中文自然语言实体语义关系的自动辨识算法的制作方法
本发明属于自然语言的识别和机器学习技术领域,具体涉及一种中文自然语言实体语义关系的自动辨识算法。
背景技术
近年来,随着互联网的发展,网络数据内容呈现爆炸式增长的态势。由于互联网内容的大规模、异质多元、组织结构松散的特点,给人们有效获取信息和知识提出了挑战。知识图谱(knowledgegraph)以其强大的语义处理能力和开放组织能力,为互联网时代的知识化组织和智能应用奠定了基础。
具体说来,知识图谱旨在描述真实世界中存在的各种实体(概念)及其关系,进而构成一张巨大的语义网络图,图中以节点表示实体(概念),边则由属性或关系构成。现在的知识图谱已被用来泛指各种大规模的知识库。
大规模知识图谱的构建,作为知识图谱的起步,在学术界和工业界引起了足够的注意力。其中,知识提取技术则是知识图谱构建的第一步。而知识提取技术常常要求从一些公开的、非结构化的文本中提取出实体、关系、属性等知识要素。
在中文知识图谱的构建中,非结构化的文本常常表现为中文自然语言文本。这样,中文自然语言的理解就成构建中文知识图谱的重要工具。到目前为止,在中文自然语言的理解方面已经取得了许多成绩。例如中文自然语言的自动分词、词性标注、句法分析、实体提取等等,国内外都有许多软件可以支持。尽管这些技术从很大程度上加强了中文知识图谱的构建,但是到目前为止,如何辨识实体之间的关系仍然是中文自然语言理解中一个没有解决的关键问题,也是阻碍中文知识图谱构建的关键技术。
为了进一步理解这个关键技术,需要先来理解知识图谱中实体的概念。在知识图谱中,实体可以是一个实实在在存在的事物,比如一个人、一本书、一个建筑物等等。同时,实体也可以是一个抽象的概念,比如说马克思主义。中文自然语言的处理工具已经可以从中文自然语言文本中辨识实体,这些可以辨识的实体包括人、时间、地点、组织等等。但是,中文自然语言的处理工具没有办法辨识这些实体之间的关系,而实体之间的关系的辨别是构造中文知识图谱的关键环节。
例如在一个中文自然语言的文本中,利用自然语言的处理工具辨识出“美国网球公开赛”(事件)和“纽约”(地点)这两个实体,但是“美国网球公开赛”和“纽约”这两个实体是如何关联的却无法得知。事实上美国网球公开赛是在纽约进行的。又比如,通过中文自然语言工具辨识出费德勒是一个人的名字,同时辨识出上海是一座城市的名字,但是自然语言工具无法辨识出费德勒与上海这座城市的关系。事实上,费德勒与上海的关系是费德勒来上海参加一年一度的大师杯网球公开赛。到目前为止,中文自然语言的理解还没有能力分辨出这些关系,可是这些恰恰对于构建知识图谱来说是非常重要的。
综上所举的例子,因为没有能力辨识实体之间的关系,在这样的知识图谱基础上搭建起来的应用系统,比如人工智能和自动应答系统,其系统能力就被极大地束缚了。假如用户的问题是“费德勒去过哪些城市参加比赛”,所建立的知识图谱就没有能力回答这个问题,尽管它能够看出来费德勒与上海、纽约有所关联,但是它完全没有能力辨识出与这些城市关联的具体原因。
基于上述的困难和限制,在建立中文知识图谱的时候,工业界避免进行实体关系的抽取。比如“百度知识图谱”(由百度创建)建立在进行结构化数据搜索所收获的数据上,而不进行非结构化数据(自然语言文本)的搜索。另一个著名的“搜狗知识图谱”,也是同样只搜索结构化数据,而避免非结构化数据的搜索。
