面向法制相关文本的判别方法与流程
本发明属于自然语言处理领域,具体涉及一种面向法制相关文本的判别方法。
背景技术
2017年12月14日,工业和信息化部印发了《促进新一代人工智能产业发展三年行动计划(2018-2020年)》,行动计划中,明确提出“面向语音识别、视觉识别、自然语言处理等基础领域及工业、医疗、金融、交通等行业领域,支持建设高质量人工智能训练资源库、标准测试数据集并推动共享。”
也就是说,国家将在未来的若干年中,继续大力扶持人工智能相关产业,其中也包括了基础领域的自然语言处理的研究。而本文所研究的面向法制相关话题的文本判别技术与此政策中的相关领域相契合,利用人工智能中的自然语言处理和机器学习,运用到法制话题的判别中,以更好地在法制类研究中节约时间以及完成更多更复杂的分析工作。与此同时,这个技术研究也很容易移植到其他话题的判别研究中。
因此,本文研究的法制类相关话题的文本判别技术顺应了国家发展人工智能的发展需要。文本判别在很多领域都能有重要的作用,它可以帮助我们对于文本进行分析,快速准确地确定文本的中心,帮助人们归纳和更好地提取和利用有用的信息,同时也在其他领域有所应用。本文的主要研究就是利用了自然语言处理对于语料库中的文本进行处理,利用机器学习对于处理好的数据进行学习训练,最终实现文本判别程序。因此,本文研究的很多内容在当今科技的发展和未来的发展趋势中,都有着重要的意义。
技术实现要素:
本发明的目的在于提供一种面向法制相关文本的判别方法,利用机器学习对于处理好的数据进行学习训练,最终实现法制相关文本的判别。
为实现上述目的,本发明的技术方案是:一种面向法制相关文本的判别方法,包括如下步骤:
步骤s1、利用爬虫在互联网上爬取法制相关文本,构建法制相关语料库;
步骤s2、对法制相关语料库中的语料标注关联度,并且利用结巴分词技术及tf-idf关键词技术对每条语料进行分词,统计得到关键词;
步骤s3、利用关键词生成文本特征向量;
步骤s4、对文本特征向量进行机器学习并生成对应的分类模型;
步骤s5、最后利用分类模型对互联网上文本进行判别。
在本发明一实施例中,所述步骤s1中,爬取法制相关文本后,首先,需对爬取法制相关文本进行包括网址、乱码信息的无用数据的清洗;而后,对法制相关文本聚类分析并得到三个子话题,并给出4个相关度等级;再而,根据子话题相关度对法制相关文本逐一标注;最后,得到法制相关语料库。
在本发明一实施例中,所述三个子话题分别为权力、制度、监督。
在本发明一实施例中,所述步骤s2中,对语料进行分词的过程中,仅选择至少与一个子话题的关联度在2以上的语料进行。
在本发明一实施例中,所述步骤s2中,统计得到关键词的方式为:首先,每条语料提取其中的前10个关键词,将所有语料提取出的关键词形成一个列表;而后,将列表中所有提取出来的关键词根据在列表中的出现词数进行词频统计和排序,再而,将其中的包括停用词和英文字母的无效的关键词删去;最后,排列出词频在前200的关键词,并按照出现的词数形成一个新的关键词列表。
在本发明一实施例中,所述步骤s3的具体实现过程如下:
步骤s31、将法制相关语料库中的语料文本信息向量化,得到文本向量;
步骤s32、文本向量的每行是原先选择好的所有语料的信息,其具体的构造方法为,前200列中,每一个位置体现的是该列上的关键词在该行的语料文本中是否出现,若出现则该位置的值为1,若没有出现则该位置的值为0;
步骤s33、将每条语料与三个子话题的关联度标注合并进文本向量,构成文本特征向量。
在本发明一实施例中,所述步骤s4中,采用支持向量机算法、朴素贝叶斯算法以及决策树算法对文本特征向量进行机器学习并生成对应的分类模型。
在本发明一实施例中,采用支持向量机算法对文本特征向量进行机器学习并生成对应的分类模型的具体过程如下:
步骤s81、加载法制相关语料库并将文本特征向量拆分为x数组与y数组;
步骤s82、对法制相关语料库进行随机划分,训练集和测试集的比例为8:2;
步骤s83、采用线性核函数,将惩罚因子设置为0.05;
步骤s84、对分类模型进行训练和测试;
步骤s85、保存训练后的分类模型。
在本发明一实施例中,采用朴素贝叶斯算法对文本特征向量进行机器学习并生成对应的分类模型的具体过程如下:
步骤s91、加载法制相关语料库并将文本特征向量拆分为x数组与y数组;
步骤s92、对法制相关语料库进行随机划分,训练集和测试集的比例为8:2;
步骤s93、选用伯努利朴素贝叶斯算法;
步骤s94、对分类模型进行训练和测试;
步骤s95、保存训练后的分类模型。
