以三元组形式展现,如图3所示,以<主语、关系、属性>形式进行展示,记为{o,or,oa},其中o为主语、or为关系、oa为属性。这种三元组形式奠定了金融知识图谱中利用三元组进行融合、运算、查询的基础,同时为数据的格式化存储提供了基础。
以合同文本为例智能化抽取三元组,对不良资产经营领域中的合同进行分词处理,并利用特定合同模板对分词处理之后的词汇进行字符串识别,将识别之后的词汇内容作为候选实体;利用语义识别模型对候选实体进行筛选,获取实体位置、实体的属性、实体与实体之间的关系,通过实体内容和实体属性构建该实体的特征向量,并利用该向量与本体库进行匹配,确定该实体的所属本体。
在本发明实施例中,合同信息中包含债券转让合同、收购合同、保密合同、财务顾问合同等多种类型合同,当然还包括其他记载有合同信息的数据源,本发明实施例对此不作具体限定。
首先根据业务经验得到合同要素,以x={xi}1×n表示合同要素集合,每个xi表示一个合同要素,内容包括本体标签。对于一份真实的合同c,利用结巴分词工具对文本进行分词,采取分词方式为:特殊词库+精确分词+新词发现。自主词库来源共分为两部分:一部分为从网络上搜集以及业务专家提供,另一部分为利用概率模型提供。
网络上搜集和业务专家提供的特殊词库主要为:“不动产”、“货币贬值”、“中国人民银行”等。利用概率模型获取专业领域词汇步骤为:将所有的法律合同文件提取文本信息,去除掉非中文字符;将提取到的文件信息以空格进行首尾相连;进而利用多个字符共同出现的频率以及多个字符的左右信息熵,基于一定的阈值进行筛选,得到多个字符组成的词汇;将该词汇作为本发明的特殊词汇,主要包括:债务合同、本文等。将上述两种方法得到的词汇合并成为特殊词库作为本发明中的特殊分词词库。
利用上述方式对合同c进行分词后,生成以词序列构成的向量来表示该合同c=[w1,w2,…,wm],其中m表示合同c共包含m个词汇。对每个合同要素xi和词序列向量c=[w1,w2,…,wm]进行字符串匹配,将词
将实体内容和实体属性构建该实体的特征向量,该向量的构成方式为:
根据本体内容和时间项并结合金融知识图谱词典,对初始本体库中的本体类和本体属性、本体关系、关系属性进行融合,并将所有信息作为历史数据进行存储,以便进行知识推理、知识计算、知识补全。
在本发明实施例中,得到合同中的本体信息后,为了将合同中的本体和金融知识图谱词典进行逐一对比,若初始本体库中的本体类中不包含合同中的本体,则对初始本体库中的本体类进行更新,添加新的合同本体,其中合同中本体的属性为作为更新后本体库的本体属性;若本体库中的本体类包含合同中的本体,则对初始本体库中的本体类进行更新,根据时间属性对本体中相同的属性,选择最近时间内的属性值;若本体对在初始本体库中不存在该关系,则将合同中的本体对关系添加到初始本体库中,合同中本体对关系的属性为初始本体库中关系的属性;若本体对在初始本体库中存在该关系,则根据合同中的本体对关系中时间属性和初始本体库中的时间属性对比,选择最近时间内的属性值,并将另外的属性作为历史属性放入到历史本体库中。
对于合并后的三元组本体库,对于用户输入的特定信息,使用sparql将其转化为关系查询语句查询三元组本体库,并返回相关信息。然后,将查询到的三元组信息进行可视化操作,其中可视化工具利用d3.js生成动态展示图以及动态关系图。
在本发明实施例中,将生成的三元组本体库(rdf文件),利用sparql语句进行查询,并利用d3.js进行可视化操作,生成不良资产经营领域下的知识图谱。在专家输入了例如公司名称等实体参数之后,在对这些实体参数进行分词以及语义解析之后确定专家想要输入的实体,在基于该已生成的知识图谱,可以自动生成并输出关于该实体参数的信息内容,以供业务专家参考。
以查询与本体“绩溪县瑞泰置业有限公司”关联3个本体为例,需要利用查询语句为:
select?nwhere{
?srdf:type:company.
?s:companyname'绩溪县瑞泰置业有限公司'.
?s:hasinvestin?o.
?o:companyname?n
}=
limit3
则呈现出来的查询关系结构如图4所示,以查询两个企业之间的关系,如图5所示。
在具体实施时,这里的本体库中还包括预设的实体需要遵守的规则。具体来说,这里的规则可以包括:某人是公司a的法人,公司b是公司a的分支,则该人自动补充到公司b的独立法人信息。
因此,本发明实施例提供的方法还包括:
通过分词操作识别之后的实体、预设的所属实体需要遵守的规则以及所属规则中所关联的另一实体。
详细来说,对于各个识别出来的实体,需要判断一下该实体在本体库中是存储有限制该实体的规则,若有,则获取基于该规则所关联的另一实体,最终获得《实体、规则、实体》的三元组。
- 还没有人留言评论。精彩留言会获得点赞!