一种基于语义资源词表示和搭配关系的语义双关语识别方法与流程
本发明涉及自然语言处理领域,语义双关语的识别。尤其是一种基于语义资源词表示和搭配关系的语义双关语识别方法。
背景技术
近年来,双关语一直在语言中以模棱两可和不一致的方式来使用一个词经常使用这个词的不同含义,或者利用声音的近似程度产生幽默的效果。双关语被广泛用于书面语和口头文学中,其目的在于成为幽默的来源之一。从文学创作、演讲和口头故事等角度来讲,双关也是一种标准的修辞手段,也可以作为一直非幽默的方式来使用。例如莎士比亚以他的双关语而闻名于世,在他的经典作品中不断出现。幽默和非幽默的双关语一直是广泛和有吸引力的作品的主题,导致了对双重含义的辨识的难点。
自然语言处理中双关语识别的研究有很多。许多学者试图根据单词的发音和不同含义的相似关系对双关语进行分类。例如,redfern将双关语分为谐音双关语和语义双关语,分别使用语音性和语义性。
语义双关语和谐音双关语都具有双重的情景,可以在一定的环境中增加深刻的印象。然而,两种双关语都有各自的特点。语义双关语作为双关语的一个重要类别,其两个意义的单词具有相同的写作形式。而谐音双关语中是由发音相似而导致的双重感觉。前者可以使用同义词来解决,而后者可以使用同音词来解决。由于它们之间明显的差异,不能使用统一的模型进行区分。
关于语义双关语的研究很多,因为它们在世界各地广泛使用,并且在现有的文本语料库中很容易获得。然而,目前对语义双关语的识别模型中并不能很好的解决双重的含义,同时,其识别的结果也不佳。如果能在识别的过程中充分考虑不同含义及其之间的关系,将会对双关语识别的性能带来巨大的提升。
技术实现要素:
本发明的目的是提供一种准确的识别语义双关语的方法,是一种可以有效完善其多个含义并补充其搭配关系的基于语义资源词表示和搭配关系的语义双关语识别方法。
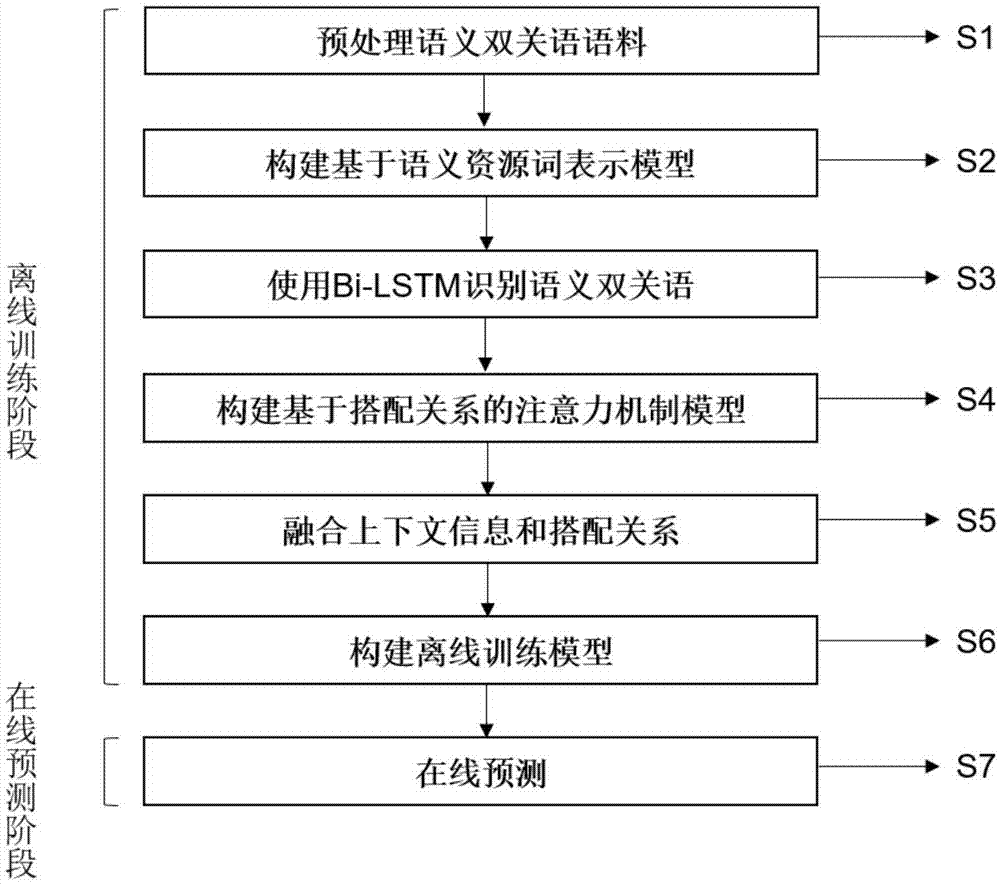
本发明解决现有技术问题所采用的技术方案:一种语义双关语识别方法,主要包括离线训练和在线预测两个部分,其中,离线训练包括以下步骤:
s1、预处理语义双关语语料:在预处理中需要进行基本的去停用词和去除噪音的工作;
s2、构建基于语义资源词表示模型:通过语义资源查询词汇的多义性,然后通过词向量模型构建每个词汇对应的词向量表示,最后使用基于语义资源的信息采用一种加权的集合方式构建最终的词向量;
a1:根据语义资源,查找每个词汇对应的词(word)、意思(sysnets)和引理(lemmas)。每个词汇有多个意思,每个意思有多个引理,用以表示词汇的多义性。
a2:根据词向量模型,分别构建每个词汇对应的词、意思和引理对应的词向量(w,s,l),得到其潜在的语义表示信息。
a3:使用加权的集合方式构建词向量,在a2词向量的基础上融合语义资源提供的词、意思和引理信息,具体公式如下所示:
这里m表示词汇word对应所有意思的所有引理的总数量,
最终得到的词表示模型由glove模型提供的向量和上面得到的w向量这两个向量进行拼接的操作,从而为wordnet编码的词表示模型的输出结果。
s3、使用bi-lstm识别语义双关语:对于每个句子,分别从前向和后向两个方向对句子进行隐层表示,最终将两个方向的结果进行拼接。
其中每个细胞计算单元的计算公式如下:
ft=σ(wf·x′+bf)
it=σ(wi·x′+bi)
ot=σ(wo·x′+bo)
ct=ft⊙ct-1+it⊙tanh(wc·x′+bc)
hout=ot⊙tanh(ct)
