基于人工智能的在线学习方法与流程
本发明涉及在线学习方法,特别是涉及基于人工智能的在线学习方法。
背景技术
在线学习现在虽然越来越普及,可是对于学习状态和效果的监控,是提高教学质量的重要环节,充分了解学生学习时的反应,才能保证高质量的教学水平。现有教学软件对用户的行为分析还很原始,都是基于对界面的操作来进行,此种方式不能够准确把握学习者的状态,也无法做到有效及时的调整。
技术实现要素:
基于此,有必要针对上述技术问题,提供一种基于人工智能的在线学习方法,通过识别用户的表情,对播放内容进行调整,保证高质量的教学水平。
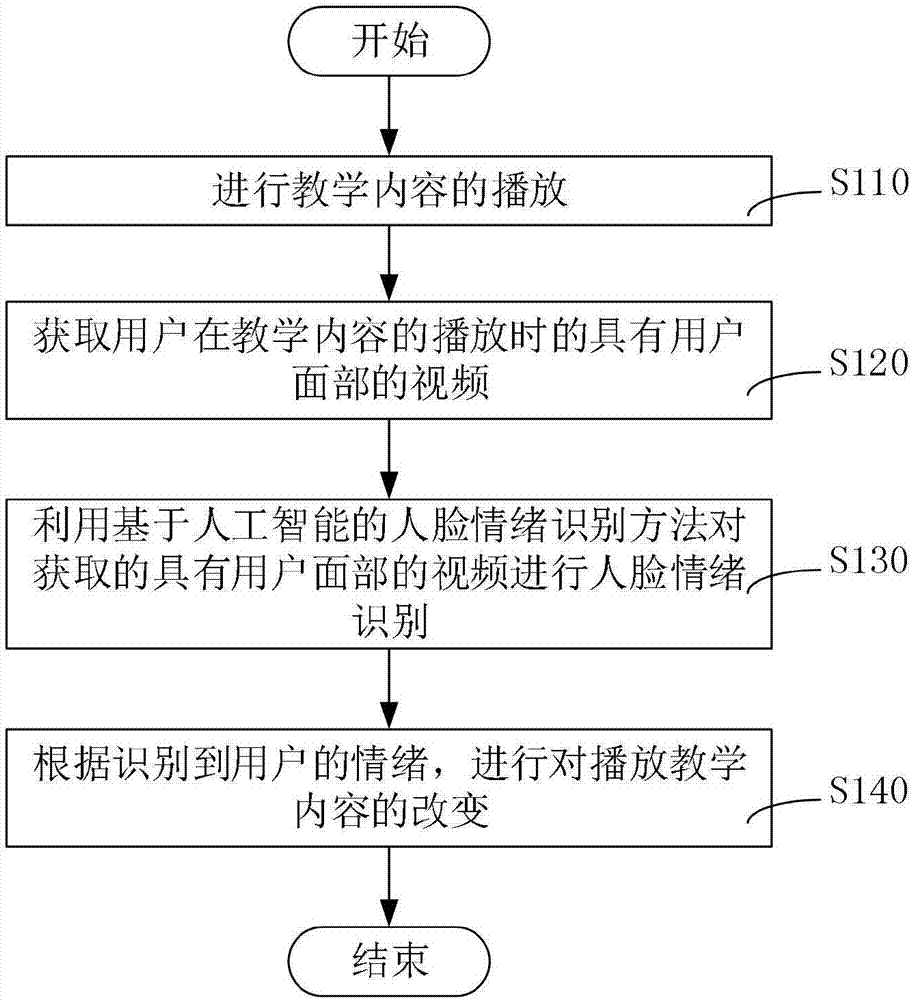
一种基于人工智能的在线学习方法,包括:
进行教学内容的播放;
获取用户在教学内容的播放时的具有用户面部的视频;
利用基于人工智能的人脸情绪识别方法对获取的具有用户面部的视频进行人脸情绪识别;
根据识别到用户的情绪,进行对播放教学内容的改变,具体包括:
当检测到用户一直表现出愉快、兴奋或期待的表情时,加快播放的进度;
当检测到用户表现出疑惑的表情时,减低播放的进度,并且重复播放已播放的内容;
当检测到用户进一步表现出失望、不耐烦或疲劳的表情时,更换播放内容,或播放音乐,或进入游戏界面,或进入聊天界面,或播放结束;
当检测到用户表现出生气、反感的表情时,停止播放当前内容,自动匹配其他教学课程。
上述基于人工智能的在线学习方法,通过识别用户的表情,对播放内容进行调整,保证高质量的教学水平。
在另外的一个实施例中,“利用基于人工智能的人脸情绪识别方法对获取的具有用户面部的视频进行人脸情绪识别;”中,基于人工智能的人脸情绪识别方法具体包括:
步骤1:获取视频素材,对视频进行分帧处理,划分出视频中所有完整的表情动作,具体方法为:
步骤2:标定面部关键点及图像预处理;在获取分帧后的人脸图像后,先进行特征点的标定,对于所有可识别的人脸标定出m个特征点,对获得的面部特征点进行旋转、平移和缩放的坐标变换几何归一化处理;
步骤3:计算特征向量;在n帧为一组的面部特征点信息中,计算每个特征点n个坐标序列的最大值、最小值、平均值、峰度、偏度、离散傅里叶变换(discretefouriertransform,dft)峰值及其所对应频率,再使用主成分分析(principalcomponentanalysis,pca)降维,去除冗余数据,作为表情的特征向量;
步骤4:对表情进行分类及识别;将预先设定的表情的特征向量以及与之对应的标签输入分类器中进行训练,得到训练的结果模型,分类器采用支持向量机(supportvectormachine,svm)或邻近算法(k-nearestneighbor,k-nn);在识别时,将要识别的图像序列的特征向量与训练的结果模型输入分类器,得到识别结果。
在另外的一个实施例中,步骤1具体包括:
步骤1.1:用分帧代码对拍摄到的视频进行分帧处理,保存视频的每一帧图像;
步骤1.2:划分出视频中所有的完整表情变化的图像,从正常表情开始,到表情最大化时结束,定义每n帧图像为单个表情动作的完整变化,n表示某一表情从正常到最大化的过程所占用的图像帧数,其取值根据被识别视频的清晰度确定;
步骤1.3:返回步骤1.1重复执行,直到所有视频都处理完毕。
在另外的一个实施例中,所述步骤2的具体方法为:
步骤2.1:使用人脸标定工具,检测出图像中的人脸,并标出m个特征点,m为人脸标定工具特定参数;
步骤2.2:将直角坐标转换为齐次坐标,定义每帧图像的特征点齐次坐标为m;
步骤2.3:旋转面部特征点,除去帧图像中人脸相对于图像坐标轴的倾斜角;
步骤2.4:将坐标原点平移到面部中心;
步骤2.5:以鼻梁左右距离l为基准值,将所有特征点的坐标除以l,对特征点坐标进行缩放,得到经过旋转、平移、缩放变换后的特征点齐次坐标m’;