在本发明一实施例中,采用决策树算法对文本特征向量进行机器学习并生成对应的分类模型的具体过程如下:
步骤s101、加载法制相关语料库并将文本特征向量拆分为x数组与y数组;
步骤s102、对法制相关语料库进行随机划分,训练集和测试集的比例为8:2;
步骤s103、选用决策树算法;
步骤s104、对分类模型进行训练和测试;
步骤s105、保存训练后的分类模型。
相较于现有技术,本发明具有以下有益效果:本发明利用机器学习对于处理好的数据进行学习训练,最终实现法制相关文本的判别。
附图说明
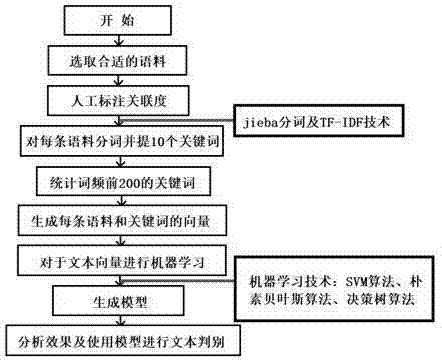
图1为本发明文本处理及分类器建模流程图。
图2为本发明语料库构建流程图。
具体实施方式
下面结合附图,对本发明的技术方案进行具体说明。
本发明提供了一种面向法制相关文本的判别方法,包括如下步骤:
步骤s1、利用爬虫在互联网上爬取法制相关文本,构建法制相关语料库;
步骤s2、对法制相关语料库中的语料标注关联度,并且利用结巴分词技术及tf-idf关键词技术对每条语料进行分词,统计得到关键词;
步骤s3、利用关键词生成文本特征向量;
步骤s4、对文本特征向量进行机器学习并生成对应的分类模型;
步骤s5、最后利用分类模型对互联网上文本进行判别。
所述步骤s1中,爬取法制相关文本后,首先,需对爬取法制相关文本进行包括网址、乱码信息的无用数据的清洗;而后,对法制相关文本聚类分析并得到三个子话题(权力、制度、监督),并给出4个相关度等级;再而,根据子话题相关度对法制相关文本逐一标注;最后,得到法制相关语料库。
所述步骤s2中,对语料进行分词的过程中,仅选择至少与一个子话题的关联度在2以上的语料进行。所述步骤s2中,统计得到关键词的方式为:首先,每条语料提取其中的前10个关键词,将所有语料提取出的关键词形成一个列表;而后,将列表中所有提取出来的关键词根据在列表中的出现词数进行词频统计和排序,再而,将其中的包括停用词和英文字母的无效的关键词删去;最后,排列出词频在前200的关键词,并按照出现的词数形成一个新的关键词列表。
所述步骤s3的具体实现过程如下:
步骤s31、将法制相关语料库中的语料文本信息向量化,得到文本向量;
步骤s32、文本向量的每行是原先选择好的所有语料的信息,其具体的构造方法为,前200列中,每一个位置体现的是该列上的关键词在该行的语料文本中是否出现,若出现则该位置的值为1,若没有出现则该位置的值为0;
步骤s33、将每条语料与三个子话题的关联度标注合并进文本向量,构成文本特征向量。
所述步骤s4中,采用支持向量机算法、朴素贝叶斯算法以及决策树算法对文本特征向量进行机器学习并生成对应的分类模型。
采用支持向量机算法对文本特征向量进行机器学习并生成对应的分类模型的具体过程如下:
步骤s81、加载法制相关语料库并将文本特征向量拆分为x数组与y数组;
步骤s82、对法制相关语料库进行随机划分,训练集和测试集的比例为8:2;
步骤s83、采用线性核函数,将惩罚因子设置为0.05;
步骤s84、对分类模型进行训练和测试;
步骤s85、保存训练后的分类模型。
采用朴素贝叶斯算法对文本特征向量进行机器学习并生成对应的分类模型的具体过程如下:
步骤s91、加载法制相关语料库并将文本特征向量拆分为x数组与y数组;
步骤s92、对法制相关语料库进行随机划分,训练集和测试集的比例为8:2;
步骤s93、选用伯努利朴素贝叶斯算法;
步骤s94、对分类模型进行训练和测试;
步骤s95、保存训练后的分类模型。
采用决策树算法对文本特征向量进行机器学习并生成对应的分类模型的具体过程如下:
步骤s101、加载法制相关语料库并将文本特征向量拆分为x数组与y数组;
步骤s102、对法制相关语料库进行随机划分,训练集和测试集的比例为8:2;
步骤s103、选用决策树算法;
步骤s104、对分类模型进行训练和测试;
步骤s105、保存训练后的分类模型。
以下为本发明的具体实施过程。
图1为文本处理及分类器建模流程图,首先选择合适的语料并进行人工标注关联度,并且利用中文分词及tf-idf技术对每条语料进行分词,统计得到关键词。利用关键词组生成每条语料和关键词的特征向量。对于文本特征向量进行机器学习并生成对应的分类模型。本发明最终能够利用模型对文本进行判别。
1、构建语料库
图2给出了构建语料库的流程图,根据对爬取文本的聚类分析,得出三个子话题“权力”、“制度”与“监督”。语料库为利用爬虫在互联网上各大论坛爬取并筛选后所得,主要是与法制话题相关的文本。将爬取后的文本根据子话题与4个相关度等级进行标注。
