一种仓库通道环境下的激光雷达数据聚类方法与流程
本发明属于移动机器人的环境建模领域,具体公开一种仓库通道环境下的激光雷达数据聚类方法。
背景技术
两侧摆放货包的仓库通道环境是仓库中的常见场景。在该环境下,机器人定位和导航的基础是建立通道场景的环境模型,货包作为环境模型中必要的组成部分,其模型的精度直接影响环境模型的准确性。而聚类算法作为提取货包模型的首要步骤,聚类的结果直接影响模型提取的准确性。因此,在仓库通道环境下对激光雷达数据进行准确聚类具有重要意义。
激光雷达的测量数据点之间存在固定偏角,但数据点之间的实际距离还取决于传感器与障碍物之间的距离。在仓库通道环境下,激光雷达对同一障碍物的不同测量角度距离会有不同的测量距离,这也导致激光雷达数据点的分散程度不同。同一类型的数据点分散程度不同导致在仓库通道环境下聚类变得难以实现。
现有聚类算法研究中,以k均值聚类和dbscan代表的密度聚类应用最为广泛。其中k均值聚类应用最为广泛,但k均值聚类算法忽略了激光雷达相邻数据点之间的关联关系,此外算法需要事先指定聚类的簇数,上述两个特点导致k均值聚类不能良好适用于仓库通道环境。dbcscan算法则使用固定阈值划分数据点,由于仓库通道环境的特点,这种聚类方式容易错误划分数据点分。
综上所述,当前聚类算法由于缺乏对通道环境以及激光雷达特点的考虑,难以适用于通道环境下激光雷达的数据聚类。因此,针对当前算法在仓库通道环境下的不足,有必要提出一种使用于仓库通道的激光雷达数据聚类算法。
技术实现要素:
有鉴于此,为了解决上述问题,本发明提供一种仓库通道环境下的激光雷达数据聚类方法。该方法易于实现、适应能力强,能够稳定准确地对通道环境下激光雷达数据点进行聚类。
为实现上述目的及其他目的,本发明提供一种仓库通道环境下的激光雷达数据聚类方法,包括以下步骤:
步骤1.初始化核心点数m和邻域大小σ;
步骤2.将测量数据点集p={p1,p2,...,pn}按照测量角度0度到180度进行排序或者角度由小到大的顺序进行排序,并将测量数据点集中所有的数据点标记为未访问的状态;
步骤3.按照顺序一次选取一个状态为未访问的数据点p,将该点的状态标记为已访问,如果此时测量数据点集中已经不存在状态为未访问的数据点,则算法终止,完成聚类;
步骤4.计算数据点p的邻域σ内是否包含m个核心点数,是则转到下一步,否则将数据点p标记为噪声点,转到步骤2;
步骤5.创建数据点p的簇c,将数据点p添加到簇c中,根据雷达散度模型计算当前阈值大小,并将阈值σ的大小设置为雷达散度模型返回值的两倍,σ=2·f(φ,θ);
步骤6.判断序列中下一个数据点q是否在数据点p的邻域内,如果不在则转到步骤2,否则将数据点q标记为已访问,如果数据点q是核心点即数据点q的邻域内包含m个数据点,则更新阈值,新的阈值大小为q处激光雷达散度模型返回值的两倍,即σ=2·f(φ,θ),此外将数据q加入簇c,转到步骤5。
优选地,
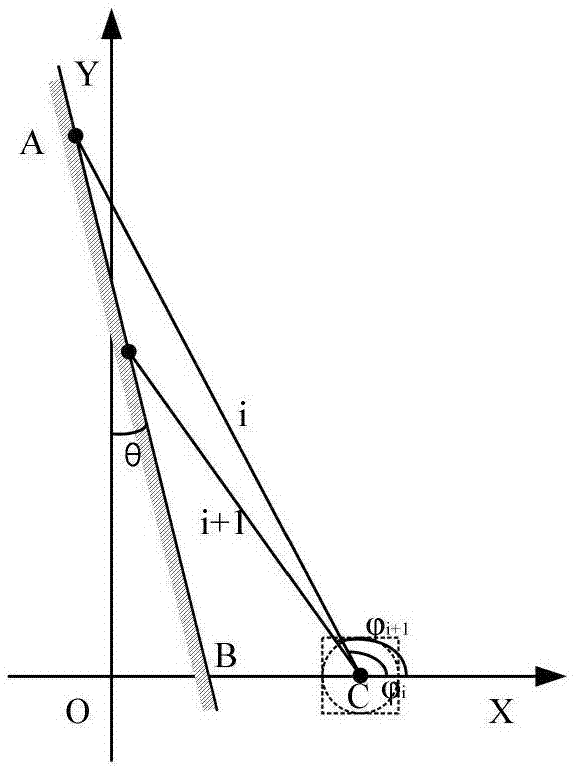
φi为激光雷达第i束光线与水平方向的角度,φi+1为激光雷达第i+1束光线与水平方向的角度,θ为障碍物与竖直方向的夹角,d为激光雷达所在位置的水平线与障碍物交点的距离。
