一种基于多标签深度卷积网络的证件照分类方法与流程
本发明涉及图像分类
技术领域:
,具体涉及一种基于多标签深度卷积网络的证件照分类方法。
背景技术:
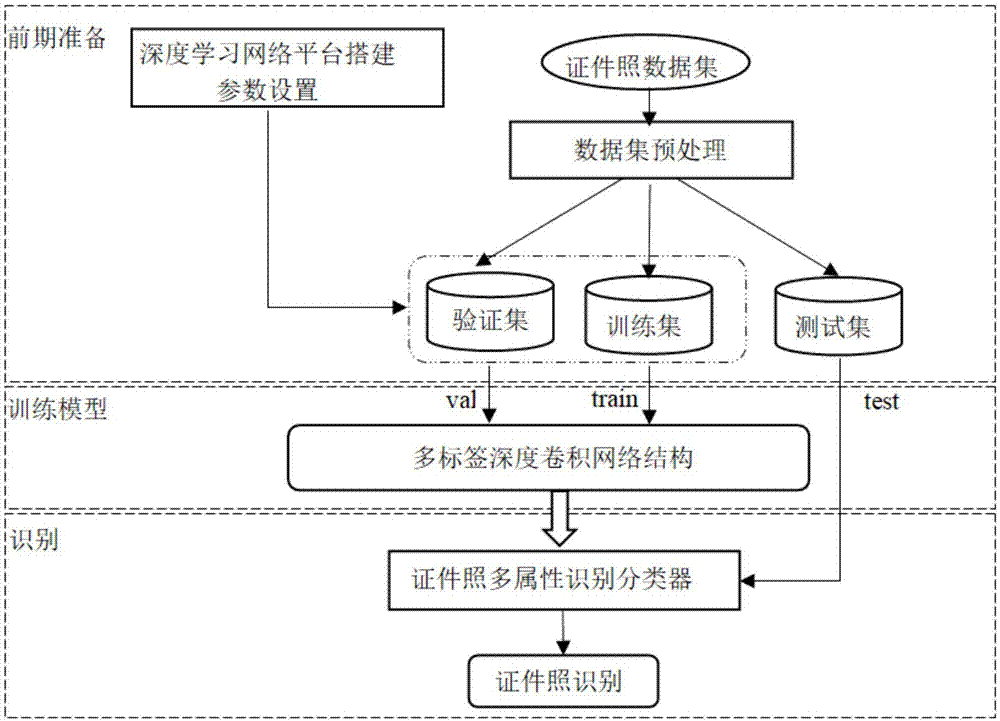
:随着移动互联网技术的发展,使用智能手机等设备进行移动办公给人们的生活带来了极大的便利。而证件照又是我们日常生活中经常用到的,一张证件照拥有身份证,驾驶证,护照签证,社保卡,司法考试等多种用途。证件照在不同的使用场合也有不同的标准要求,比如说背景颜色,照片尺寸等等。这些要求通常众多且细碎,不利于人们的理解和实际执行。以至于拍摄效果更是因人而异,照片质量参差不齐。如果仅仅依靠专业人员进行人工检验无疑会浪费巨大的人力物力。而传统的识别方法在解决上述问题时多数通过人工定义特征,比如提取sift、hog等特征,然后进行训练和学习,最后生成一个可分类模型。然而这种人工设计的特征需要一定的先验知识,在实际开发中很难设计出最优的具有区分度的特征。同时在证件照分类中,一张图片可能同时属于戴眼镜类和浓妆类等,即单实例多标签问题siml(singleinstancemultilabel)。多标签学习旨在通过适当共享多个预测子任务的相关信息来提高预测性能。技术实现要素:本发明所要解决的技术问题是针对上述现有技术的不足提供一种基于多标签深度卷积网络的证件照分类方法,本基于多标签深度卷积网络的证件照分类方法一方面能够快速准确地识别出证件照的属性特征,从而判断是否为合格证件照以及不合格证件照的不合格因素,节省工作人员人工逐项检查审核照片的时间,提高工作效率。另一方面对于单任务多标签实例,本发明的多标签学习只利用一个分类器即可判断一张图片的多个属性特征,而不是冗余的为每个属性任务都训练学习一个分类器,既节省了预测效率,模型存储空间。为实现上述技术目的,本发明采取的技术方案为:一种基于多标签深度卷积网络的证件照分类方法,包括以下步骤:步骤1:搭建基于包含多种卷积神经网络模型的caffe深度学习框架平台;步骤2:收集证件照数据集;步骤3:建立基于caffe架构的多标签深度卷积网络结构;步骤4:初始化多标签深度卷积网络结构内的参数;步骤5:采用证件照数据集对多标签深度卷积网络结构进行训练,得到证件照属性分类模型;步骤6:将待测证件照的图像输入到证件照属性分类模型内,从而识别证件照的属性类别特征。作为本发明进一步改进的技术方案,所述的步骤(2)包括以下步骤:(2.1):利用图像搜索引擎采集多种具有头像特征的图像;(2.2):对采集的所有图像进行提纯,消除其中不具有头像特征的图像;(2.3):从步骤(2.2)得到的图像中删除重复图像;(2.4):设置证件照分类任务,所述证件照分类任务为将m个属性类别特征的标签均分配给每一个图像,即若步骤(2.3)得到的图像具有某种属性类别特征,则将该图像的某种属性类别特征的标签设为1,若图像不具有某种属性类别特征,则将图像的某种属性类别特征的标签设为-1,从而实现将m个属性类别特征的标签均分配给每一个图像,将所有图像和每个图像对应的m个属性类别特征的标签作为证件照数据集。作为本发明进一步改进的技术方案,所述的m个属性类别特征包括是否是合格证件照、图片背景是否合适、着装是否合适、是否浓妆、头顶发迹距证件照片上边缘距离是否合适、是否闭眼以及是否戴眼镜,若图像具有m个属性类别特征中的某个属性类别特征,则将图像的该属性类别特征的标签设为1,若图像不具有m个属性类别特征中的某个属性类别特征,则将图像的该属性类别特征的标签设为-1。