(1)选择合适的、活跃用户较多的论坛进行文本爬取
(2)爬取得到的文本都是无结构的,需要对它们进行处理,把网址、乱码信息等无用数据清洗掉。
(3)将文本聚类分析并得到三个子话题,并给出4个相关度等级。
(4)根据子话题相关度对文本逐一标注。
通过上述步骤便可得到文本处理的语料库。
2、特征抽取
本发明采用基于特征向量的机器学习方法来进行关系抽取。机器学习算法采用特征向量作为处理对象,所以需要将实验语料处理成特征向量的形式,然后才能用于各种机器学习算法。
以下是具体对这些特征的抽取方法:
(1)使用“结巴”分词技术和tf-idf关键词提取技术,对于与法制类相关的文本语料进行关键词提取。
(2)为了保证结果的更加准确,只选择至少与一个子话题的关联度在2以上的语料进行
(3)对于筛选过后的语料,每一条语料提取其中的前10个关键词,最后将所有语料提取出的关键词形成一个列表。
(4)将列表中所有提取出来的关键词根据在列表中的出现词数进行词频统计和排序,然后将其中的停用词和英文字母等无效的关键词删去。
(5)排列出词频在前200的关键词,并按照出现的词数形成一个新的关键词列表。
3、构造特征向量
本发明采用基于特征向量的机器学习方法来进行关系抽取。机器学习算法采用特征向量作为处理对象,所以需要将实验语料处理成特征向量的形式,然后才能用于各种机器学习算法。于是这部分工作就是将上述步骤中抽取得到的特征将其数字化,构造特征向量。
(1)对于语料最终的一个处理工作就是将文本信息向量化,使其成为一个固定的格式,让机器来识别和进行学习。
(2)文本向量的每行是原先选择好的所有语料的信息,具体的构造方法为,前200列中,每一个位置体现的是该列上的关键词在该行的语料文本中是否出现,若出现则该位置的值为1,若没有出现则该位置的值为0。
(3)将之前已经进行过的每条文本关于三个子话题的关联度标注合并进去构成该文本的特征向量。
4、分类器学习
本发明采用基于特征向量的有监督学习方法对法制相关文本进行分类。使用支持向量机(svm)算法、朴素贝叶斯算法以及决策树算法进行模型的训练。
其中支持向量机算法模型训练过程如下:
(1)加载语料库并将特征向量拆分为x数组与y数组。
(2)对语料库进行随机划分,训练集和测试集的比例为8:2。
(3)采用线性核函数,将惩罚因子设置为0.05。
(4)对模型进行训练和测试。
(5)保存训练后的模型
朴素贝叶斯算法模型训练如下:
(1)加载语料库并将特征向量拆分为x数组与y数组。
(2)对语料库进行随机划分,训练集和测试集的比例为8:2。
(3)选用伯努利朴素贝叶斯算法
(4)对模型进行训练和测试。
(5)保存训练后的模型
决策树算法模型训练如下:
(1)加载语料库并将特征向量拆分为x数组与y数组。
(2)对语料库进行随机划分,训练集和测试集的比例为8:2。
(3)选用决策树算法
(4)对模型进行训练和测试。
(5)保存训练后的模型
以下为本发明的具体实施例。
本实例主要是根据前述对于文本的处理而生成的文本空间向量,来进行机器学习,并且对于机器学习的结果进行效果分析。
本实施实例的数据集为利用爬虫在互联网上采集处理后的数据集,其中共有1000条文本。在标注时,一共有4档评分,为0~3,其中0为无关,分数按照相关度递增,3为非常相关。为了证明本发明的算法优点,对上述数据集在三个分类模型下分别进行了训练测试,以下将逐一给出实验结果并分析。
表1,表2,表3分别表示了使用svm方法训练出的“权力”“制度”“监督”三个子话题模型测试时的精确率等参数指标。整体上来看,svm方法训练出来的模型,效果大约接近百分之七十,可以达到较好的预测分类效果。
表4,表5,表6分别表示了使用伯努利朴素贝叶斯方法训练出的“权力”“制度”“监督”三个子话题模型测试时的精确率等参数指标。整体上来看,朴素贝叶斯算法训练出来的模型,效果大约在百分之六十左右,效果低于svm算法,但百分之六十左右的效果也可以达到一定的预测分类效果。
监督”三个子话题模型测试时的精确率等参数指标。整体上来看,决策树算法训练出来的模型,效果大约在百分之七十左右,与svm算法比较好,决策树算法也可以达到比较理想的预测分类效果。
以上是本发明的较佳实施例,凡依本发明技术方案所作的改变,所产生的功能作用未超出本发明技术方案的范围时,均属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!