一种基于强化学习的P2P网络借贷机构风险评估方法与流程
本发明涉及网络大数据处理及电子信息技术,具体涉及一种基于强化学习的p2p网络借贷机构风险评估方法。
背景技术:
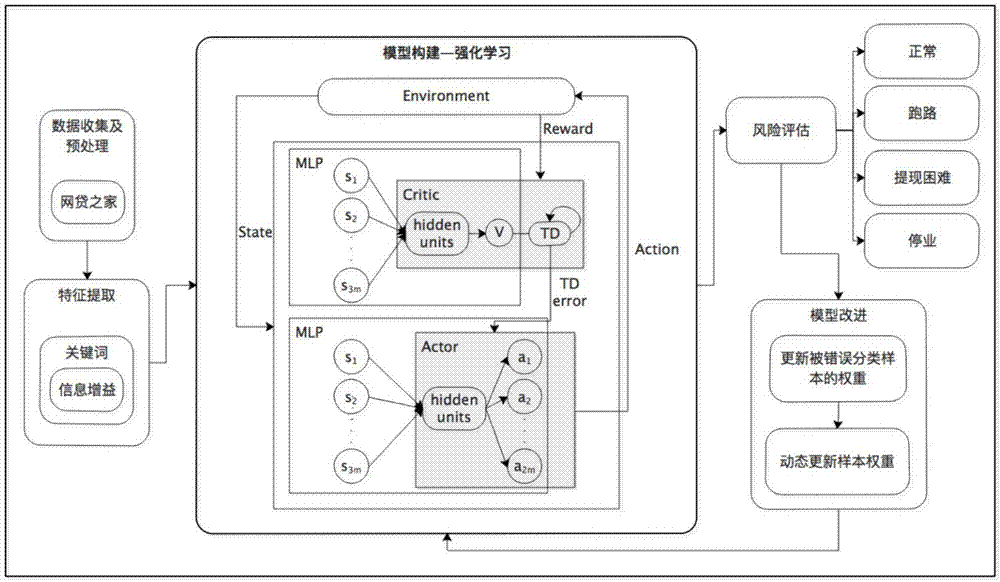
:p2p(peer-to-peer,个人对个人或是伙伴对伙伴)网络借贷是指通过在线服务向个人或企业贷款,它向借贷者直接匹配贷款人,通过网上交易,p2p网贷使得无需通过任何传统的金融中介机构的微型金融成为可能[1]。近年来,p2p网络借贷在全球尤其是中国发展迅速,其中,p2p网络借贷机构为借款人和贷款人提供交易平台[2]。自2008年第一个中国p2p平台—拍拍贷成立以来,越来越多的p2p网络借贷公司涌现出来。根据第三方网络借贷平台网贷之家(http://shuju.wdzj.com/industry-list.html,简称“hnl”)的统计,已经有超过4000家中国p2p网贷公司。但随着p2p借贷公司的快速发展,这些公司的风险也逐渐暴露出来。例如,宣称用户数超过2亿,营业额超过500亿的钱宝网在2017年8月坐实跑路。p2p网络借贷机构的风险通常会给投资人造成一些损失。因此,加强对这些机构的监督和实现风险的自动评估是很有必要的。在网络大数据时代,由于数据量很大,并且非结构化的自然语言文本信息很多,传统的数据收集和分析方法用于监管和风险分析,不仅耗时费力,并且无法适应数据的增长速度。因此,探索使用机器学习[3]的方法完成基于非结构化自然语言文本信息的企业风险的自动评估具有重要的理论意义和应用价值。此外,p2p网络借贷是一种新型的金融业务模式,目前可用的数据较少,且各类数据不平衡,未来将继续增长和变化,传统的监督学习方法无法很好的适应。在机器学习、深度学习领域,与其它技术相比,强化学习具有对环境先验知识要求低、自学习能力强等特点,使其成为近几年十分热门的一个分支。尽管强化学习在很多领域应用中已经取得了突破性的进展,但在企业风险评估分析方面的应用却很少见到。目前为止,关于p2p风险方面的研究主要集中在如何评估借款人的信用风险和违约风险[4],只有较少的研究涉及p2p中介机构风险[5]。而机器学习在金融风险评估方面的应用还处于初期阶段,bao等[6]利用lda主题模型在公司年度报告的文字风险披露中发现和量化风险类型;yuan等[7]使用潜在语义模型预测众筹项目的筹资结果。强化学习已经应用在很多领域,如机器人的智能学习[8]、自动化控制[9]、游戏比赛[10]等。而在金融领域,对强化学习的研究主要集中在股票市场,deng等提出了一种深度强化学习框架来进行金融信号处理和在线交易。通过以上研究发现,p2p网络借贷的问题主要是缺乏对平台风险的关注以及缺乏自动风险评估方法。传统评估方法多是基于各种数值型结构化数据进行的,就p2p网络借贷风险评估这个问题,通过调查发现,有一个重要的问题就是数据受限,全国只有这些数据,不同风险类别之间数据极不平衡,随着时间的推移,很多公司的风险状况会很快发生改变,甚至倒闭。这就要求评估方法不能太受数据影响,具有较好的泛化能力,但这些恰是传统基于机器学习的分类方法的弱点,传统方法更多依赖于数据量和特征抽取。参考文献:[1]hongkezhao,yongge,qiliu,etal.p2plendingsurvey:platforms,recentadvancesandprospects[j].acmtransactionsonintelligentsystems&technology,2017,8(6):72.[2]ohavrylchyk,mverdier.thefinancialintermediationroleofthep2plendingplatforms[j].comparativeeconomicstudies,2018(3):1-16.[3]mitchell,t.m.:machinelearning,1stedn.mcgraw-hillinc.,newyork(1997)[4]emekterr,tuy,jirasakuldechb,etal.evaluatingcreditriskandloanperformanceinonlinepeer-to-peer(p2p)lending[j].appliedeconomics,2015,47(1):54-70.