一种中文文章查重方法和系统与流程
本发明涉及通信技术领域,具体地,涉及一种中文文章查重方法和系统。
背景技术
目前中文论文查重方法主要是基于语义知识的方法。基于语义知识的方法是通过分析比较待检测文章与数据库文章的自然语义相似程度从而达到判别抄袭的目的。由于汉语言的文章是以“字”为最小单位,而文章要表达的意思,则是以“词”为最小单位,常见的分词方法,不能完全准确的进行分词;中文语言的复杂性,如语句的重组,都会使得查重的准确性不高,基于语义知识的判断结果正确性很难得到保证。
因此,如何提高中文论文的查重准确性已成为目前亟待解决的问题。
技术实现要素:
本发明针对现有技术中存在的上述技术问题,提供一种中文文章查重方法和系统。该中文文章查重方法能够避免中文语言的复杂性如语句的重组和分词方法的不准所导致的中文论文查重准确性不高的问题,提高了中文论文查重的准确性。
本发明提供一种中文文章查重方法,包括:
步骤s10:将待查文章和文章库中的文章均拆分为句子;
步骤s11:将所述句子翻译成英文;
步骤s12:将所述待查文章中的句子和所述文章库中文章的句子按序进行一一对比,判断相对比句子的相似度是否达到了设定范围;
步骤s13:统计所述待查文章中与所述文章库中文章的句子相似度达到设定范围的句子数量是否达到了所述待查文章中句子总数的设定范围;
如果是,则所述待查文章为重复文章。
优选地,在所述步骤s11之后和所述步骤s12之前还包括:
步骤s11′:设置同义词库,所述同义词库用于定义同义词;
步骤s12′:根据所述同义词库将所述文章库中文章和所述待查文章中的同义词统一更换为所述待查文章中的用词。
优选地,所述步骤s11′包括:
设置语义相近的词为同义词;
设置表示同一时间的词为同义词;
设置同一个词的不同时态和单复数为同义词;
设置同一个词的大小写为同义词;
设置同一个词的名词性物主代词和形容词性物主代词为同义词;
设置同一事物的知名绰号、别名和本名为同义词。
优选地,所述步骤s12包括:
记录所述待查文章每个句子中出现的单词并统计该单词在该句子中的出现次数;
记录所述文章库中文章的每个句子中出现的单词并统计该单词在该句子中的出现次数;
判断所述文章库中文章和所述待查文章的相对比句子中出现单词及其出现次数均相同的情况数量是否达到了各个所述相对比句子中出现单词及其出现次数情况总量的设定范围;如果是,则所述相对比句子的相似度达到了设定范围。
优选地,所述待查文章和所述文章库中的文章均按照语句结束符号拆分为句子;
其中,所述语句结束符号包括句号、问号和感叹号。
本发明还提供一种中文文章查重系统,包括:
拆分模块,用于将待查文章和文章库中的文章均拆分为句子;
翻译模块,用于将所述句子翻译成英文;
对比判断模块,用于将所述待查文章中的句子和所述文章库中文章的句子按序进行一一对比,判断相对比句子的相似度是否达到了设定范围;
统计确定模块,用于统计所述待查文章中与所述文章库中文章的句子相似度达到设定范围的句子数量是否达到了所述待查文章中句子总数的设定范围,并根据统计结果确定所述待查文章是否为重复文章。
优选地,还包括:
设置模块,用于设置同义词库,所述同义词库用于定义同义词;
更换模块,用于根据所述同义词库将所述文章库中文章和所述待查文章中的同义词统一更换为所述待查文章中的用词。