步骤2.6:判断是否视频中所有图像均完成几何归一化处理,若是,则执行步骤3,若否,则返回步骤2.1重复执行,直到所有图像均被处理。
在另外的一个实施例中,在步骤2获得面部特征点坐标信息后,对于所有的表情素材,取每n帧为一个表情单位,随后计算每个特征点n维坐标序列的最大值、最小值、平均值、峰度、偏度、自相关性、以及dft变换后的幅度峰值及其频率,具体方法为:
步骤3.1:人脸标定工具所标定的m个面部特征点中,除去r个定位不准确的脸部轮廓点,共m0个可供使用的特征点,m0=m-r;
步骤3.2:计算m0个可供使用的特征点中每个特征点的坐标序列中的最大值、最小值、平均值、峰度和偏度,得到m0×2×5个特征值;
步骤3.3:对m0个可供使用的特征点中每个特征点的坐标序列进行dft变换,选取5个最大的傅里叶峰值及其所对应频率,获得m0×2×5个每个点对应的傅里叶峰值和m0×2×5个峰值所对应的频率;
步骤3.4:计算m0个可供使用的特征点中每个特征点坐标序列的自相关性,每个特征点选用n个不重复的值作为特征向量的一部分,共有m0×2×n维数据;
步骤3.5:在以上特征值计算后,得到特征向量的m0×2×5×3+m0×2×n个特征值,利用pca函数对该特征向量进行降维;
步骤3.6:重复步骤3.1到3.5,直到计算出所有表情的特征向量。
在另外的一个实施例中,在进行教学内容的播放以前,根据面部特征实时检测登陆的用户身份,当检测到当前用户与登录用户不匹配时,暂停播放。
在另外的一个实施例中,在进行教学内容的播放以前,获取用户的年龄、性别、所在位置、语言能力、兴趣、填写的教学水平、填写的课程定价、填写的课程内容和填写的授课时间,自动匹配教学课程进行播放。
一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,其特征在于,所述处理器执行所述程序时实现任一项所述方法的步骤。
一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现任一项所述方法的步骤。
一种处理器,所述处理器用于运行程序,其中,所述程序运行时执行任一项所述的方法。
附图说明
图1为本申请实施例提供的一种基于人工智能的在线学习方法的流程示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
参阅图1,一种基于人工智能的在线学习方法,包括:
s110、进行教学内容的播放。
s120、获取用户在教学内容的播放时的具有用户面部的视频。
s130、利用基于人工智能的人脸情绪识别方法对获取的具有用户面部的视频进行人脸情绪识别。
s140、根据识别到用户的情绪,进行对播放教学内容的改变,具体包括:
当检测到用户一直表现出愉快、兴奋或期待的表情时,加快播放的进度;
当检测到用户表现出疑惑的表情时,减低播放的进度,并且重复播放已播放的内容;
当检测到用户进一步表现出失望、不耐烦或疲劳的表情时,更换播放内容,或播放音乐,或进入游戏界面,或进入聊天界面,或播放结束;
当检测到用户表现出生气、反感的表情时,停止播放当前内容,自动匹配其他教学课程。
上述基于人工智能的在线学习方法,通过识别用户的表情,对播放内容进行调整,保证高质量的教学水平。
在另外的一个实施例中,“利用基于人工智能的人脸情绪识别方法对获取的具有用户面部的视频进行人脸情绪识别;”中,基于人工智能的人脸情绪识别方法具体包括:
步骤1:获取视频素材,对视频进行分帧处理,划分出视频中所有完整的表情动作,具体方法为:
步骤2:标定面部关键点及图像预处理;在获取分帧后的人脸图像后,先进行特征点的标定,对于所有可识别的人脸标定出m个特征点,对获得的面部特征点进行旋转、平移和缩放的坐标变换几何归一化处理;
步骤3:计算特征向量;在n帧为一组的面部特征点信息中,计算每个特征点n个坐标序列的最大值、最小值、平均值、峰度、偏度、离散傅里叶变换(discretefouriertransform,dft)峰值及其所对应频率,再使用主成分分析(principalcomponentanalysis,pca)降维,去除冗余数据,作为表情的特征向量;
