一种面向RDF知识图谱的语义近似查询方法与流程
本发明涉及知识图谱查询技术领域,具体涉及一种面向rdf知识图谱的语义近似查询方法。
背景技术
近年来,随着社交网络、电子商务等新一代大规模互联网智能应用的兴起,网络中各类数据的规模、更新速率、复杂程度均日益增长。在大数据分析过程中,基于rdf(resourcedescriptionframework)的知识图谱(knowledgegraph)作为一种有效描述大数据及其复杂关联关系的数据表现形式,扮演着越来越重要的角色。
目前,面向rdf知识图谱的查询方法按照其所用技术及应用场景可分为以下两类:(1)基于子图遍历和匹配算法实现对给定查询图的精确查询,即返回严格满足查询条件的查询结果(查询结果一定包含给定的查询谓词)。(2)基于先验知识和结构相似性实现对给定查询图的模糊查询,即返回近似查询结果(查询结果不仅限于给定的谓词)。
上述研究成果分别从结构相似性、语义相似性等角度展开研究并取得了突出效果,但面对多源异构且具有一定数据不完整性的rdf知识图谱,上述研究成果仍然具有一定的局限性。以wikipedia为例,其允许全网用户进行开放式的词条创立、维护、更新,导致针对同一实体或谓词的描述具有多种不同形式,使用户无法给出精确的查询语句,引起查询结果的缺失。此外,也会出现某类知识缺乏描述信息的情况,即存在一定的数据不完整性,使用户无法通过通用的先验知识获取此类知识的结构特征,引起查询结果缺失。
综上所述,在rdf知识图谱查询应用中,由于用户并不了解底层数据的组织结构与关联关系,无法写出精确的sparql查询语句,且无法利用有限的先验知识覆盖某一领域全部知识的图谱结构,从而导致查询结果数量有限且不能很好满足用户真实查询意图。为此,本发明充分考虑rdf知识图谱中实体与谓词的语义局部性特征实现对知识图谱数据的有效重构形成可训练的文本语料,在此基础上利用文本语义嵌入模型实现上下文敏感的语义学习,获取实体与谓词的语义向量,最后对用户提供的sparql查询语句进行语法分析并扩展查询谓词语义,实现基于语义相似度的rdf知识图谱近似查询,实时返回满足用户查询意图的语义近似查询结果。
技术实现要素:
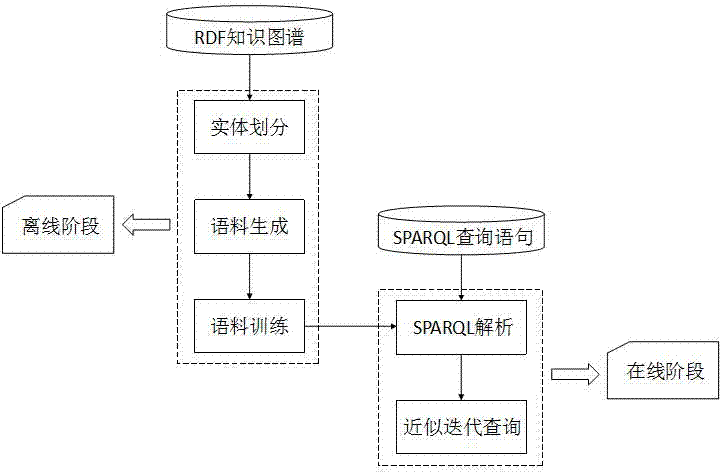
本发明的目的在于克服上述已有技术的不足,提出一种面向rdf知识图谱的语义近似查询方法,有效解决rdf知识图谱查询在多源异构及数据不完整性约束下的查询精度及性能问题,有助于促进知识图谱近似查询研究领域的进一步发展。本发明提出的面向rdf知识图谱的语义近似查询方法,具体步骤包括两个阶段:离线语料生成和训练阶段以及在线实时查询阶段。其中:
步骤1:离线语料生成和训练阶段。
这个阶段包括将rdf知识图谱转化成可训练的文本语料,并利用文本嵌入模型对该文本语料进行上下文敏感的语义学习,训练出实体与谓词的语义向量。主要包括以下三个步骤:
步骤1.1:实体划分
实体划分是根据实体的类型,对rdf知识图谱进行划分,使得相同类型的实体聚集在一起进行语料的生成,有助于语料训练效果的提高。假设给定两个实体ei和ej,通过rdf知识图谱获得两个实体的邻接实体分别是n(ei)={ni1,ni2,...,nik}和n(ej)={nj1,nj2,...,njm}(其中,ni1是实体ei的第一个邻接实体)。再获取给定实体及其邻接实体的类型分别是t(ei)={ti1,ti2,...,tik'}和t(ej)={tj1,tj2,...,tjm'},如果t(ei)和t(ej)的主要部分都重合,即可判定实体ei和ej是相同类型的实体。按照上述规则将rdf知识图谱中的所有实体划分为n个实体集合e={ek|1≤k≤n,k∈n},其中,每个实体集ek包含了相同类型的m个实体,表示为ek={eki|1≤i≤m,i∈n}。
步骤1.2:语料生成
考虑rdf知识图谱中实体与谓词的语义局部性特征,提出一种bfs-dfs混合图遍历语料生成算法corpusgeneration,对知识图谱数据进行有效重构,形成可训练的文本语料。根据步骤1.1划分好的实体集,对n个实体集合的每一个实体集都进行语料生成。下面拿n个实体集合中的某一个实体集e作为例子进行说明,其他实体集合也做相同操作。考虑某一个实体节点,周边与其越靠近的知识图谱网络所表达的语义信息必定与该实体更为相关,而与其越远的知识图谱网络所表达的语义信息相对来说相关性更低,生成的语料文本经过训练以后得到的相关性效果也较差。因此本发明考虑用广度优先遍历算法(bfs)先在某个实体周边框定一个范围,尽可能保证基于这个范围内生成的语料文本与该实体具有较高的相关性。框定范围后,为了保证生成的语料信息具有一定的逻辑性和实际意义,比如车型bmw_x6的厂商是bmw公司,而bmw公司又是德国企业,那么具有实际意义的一条路径即可表示为:
bmw_x6-manufacturer-bmw-location-germany
因此本发明在框定范围的基础上采用了深度优先遍历算法(dfs)来获取框定范围内具有逻辑性和实际意义的路径,将这些路径拼接后构成语料文本。下面拿n个实体集合中的某一个实体集作为例子进行说明,其他实体集合也做相同操作。假设从n个实体集合中选定了一个实体集e,该实体集中包含了相同类型的m个实体,表示为e={ei|1≤i≤m,i∈n}。从构建好的rdf知识图谱中获取关于这个实体集e的实体类型关系结构图o,并给定语料限定层数参数n,把e,o,n作为输入参数,按如下算法进行语料生成:
其中,输入参数e为知识图谱划分后选定的实体集;o为从rdf知识图谱得到该实体集中实体的类型关系图结构;n为给定的语料限定层数参数;t为已经作为起始节点访问过的实体集合。
首先设置t为空,表明初始时实体集e中的任何实体节点都未被访问。根据已访问节点集合t以及关于实体集e中关于实体类型的关系结构o,从实体集e中选定一个实体estart作为起始中心节点,并从e集合中删除该实体,避免之后对该实体进行重复访问处理;当e不为空时,首先初始化pstart为空,pstart为起始节点estart到以estart为中心n层范围内的其他节点(不包括estart)的路径,cstart以是关于起始节点estart的语料文本,把estart、n、pstart、cstart以及t作为输入做ndepthbfs算法操作,在ndepthbfs算法中生成的语料文本信息更新到cstart,同时更新t。退出ndepthbfs算法,把更新完的cstart加入到语料集c中。根据更新完的t以及o,并在实体集e中过滤掉已经作为中心节点访问过的集合t,重新选定一个起始中心节点,重复以上操作直到实体集e中的所有实体节点都被访问。
其中,ndepthbfs中生成语料信息更新cstart以及t的过程按如下算法进行计算:
其中,该算法中的输入estart为起始中心节点,n为给定的语料限定层数参数,pstart为estart到以estart为中心n层范围内的其他节点的路径,cstart为关于当前中心点estart的语料文本信息,t为已经作为起始节点访问过的实体集合。
算法首先判断当前语料限定层数n是否小于等于零,如果满足n小于等于零的条件,说明当前范围内中心节点周围已无其他节点与边,则把当前中心节点estart加到路径pstart中,然后把当前路径pstart为加入到语料集cstart中,并且把estart加入到t中,表明中心节点estart已经被访问过;如果不满足n小于等于零的条件,则把当前中心节点estart加到路径pstart中,并且把estart加入到t中,表明中心节点estart已经被访问过,然后找出中心节点estart的邻接节点,对于每一个estart的邻接节点都做ndepthbfs递归操作,其中输入参数更新为n-1层,直到中心节点周围已无其他节点与边。
步骤1.3:语料训练
通过步骤1.2的算法进行一系列计算之后把rdf知识图谱转化成了可以训练的文本语料c,利用gensim的word2vec模型对语料c进行上下文敏感的语义学习,得到关于语料c的语义模型m,通过加载该模型可以获取语料c中某一个词word的topk个词义最相近的相关词,构成关于word的相关词集合word',使之可以在进行在线实时查询的时候被使用。
步骤2:在线实时查询阶段。
这个阶段包括对用户给定的sparql查询语句进行语法分析,并对其中的谓词进行适当语义扩展;然后从给定实体出发进行基于谓词语义相似度的近似迭代查询,实时获取语义近似查询结果。主要包括以下两个步骤:
步骤2.1:sparql解析
对用户给定的sparql查询语句进行语法分析,解析出用户指定实体、用户期望返回宾语的类型、用户指定的关系谓词,并根据步骤1.3中得到的语义模型m计算出关系谓词的相关词,完成适当的语义扩展。在该过程中,将解析得到的结果作为输入参数代入迭代查询算法semanticapproquery进行实时计算。具体按如下算法进行解析:
其中,该算法中的输入q为用户给定的sparql查询语句。该算法先对用户给定的sparql查询语句q进行解析,得到指定主语实体estart,用户期望返回结果的宾语实体的类型tend,以及指定的谓语关系r;通过步骤1.3得到的相似词计算模型m,计算出指定谓语关系r的所有近义相关词的集合r';g为总查询结果集,初始为空;p为查询结果的子路径。
步骤2.2:近似迭代查询
通过解析用户给定的sparql语句,得到主语实体、指定谓词以及宾语实体类型,为了尽可能全的找出用户希望得到的宾语实体,本发明考虑从主语实体出发,借助训练得到的语义模型获取谓词的语义相关词,在知识图谱中匹配由主语实体+相关谓词构成的子图模式,从而找到与主语实体一跳相关的宾语实体,并判断该宾语实体的类型是否属于用户指定的实体类型,若符合则加入结果集中。再从已得到的结果集中的宾语实体出发,迭代上述操作可找到与主语实体两跳相关的宾语实体结果。如此迭代查询,直到找出所有满足条件的宾语实体,再将迭代过程中记录的宾语实体拼接成一条路径,即找到指定主语实体到结果宾语的路径(实体之间用谓词连接)。具体的查询过程按如下semanticapproquery算法进行:
其中,该算法中的输入estart为用户指定的主语实体节点,r'为指定谓语关系r的相似词集合,tend为用户期望返回结果实体的类型、p为查询结果的子路径、g为总查询结果集。
算法首先判断起始节点estart的类型是否是tend类型,若条件满足,则把当前子路径p加入到查询结果集g中;若条件不满足,则获取当前起始节点estart的邻接谓语关系词,判断该词是否属于r',若属于,则获取当前起始节点estart与当前谓语关系词ri组成的三元组关系中的另一个节点e'start,把该节点加入到子路径p中。然后将e'start、r'、tend、g、p作为新的输入参数,递归调用semanticapproquery算法,直到找到当前节点的类型是tend才结束。
与现有技术相比,本发明有如下优点:
一方面,本发明考虑了语义局部性特征,实现了上下文敏感知识图谱语义学习。通过bfs-dfs混合图遍历算法实现对rdf图数据的有效重布局,将物理上具有局部相关性的实体聚合在一起形成文本语料(完成从图数据到文本语料的有效转换),在保留已有三元组知识的同时通过局部相关性对其进行知识扩充以尽可能消除多源异构和数据不完整性对语义学习带来的负面影响,使得在数据多源化以及数据不完整的情况下,借助数据本身带有的语义尽可能地减少对于先验知识的依赖。然后利用文本嵌入模型对rdf知识图谱实体、谓词等要素实现上下文敏感的语义学习,获取语义向量,为后续语义近似迭代查询提供数据基础。
另一方面,在上述数据基础上,本发明对用户的sparql查询进行语义拓展即查询语义的泛化,然后通过多层次的迭代查询,尽可能多的查找出所有满足条件的路径。
附图说明
图1为本发明的系统架构图。
图2为本发明离线和在线阶段的实例流程图。
具体实施方式
以下用实例并结合附图来演示本发明的具体实施方式。本发明整体系统架构如图1所示,各个阶段依次进行处理如下:
步骤1:离线语料生成和训练阶段。
这个阶段包括将rdf知识图谱转化成可训练的文本语料,并利用文本嵌入模型对该文本语料进行上下文敏感的语义学习,训练出实体与谓词的语义向量。主要包括以下三个步骤:
步骤1.1:实体划分
面向整个英文维基库(https://www.wikipedia.org/)的rdf知识图谱,根据实体的类型,相同类型的实体聚集成一类,将rdf知识图谱中的所有实体划分为n个实体集合e={ek|1≤k≤n,k∈n},其中,每个实体集ek包含了相同类型的m个实体,表示为ek={eki|1≤i≤m,i∈n}。
步骤1.2:语料生成
根据步骤1.1划分好的实体集,对n个实体集合的每一个实体集都进行语料生成。下面拿n个实体集合中的某一个实体集e作为例子进行说明,其他实体集合也做相同操作。在该实体集e中选取某一个实体节点g,从g点出发通过bfs-dfs混合图遍历语料生成算法corpusgeneration,获取了g点周边相关的实体节点与关系,如图2中rdfkgofgstorage所示,其中图中各个实体记号与它实际意义的对应关系如下:
a:university_of_stuttgart
b:stuttgart
c:münchen
d:fc_bayern_münchen
e:porsche_911
f:porsche
g:germany
h:bmw
i:bmw_x5
j:porsche_panamera
k:porsche_cayenne