由于采用了上述技术方案,本发明具有如下的优点:
本发有根据激光雷达原理和通道环境特征,提出了激光雷达测量散度模型;
本发明根据测量散度模型动态确定聚类划分阈值,提出自适应阈值的聚类方法。
本发明提出的聚类方法在仓库通道环境下,具有较高运行效率,并且提升了聚类算法结果的准确性。
本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
附图说明
为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步的详细描述:
图1为散度模型示意图1;
图2为散度模型示意图2;
图3为本发明的流程图。
具体实施方式
以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。
需要说明的是,本实施例中所提供的图示仅以示意方式说明本发明的基本构想,遂图式中仅显示与本发明中有关的组件而非按照实际实施时的组件数目、形状及尺寸绘制,其实际实施时各组件的型态、数量及比例可为一种随意的改变,且其组件布局型态也可能更为复杂。
本发明提供一种仓库通道环境下的激光雷达数据聚类方法,具体发明内容如下:
首先建立激光雷达测量散度模型,如图1和2所示,xoy表示当前全局坐标系,在xoy坐标系下,假设激光雷达所在位置为c,障碍物为ab且与竖直方向的夹角为θ,激光雷达第i束光线与水平方向的角度为
根据图1,当前所测距离ca以及ba可以描述为如下。
基于测量散度变阈值的聚类方法:
记激光雷达的采集的数据集为z={z1,z2,...,zn},每个数据对应激光雷达一个方向的数据,该数据表示该方向上的测量距离。将距离数据转换为直角坐标系下的数据点集,记为p={p1,p2,...,pn}。设置常数m为核心点的周围最小点数,同时定义σ为每个点邻域阈值,该值是根据散度模型来动态确定的。如图3所示,考虑散度模型的变阈值聚类方法具体步骤如下:
步骤1.初始化核心点数m和邻域大小σ为默认值;
步骤2.将测量数据点集p={p1,p2,...,pn}按照测量角度0度到180度进行排序或者角度由小到大的顺序进行排序,同时并将点集中所有的数据点标记为未访问的状态;
步骤3.按照顺序一次选取一个状态为未访问的数据点p,将该点的状态标记为已访问,如果此时点集中已经不存在状态为未访问的数据点,则算法终止,完成聚类;
步骤4计算测量数据点p的邻域σ内是否包含m个点,是则转到下一步,否则将数据点p标记为噪声点,转到步骤2;
步骤5.创建测量数据点p的簇c,将测量数据点p添加到簇c中,根据测量散度模型计算当前阈值大小,并将阈值σ的大小设置为模型返回值的两倍,如下式所示:
σ=2·f(φ,θ)
步骤6.判断序列中下一个数据点q是否在数据点p的邻域内,如果不在则转到步骤2,否则将数据点q标记为已访问,如果数据点q是核心点即数据点q的邻域内包含m个数据点,则更新阈值,此外将数据点q加入簇c,转到步骤5。
最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本技术方案的宗旨和范围,其均应涵盖在本发明的保护范围当中。
- 还没有人留言评论。精彩留言会获得点赞!