wf,wi,wo,wc分别为lstm模型遗忘门ft、输入门it、输出门ot和细胞ct的参数矩阵,bf,bi,bo,bc分别为ft、it和ot和ct的偏执量,这些参数由lstm模型学习获得,ct-1为上一层的细胞,xt为当前的输入,ht-1为上一层lstm的隐层输出,x’为xt和ht-1的拼接。σ为sigmoid函数,⊙表示矩阵的按元素乘法,tanh为激活函数,hout表示隐层输出。
s4、构建基于搭配关系的注意力机制模型:在语义双关语识别中,句子中候选双关词的搭配为获取搭配权重提供了更多的线索。候选双关词主要由名词、动词、形容词和副词组成,候选双关语的搭配对识别语义双关语尤为重要。将候选双关词按词性划分为4个集合,在每个同性词集合中词与词之间的语义关联关系称为搭配关系。
这里使用注意力机制来挖掘词汇搭配中潜在关系。选取候选双关词中的每个词性集合中的任何一个词,提取搭配词用以获取搭配的权重,公式如下:
uijt=v·tanh(wwhijt+bw
其中,hijt是任一时刻的任一词性的bi-lstm模型的隐层状态,tx={1,2,3,4}表示四种词性,其中1表示nouns,2表示verbs,3表示adjectives,4表示adverbs,t表示四种词性的任意一种,t∈tx,i表示当前词i,j表示当前句子中的其他词,ww表示权重向量,bw表示偏置向量,v是投影向量,tanh是激活函数。uijt是hijt在进行tanh变换后得到的隐层表示,αijt是通过softmax函数后得到的每个词性的正则化权重,cij是在注意力机制作用下的上下文向量。
每个候选词性在注意力机制作用下与句子的上下文权重相结合生成的文档向量,进行拼接合并得到搭配关系的模型向量,具体公式如下:
ci=[cinouns;civerbs;ciadjectives;ciadverbs]
其中,ci由上个步骤得到的上下文向量cij进行合并得到,主要有名词、动词、形容词和副词四部分组成,j∈{nouns,verbs,adjectives,adverbs}。
s5、融合语义上下文信息和搭配信息:将步骤s4得到的搭配关系模型与句子上下文向量进行元素相乘运算,用以识别语义双关语。公式如下:
lout=ci·hout
yi=softmax(lout)
lout是在上下文向量ci和隐层向量hout上进行元素级点乘运算后得到的结果,yi是softmax函数得到的结果,最终用于进行语义双关语识别。
s6、构建离线训练模型:模型使用端到端的方式通过反向传播进行训练,损失函数使用交叉熵函数。
i表示句子的索引,j表示类别的索引。我们这里是二分类问题,λ表示l2正则项,θ是参数。
其中,在线预测阶段包括以下步骤:
s7、在线预测:
b1、获取至少一条待识别的双关语文本i;
b2、将待识别的双关语文本通过s2步骤构建基于语义资源词表示模型,通过s3步骤使用bi-lstm识别语义双关语,利用s4步骤构建基于搭配关系的注意力机制模型,利用s5步骤融合语义上下文信息和搭配信息,获得预测向量yi。
b3、利用s6步骤训练出的离线模型,判断待识别的文本i是否为双关语文本。
附图说明
图1为本发明识别方法的流程示意图。
具体实施方式
以下结合附图及具体实施方式对本发明进行说明:
图1是本发明一种基于语义资源词表示和搭配关系的语义双关语方法的流程示意图,一种基于语义资源词表示和搭配关系的语义双关语方法,包括以下离线训练阶段和在线预测阶段,其中,离线训练阶段包括以下步骤:
s1、预处理语义双关语语料:在预处理中需要进行基本的去停用词和去除噪音的工作;