作为本发明进一步改进的技术方案,所述的步骤(3)中的多标签深度卷积网络结构包括输入层和输出层,所述输入层用于输入证件照数据集内的图像和图像对应的m个属性类别特征的标签,所述输出层用于输出图像的m个属性类别特征的概率。作为本发明进一步改进的技术方案,所述的步骤4包括:(4.1)建立人脸特征识别cnn网络结构,所述人脸特征识别cnn网络结构用于通过识别人脸特征从而对人的年龄进行分类;(4.2)将步骤(2.3)中得到的图像和图像对应的人的年龄作为人脸数据集对人脸特征识别cnn网络结构进行训练,得到训练好的人脸特征识别cnn网络模型;(4.3)通过人脸特征识别cnn网络模型内的参数对多标签深度卷积网络结构内的参数进行初始化。作为本发明进一步改进的技术方案,所述的步骤5包括:(5.1)采用留出法将证件照数据集划分为训练集、验证集和测试集;(5.2)将训练集输入到多标签深度卷积网络结构进行训练,将验证集输入到多标签深度卷积网络结构进行验证,得到证件照属性分类模型,将测试集输入到证件照属性分类模型中进行测试。根据权利要求6所述的基于多标签深度卷积网络的证件照分类方法,其特征在于,所述的步骤6包括:(6.1)将待测证件照的图像进行预处理,然后输入到证件照属性分类模型内;(6.2)通过证件照属性分类模型对待测证件照的图像的m个属性类别特征进行分类,输出待测证件照的图像的m个属性类别特征的概率。本发明的有益效果为:(1)本发明能够快速准确地识别出待测证件照的属性类别特征的概率从而判断是否为合格证件照以及不合格证件照的不合格因素,提供拍摄建议机制,极大方便普通用户自己制作满足条件的证件照,提供较好的操作体验,同时对于证件照审查的工作人员来说大大节省了人工逐项检查审核照片的时间,提高工作效率。(2)本发明将多标签学习和深度卷积网络结合,不仅避免了传统复杂的特征提取设计,自动学习更深层次的语义特征,而且能够通过适当共享多个预测子任务的相关信息来提高预测性能。(3)本发明解决了传统深度学习模型采用的网络初始化方法训练时收敛效果不好,实际预测时准确率较低的问题。传统深度学习网络的初始化一般为将网络所有参数初始化为-1或随机初始化。本发明先训练了对人脸特征进行识别的cnn网络结构,然后利用该人脸特征识别cnn网络结构的参数对多标签深度卷积网络结构进行初始化,不仅提高了网络训练的收敛速度,且使证件照属性分类模型有更高的识别准确度。附图说明图1为本发明的工作流程图。具体实施方式下面根据图1对本发明的具体实施方式作出进一步说明:参见图1,一种基于多标签深度卷积网络的证件照分类方法,包括以下步骤:步骤1:搭建基于包含多种卷积神经网络模型的caffe深度学习框架平台;步骤2:收集证件照数据集;步骤3:建立基于caffe架构的多标签深度卷积网络结构;步骤4:初始化多标签深度卷积网络结构内的参数;步骤5:采用证件照数据集对步骤3建立的多标签深度卷积网络结构进行训练,得到证件照属性分类模型(即图1中证件照多属性识别分类器);步骤6:将待测证件照的图像预处理后输入到证件照属性分类模型内,从而识别证件照的属性类别特征。