对于以英文为主的知识图谱来讲,早期的实体关系抽取主要是通过人工构造语义规则以及模板的方法识别实体关系。这些方法需要大量的人工干预,过于繁琐,且不够灵活。随后,实体间的关系模型逐渐替代了人工预定义的语法与规则,但是仍需要提前定义实体间的关系类型。近年来,面向开放域的信息抽取框架(openinformationextraction,oie)成为主要的研究方向,其本身经历了开放式实体关系抽取和基于联合推理的实体关系抽取等不同的阶段与成果,但是到目前为止,这个方法被证实并不适用中文自然语言文本实体关系的提取。
综上所述,解决中文自然语言文本中实体关系的抽取是中文知识图谱的构建领域亟待解决的问题。
技术实现要素:
本发明旨在提供一种能够有效地辨别中文自然语言文本中实体之间关系的新型算法,该算法结合现有的机器学习和中文自然语言理解最新成果,提供了可靠的辨识度,也避免了中文知识图谱只能搜索结构化数据的限制,从而为建立中文知识图谱开辟了新的可能。
为实现上述目的,本发明采用的技术方案为中文自然语言实体语义关系的自动辨识算法,具体包括以下步骤:
s1:输入原始自然语言文本;
s2:从原始自然语言文本中提取“实体关系”训练用文本,存入“实体关系”训练用文本库;
s3:从“实体关系”训练用文本库读取文本;
s4:从文本中提取实体集合;
s5:辨识出相关实体对,摘取其关系语句,构造“实体关系”语句;
s6:将构造出的“实体关系”语句存入训练用“实体关系”语句库;
s7:如果每个文本已被读取,则对“实体关系”语句库中的每个语句进行人工标注;否则返回步骤s3;
s8:对标注后的“实体关系”语句库进行机器学习并建模;
s9:“实体关系”辨识模型得以建立。
为提高效率,上述步骤4中从文本中提取实体集合可以使用现有的中文自然语言处理软件提取出所有中文实体集合。
作为一个标准,上述步骤5中辨识相关实体对时两个实体能够成为相关实体对的条件是二者一定要出现在同一个句子里。
上述步骤5中所述构造“实体关系”语句具体指去掉实体并保留所有其他内容。
作为优选,步骤7中所述人工标注为在每一个句子的末尾加入人工标注的语义关系。
作为优选,步骤8中所述机器学习可以选择使用贝叶斯算法或选用svm来进行。
本发明还提出一种利用上述中文自然语言实体语义关系的自动辨识算法对给定的中文自然语言文本生成“实体关系“三元组的算法,具体包括以下步骤:
s21:输入原始自然语言文本;
s22:调用“文本类型”辨识模型辨识文本类型,生成文本类型三元组;
s23:从文本中提取实体集合;
s24:辨识出相关实体,摘取其关系语句,构造“实体关系”语句;
s25:调用“实体关系”辨识模型辨识实体关系,生成实体关系三元组;
s26:收集所有生成的三元组语句。
其中,上述步骤22中所述调用“文本类型”辨识模型辨识文本类型,生成文本类型三元组,具体包括以下步骤:
s31:输入原始自然语言文本集;
s32:提取“文本类型”训练用文本,存入“文本类型”训练用文本库;
s33:对每一个文本人工标注其类型;
s34:形成标注后的训练文本集合库;
s35:进行机器学习并建模;
s36:完成“文本类型”辨识模型。
与现有技术相比,本发明具有有以下优点:
1,本发明提出一个基于机器自动学习的算法来辨识和构建实体之间的关系。本发明中,机器学习的过程是通过分析所有的训练用“实体关系”语句来建立辨识模型的过程的,由于这些训练用“实体关系”语句在经过人工标注之后准确的表达了实体之间的语义关系,这样训练产生的辨识分类模型在面对一个从未见过的实体对时,能够以比较可靠的辨识度来判断该陌生实体对最有可能的语义关系。