[5]yany,lvz,hub.buildinginvestortrustinthep2plendingplatformwithafocusonchinesep2plendingplatforms[j].electroniccommerceresearch,2017(2):1-22.[6]baoy,dattaa,sciencem.simultaneouslydiscoveringandquantifyingrisktypesfromtextualriskdisclosures[j].managementscience,2014,60(6):1371-1391.[7]yuanh,lauryk,xuw.thedeterminantsofcrowdfundingsuccess:asemantictextanalyticsapproach[j].decisionsupportsystems,2016,91:67-76.[8]cuiy,matsubarat,sugimotok.kerneldynamicpolicyprogramming:applicablereinforcementlearningtorobotsystemswithhighdimensionalstates.[j].neuralnetworkstheofficialjournaloftheinternationalneuralnetworksociety,2017,94:13.[9]kangdh,bongjh,parkj,etal.reinforcementlearningstrategyforautomaticcontrolofreal-timeobstacleavoidancebasedonvehicledynamics[j].journalofkorearoboticssociety,2017,12(3):297-305.[10]andradeg,ramalhog,santanah,etal.extendingreinforcementlearningtoprovidedynamicgamebalancing[c]//theworkshoponijcaiworkshoponreasoning.2005:7-12.技术实现要素:本发明针对目前p2p网络借贷风险评估存在的数据有限,需要一种泛化能力好的分类方法的问题,提供了一种基于强化学习的p2p网络借贷机构风险评估方法。本发明采用强化学习模型来评估p2p网络借贷风险,并针对强化学习模型的训练很耗时的问题,提出一种动态更新样本权重的方法,以加快模型训练过程使其更快地收敛。本发明的一种基于强化学习的p2p网络借贷机构风险评估方法,包括如下步骤:步骤1,采集p2p网贷企业的公司简介文本信息,进行分词;步骤2,对所有文档的词,使用信息增益提取关键词,设选定m个关键词,为每篇文档构造一个m维的特征向量;特征向量中的每一维代表了所对应的关键词在文档中是否出现,若出现,则取值为1,否则取值为0;m为正整数;步骤3,使用max-minacla算法构造强化学习模型;所述的强化学习模型中,将文档的特征向量作为输入向量,将p2p网贷企业的风险类别作为目标类别,为每个目标类别构建一个代理agent,每个agent接收三个桶作为状态向量,每个桶的大小与输入向量相同,第一个桶是输入向量的副本,第二个桶初始化为零向量,第三个桶初始化为输入向量;步骤4,在强化学习模型的训练过程中,采用动态改变权重的方法更新样本权重;所述的动态改变权重的方法是:当前迭代到设定次数时,计算当前模型的正确率acccur,与上次更新权重时的模型正确率accpre比较,若accpre-acccur>5%,则将样本权重重新被设置成相同的,否则,样本权重继续按照之前的策略更新;步骤5,利用训练好的强化学习模型对待评估机构进行风险评估;提取待评估机构的公司简介文本信息,进行分词,为评估机构构造步骤2所述的m维的特征向量,将该特征向量输入训练好的强化学习模型,获得风险评估结果。本发明的优点与积极效果在于:本发明提出了一种新颖的强化学习方法来自动地评估p2p网络借贷机构的风险,采用了强化学习模型来解决文本分类数据少且数据不平衡的问题,实验结果显示本发明方法较传统的机器学习方法相比有较好的效果,同时不需要进行欠采样等处理就可以解决数据不平衡的问题,评估结果比较准确,对投资者和监管者具有一定的参考价值。