优选地,所述设置模块包括:
第一设置单元,用于设置语义相近的词为同义词并设置表示同一时间的词为同义词;
第二设置单元,用于设置同一个词的不同时态和单复数为同义词并设置同一个词的大小写为同义词;
第三设置单元,用于设置同一个词的名词性物主代词和形容词性物主代词为同义词并设置同一事物的知名绰号、别名和本名为同义词。
优选地,所述对比判断模块包括:
第一记录统计单元,用于记录所述待查文章每个句子中出现的单词并统计该单词在该句子中的出现次数;
第二记录统计单元,用于记录所述文章库中文章的每个句子中出现的单词并统计该单词在该句子中的出现次数;
判断确定单元,用于判断所述文章库中文章和所述待查文章的相对比句子中出现单词及其出现次数均相同的情况数量是否达到了各个所述相对比句子中出现单词及其出现次数情况总量的设定范围,以确定所述相对比句子的相似度是否达到了设定范围。
优选地,所述拆分模块用于将所述待查文章和所述文章库中的文章按照语句结束符号拆分为句子;
其中,所述语句结束符号包括句号、问号和感叹号。
本发明的有益效果:本发明所提供的中文文章查重方法和系统,通过将文章库中的文章和待查文章拆分为句子,并将句子都翻译成英文,然后通过对比按序相对应句子的相似度,统计相似度达设定范围的句子在待查文章句子中的占比,从而确定待查文章是否为重复文章,能够避免中文语言的复杂性如语句的重组和分词方法的不准所导致的中文论文查重准确性不高的问题,提高了中文论文查重的准确性。
附图说明
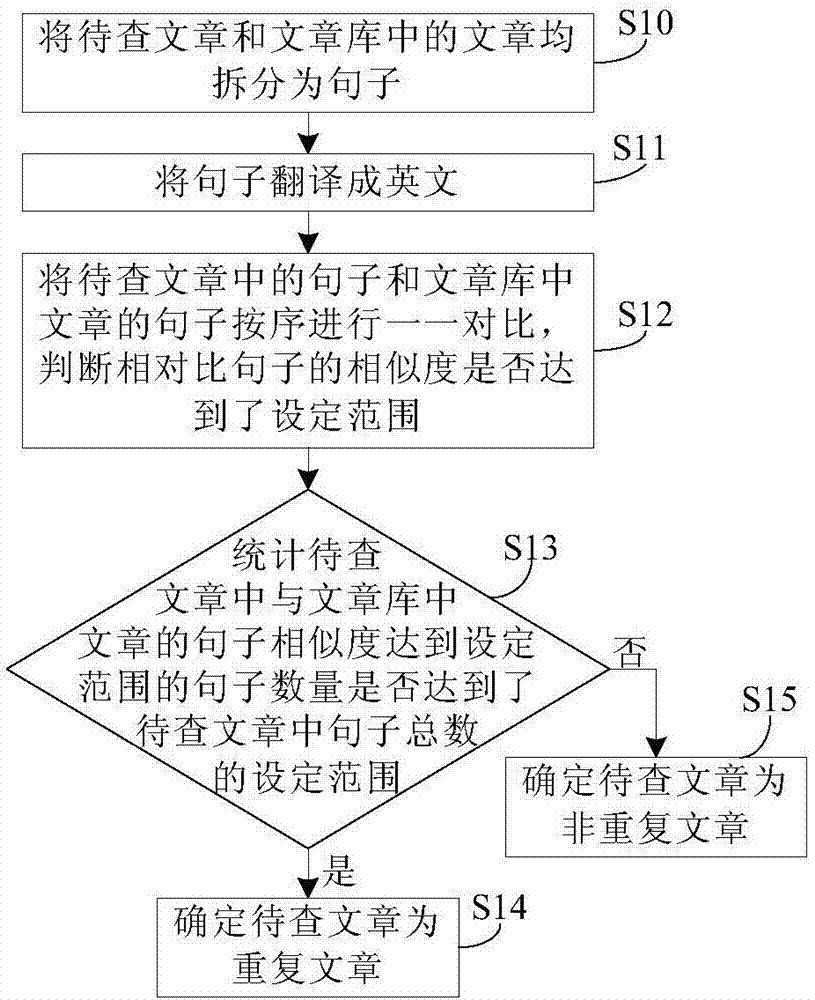
图1为本发明实施例1中中文文章查重方法的流程图;
图2为本发明实施例2中中文文章查重方法的流程图;
图3为本发明实施例3中中文文章查重系统的原理框图。
其中的附图标记说明:
1.拆分模块;2.翻译模块;3.对比判断模块;31.第一记录统计单元;32.第二记录统计单元;33.判断确定单元;4.统计确定模块;5.设置模块;51.第一设置单元;52.第二设置单元;53.第三设置单元;6.更换模块。
具体实施方式
为使本领域的技术人员更好地理解本发明的技术方案,下面结合附图和具体实施方式对本发明所提供的一种中文文章查重方法和系统作进一步详细描述。
实施例1:
本实施例提供一种中文文章查重方法,如图1所示,包括:
步骤s10:将待查文章和文章库中的文章均拆分为句子。
本实施例中,待查文章和文章库中的文章均为中文论文。文章库中的文章可以是一篇,也可以是多篇。
步骤s11:将句子翻译成英文。
将句子翻译成英文能够避免中文语言的复杂性如语句的重组和分词方法的不准所导致的文章查重准确性不高的问题。
步骤s12:将待查文章中的句子和文章库中文章的句子按序进行一一对比,判断相对比句子的相似度是否达到了设定范围。
其中,设定范围为70%以上。
步骤s13:统计待查文章中与文章库中文章的句子相似度达到设定范围的句子数量是否达到了待查文章中句子总数的设定范围。
如果是,则执行步骤s14:确定待查文章为重复文章。如果否,则执行步骤s15:确定待查文章为非重复文章。
本实施例中,如果文章库中的文章为多篇,则待查文章与文章库中的文章逐篇进行步骤s12~步骤s15中的对比、统计和确定,从而确定待查文章与多篇文章相比,是否为重复文章,重复文章表示待查文章为抄袭文章。