2,目前的实验结果证实了上述算法的有效性和可扩展性,填补了中文自然语言实体关系抽取的空白。
3,本发明算法的提出突破和避免了中文知识图谱只能搜索结构化数据的限制,从而为建立中文知识图谱开辟了新的可能。
附图说明
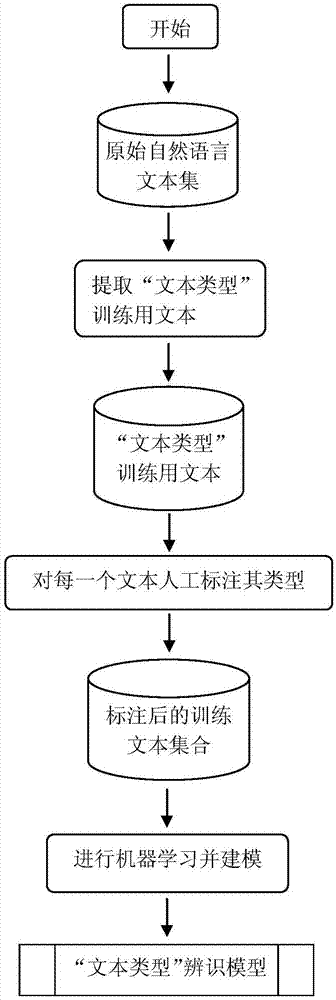
图1为“文本类型“辨识模型产生过程示意图;
图2为“实体关系“辨识模型产生过程示意图;
图3为对给定的自然语言文本产生“实体关系“三元组的过程示意图。
具体实施方式
现结合附图对本发明做进一步详尽的说明。
本发明提供了一种能够有效地辨别中文自然语言文本中实体之间关系的算法,该算法工作原理如下所述。
算法输入:大量的中文自然语言文本。每一个文本只有一个主题,比如描述建筑物天安门,则只描述天安门;如果描述一个人物,就只描述这一个人物等等。例如百科文本,就是符合这样条件的文本。
算法输出:大量符合国际语义网标准的三元组(resourcedescriptionframework,rdf)结构化数据。这些三元组语句有效地描述了不同的实体,以及实体之间的关系。构造三元组语句时的本体选用国际上最为通用的schema.org(为谷歌、推特等公司所使用),但是也可以由用户指定。
算法的实现设计与原理逻辑描述如图1、2、3所示。
图1描述了“文本类型”辨识模型的产生过程。该过程的输入为主语单一的原始自然语言文本集,其中的一部分被提取出来,作为“文本类型”的训练用文本。这些训练用文本被存入“文本类型”训练用文本库。然后,在专家的指导下,人工标注“文本类型”训练用文本库中每一个训练文本的类型。人工标注完成后,形成标注后的训练文本集合。此时,用机器学习的方法读取标注后的训练文本集合,进行机器学习,其结果是“文本类型”辨识模型的建立。
图2描述了“实体关系”辨识模型的产生过程。该过程的输入同样为主语单一的原始自然语言文本集,其中的一部分被提取出来,作为“实体关系”的训练用文本。这些训练用文本被存入“实体关系”训练用文本库,然后,对于该库中的每一个训练用文本,进行如下的操作:
一、读取当前的训练文本;
二、从该训练文本中提取出所有中文实体集合;
三、在提取出来的实体集合中,辨识出所有的相关实体对。对每一对相关实体对,摘取其关系语句,并构造“实体关系”语句;
四、将构造出的“实体关系”语句存入训练用“实体关系”语句库;
上述的操作对“实体关系”训练用文本库中的每一个文本进行,其结果是构造产生了(庞大的)训练用“实体关系”语句库。此刻,在专家的指导下,人工标注训练用“实体关系”语句库中每一个语句的具体实体关系。人工标注完成后,形成标注后的“实体关系”语句库。此时,用机器学习的方法读取标注后的“实体关系”语句库,进行机器学习,其结果是“实体关系”辨识模型的建立。
到此为止,得到了一个覆盖众多文本类型、描述其中各个中文自然语言实体关系的两个核心模型,即“文本类型”辨识模型和“实体关系”辨识模型。现在,对于任何一个给定的中文自然语言文本,利用这两个核心模型,就可以用机器来抽取该给定文本的主语类型,该给定文本中所有实体,以及更重要的信息,即这些实体之间的语义联系。这个过程由图3中的算法具体描述。