这里,主要采用semeval2017task7和punoftheday两个公开数据集,均可用于语义双关语的识别工作,具体统计如下表所示:
这里,给出语料中一个语义双关语的例子。
eg1.iusedtobeabankerbutilost#interest#.
例1.我过去是一个银行家但是我失去了#利益#。
该句为语义双关语,[interest]为双关词,具有[利益]和[兴趣]的含义,这里是[利益]的意思。[iusedtobeabanker]和[ilostinterest]产生一种与语境的冲突,从而达到语义双关语的效果。
s2、构建基于语义资源词表示模型:通过语义资源查询词汇的多义性,然后通过词向量模型构建每个词汇对应的词向量表示,最后使用基于语义资源的信息采用一种加权的集合方式构建最终的词向量;
a1:根据语义资源,查找每个词汇对应的词(word)、意思(sysnets)和引理(lemmas)。每个词汇有多个意思,每个意思有多个引理,用以表示词汇的多义性。
例如,词[interest]共有[sake]、[pastime]和[interest]三个意思,其中意思[sake]有[sake]和[interest]两个引理,意思[pastime]有[pastime]、[pursuit]、[interest]三个引理,意思[interest]有[involvement]和[interest]两个引理。
a2:根据词向量模型,分别构建每个词汇对应的词、意思和引理对应的词向量(w,s,l),得到其潜在的语义表示信息。这里,词向量采用glove词向量,维度为200。
a3:使用加权的集合方式构建词向量,在a2词向量的基础上融合语义资源提供的词、意思和引理信息,具体公式如下所示:
这里m表示词汇word对应所有意思的所有引理的总数量,
最终得到的词表示模型由glove模型提供的向量和上面得到的w向量这两个向量进行拼接的操作,从而为wordnet编码的词表示模型的输出结果,其中维度为200维。
s3、使用bi-lstm识别语义双关语:对于每个句子,分别从前向和后向两个方向对句子进行隐层表示,最终将两个方向的结果进行拼接。这里,采用一层bi-lstm模型,其神经单元个数为800个。
其中每个细胞计算单元的计算公式如下:
ft=σ(wf·x′+bf)
it=σ(wi·x′+bi)
ot=σ(wo·x′+bo)
ct=ft⊙ct-1+it⊙tanh(wc·x′+bc)
hout=ot⊙tanh(ct)
wf,wi,wo,wc分别为lstm模型遗忘门ft、输入门it、输出门ot和细胞ct的参数矩阵,bf,bi,bo,bc分别为ft、it和ot和ct的偏执量,这些参数由lstm模型学习获得,ct-1为上一层的细胞,xt为当前的输入,ht-1为上一层lstm的隐层输出,x’为xt和ht-1的拼接。σ为sigmoid函数,⊙表示矩阵的按元素乘法,tanh为激活函数,hout表示隐层输出。
s4、构建基于搭配关系的注意力机制模型:在语义双关语识别中,句子中候选双关词的搭配为获取搭配权重提供了更多的线索。候选双关词主要由名词、动词、形容词和副词组成,候选双关语的搭配对识别语义双关语尤为重要。将候选双关词按词性划分为4个集合,在每个同性词集合中词与词之间的语义关联关系称为搭配关系。这里例1的候选双关词为{used,banker,lost,interest},仅有动词候选双关词集合{used,lost}和名词候选双关词集合{banker,interest},主要计算各个相同词性集合内的语义关联搭配关系。