所述的步骤(2)包括以下步骤:(2.1):利用图像搜索引擎从多个搜索引擎的搜索结果中采集多种具有头像特征的图像,包括但不限于戴眼镜、闭眼、浓妆等。(2.2):对采集的所有图像进行提纯,消除其中不具有头像特征的图像从而完全无关图像。这个步骤将图像总数减少为50k;(2.3):从步骤(2.2)得到的图像中删除重复图像:从两个不同搜索引擎找到的高精度重复图像,或者在两个不同互联网位置找到的同一副图像的副本都被删除;(2.4):人工标注数据集,设置证件照分类任务,所述证件照分类任务为将m个属性类别特征配给每个图像样本;本实施例包括7个属性类别特征,证件照分类任务的7个属性类别特征分别为“是否是合格证件照”,“图片背景是否合适”,“着装是否合适”,“是否浓妆”,“头顶发迹距证件照片上边缘距离是否合适”,“是否闭眼”,“是否戴眼镜”;若步骤(2.3)得到的图像具有某种属性类别特征,则将该图像的某种属性类别特征的标签设为1,若图像不具有某种属性类别特征,则将图像的某种属性类别特征的标签设为-1,从而实现将m个属性类别特征的标签均分配给每一个图像;(2.5):将所有图像和每个图像对应的m个属性类别特征的标签划分为证件照数据集,证件照数据集划分为训练集dtrain、验证集dval和测试集dtest,dtrain={(xi,yi)|1≤i≤n},其中n为训练样本的个数;我们有m个属性,也即有m个任务,第tth个任务的单个训练样本可记为其中t(1,…,m),i=(1,…,n,且分别是该样本对应的特征向量和属性类别特征的标签。如果样本具有第jth个属性,则否则该证件照数据集详情和其他两个公开人脸数据集的对比如下表1所示,表1中第3个为本发明的证件照数据集,通过数据集比较可知,本发明的证件照数据集针对证件照分类图像具有一定的规模:表1:数据集样本数属性lfwa[7]13,14340celeba200,00040ours56,3827本发明以深度残差网络作为基本的网络结构(多标签深度卷积网络结构),cnn网络能够提取low/mid/high-level的特征,网络层数越多,意味着提取的特征越丰富,越抽象,语义信息也会更加完善。所述的步骤(3)中的多标签深度卷积网络结构包括输入层和输出层,输入层用于输入证件照数据集内的图像和图像对应的m个属性类别特征的标签,多标签深度卷积网络结构大小为w×h×c(w×h为每个图像像素的宽和高,c为通道值),输出层用于输出图像的m个属性类别特征的概率,记为该网络结构共50层,主要由四部分组成,卷积层,全连接层,残差模块层和加权损失层,其中卷积层包含多个池化层,激活层和批正则化层等。基础网络结构(多标签深度卷积网络结构)中每个convx_x中都包含多个残差模块,在该实施例中采用两个不同的残差模块,模块a(buildingblocka),模块b(buildingblockb)。其中模块b也叫做identityblock,输入和输出的dimension是一样的,所以可以串联多个,模块a也叫做convblock,输入和输出的dimension是不一样的,所以不能连续串联。相比于之前的网络,解决了网络层数过深导致的梯度弥散问题,不仅加深了网络层数有利于提取更深层次的特征,而且减少了计算量,加速收敛。所述多标签卷积神经网络模型包括多层,其中第一层为输入层、中间多层为隐藏层,第八层为输出层。