除此之外,本发明提出的动态更新样本权重的方法可以大大加快模型训练的收敛速度,节省了大量时间,使其具有更强的实用性。并且,本发明针对公司简介文本提取关键词特征,非常易于实现。附图说明图1是本发明的p2p网络借贷机构风险评估方法的实现框架示意图;图2是本发明采用基础强化学习模型实验结果示意图;图3是本发明在采用更新样本权重实验结果的示意图;图4是本发明采用动态更新样本权重实验结果示意图。具体实施方式下面将结合附图和实施例对本发明作进一步的详细说明。本发明采用的基于强化学习的p2p网络借贷机构风险评估方法,更加注重非结构化数据,目前只针对公司简介这样的文本内容进行了处理,希望从中挖掘更多的语义信息来进行风险评估。针对数据有限,不同风险类别之间数据极不平衡的问题,本发明找到了强化学习方法,实验发现该方法具有应对上述问题的潜力。对目前文献调研,当前强化学习在游戏、对话这种互动型任务中应用普遍,但在文本分类中的应用很少,主要原因在于对于任务的描述比较困难,状态、动作与环境这些基本元素的描述都是困难的。本发明找到了一种可用的方法,对在多次真实数据的实验的基础上,创新地提供了一种动态更新样本权重的方法,解决强化学习过程太慢的问题,实验证明,可以将强化学习时间缩短十倍,性能仍然能够保持较高的水平。本发明提出的风险评估方法,整体实现框架如图1所示,根据网贷之家的统计,p2p网贷机构风险主要可分为四种:正常、跑路、提现困难和停业。风险评估的实质就是将p2p企业分到这四类中的一类。下面对实现的流程进行详细说明。步骤一,数据收集及预处理。原始数据是通过爬虫从网贷之家上爬取的,包含p2p网贷企业的众多文本及数值信息,本发明主要使用公司简介这一文本信息。首先,对公司简介使用结巴分词工具包进行分词处理,然后,进行去停用词、词频统计等预处理。结巴分词工具包参见网页https://pypi.python.org/pypi/jieba/。步骤二,特征提取。本发明方法主要使用的是关键词特征,使用信息增益来提取关键词。首先,对所有文档的词,计算每个词的信息增益值,并根据信息增益值排序,选出值较高的一些关键词。预设一个变量m,m为正整数,选取所有文档组成的词中信息增益最大的前m个词作为关键词。然后,在选定m个关键词后,为每篇文档构造一个m维的特征向量。在本发明方法中,将m从10取到60来确定最优的取值,对于一篇文档的m维特征向量,每一维代表了这一维对应的关键词在这篇文档中是否出现,若出现,则这一维值为1,否则值为0。一个企业的公司简介文本信息为一篇文档,对应有一个m维特征向量。步骤三,模型构建。本发明使用max-minacla(actor-criticlearningautomaton)算法来构造基础的强化学习模型,该算法是acla算法的一个延展,它结合了多层感知机(mlp)并且能够解决分类问题。假设数据集d={(x1,y1),(x2,y2),…,(xn,yn)},包含n个样本,其中xi为第i个样本的特征向量,yi是它的目标类别,yi∈{0,1,…,n-1},n是类别总数,本发明n是4,分别代表四种p2p网贷机构风险。max-minacla算法为每个目标类别构建一个代理agent,对于每个训练样本,与该训练样本类别相同的agent会选择动作来使它获得的奖励最大化,而具有其他类别的agent会选择动作来使它获得的奖励最小化。每个agent接收三个桶作为状态向量,每个桶的大小与输入向量xi相同。第一个桶是xi的副本,这样agent就可以知道原始输入;第二个桶初始化为零向量,这些零可以被agent设置成输入向量的副本;第三个桶初始化为输入向量并且可以被agent设置成0。该算法的马尔科夫决策过程(mdp)如下定义:状态集s:通常是连续的,对于长度为m的输入向量xi,状态si∈s包含3m个元素。这些元素被分成三个桶,st表示单次迭代中t时刻的状态向量,对于输入向量xi,初始状态其中三个桶的大小均为m。动作集a:共有2m个动作,每个动作可设置其对应的桶元素的值,at表示t时刻选择的动作。