具体说来,对于任何一个给定的中文自然语言文本,图3中所示的第一步是调用并且运行“文本类型”辨识模型,以判断该自然语言文本的主题的基本语义类型(值得重申的是,每一个文本只有一个主题,比如描述建筑物天安门,则只描述天安门;如果描述一个人物,就只描述这一个人物等等)。模型运行完毕后所得出的基本语义类型将以rdf三元组的形式被记录下来,并被暂存于机器内存中。
图3中,下面的步骤主要用于文本中实体关系的抽取。首先,机器从该给定的文本中提取出所有中文实体集合,从这些提取出来的实体集合中,辨识出所有的相关实体对。对每一对辨识出的相关实体对,摘取其关系语句,并构造相应的“实体关系”语句。该“实体关系”语句作为输入,被用来调用并运行“实体关系”辨识模型,从而抽取给定的相关实体间的语义关系。模型运行的结果表达了相关实体之间的关系,该关系也将以rdf三元组语句的形式被记录下来,并被暂存于机器内存中。
最后,当所有辨识出的相关实体对都完成模型的调用,并抽取出实体对的相应语义关系后,图3所示的算法会进行最后一步:收集所有产生的三元组语句,并存入相关的数据库中。
图3所描述的抽取过程是以一个任意给定的自然语言文本为例来说明的。在实际使用中,会有大量的自然语言文本作为输入,图3所描述的算法将被逐一用在每一个输入的文本上,从而产生大量的rdf三元组语句。这些rdf三元组语句形成了知识图谱的核心构成元素,这样,一个能够表达实体及实体之间关系的知识图谱就被成功的构造出来了。
本发明的发明填补了中文自然语言实体关系抽取的空白,也在同时极大地促进了中文知识图谱的建立,尤其是基于中文自然语言文本的知识图谱的建立。
如前文所述,由于目前缺少中文自然语言实体关系抽取的算法,工业界在建立中文知识图谱的时候,其基本解决方案是避免进行自然语言实体关系的抽取。比如“百度知识图谱”是建立在搜索结构化数据所收获的数据上,而不进行非结构化数据(自然语言)的搜索。“搜狗知识图谱“也是同样只搜索结构化数据,而避免非结构化数据的搜索。
又如前文所述,以英文为主的知识图谱近年来采用面向开放域的信息抽取框架(openinformationextraction,oie)来抽取实体之间的语义关系,但是到目前为止,这个方法不适用中文自然语言文本实体关系的提取。
具体实施方案描述:
在如下的描述中,假定有若干数量的中文自然语言文本,比如共有10,000个文本,称这些文本为“原始文本集”。为描述方便,假定该原始文本集涉及如下类别:人物、事件、建筑物、国家。更多的种类,可以以此类推,同样适用这里的描述。
图1中描述的算法可以实现如下:
一、从原始文本集中随机抽取100篇有关人物的文本、100篇有关事件的文本、100篇有关建筑物的文本、100篇有关国家的文本;
二、这样一共得到400篇文本,形成了“文本类型”训练用文本库;
三、在专家的指导下,人工标注“文本类型”训练用文本库中每一个文本的类型,具体说来:
对于每一篇关于人的文本,人工标注其为schema:person
对于每一篇关于事件的文本,人工标注其为schema:event
对于每一篇关于关于建筑物的文本,人工标注其为schema:civicstructure
对于每一篇关于国家的文本,人工标注其为schema:country;
四、上述人工标注完成后,形成标注后的训练文本集合;
五、用机器学习的方法读取标注后的训练文本集合,进行机器学习。这里可以选取不同的学习算法,比如贝叶斯分类器,svm等等;
六、机器学习的结果是“文本类型”辨识模型,该模型被存储于持久介质中待用。
图2中描述的算法是本发明的主要内容,其细节可以实现如下:
在描述图2中的算法实现时,将以如上的训练文本集合为例(上述的训练文本集合等同于“实体关系”训练用文本库),并将以人物为具体类型。其他类型的实现可以以此类推。
假定现在从“实体关系”训练用文本库中提取出一篇文章,该文章是关于邓稼先(人物)的文章:
邓稼先(1924—1986),九三学社社员,中国科学院院士,著名核物理学家,中国核武器研制工作的开拓者和奠基者,为中国核武器、原子武器的研发做出了重要贡献。1924年出生于安徽怀宁县一个书香门第的家庭。1935年考入志成中学,在读书求学期间,深受爱国救亡运动的影响。1937年北平沦陷后,他曾秘密参加抗日聚会。后在父亲邓以蛰的安排下,他随大姐去往昆明,并于1941年考入西南联合大学物理系。1948年至1950年,他在美国普渡大学留学,获得物理学博士学位,毕业当年,他就毅然回国。邓稼先是中国核武器研制与发展的主要组织者、领导者,邓稼先始终在中国武器制造的第一线,领导了许多学者和技术人员,成功地设计了中国原子弹和氢弹,把中国国防自卫武器引领到了世界先进水平。邓稼先在一次实验中,受到核辐射,身患直肠癌,于1986年7月29日在北京不幸逝世,终年62岁。
“实体关系“辨识模型产生过程的步骤如下:
一、首先要从《邓稼先》中提取出所有中文实体集合,
可以使用现有的中文自然语言处理软件从这篇关于邓稼先的文章中提取出所有中文实体集合。例如,可以提取出的实体包括如下:邓稼先(人物),安徽怀宁县(地点),西南联合大学物理系(组织),美国普渡大学(组织),北京(地点)等等。
二、在提取出来的实体集合中,辨识出所有的相关实体对。对每一对相关实体对,摘取其关系语句,并构造“实体关系”语句。
以此为例,可以辨别出来的相关实体对有这些:邓稼先安徽怀宁县,邓稼先西南联合大学物理系,邓稼先美国普渡大学,邓稼先北京。两个实体能够成为相关实体对的条件是它们一定要出现在同一个句子里。基于这个标准,以上是所有的相关实体对。“美国普渡大学北京”不是相关实体对,因为它们从未同时出现在一个句子里。
下面,要对每一个相关实体对摘取其关系语句,并构造“实体关系”语句。以相关实体对“邓稼先安徽怀宁县“为例,该实体对出现在下面这个句子里,
1924年出生于安徽怀宁县一个书香门第的家庭
去掉实体,保留所有其他内容,就是所要的“实体关系“语句:
1924年出生于一个书香门第的家庭
上面的语句去掉了实体部分。经过现有的中文自然语言处理软件的处理,上述“实体关系“语句是这样表达的:
1924年|出生|于|一个|书香门第|的|家庭
到此为止,从相关实体对“邓稼先安徽怀宁县“出发,构造了它的对应”实体关系“语句。下面,再以相关实体对“邓稼先西南联合大学物理系“为例,描述如何构造该实体对的相应”实体关系“语句。
实体对“邓稼先西南联合大学物理系“出现在下面这个句子里,
并于1941年考入西南联合大学物理系
去掉实体,保留所有其他内容,就是所要的“实体关系“语句:
并于1941年考入
上面的语句去掉了实体部分。经过现有的中文自然语言处理软件的处理,上述“实体关系“语句是这样表达的:
并|于|1941年|考入
作为最后一个例子,来分析实体对“邓稼先北京“。其他实体关系的分析可以完全按照同样的步骤,不再详述。
实体对“邓稼先北京“出现在下面这个句子里,
于1986年7月29日在北京不幸逝世
去掉实体,保留所有其他内容,就是所要的“实体关系“语句:
于1986年7月29日在不幸逝世