l:angela_dorothea_merkel
m:bmw_z4
n:bmw_i8
o:automobile
图中各个关系记号与它实际意义的对应关系如下:
r1:education
r2:sport
r3:establish
r4:city
r5:city
r6:place_of_origin
r7:manufacturer
r8:location
r9:production
r10:manufacturer
r11:designer
r12:supplier
r13:leader
r14:designer
r15:supplier
r16:type
r17:type
r18:type
r19:type
r20:type
r21:type
最终转化得到的文本语料如下:
gr4br3fr7egr4br3fr11jgr4br3fr12kgr5cr6hr10i......
替换成实际意义的文本语料如下:
germany-city-stuttgart-establish-porsche-manufacturer-porsche_911
germany-city-stuttgart-establish-porsche-designer-porsche_panamera
germany-city-stuttgart-establish-porsche-supplier-porsche_cayenne
germany-city-münchen-place_of_origin-bmw-manufacturer-bmw_x5
步骤1.3:语料训练
利用gensim的word2vec模型对上述步骤1.2得到的语料文本进行上下文敏感的语义学习,学习得到语料中每一个词的200维的向量,由这些向量构成了关于该语料的语义模型。通过加载该模型可以获取语料中某一个词的topk个词义最相近的相关词,构成关于这个词的相关词集合,使之可以在进行在线实时查询的时候被使用。
步骤2:在线实时查询阶段。
这个阶段包括对用户给定的sparql查询语句进行语法分析,并对其中的谓词进行适当语义扩展;然后从给定实体出发进行基于谓词语义相似度的近似迭代查询,实时获取语义近似查询结果。主要包括以下两个步骤:
步骤2.1:sparql解析
对用户给定的sparql查询语句进行语法分析,解析出用户指定实体、用户期望返回宾语的类型、用户指定的关系谓词,并根据步骤1.3中得到的语义模型计算出关系谓词的相关词,完成适当的语义扩展。在该过程中,将解析得到的结果作为输入参数代入迭代查询算法semanticapproquery进行实时计算。如说明书附图2中用户给出的sparql查询语句所表述的查询意图是想找到在德国生产的汽车,解析该sparql语句可以得出用户指定实体标记是g(germany),用户期望返回的宾语类型实体标记是o(automobile),用户指定的关系谓词是r8(location)、r11(designer)和r16(type),通过训练好的语义模型对这些谓词进行适当的语义扩展,得到r8与r4、r5、r3、r6、r9语义相关,即location与establish、place_of_origin、production等词语义相关。
步骤2.2:近似迭代查询
通过解析用户给定的sparql语句,得到主语实体、指定谓词以及宾语实体类型,为了尽可能全的找出用户希望得到的宾语实体,本发明考虑从主语实体出发,借助训练得到的语义模型获取谓词的语义相关词,在知识图谱中匹配由主语实体+相关谓词构成的子图模式,从而找到与主语实体一跳相关的宾语实体,并判断该宾语实体的类型是否属于用户指定的实体类型,若符合则加入结果集中。再从已得到的结果集中的宾语实体出发,迭代上述操作可找到与主语实体两跳相关的宾语实体结果。如此迭代查询,直到找出所有满足条件的宾语实体,再将迭代过程中记录的宾语实体拼接成一条路径,即找到指定主语实体到结果宾语的路径(实体之间用谓词连接)。具体的查询过程按semanticapproquery算法进行。在实例中如说明书附图2中的近似查询结果图所示,通过解析sparql语句以及适当语义扩展以后,从标记为g的指定实体出发,通过迭代查询,得到g到标记为o的所有路径,即找到了在德国生产的汽车有porsche_911、porsche_panamera、porsche_cayenne、bmw_x5、bmw_z4、bmw_i8等,并且找到了这些汽车与德国之间的路径关系。
- 还没有人留言评论。精彩留言会获得点赞!