各层结构如下:第一层:输入层,输入层为python层,输入数据为步骤(2.4)生成的图片+标签;因为caffe不支持多标签分类,这里本实施例通过python代码读取原始数据和图像对应的多个标签,将预处理过后的图像送入第二层;第二层:隐藏层,包含一个卷积层、批量归一化层batchnorm和scale层、激活层、池化层;卷积层用于对第一层输入的图像提取边缘纹理特征,得到多个特征图,batchnorm对特征图的值归一化,scale层对对归一化后的值进行平移,缩放,激活层对特征值超过一定阈值的值进行激活,得到的多个特征图送入池化层,减少特征图的尺寸,减少参数。第三层:conv2_x,包含一个残差模块a层和2个模块b;第三层的作用对对上一层输入的多个特征图进行进一步特征提取,提取一些低层次的语义特征,对提取的特征组合,进一步加深了网络,同时消除梯度弥散;第四层:conv3_x,包含一个模块a和3个模块b;相对于第三层,在其基础上,提取一些中等层次的主题特征,进一步对提取的组合,压缩。第五层:conv4_x,包含一个模块a和5个模块b;在第四层基础上,提取一些高等层次的物体部分特征;第六层:conv5_x,包含一个模块a和3个模块b,一个池化层;在第五层基础上,对多个特征图,提取更抽象的语义特征;第七层:网络越深,计算量越大;网络大部分的参数都集中在全连接层上,将全连接层换成全局平均池化层,减少参数量和计算量,该层输出m维的特征向量。第七层为全局平均池化层,对前面提取到的卷积特征进行平均池化,这一步减少参数量和计算量,该层输出m维的特征向量,该层的另一个作用,不要求网络第一层输入层输入的原始图像的尺寸是固定的。第八层:加权损失层,计算验证损失和训练损失,更新每个属性任务的权重,用于反向传播训练;和传统损失层不同,这里根据证件照验证集的损失趋势赋予m个属性任务不同的权重,结合证件照训练集的训练损失来优化权重。所述的步骤4包括:(4.1)建立人脸特征识别cnn网络结构,所述人脸特征识别cnn网络结构用于通过识别人脸特征从而对人的年龄进行分类;(4.2)将步骤(2.3)中得到的图像和图像对应的人的年龄作为人脸数据集对人脸特征识别cnn网络结构进行训练,得到训练好的人脸特征识别cnn网络模型;(4.3)通过人脸特征识别cnn网络模型内的参数对多标签深度卷积网络结构内的参数进行初始化。优选的,这里选取年龄网络(人脸特征识别cnn网络模型)的第一层至第六层的池化层的网络参数初始化证件照网络对应层的参数。所述的步骤5包括:(5.1)采用留出法将证件照数据集划分为训练集dtrain、验证集dval和测试集dtest;(5.2)用bp算法将训练集输入到多标签深度卷积网络结构进行训练,将验证集输入到多标签深度卷积网络结构进行验证,得到证件照属性分类模型,将测试集输入到证件照属性分类模型中进行测试。其中第一层至第七层的网络权重为所有子任务共享参数,这样可以大大减少网络参数的数量。证件照分类模型是利用训练集进行前向训练和反向传播更新参数,经过多次迭代,每训练一定的代数用验证集验证一次,最后得到证件照分类模型,然后将测试集输入到训练好的模型进行测试。所述步骤3中多标签深度卷积网络结构的第八层的加权损失层,其目标为最小化:每次训练过程中,加权损失层自动调整每个子任务权重的数值。优选的,调整权重时使用验证损失趋势算法。