上面的语句去掉了实体部分。经过现有的中文自然语言处理软件的处理,上述“实体关系“语句是这样表达的:
于|1986年|7月|29日|在|不幸|逝世
到此为止,分析了三对实体对,得到了如下三个“实体关系“语句:
1924年|出生|于|一个|书香门第|的|家庭
并|于|1941年|考入
于|1986年|7月|29日|在|不幸|逝世
三、将构造出的“实体关系”语句存入训练用“实体关系”语句库
以上述的例子看,“实体关系“语句库至少有下面这几个语句,
1924年|出生|于|一个|书香门第|的|家庭
并|于|1941年|考入
于|1986年|7月|29日|在|不幸|逝世
事实上,一个文本就可以包含很多实体对,从而也可以产生很多”实体关系“语句。
四、重复上述操作,即对“实体关系”训练用文本库中的每一个文本进行上述操作,其结果是构造产生了庞大的训练用“实体关系”语句库
五、在专家的指导下,人工标注训练用“实体关系”语句库中每一个语句的具体实体关系。
以上面的三个句子为例,可以得到如下的标注:
1924年|出生|于|一个|书香门第|的|家庭[schema:birthplace]
并|于|1941年|考入[schema:alumniof]
于|1986年|7月|29日|在|不幸|逝世[schema:deathplace]
在上面每一个句子的末尾,人工标注的语义关系被加入。这里的例子是使用了schema.org作为本体(ontology)。在不同的应用中,用户可以选择更加适合自己的本体。
六、如上所述的人工标注完成后,得到了标注后的“实体关系”语句库。此时,用机器学习的方法读取标注后的“实体关系”语句库,进行机器学习,其结果是“实体关系”辨识模型的建立。这里,可以选择使用贝叶斯算法,也可以选用svm来进行具体的机器学习。
现在,有了以上的具体实现,就可以对一个未知文本进行关系抽取了(未知文本取自于原始文本集,但是不在训练文本之列)。这个过程在图3中有详细描述,这里用一个具体的例子说明图3中算法的具体实现。以一个描述人的自然语言文本为例,其他文本可以按此推理。
假定这篇没有包含在训练文本库里的文章是关于陈景润的,其内容如下:
陈景润,1933年5月22日生于福建福州,当代数学家。1953年9月分配到北京四中任教。1955年2月由当时厦门大学的校长王亚南先生举荐,回母校厦门大学数学系任助教。1957年10月,由于华罗庚教授的赏识,陈景润被调到中国科学院数学研究所。1973年发表了(1+2)的详细证明,被公认为是对哥德巴赫猜想研究的重大贡献。1981年3月当选为中国科学院学部委员(院士)。曾任国家科委数学学科组成员。1992年任《数学学报》主编。1996年3月19日下午1点10分,陈景润在北京医院去世,年仅63岁。
现在的目的就是要由机器来理解这篇文章:第一,机器要首先分辨出这是一篇关于人的文章,第二,机器要分辨出文章中包含的实体,以及这些实体之间的关系。这些所有抽取的内容都将由符合国际语义标准的rdf语句表达,这些语句也是进一步构造知识图谱的基本元素。
第一步、以此文本作为输入,调用并且运行“文本类型”辨识模型,以判断该自然语言文本的主题的基本语义类型
这里,如果“文本类型”辨识模型建立得足够精确,它会给该文本赋以正确的类型:这是一篇关于schema:person的文章,也就是一篇关于人的文章,并同时产生下面的三元组语句:
ex:陈景润rdf:typeschema:person.