包含多个操作o(s,a)的转移函数集合t:下一时刻状态st+1=o(st,at),其中操作o按如下规则执行动作:如果动作满足0≤at<m,那么将第(m+at)个桶元素设置成输入向量的第at个元素的值;如果动作满足m≤at<2m,那么将第(m+at)个桶元素设置成0。即时奖励r:它与状态向量中0的个数有关,t时刻的即时奖励其中z表示状态向量中0的个数。折扣因子γ。单次迭代中,执行动作的次数h。用来说明agent的代表类别与训练样本的类别是否相同的标记,该标记决定了agent应该最大化还是最小化它的即时奖励。在训练过程中,agent与训练样本进行交互,每个agent执行h个动作,并且从观察到的状态转移和获得的即时奖励中学习。状态值函数(critic)和挑选动作的功能函数(actor)分别使用一个不同的mlp来表示。为了减少参数的数量,将两个mlp的隐含层节点个数和学习速率设成相同的,其中隐含层节点个数为11,学习速率为0.03。假设vj(·)表示类别j的agentacj的值函数,acj在状态st执行完动作后,将收到(st,at,rt,st+1),使用tderrorδt来更新值函数vj(st):δt=rt+γvj(st+1)-vj(st)vj(st)=vj(st)+αδt其中,α是critic的学习速率,若样本类别y=j,则acj选择动作的mlp的目标值为:这样,acj可以最大化即时奖励来学习更高的状态值函数。若样本类别y≠j,则acj选择动作的mlp的目标值为:这样,对于类别不相同的样本,acj将会得到负的即时奖励,并且这些奖励将会td(temporal-difference)学习传递给初始状态的值函数。在测试阶段,agent不需要选择动作。首先对所有类别j的acj计算值函数vj(s0),输入样本将会被预测为具有最大值函数的agent代表的类别yp:步骤四,模型改进。实验结果显示由于多层感知机的引入,强化学习模型的训练过程比其他算法慢了很多。为了加速模型的训练,本发明借鉴了adaboost算法[参考文献11:g,onodat,müllerkr.softmarginsforadaboost[j].machinelearning,2001,42(3):287-320.]中改变样本权重的方法,即在之前的学习中被错误分类的样本的权重会更大。在本发明方法中,所有样本权重初始化为相同的,然后每20000次迭代,更新一次样本权重。实验结果显示该方法可以加速模型的训练,但模型的正确率在到达峰值后会开始下降。因此,本发明改进了该方法,提出了一种动态改变权重的方法,即在更新权重之前,比较当前模型的正确率acccur和上次更新权重时模型的正确率accpre,若accpre-acccur>5%,则样本权重重新被设置成相同的,否则,样本权重继续按照之前的策略更新。动态更新样本权重的算法伪代码如下:上面动态更新样本权重的过程中,初始化样本的权重为相同的,均为1/n;当前迭代达到20000次时,计算当前模型的正确率acccur,与上次更新权重时的模型正确率accpre比较,若accpre-acccur>5%,则样本权重重新被设置成相同的,均为1/n。否则,样本权重继续按照之前的策略更新,计算当前模型的错误率errorrate,上面i(yi≠y(xi))表示模型的预测结果与真实结果不同的样本个数,设置更新第i个样本的权重为在更新完样本权重后,将accpre更新为当前模型的正确率acccur的值。步骤五,风险评估。在构建强化学习模型后,使用提取的关键词特征来进行风险评估。下面通过实验来验证本发明方法。实验设计:本发明使用公司简介信息来进行p2p网贷企业风险评估。实验数据规模如表1所示,可以看出数据量较小且各类数据较不平衡。实验中将数据按照7∶3的比例分为训练集和测试集,每类数据大体上保持了在总体数据中所占的比例。在分类中,0代表正常,1代表停业,2代表提现困难,3代表跑路。表1实验数据规模类别数量正常(0)1849停业(1)1263提现困难(2)595跑路(3)847总体4554首先使用基础的强化学习模型和关键词特征来对p2p网贷机构进行分类,然后使用通过更改样本权重改进的强化学习模型重新进行实验。除此之外,实验中还使用了传统的有监督机器学习方法做相同的实验来进行对比,如支持向量机(svm)、逻辑回归(lr)、mlp、朴素贝叶斯和决策树。