验证损失趋势算法(validationlosstrendalgorithm)具体按照如下步骤:(a)初始化各属性任务的权重ε=1;(b)判断当前训练迭代次数c是否大于等于2*k;(c)若满足步骤(b)的条件,则计算验证损失集合val_loss_list里c-2*k代到c-k代的验证损失均值pre_mean;若不满足条件,则直接结束返回ε;(d)计算验证损失集合val_loss_list里c-k代到c代的验证损失均值cur_mean;(e)计算验证损失趋势trend;(f)计算并返回各属性任务的权重ε。所述的步骤6包括:(6.1)将待测证件照的图像进行预处理,然后输入到证件照属性分类模型内;提取测试图像的特征,提取深度卷积网络提取的特征向量作为此张照片的特征;(6.2)通过证件照属性分类模型对待测证件照的图像的m个属性类别特征进行分类,输出待测证件照的图像的m个属性类别特征的概率。从而判断该照片是否合格,或者不合格因素有哪些。本实施例将7个属性任务当做是单样本单标签任务,针对每个任务单独训练一个分类器(baseline),和本多标签深度卷积网络(multilabel-cnn)识别准确率比较。其中证件照数据集包括48000训练样本,3000验证样本,5000测试样本。本实施例的证件照属性分类识别精度如下表2所示:方法背景着装闭眼戴眼镜浓妆距离不适证件照baseline94.370.394.598.497.693.499.6multilable_cnn90.689.396.298.695.594.098.4从表2中可以看出multilabel_cnn在多数属性特征任务上表现要优于单标签二分类任务训练的baseline模型,尤其在人像着装是否合适一项,多标签学习通过联合多个任务的相关性训练的模型达到89.3%的预测精度,相比于baseline方法获得了19%的精度提升。在日常生活采集到的图像通常背景杂乱,场景复杂,人物有遮挡物或者多个人像,光照条件变化差异大,用传统的证件照片质量检测方法,比如一些基于几何性质,先验规则,色彩信息和外观信息等的定位方法需要人工从复杂的图片背景中分割抽取人脸特征属性信息,无疑会耗费很大的人力。而基于多标签深度卷积网络则能够避免以上繁杂的特征提取工作,并且达到精确地识别效果。本实施例能够快速准确地识别出待测证件照的属性类别特征的概率从而判断是否为合格证件照以及不合格证件照的不合格因素,提供拍摄建议机制,极大方便普通用户自己制作满足条件的证件照,提供较好的操作体验,同时对于证件照审查的工作人员来说大大节省了人工逐项检查审核照片的时间,提高工作效率。本实施例将多标签学习和深度卷积网络结合,不仅避免了传统复杂的特征提取设计,自动学习更深层次的语义特征,而且能够通过适当共享多个预测子任务的相关信息来提高预测性能。本实施例先训练了对人脸特征进行识别的cnn网络结构,然后利用该人脸特征识别cnn网络结构的参数对多标签深度卷积网络结构进行初始化,不仅提高了网络训练的收敛速度,且使证件照属性分类模型有更高的识别准确度。本发明的保护范围包括但不限于以上实施方式,本发明的保护范围以权利要求书为准,任何对本技术做出的本领域的技术人员容易想到的替换、变形、改进均落入本发明的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1