第二部、机器开始在《陈景润》中提取出所有中文实体集合,机器可以使用现有的中文自然语言处理软件从这篇关于陈景润的文章中提取出所有中文实体集合。例如,可以提取出的实体包括如下:陈景润(人物),福建福州(地点),中国科学院数学研究所(组织),北京(地点)等等。
三、在提取出来的实体集合中,机器会辨识出所有的相关实体对。对每一对相关实体对,摘取其关系语句,并构造“实体关系”语句
这里,机器可以辨别出来的相关实体对有这些:陈景润福建福州,陈景润中国科学院数学研究所,陈景润北京。下面,机器要对每一个相关实体对摘取其关系语句,并构造“实体关系”语句。
以相关实体对“陈景润福建福州“为例,该实体对出现在下面这个句子里,
1933年5月22日生于福建福州
去掉实体,保留所有其他内容,就是所要的“实体关系“语句:
1933年5月22日生于
上面的语句去掉了实体部分。经过现有的中文自然语言处理软件的处理,上述“实体关系“语句是这样表达的:
1933年|5月|22日|生|于
再以相关实体对“陈景润中国科学院数学研究所“为例,该实体对出现在下面这个句子里,陈景润被调到中国科学院数学研究所
去掉实体,保留所有其他内容,就是所要的“实体关系“语句:被调到
上面的语句去掉了实体部分。经过现有的中文自然语言处理软件的处理,上述“实体关系“语句是这样表达的:
被|调到
最后,以相关实体对“陈景润北京“为例,该实体对出现在下面这个句子里,陈景润在北京医院去世
去掉实体,保留所有其他内容,就是所要的“实体关系“语句:
在医院去世
上面的语句去掉了实体部分。经过现有的中文自然语言处理软件的处理,上述“实体关系“语句是这样表达的:
在|医院|去世
四、机器已经生成了如下的“实体关系”语句,
陈景润福建福州:1933年|5月|22日|生|于
陈景润中国科学院数学研究所:被|调到
陈景润北京:在|医院|去世
其中第一句“实体关系”语句作为输入,调用并运行“实体关系”辨识模型。如果模型的精确度足够好,它应该可以辨别出“陈景润福建福州”的关系应该是如下出生地的关系,该关系将以rdf三元组语句的形式被记录下来如下:
ex:陈景润schema:birthplaceex:福建福州.
同样的,第二句“实体关系”语句作为输入,调用并运行“实体关系”辨识模型。模型应该可以辨别出“陈景润中国科学院数学研究所”的关系应该是如下工作地的关系,该关系将以rdf三元组语句的形式被记录下来如下:
ex:陈景润schema:workplaceex:中国科学院数学研究所.
最后,第三句“实体关系”语句作为输入,调用并运行“实体关系”辨识模型时,模型应该可以辨别出“陈景润北京”的关系应该是他去世的地点,该关系将以rdf三元组语句的形式被记录下来如下:
ex:陈景润schema:deathplaceex:北京.
这样,机器所辨识到的每一个实体对,它们之间的语义关系就被准确的抽取出来了。
五、对于这个给定的未知文本,机器获取了如下的rdf三元组语句,
ex:陈景润rdf:typeschema:person.
ex:陈景润schema:birthplaceex:福建福州.
ex:陈景润schema:workplaceex:中国科学院数学研究所.
ex:陈景润schema:deathplaceex:北京.
至此,就完成了实体关系的机器自动抽取。如前所述,由于目前缺少中文自然语言实体关系抽取的算法,工业界在建立中文知识图谱的时候,其基本解决方案是避免进行自然语言实体关系的抽取。比如“百度知识图谱”是建立在搜索结构化数据所收获的数据上,而不进行非结构化数据(自然语言)的搜索。“搜狗知识图谱“也是同样只搜索结构化数据,而避免非结构化数据的搜索。
又如前所述,以英文为主的知识图谱近年来采用面向开放域的信息抽取框架(openinformationextraction,oie)来抽取实体之间的语义关系,但是到目前为止,这个方法不适用中文自然语言文本实体关系的提取。本发明填补了中文自然语言实体关系抽取的空白,也在同时极大地促进了中文知识图谱的建立,尤其是基于中文自然语言文本的知识图谱的建立。
需要说明的是,以上具体实施方式的描述并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!