该中文文章查重方法,通过将文章库中的文章和待查文章拆分为句子,并将句子都翻译成英文,然后通过对比按序相对应句子的相似度,统计相似度达设定范围的句子在待查文章句子中的占比,从而确定待查文章是否为重复文章,能够避免中文语言的复杂性如语句的重组和分词方法的不准所导致的中文论文查重准确性不高的问题,提高了中文论文查重的准确性。
实施例2:
本实施例提供一种中文文章查重方法,如图2所示,包括:
步骤s10:将待查文章和文章库中的文章均拆分为句子。
该步骤中,待查文章和文章库中的文章均按照语句结束符号拆分为句子。其中,语句结束符号包括句号、问号和感叹号。
本实施例中,待查文章和文章库中的文章均为中文论文。文章库中的文章是多篇。文章库中的多篇文章分别与待查文章进行逐篇对比。文章库中的文章拆分后的结果为:
l1={l1,1,l1,2,l1,3,……l1,m},第一篇文章拆分为m个句子。
l2={l2,1,l2,2,l2,3,……l2,m},第二篇文章拆分为m个句子。
l3={l3,1,l3,2,l3,3,……l3,m},第三篇文章拆分为m个句子。
……
ln={ln,1,ln,2,ln,3,……ln,m},第n篇文章拆分为m个句子。
待查文章拆分后的结果为:
r={r1,r2,r3,……rm},待查文章r拆分为m个句子。
步骤s11:将句子翻译成英文。
本实施例中,文章库中文章的各句子分别翻译成英文:
l1={l1,1,l1,2,l1,3,……l1,m}->el1={el1,1,el1,2,el1,3,……el1,m},第一篇文章中的各句子翻译成英文。
l2={l2,1,l2,2,l2,3,……l2,m}->el2={el2,1,el2,2,el2,3,……el2,m},第二篇文章中的各句子翻译成英文。
l3={l3,1,l3,2,l3,3,……l3,m}->el3={el3,1,el3,2,el3,3,……el3,m},第三篇文章中的各句子翻译成英文。
……
ln={ln,1,ln,2,ln,3,……ln,m}->eln={eln,1,eln,2,eln,3,……eln,m},第n篇文章中的各句子翻译成英文。
待查文章中的各句子翻译成英文:
r={r1,r2,r3,……rm}->er={er1,er2,er3,……erm}。
步骤s11′:设置同义词库,同义词库用于定义同义词。
该步骤具体包括:
设置语义相近的词为同义词。如将extremely与seriously设置为同义词。
设置表示同一时间的词为同义词。如今年是2018年,则将“2018”与“thisyear”设置为同义词。
设置同一个词的不同时态和单复数为同义词。如将eat和eaten设置为同义词,apple和apples设置为同义词。
设置同一个词的大小写为同义词。如将rat和rat设置为同义词。
设置同一个词的名词性物主代词和形容词性物主代词为同义词。如将yours和your设置为同义词。
设置同一事物的知名绰号、别名和本名为同义词。如将英国国王爱德华一世的绰号“longshank”和“edwardⅰ”设置为同义词。
步骤s12′:根据同义词库将文章库中文章和待查文章中的同义词统一更换为待查文章中的用词。