这里使用注意力机制来挖掘词汇搭配中潜在关系。选取候选双关词中的每个词性集合中的任何一个词,提取搭配词用以获取搭配的权重,公式如下:
uijt=v·tanh(wwhijt+bw
其中,hijt是任一时刻的任一词性的bi-lstm模型的隐层状态,tx={1,2,3,4}表示四种词性,其中1表示nouns,2表示verbs,3表示adjectives,4表示adverbs,t表示四种词性的任意一种,t∈tx,i表示当前词i,j表示当前句子中的其他词,ww表示权重向量,bw表示偏置向量,v是投影向量,tanh是激活函数。uijt是hijt在进行tanh变换后得到的隐层表示,αijt是通过softmax函数后得到的每个词性的正则化权重,cij是在注意力机制作用下的上下文向量。
每个候选词性在注意力机制作用下与句子的上下文权重相结合生成的文档向量,进行拼接合并得到搭配关系的模型向量,具体公式如下:
ci=[cinouns;civerbs;ciadjectives;ciadverbs]
其中,ci由上个步骤得到的上下文向量cij进行合并得到,主要有名词、动词、形容词和副词四部分组成,j∈{nouns,verbs,adjectives,adverbs}。
s5、融合语义上下文信息和搭配信息:将上述步骤得到的搭配关系模型与句子上下文向量进行元素相乘运算,用以识别语义双关语。公式如下:
lout=ci·hout
yi=softmax(lout)
lout是在上下文向量ci和隐层向量hout上进行元素级点乘运算后得到的结果,yi是softmax函数得到的结果,最终用于进行语义双关语识别。
s6、构建离线训练模型:模型使用端到端的方式通过反向传播进行训练,损失函数使用交叉熵函数。
i表示句子的索引,j表示类别的索引。我们这里是二分类问题,λ表示l2正则项,θ是参数。
其中,在线预测阶段包括以下步骤:
s7、在线预测:
b1、获取至少一条待识别的双关语文本i;
b2、将待识别的双关语文本通过s2步骤构建基于语义资源词表示模型,通过s3步骤使用bi-lstm识别语义双关语,利用s4步骤构建基于搭配关系的注意力机制模型,利用s5步骤融合语义上下文信息和搭配信息,获得预测向量yi。针对例1,通过b2步骤得到的是否为语义双关语的预测概率值为0.875。
b3、利用s6步骤训练出的离线模型,判断待识别的文本i是否为双关语文本。这里,判断例1是否为语义双关语,得到最终的标签为1,则在线预测模型认为例1是语义双关语。
其中,对比实验如下:
lstm:lstm不使用wordnet编码的词向量和搭配注意力机制模型。
bi-lstm:bi-lstm不使用wordnet编码的词向量和搭配注意力机制模型。
bi-lstm-attention:bi-lstm结合经典的注意力机制模型。
our:本文方法,使用wordnet编码的词向量和搭配关系注意力机制模型。
表1各模型性能对比
如表1所示,使用bi-lstm的结果要优于lstm,证明双向的信息能更加全面的挖掘上下文信息;bi-lstm-attention模型优于bi-lstm模型,证明使用注意力机制能够发现更应该关注到的信息;本文方法的结果最佳,证明了wordnet编码的词向量的有效性,同时证明了搭配关系的注意力机制的有效性。
以上内容是结合具体的优选技术方案对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单推演或替换,都应当视为属于本发明的保。
- 还没有人留言评论。精彩留言会获得点赞!