本发明使用的效果衡量指标定义如下:accuracy=(tp+tn)/(tp+fp+tn+fn)×100%precision=tp/(tp+fp)×100%recall=tp/(tp+fn)×100%f1=(2×precision×recall)/(precision+recall)其中,tp表示被正确分类的正例的数量,fp表示被错误分类的负例的数量,tn表示被正确分类的负例的数量,fn表示被错误分类的正例的数量。上面四个指标值越高代表效果越好。上述效果衡量指标可参见参考文件12:[12]dengy,baof,kongy,etal.deepdirectreinforcementlearningforfinancialsignalrepresentationandtrading.[j].ieeetransactionsonneuralnetworks&learningsystems,2016,28(3):653-664.实验结果说明如下:(1)使用基础的强化学习模型实验:不同关键词个数实验的训练集正确率结果如图2所示,其中横轴表示迭代次数,纵轴表示正确率,不同颜色的曲线表示不同的关键词个数。模型收敛后测试集的最优结果(关键词个数为40时取得最优解)如表2所示。表2测试集最优结果类别precisionrecallf1-score数量00.83130.93190.878751310.66400.66930.666740020.74470.40460.524319830.65820.67240.6652256avg0.74510.74910.73951367从表2可以看出,提现困难(2)一类的准确率比停业(1)和跑路(3)的准确率高,这说明本发明提出的强化学习模型较少受到数据不平衡的影响并且能够正确识别出数量较少一类的样本,而常见的有监督机器学习算法,如决策树、逻辑回归等,通常对数据不平衡较为敏感。然而,如图2所示,本模型需要训练几十万次才会收敛,使得模型的效率不高。因此,为了解决这个问题,利用本发明提出了更改样本权重的方法,并用改进的强化学习模型重新实验。图2~图4中,横坐标表示训练次数times,纵坐标表示模型正确率accuracy,图中的每条线型代表关键词个数m的取值,依次取值为10,20,30,40,50和60。(2)更新样本权重的改进强化学习模型实验:首先,本发明尝试每20000次迭代更新一次样本权重,即增加被错误分类样本的权重,使其在下次迭代中被选中的概率增大。训练集的正确率如图3所示。可以看出,在更新样本权重之后,收敛的速度比之前快了很多。但是最高正确率比之前稍低了一些并且随着迭代次数的不断增加正确率开始下降。出现这一现象的原因可能是在更新样本权重的过程中,某些样本的权重不断的增加,导致模型大多数情况下只训练这部分样本。为了避免这一问题,本发明尝试调整策略,来动态的更新样本权重并且重新进行实验。动态更新样本权重的改进强化学习模型实验:不同于上个实验,本实验计算当前模型的正确率acccur并在更新样本权重之前将其记录下来,如果上次更新前的正确率accpre-acccur>5%,那么样本权重重新被设置成相等的,否则,样本权重按照之前的策略更新。训练集正确率如图4所示。实验结果显示,正确率下降的现象得到了缓解并且正确率也比按照同一策略更新样本权重的实验高了一些。同时,模型的收敛速度比基础强化学习模型快了很多,同时也比按照同一策略更新样本权重的模型快。(3)使用传统有监督机器学习方法的对比实验:除了上述本发明提出的三种模型,还使用几种传统的机器学习算法做了相同的实验。结果如表3所示,rl表示强化学习模型。本发明选择准确率作为主要的衡量标准,以更加有把握的找出有风险的机构并降低误判的风险。表3不同模型的准确率实验结果显示强化学习模型优于大多数传统机器学习模型。虽然动态更新样本权重的强化学习模型的准确率稍低于基础强化学习模型,但它节省了大量的时间,更加具有实用性。对于一般模型,准确率受到数据不平衡的影响,数据量大的类别准确率高,数据量小的类别准确率低。对于本发明数据量小的应用场景,本发明所提供的模型较少受到数据不平衡的影响,使得数据量小的类别准确率与数据量大的类别准确率相差不大,同时总体准确率达到平均以上的水平。显然,所描述的实施例也仅仅是本发明的一部分实施例,而不是全部实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1