步骤s11′和步骤s12′的设置,能够使后续相对比句子相似度的判定更加准确,从而提高了文章查重的准确性。
步骤s12:将待查文章中的句子和文章库中文章的句子按序进行一一对比,判断相对比句子的相似度是否达到了设定范围。
其中,设定范围为70%以上。即将待查文章中的第一句与文章库中文章的第一句进行对比,两文章中的第二句进行对比,依次类推进行句子对比。
该步骤具体包括:
步骤s121:记录待查文章每个句子中出现的单词并统计该单词在该句子中的出现次数。
如word为出现的单词,count为单词出现的次数:
er1,word1,1,count1,1;word1,2,count1,2;……word1,n,count1,n。
er2,word2,1,count2,1;word2,2,count2,2;……word2,n,count2,n。
……
erm,wordm,1,countn,1;wordm,2,countm,2;……wordm,n,countm,n。
例如:er1=hello,howareyou?则word1,1=hello,count1,1=1;word1,2=how,count1,2=1;word1,4=you,count1,4=1。
步骤s122:记录文章库中文章的每个句子中出现的单词并统计该单词在该句子中的出现次数。
步骤s123:判断文章库中文章和待查文章的相对比句子中出现单词及其出现次数均相同的情况数量是否达到了各个相对比句子中出现单词及其出现次数情况总量的设定范围;如果是,则相对比句子的相似度达到了设定范围。
该步骤中,一个句子中出现的单词及该单词的出现次数作为一个整体条件考虑。即相对比的两句子中,出现单词及其出现次数均相同为一种情况,出现单词相同但其出现次数不同为另一种情况,出现单词及其出现次数均不同为又一种情况,在相对比的其中一个句子中出现但在另一个句子中未出现的单词及其出现次数也是一种情况。各个相对比句子中出现单词及其出现次数情况总量包括上述各种情况。
步骤s121~步骤s123的设置,能够使相对比句子的相似度判定更加准确,从而提高了文章查重的准确性。
步骤s13:统计待查文章中与文章库中文章的句子相似度达到设定范围的句子数量是否达到了待查文章中句子总数的设定范围。
如果是,则执行步骤s14:确定待查文章为重复文章。如果否,则执行步骤s15:确定待查文章为非重复文章。
本实施例中,如果文章库中的文章为多篇,则待查文章与文章库中的文章逐篇进行步骤s12~步骤s15中的对比、统计和确定,从而确定待查文章与多篇文章相比,是否为重复文章,重复文章表示待查文章为抄袭文章。
实施例1-2的有益效果:实施例1-2中所提供的中文文章查重方法,通过将文章库中的文章和待查文章拆分为句子,并将句子都翻译成英文,然后通过对比按序相对应句子的相似度,统计相似度达设定范围的句子在待查文章句子中的占比,从而确定待查文章是否为重复文章,能够避免中文语言的复杂性如语句的重组和分词方法的不准所导致的中文论文查重准确性不高的问题,提高了中文论文查重的准确性。
实施例3:
基于实施例2中所提供的中文文章查重方法,本实施例提供一种中文文章查重系统,如图3所示,包括:拆分模块1,用于将待查文章和文章库中的文章均拆分为句子。翻译模块2,用于将句子翻译成英文。对比判断模块3,用于将待查文章中的句子和文章库中文章的句子按序进行一一对比,判断相对比句子的相似度是否达到了设定范围。统计确定模块4,用于统计待查文章中与文章库中文章的句子相似度达到设定范围的句子数量是否达到了待查文章中句子总数的设定范围,并根据统计结果确定待查文章是否为重复文章。
本实施例中,设定范围为70%以上。拆分模块1用于将待查文章和文章库中的文章按照语句结束符号拆分为句子。其中,语句结束符号包括句号、问号和感叹号。
本实施例中,翻译模块2的设置,能将句子翻译成英文,从而避免中文文章分词的不准确和中文语言的复杂性所导致的文章查重准确性不高的问题。对比判断模块3和统计确定模块4的设置,能够使相对比句子的相似度判定更加准确,从而提高了文章查重的准确性。
本实施例中,中文文章查重系统还包括:设置模块5,用于设置同义词库,同义词库用于定义同义词。更换模块6,用于根据同义词库将文章库中文章和待查文章中的同义词统一更换为待查文章中的用词。设置模块5和更换模块6的设置,能够使后续相对比句子相似度的判定更加准确,从而提高了文章查重的准确性。
其中,设置模块5包括:第一设置单元51,用于设置语义相近的词为同义词并设置表示同一时间的词为同义词。第二设置单元52,用于设置同一个词的不同时态和单复数为同义词并设置同一个词的大小写为同义词。第三设置单元53,用于设置同一个词的名词性物主代词和形容词性物主代词为同义词并设置同一事物的知名绰号、别名和本名为同义词。
本实施例中,对比判断模块3包括:第一记录统计单元31,用于记录待查文章每个句子中出现的单词并统计该单词在该句子中的出现次数。第二记录统计单元32,用于记录文章库中文章的每个句子中出现的单词并统计该单词在该句子中的出现次数。判断确定单元33,用于判断文章库中文章和待查文章的相对比句子中出现单词及其出现次数均相同的情况数量是否达到了各个相对比句子中出现单词及其出现次数情况总量的设定范围,以确定相对比句子的相似度是否达到了设定范围。第一记录统计单元31、第二记录统计单元32和判断确定单元33的设置,能够使相对比句子的相似度判定更加准确,从而提高了文章查重的准确性。
需要说明的是,对比判断模块3中,一个句子中出现的单词及该单词的出现次数作为一个整体条件考虑。即相对比的两句子中,出现单词及其出现次数均相同为一种情况,出现单词相同但其出现次数不同为另一种情况,出现单词及其出现次数均不同为又一种情况,在相对比的其中一个句子中出现但在另一个句子中未出现的单词及其出现次数也是一种情况。各个相对比句子中出现单词及其出现次数情况总量包括上述各种情况。
实施例3的有益效果:实施例3中所提供的中文文章查重系统,通过设置拆分模块、翻译模块、对比判断模块和统计确定模块,能够避免中文语言的复杂性如语句的重组和分词方法的不准所导致的中文论文查重准确性不高的问题,提高了中文论文查重的准确性。
可以理解的是,以上实施方式仅仅是为了说明本发明的原理而采用的示例性实施方式,然而本发明并不局限于此。对于本领域内的普通技术人员而言,在不脱离本发明的精神和实质的情况下,可以做出各种变型和改进,这些变型和改进也视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!