步骤4:对表情进行分类及识别;将预先设定的表情的特征向量以及与之对应的标签输入分类器中进行训练,得到训练的结果模型,分类器采用支持向量机(supportvectormachine,svm)或邻近算法(k-nearestneighbor,k-nn);在识别时,将要识别的图像序列的特征向量与训练的结果模型输入分类器,得到识别结果。
在另外的一个实施例中,步骤1具体包括:
步骤1.1:用分帧代码对拍摄到的视频进行分帧处理,保存视频的每一帧图像;
步骤1.2:划分出视频中所有的完整表情变化的图像,从正常表情开始,到表情最大化时结束,定义每n帧图像为单个表情动作的完整变化,n表示某一表情从正常到最大化的过程所占用的图像帧数,其取值根据被识别视频的清晰度确定;
步骤1.3:返回步骤1.1重复执行,直到所有视频都处理完毕。
在另外的一个实施例中,所述步骤2的具体方法为:
步骤2.1:使用人脸标定工具,检测出图像中的人脸,并标出m个特征点,m为人脸标定工具特定参数;
步骤2.2:将直角坐标转换为齐次坐标,定义每帧图像的特征点齐次坐标为m;
步骤2.3:旋转面部特征点,除去帧图像中人脸相对于图像坐标轴的倾斜角;
步骤2.4:将坐标原点平移到面部中心;
步骤2.5:以鼻梁左右距离l为基准值,将所有特征点的坐标除以l,对特征点坐标进行缩放,得到经过旋转、平移、缩放变换后的特征点齐次坐标m’;
步骤2.6:判断是否视频中所有图像均完成几何归一化处理,若是,则执行步骤3,若否,则返回步骤2.1重复执行,直到所有图像均被处理。
在另外的一个实施例中,在步骤2获得面部特征点坐标信息后,对于所有的表情素材,取每n帧为一个表情单位,随后计算每个特征点n维坐标序列的最大值、最小值、平均值、峰度、偏度、自相关性、以及dft变换后的幅度峰值及其频率,具体方法为:
步骤3.1:人脸标定工具所标定的m个面部特征点中,除去r个定位不准确的脸部轮廓点,共m0个可供使用的特征点,m0=m-r;
步骤3.2:计算m0个可供使用的特征点中每个特征点的坐标序列中的最大值、最小值、平均值、峰度和偏度,得到m0×2×5个特征值;
步骤3.3:对m0个可供使用的特征点中每个特征点的坐标序列进行dft变换,选取5个最大的傅里叶峰值及其所对应频率,获得m0×2×5个每个点对应的傅里叶峰值和m0×2×5个峰值所对应的频率;
步骤3.4:计算m0个可供使用的特征点中每个特征点坐标序列的自相关性,每个特征点选用n个不重复的值作为特征向量的一部分,共有m0×2×n维数据;
步骤3.5:在以上特征值计算后,得到特征向量的m0×2×5×3+m0×2×n个特征值,利用pca函数对该特征向量进行降维;
步骤3.6:重复步骤3.1到3.5,直到计算出所有表情的特征向量。
在另外的一个实施例中,在进行教学内容的播放以前,根据面部特征实时检测登陆的用户身份,当检测到当前用户与登录用户不匹配时,暂停播放。
在另外的一个实施例中,在进行教学内容的播放以前,获取用户的年龄、性别、所在位置、语言能力、兴趣、填写的教学水平、填写的课程定价、填写的课程内容和填写的授课时间,自动匹配教学课程进行播放。
一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,其特征在于,所述处理器执行所述程序时实现任一项所述方法的步骤。
一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现任一项所述方法的步骤。
一种处理器,所述处理器用于运行程序,其中,所述程序运行时执行任一项所述的方法。
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!